随着现在Kubernetes(以下都成为k8s)大行其道,各个公司也开始引入k8s集群,相比于yarn针对大数据的资源调度框架,其实k8s感觉诞生初期是为在线应用量身定制的,但是现在大家发现这些大数据引擎,也可以基于k8s的资源描述,将其运行在k8s集群上,能够更好的提高资源的利用率和架构的统一性,所以各个大数据引擎也开始支持on k8s的模式。Flink引擎在1.10版本也支持了原生的k8s调度。
Flink on k8s会使用以下几种k8s原生的资源:
ConfigMap: Flink的jar包和配置文件分离,配置文件修改更加灵活不需要修改镜像
Service: 用于暴露JobMaster提供Web以及rpc服务
Pod:启动JobMaster以及TaskManager节点
Deployment: 负责保证永远有一个Jobmanager存活
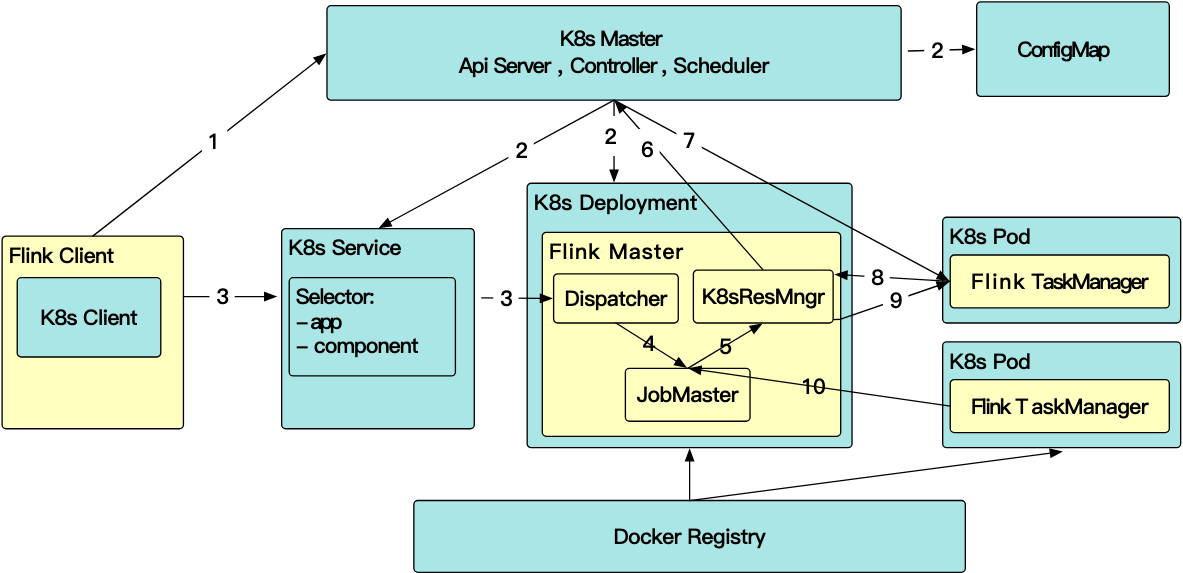
k8s任务的管理流程和yarn类似
- client发起申请,同时在客户端通过k8s client创建jobmaster service 以及rc
- rc拉起Flink JobMaster Pod,启动rest server,jobmaster,dispatcher和resourcemanager服务
- 客户端通过restclient提交job,并通过blob服务将jar包都上传到HA文件系统中
- 然后JM接收jobgraph后分析作业计算出所需的资源(TM个数,内存,cpu),开始向k8s申请资源,拉起TM
- 同时通过io.fabric8提供的watch接口监听同一个label的pod的event注册回调
public Watch createAndStartPodsWatcher(Map<String, String> labels,BiConsumer<Watcher.Action, Pod> podEventHandler, Consumer<Exception> watcherCloseHandler)throws ResourceManagerException {Watcher watcher = new Watcher<Pod>() {@Overridepublic void eventReceived(Action action, Pod pod) {podEventHandler.accept(action, pod);}@Overridepublic void onClose(KubernetesClientException e) {LOG.error("Pods watcher onClose");if (e != null) {LOG.error(e.getMessage(), e);}watcherCloseHandler.accept(e);}};return (Watch) runWithRetry(() -> kubernetesClient.pods().withLabels(labels).watch(watcher));}
关于Master的Service暴露方式有Cluster_IP 和 Node_Port方式,对于Cluster_IP模式暴露的服务在k8s集群外无法直接访问,需要通过代理来进行访问而Node_Port则是直接访问Master所在主机暴露的网络服务
资源清理
Flink会使用OwnerReference机制来做清理,所有创建的资源包括ConfigMap, Service, Deployment, Pod 都会设置owner reference指向service,所以当service被清理的时候,所有其他的service也都会被清理掉。
kubectl delete service/<ClusterID>
k8s的owner reference机制:https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/
问题
在任务切到k8s集群后遇到几类常见的线上问题
通常Yarn的内存管理比k8s的要粗,也就是在内存超出container内存申请量的时候并不会立即kill进程,而k8s上则会,导致内存需要申请的更大,否则很容易出现Task lost的异常

并且k8s上的内存管理不仅是pod级别,宿主机会有OOMKilled,在pod上还会有container的进程管理,可能在pod上直接被cgroup干掉,导致和TM心跳超时。
对于CPU资源来说也是比yarn限制的更死,通常需要调大核数,否则会出现Schedule阶段/TM注册JM很慢导致任务提交慢的情况
另外由于on k8s后没有原先的yarn的classpath,需要自行携带hadoop依赖以及core-site.xml和hdfs-site.xml配置,将其写入configMap中
社区issue
https://github.com/apache/flink/pull/9986
https://issues.apache.org/jira/browse/FLINK-9953
https://issues.apache.org/jira/browse/FLINK-11105
http://apache-flink-mailing-list-archive.1008284.n3.nabble.com/DISCUSS-Best-practice-to-run-flink-on-kubernetes-td31532.html

若有收获,就点个赞吧
0 人点赞
