今年一年实时计算任务逐步从Yarn集群逐步迁移到k8s环境,由于k8s集群的严格内存的模式,所以今年很多作业都饱受oom的痛苦,本文主要总结一下Java内存占用分析的一些工具
分析工具
NMT
这是Java自带的Native Memory Track的工具,可以用于追踪JVM的内部内存使用。使用这个工具只需要启动Java进程的时候指定相应的option开启,相应的flink的参数如下
env.java.opts: "-XX:NativeMemoryTracking=summary -Dtracer_append_pid_to_log_path=true -Dlogging.path=${LOG_DIRS} -XX:+UseParNewGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=1000 -XX:+CMSClassUnloadingEnabled -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:SurvivorRatio=5 -XX:ParallelGCThreads=4"
开启后,在作业运行时可以通过
jcmd pid VM.native_memory summary scale=MB
得到如下的信息
$ jcmd 632 VM.native_memory summary scale=MB632:Native Memory Tracking:Total: reserved=9893MB, committed=8684MB- Java Heap (reserved=8228MB, committed=8228MB)(mmap: reserved=8228MB, committed=8228MB)- Class (reserved=1102MB, committed=86MB)(classes #13276)(malloc=2MB #20238)(mmap: reserved=1100MB, committed=84MB)- Thread (reserved=86MB, committed=86MB)(thread #86)(stack: reserved=85MB, committed=85MB)- Code (reserved=254MB, committed=60MB)(malloc=10MB #14490)(mmap: reserved=244MB, committed=50MB)- GC (reserved=44MB, committed=44MB)(malloc=16MB #329)(mmap: reserved=28MB, committed=28MB)- Internal (reserved=26MB, committed=26MB)(malloc=26MB #17296)- Symbol (reserved=20MB, committed=20MB)(malloc=17MB #163542)(arena=3MB #1)- Native Memory Tracking (reserved=4MB, committed=4MB)(tracking overhead=3MB)- Unknown (reserved=130MB, committed=130MB)(mmap: reserved=130MB, committed=130MB)
其他详细的使用命令
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]# summary: 分类内存使用情况.# detail: 详细内存使用情况,除了summary信息之外还包含了虚拟内存使用情况。# baseline: 创建内存使用快照,方便和后面做对比# summary.diff: 和上一次baseline的summary对比# detail.diff: 和上一次baseline的detail对比# shutdown: 关闭NMT
这里面的baseline的工具,可以在作业刚启动的时候创建快照,运行一段时间后通过summary.diff或者detail.diff工具查看这段时间的变化量
jcmd pid VM.native_memory baselinejcmd pid VM.native_memory summary.diff
以是对输出的各项指标的含义解读
reserved 和 committed memory
在每个区块中包括了reserved memory和committed memory 大小
reserved memory 是JVM 通过mmaped 申请的虚拟地址空间,权限是PROT_NONE,在页表中已经存在了记录(entries),保证了其他进程不会被占用,但是JVM还不能直接使用这块内存
committed memory 是JVM向操作系统实际分配的内存(malloc/mmap),mmaped权限是 PROT_READ | PROT_WRITE,这块内存可以被直接使用**
RSS和committed,reservered memory
关于committed,reserved以及rss之间的关系: 首先这几个变量之间没有等量的关系
- reservered memory不一定都是committed memory,要出去PROT_NONE的部分
- committed memory不一定都是resident memory,因为malloc/mmap is lazy unless told otherwise. Pages are only backed by physical memory once they’re accessed.
