本文是阅读 LinkedIn 公司2020年发表的论文 Magnet: Push-based Shuffle Service for Large-scale Data Processing 一点笔记。
什么是Shuffle
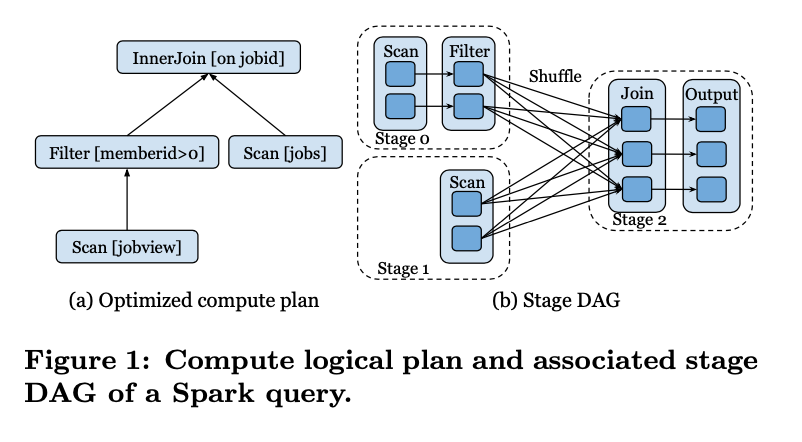
以上图为例,在一个DAG的执行图中,节点与节点之间的数据交换就是Shuffle的过程。虽然Shuffle的过程很简单,但是不同的引擎有不同的实现。
以shuffle数据传输的介质来看
- 有基于磁盘的shuffle,例如Map/Reduce ,Spark,Flink Batch中,上下游之前的数据都是需要落盘后来进行传输,这类通常是离线处理框架,对延迟不敏感,基于磁盘更加可靠稳定。
- 有基于内存的pipeline模式的shuffle方案,例如Presto/Flink Streaming中,主要是对时延比较敏感的场景,基于内存Shuffle,通过网络rpc直接传输内存数据
而基于本地磁盘的Shuffle实现中又有很多种不同的实现
- 有基于Hash的方案,每个map端的task为每个reduce task 产生一个 shuffle文件
- 有基于Sort方案,每个map端的task按照 partitionId + hash(key) 排序,并最终merge成一个文件以及一个index文件,在reduce端读取时根据每个task的index文件来读取相应segment的数据
以部署方式来看
- 有基于worker的本地shuffle的方案,直接通过worker来提供读写的功能
- 有基于external shuffle的实现,通常托管于资源管理框架,在Yarn框架中就可以实现这种辅助服务,这样就可以及时的释放worker计算资源
- 有基于Remote shuffle的实现,在云计算时代逐渐成为主流,因为其存算分离的架构往往能带来更好的可扩展性并且网络带宽的提高使得
co-locate也许不再那么重要。Spark Shuffle实现
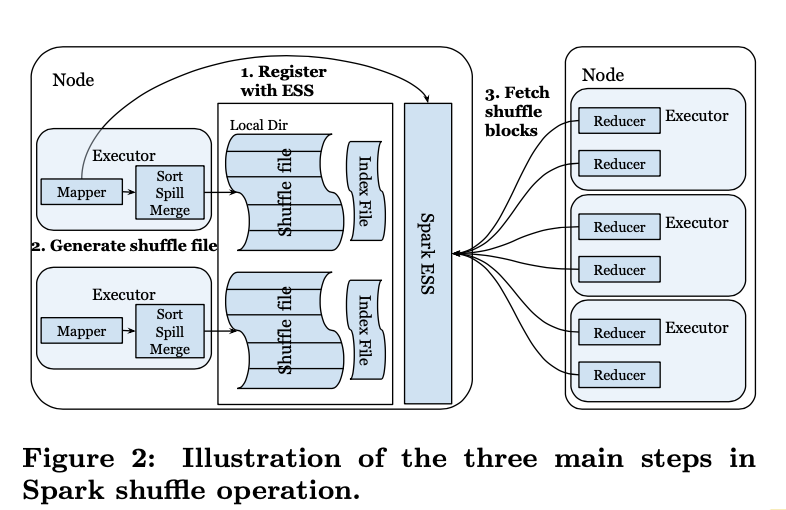
这里再大致介绍下spark原生的external sort shuffle的详细流程
- 每个spark executor启动后和本地节点的external shuffle service注册,同一个机器的多个executor会共享这个机器上的shuffle service服务。
- map stage处理完数据之后会产出两个文件 shuffle data 和 index文件,map task会按照partition key 来进行排序,属于同一个reduce 的数据作为一个Shuffle Block,而index文件中则会记录不同的Shuffle Block 之间的边界offset,辅助下游读取
- 当下游reduce task开始运行,首先会查询Spark driver 得到input shuffle blocks的位置信息,然后开始和spark ESS建立链接开始读取数据,读取数据时就会根据index文件来skip读取自己task那个shuffle blocks
痛点
在LinkedIn公司主要采用了Spark自带的基于Yarn的External sorted shuffle实现,主要遇到痛点:All-To-All Connections
map 和 reduce task之间需要维护all-to-all 的链接,以M个Map端task,R和Reducer端task为例,理论上就会建立M * R 个connection。
在实际实现中,一个executor上的reducer可以共享一个和ess的tcp链接。因此实际上的链接数是和executor个数 E 和ess节点数 S相关。但是在生产集群中 E 和 S 可能都会达到上千,这时链接数就会非常的客观,很容易带来稳定性的问题,如果建立链接失败可能会导致相关stage进行重跑,失败代价很高。Random IO