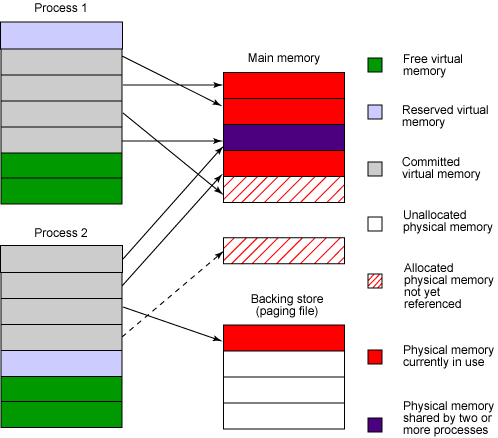
图片来自: https://www.ibm.com/developerworks/library/j-memusage/index.html
https://stackoverflow.com/questions/31173374/why-does-a-jvm-report-more-committed-memory-than-the-linux-process-resident-set
https://zhanjindong.com/2016/03/02/jvm-memory-tunning-notes
malloc 和mmap
在输出中还能看到内存申请的方式malloc和mmap两种方式各自申请了多少,在linux中可以通过brk,sbrk,malloc,mmap函数进行内存申请。
- brk和sbrk分别是调整堆顶的brk指针的指向,一种是相对,一种是绝对位置的调整
- mmap 见下文
- malloc是更高阶一点的动态内存分配器,默认情况下Linux系统Glibc的行为是调用malloc申请内存时,如果申请大小小于M_MMAP_THRESHOLD, 那么就通过brk的系统调用申请内存,如果超过了阈值,则通过mmap的系统调用来申请内存,但是从jdk的一些源码注释中(不是特别确定是不是这段代码)可以看到HotSpot内部为了兼容一些操作系统Solaris没有做这样的优化处理,所以在分配大对象的时候就会直接通过mmap来申请内存。因此JVM的heap区都是通过mmap直接申请的。
mmap 是将虚拟内存区域与磁盘上的对象进行映射,来初始化虚拟内存区域的内容// Helper class to allocate arrays that may become large. // Uses the OS malloc for allocations smaller than ArrayAllocatorMallocLimit // and uses mapped memory for larger allocations. // Most OS mallocs do something similar but Solaris malloc does not revert // to mapped memory for large allocations. By default ArrayAllocatorMallocLimit // is set so that we always use malloc except for Solaris where we set the // limit to get mapped memory.
参数含义可以参考: Linux 内存映射函数 mmap()函数详解void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset)
虚拟内存区域可以映射到
1)Linux文件系统中的普通文件,就是通常使用mmap来读取文件的方式,映射到文件时,fd就是对应文件的fd
2)匿名文件,效果就是直接向操作系统申请一块虚拟内存,传入参数fd = -1时就是映射到匿名文件
prot表示 期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
prot:
PROT_EXEC //页内容可以被执行
PROT_READ //页内容可以被读取
PROT_WRITE //页可以被写入
PROT_NONE //页不可访问
上文中提到reserved memory是PROT_NONE的, committed memory是 PROT_READ 和 PROT_WRITE的,具体的原因是什么呢?
PROT_NONE的详细含义,参见:
The memory is reserved, but cannot be read, written, or executed. If this flag is specified in a call to mmap, a virtual memory area will be set aside for future use in the process, and mmap calls without the MAP_FIXED flag will not use it for subsequent allocations. For anonymous mappings, the kernel will not reserve any physical memory for the allocation at the time the mapping is created.
虚拟内存在被真正访问之前都不会指向相应的物理内存。在被CPU第一次引用时,内核就在物理内存中找到一个合适的牺牲页面,如果该页面被修改过,就将这个页面换出,用二进制零覆盖牺牲页面并更新页表,将这个页面标记为驻留内存的。
但是假设这个虚拟内存的页面创建的时候的保护模式是PROT_NONE的,这个虚拟页面是无法被直接被访问的。JVM在初始化的时候申请的是PROT_NONE的一块reserved的内存,目的是为了提前申请一块连续的虚拟内存地址作为Java堆来使用,防止其他进程来使用这块内存。因为这块虚拟内存地址是不能被写或读的,在后续堆扩展可用区的时候会通过其他函数调用将相应的虚拟内存区转化成可读可写的。
https://stackoverflow.com/questions/12916603/what-s-the-purpose-of-mmap-memory-protection-prot-none
PROT_NONE allocates a contiguous virtual memory region with no permissions granted.
This can be useful, as other have mentioned, to implement guards (pages that on touch cause segfaults, both for bug hunting and security purposes) or “magic” pointers where values within a PROT_NONE mapping are to be interpreted as something other than a pointer.
Another use is when an application wishes to map multiple independent mappings as a virtually contiguous mapping. This would be done by first mmapping a large enough chunk with PROT_NONE, and then performing other mmap calls with the MAP_FIXED flag and an address set within the region of the PROT_NONE mapping (the use of MAP_FIXED automatically unmaps part of mappings that are being “overridden”).
还有一个原因应该是和linux overcommit机制有关,这个就不展开了,感兴趣的话可以看下以下的链接了解
https://unix.stackexchange.com/questions/353676/what-is-the-purpose-of-seemingly-unusable-memory-mappings-in-linux
https://engineering.pivotal.io/post/virtualmemory_settings_in_linux-_the_problem_with_overcommit/
https://utcc.utoronto.ca/~cks/space/blog/linux/LinuxVMOvercommit
https://lwn.net/Articles/627728/
https://lwn.net/Articles/627557/
各个部分的含义
| Category | Description |
|---|---|
| Java Heap | The heap. This is where your objects live. |
| Class | Class meta data. |
| Code | Generated code. |
| GC | Data use by the GC, such as card table. |
| Compiler | Memory used by the compiler when generating code. |
| Symbol | Symbols. |
| Memory Tracking | Memory used by the NMT itself. |
| Pooled Free Chunks | Memory used by chunks in the arena chunk pool. |
| Shared space for classes | Memory mapped to class data sharing archive. |
| Thread | Memory used by threads, including thread data structure, resource area and handle area, etc. |
| Thread stack | Thread stack. It is marked as committed memory, but it might not be completely committed by the OS. |
| Internal | Memory which does not fit the above categories, such as the memory used by the command line parser, JVMTI, properties, etc. |
| Unknown | When memory category can not be determined. - Arena: when arena is used as stack or value object - Virtual Memory: when type information has not yet arrived |
Java进程的内存可以被分为两部分,Java heap,和native memory(也就是操作系统的heap),上面表格中除了Heap其他的占用都可以被划分到native memory中。占用较大的几块是:
- Garbage collection. As you might recall, Java is a garbage-collected language. In order for the garbage collector to know which objects are eligible for collection, it needs to keep track of the object graphs. So this is one part of the memory lost to this internal bookkeeping. G1 is especially known for its excessive appetite for additional memory, so be aware of this.
- JIT optimization. Java Virtual Machine optimizes the code during runtime. Again, to know which parts to optimize it needs to keep track of the execution of certain code parts. So again, you are going to lose memory.
- Off-heap allocations. If you happen to use off-heap memory, for example while using direct or mapped ByteBuffers yourself or via some clever 3rd party API then voila – you are extending your heap to something you actually cannot control via JVM configuration. 在Flink中networkbuffer,netty都会使用这部分的内存
- JNI code. When you are using native code, for example in the format of Type 2 database drivers, then again you are loading code in the native memory. 但是这种第三方c的so库的申请的内存无法反映在NMT的输出结果中,需要通过下面的工具来分析。flink中使用的rocksdb,niagara的backend会使用这部分内存
- Metaspace. If you are an early adopter of Java 8, you are using metaspace instead of the good old permgen to store class declarations. This is unlimited and in a native part of the JVM.