从上面的读取流程我们可以看到因为多个reduce task数据在同一个文件中,很容易产生随机读取的问题,并且从linkedin公司观察到的这些block通常都比较小,平均只有10KB。而LinkedIn shuffle集群主要使用的HDD磁盘,这个问题就会更大。并且随机读取以及大量的网络小包会带来性能的损失。
也许我们会想到说是否可以有办法来通过调参来让Shuffle Block 变大而减轻随机小IO的问题呢?比如把reduce task端的并发调小,这样每个task的数据量必然就变大了。
论文中也对此做了阐述,没法通过简单的调整reduce task的并发来增大shuffle block size的大小。
假设有一个M个mapper,R个reducer的任务,总的shuffle数据量为D。为了保持每个task处理的数据量恒定,当总数据量增长的时候,map和reduce的并发都要等比增长。
而shuffle block 大小就是 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图4](/uploads/projects/aitozi@blog/6da1460c9103cc3a902f84ebebf4b02d.svg) , 为什么 是
, 为什么 是 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图5](/uploads/projects/aitozi@blog/f263df305bf563385dc2da9a96f9c01a.svg) 呢,从上面的流程中可以看到每个map端可以近似看做是维护了R个reduce的block。所以总的block数是
呢,从上面的流程中可以看到每个map端可以近似看做是维护了R个reduce的block。所以总的block数是 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图6](/uploads/projects/aitozi@blog/3845cb9098cd65e50560bd21cb9fa3ea.svg) 。
。
那么当数据量增长时,并且为了保证每个task处理的数据量恒定,即性能不下降,那么shuffle block size必然会减小。最后也因为reduce端数据分散在所有的map端的task,导致不太能利用data locality的特性。
Magent 设计概要
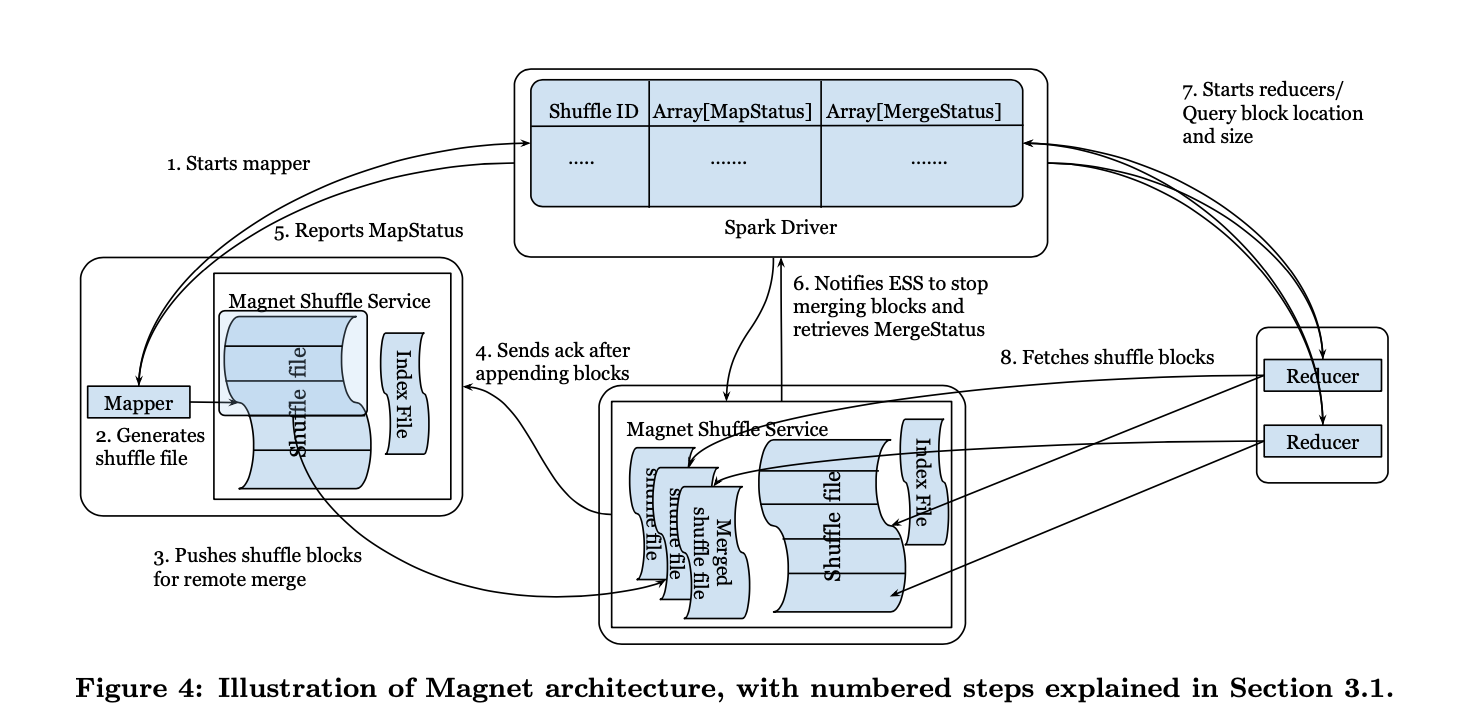
Push Merge Shuffle
Mapper 端的shuffle数据会push到远程的 shuffle service,并按照reduce端合并成一个文件。这样shuffle 文件的大小就可以提高到MB级别。
这里Magnet主要考虑尽可能避免给shuffle service带来过大的压力(为了稳定性和可扩展性考虑),因此在Magent中,在mapper端,依然会将shuffle数据,首先保存到本地,然后再按照以下的算法,将shuffle blocks打包成一个个chunks发送到shuffle service。
计算blocks划分到chunks算法
这个算法的含义如下:
- 按照
![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图9](/uploads/projects/aitozi@blog/eccbad887bb17f3fa9f64e63006a0df7.svg) 计算 第 i 个 reduce 数据所应该发送的shuffle service的下标,
计算 第 i 个 reduce 数据所应该发送的shuffle service的下标,![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图10](/uploads/projects/aitozi@blog/6996d8f58a7db8c01ec8c93d9c6fe874.svg) 表示每台shuffle service机器所需要分配的Reduce task的数量,当其大于 k 时表示需要发送到下一个机器,则更新 k 的值为