- Thread Stacks. 每个线程都会分配独立的线程栈空间, 默认栈大小可以通过以下命令查看,下面输出表示1K
https://www.ibm.com/support/knowledgecenter/SSYKE2_7.0.0/com.ibm.java.aix.70.doc/diag/problem_determination/aix_mem_heaps.html[ root@fac6d0dfbbb4:/data ]$ java -XX:+PrintFlagsFinal -version |grep ThreadStackSize intx CompilerThreadStackSize = 0 intx ThreadStackSize = 1024 intx VMThreadStackSize = 1024
https://plumbr.io/blog/memory-leaks/why-does-my-java-process-consume-more-memory-than-xmx
实验
可以通过测试查看各个内存在NMT中的内存划分
https://gist.github.com/prasanthj/48e7063cac88eb396bc9961fb3149b58
我自己写了一个简单的测试,主要测试unsafe和allocateDirect分配的内存,最终会体现在Internal中, 通过detail的模式观察到的输出会更直观
// java -XX:NativeMemoryTracking=summary -Xmx3G -jar target/test-case-1.0-SNAPSHOT-jar-with-dependencies.jar
public static void main(String[] args) throws InterruptedException {
byte[] GB = new byte[1024 * 1024 * 1024];
byte[] GB2 = new byte[1024 * 1024 * 1024];
// allocateDirect 最终也是调用unsafe.allocateMemory, 这两块内存都是反映在NMT的Internal中
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024*1024*1024);
getUnsafe().allocateMemory(1024*1024*1024L);
// Arrays.fill(b, (byte) 0);
Thread.sleep(100000000);
}
public static Unsafe getUnsafe() {
try {
Field unsafeField = sun.misc.Unsafe.class.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
return (sun.misc.Unsafe) unsafeField.get(null);
} catch (SecurityException e) {
throw new RuntimeException("Could not access the sun.misc.Unsafe handle, permission denied by security manager.", e);
} catch (NoSuchFieldException e) {
throw new RuntimeException("The static handle field in sun.misc.Unsafe was not found.");
} catch (IllegalArgumentException e) {
throw new RuntimeException("Bug: Illegal argument reflection access for static field.", e);
} catch (IllegalAccessException e) {
throw new RuntimeException("Access to sun.misc.Unsafe is forbidden by the runtime.", e);
} catch (Throwable t) {
throw new RuntimeException("Unclassified error while trying to access the sun.misc.Unsafe handle.", t);
}
}
https://stackoverflow.com/questions/47309859/what-is-contained-in-code-internal-sections-of-jcmd
pmap
pmap工具可以查看进程的内存分布情况。一般使用pmap -x pid查看。
可以把pmap 看到的内存和 jcmd pid VM.native_memory detail 的结果比对,两遍的内存地址是能对应的,如果是jni库申请的内存,在nmt看不到,但是从pmap -x是能看到的。
pmap还可以配合gdb core dump文件分析内存布局,但是这个我没有做过,就不详细展开说了,后续如果有使用再展开分析
gdb
jemalloc
jemalloc是一个高性能的内存分配器,同时提供了heap perf的功能,我们可以借助他来进行内存dump分析。
alijdk有些版本默认使用了jemalloc,我们可以通过以下方式来查看使用的是不是jemalloc
ldd /opt/taobao/java/bin/java
在实际使用的过程中,遇到虽然有些版本默认使用的是jemalloc,但是编译的jemalloc没有enable prof,会报错
export LD_PRELOAD=/opt/taobao/java/lib/libjemalloc.so.2
export MALLOC_CONF="prof:true,prof_prefix:./jeprof.out,lg_prof_interval:30,lg_prof_sample:20"
$ java -version
<jemalloc>: Invalid conf pair: prof:true
<jemalloc>: Invalid conf pair: prof_prefix:./jeprof.out
<jemalloc>: Invalid conf pair: lg_prof_interval:28
<jemalloc>: Invalid conf pair: lg_prof_sample:20
就需要重新编译一个so替换使用
https://github.com/jemalloc/jemalloc/blob/dev/INSTALL.md
./configure --enable-prof
make && make instal
安装ok后使用方式只需要在进程启动的时候指定LD_PRELOAD环境变量和指定MALLOC_CONF指定采样的间隔,文件位置等。
export MALLOC_CONF="prof:true,prof_prefix:./jeprof.out,lg_prof_interval:30,lg_prof_sample:20"
lg_prof_interval:每分配2^n字节内存,dump出一个heap文件。
lg_prof_sample:每分配2^n字节内存,采样一次。默认为19,即512KB
jemalloc工具能够对malloc方法调用进行采样dump,生成dump文件后,可以进行分析得出内存分配的情况
sudo ./jeprof /opt/taobao/java/bin/java jeprof.out.651.2.i2.heap
sudo yum -y install ghostscript
sudo yum -y install graphviz
# 下载jeprof脚本
sudo chmod +x jeprof
# 生成svg图,可以在浏览器打开
./jeprof --svg /opt/taobao/java/bin/java /tmp/jeprof.out.158194.260.i260.heap --base /tmp/jeprof.out.158194.200.i200.heap > 158194.200-260.svg
./jeprof --svg /opt/taobao/java/bin/java /tmp/jeprof.out.158194.260.i260.heap > 158194.200-260.svg
还可以通过可视化的方式拿到比例分布的图
其他类似的工具tcmalloc
https://qsli.github.io/2017/12/02/google-perf-tools/
https://www.tikalk.com/posts/2017/09/12/2017-09-12-java-native-memory-leak-detection/
https://stackoverflow.com/questions/53576163/interpreting-jemaloc-data-possible-off-heap-leak
https://www.yuanguohuo.com/2019/01/02/jemalloc-heap-profiling/
https://medium.com/swlh/native-memory-the-silent-jvm-killer-595913cba8e7
排查到的几种OOM的case
- rocksdb 和 niagara 内存超用引起的oom问题 -> 切换到gemini backend
- glibc引起的 -> 切换到jemalloc作为默认内存分配器
- heap区占用较满引起的
第三种情况稍微补充下,其实是因为假设是一个source/维表这种纯粹heap内存型的节点,在执行计划阶段就不会分配很多native内存给这种节点,这样分配给这种节点的worker进程的预留内存就会较小甚至为0,因为目前Flink的内存分配是自下而上(从task内存推导最终的TM规格 + 每个TM的预留内存大小),目前的经验值是每个TM的预留内存是500M,导致假设一个堆内存需要7.5G的pod,最终申请的规格是8G,假设堆内存使用的较满的情况下内存占用就达到了7.5/8 = 93% , 再加上额外的内存占用就很容易触发OOM killer。
如果为了应对这种情况可能就要预留更多的cut off,势必带来一定程度的资源浪费。所以在这种小容器作业模式下的内存如果不具备弹性对于任务的稳定性和资源利用率来说可能不是最好的选择。
heap区占用较满还有一个原因是因为java的heap内存不会归还给操作系统,上文也说过java的heap区内存是先申请的一块虚拟内存,随着heap区域逐渐被touch,就会看到rss逐渐上升而不会被释放,这一点G1的垃圾收集器已经提供了elasticheap的功能 https://openjdk.java.net/jeps/346
知识点补充
brk,sbrk,mmap的区别
https://blog.csdn.net/Apollon_krj/article/details/54565768
https://blog.csdn.net/gfgdsg/article/details/42709943
http://luodw.cc/2016/02/17/malloc/
https://stackoverflow.com/questions/30542428/does-malloc-use-brk-or-mmap
https://cboard.cprogramming.com/linux-programming/101090-what-differences-between-brk-mmap.html
http://abcdxyzk.github.io/blog/2015/08/05/kernel-mm-malloc/
Glibc malloc源码分析
https://a1ex.online/2020/09/28/glibc-malloc%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/
https://paper.seebug.org/papers/Archive/refs/heap/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90.pdf
mmap的使用
https://www.cnblogs.com/linhaostudy/p/10632082.html
https://blog.minhazav.dev/memory-sharing-in-linux/
https://www.jianshu.com/p/eece39beee20
PROT_NONE内存保护类型的其他用途
在查阅的过程中发现PROT_NONE的类型的虚拟内存,还有别的作用,比如用来构建guard pages,在JVM中的栈保护也有使用这个机制, stack guard page for java
https://groups.google.com/g/mechanical-sympathy/c/GOA_zEY03SU?pli=1
https://www.codenong.com/cs109399210/
https://blog.csdn.net/qq_34310242/article/details/109399210
https://www.cnblogs.com/fwycmengsoft/p/4026007.html
https://lwn.net/Articles/725832/
关于docker oom行为的讨论
https://github.com/kubernetes/kubernetes/issues/40157
有帮助的博客
http://trustmeiamadeveloper.com/2016/03/18/where-is-my-memory-java/
https://stackoverflow.com/questions/35502348/how-does-a-jvm-process-allocate-its-memory
https://zhanjindong.com/2016/03/02/jvm-memory-tunning-notes
https://stackoverflow.com/questions/12115434/linux-will-zeroed-page-pagefault-on-first-read-or-on-first-write
http://www.brendangregg.com/FlameGraphs/memoryflamegraphs.html
内部文档
https://www.atatech.org/articles/193294
https://www.atatech.org/articles/39691
https://yuque.antfin-inc.com/biao.zhoub/note/bahvot
关于/proc/{pid}/smaps

若有收获,就点个赞吧
0 人点赞