表示每台shuffle service机器所需要分配的Reduce task的数量,当其大于 k 时表示需要发送到下一个机器,则更新 k 的值为 k++ - 当chunk长度没有超过限制L,将
![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图11](/uploads/projects/aitozi@blog/d10fd9b0e97eaa62612842b715471740.svg) (长度为
(长度为 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图12](/uploads/projects/aitozi@blog/5e279623cf3f30f9bf6f3e7f8c3e65c7.svg) )append到chunk中,并将chunk长度更新为
)append到chunk中,并将chunk长度更新为 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图13](/uploads/projects/aitozi@blog/bcf4c0f39042600559bd87f84eda640c.svg)
- 当chunk长度超过了限制L,那么就把
![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图14](/uploads/projects/aitozi@blog/ea65f4121960c93ad9c01af17423f425.svg) append 到 下一个 chunk中,并将chunk 长度置为
append 到 下一个 chunk中,并将chunk 长度置为 ![[2022-10-21]Magnet: Push-based Shuffle Service for Large-scale Data Processing - 图15](/uploads/projects/aitozi@blog/158d440dba8739b21d69f1c631aede86.svg) , shuffe service 机器还是为 k。
, shuffe service 机器还是为 k。
算法最终输出的是每个 shuffle service 机器和对应的所需要接收的chunk的集合。
这个算法保证,每个chunks只包含一个shuffle file中连续的不同shuffle partition 的 shuffle blocks。当达到一定大小后会另外创建一个chunk。但是不同mapper上的同一个shuffle parititon的数据最终会路由到同一个shuffle service节点上。
并且为了避免同时mapper端都按照同一顺序往shuffle service 节点写数据造成挤兑和merge时的文件并发锁,所以在mapper端处理chunk的顺序上做了随机化。
在完成打包chunk和随机化之后,就交由一个专门的线程池来将数据从按照chunk顺序从本地磁盘load出来,所以这里就是顺序的读取本地磁盘再push到远程的shuffle service。Push操作是和Mapper端的task解耦的,push操作失败不会影响map端的task。
Magnet Metadata
当magnet收到打包发送来的chunks,首先会根据block的元数据获取他的分区信息,然后根据shuffle service本地维护的元数据做处理,shuffle service本地为每个Shuffle partition (reduce partition)维护了以下元信息
- bitmap 存储了以及merge的mapper的id
- position offset 记录了merge 文件中最近一次成功merge的 offset
- currentMapId 记录了当前正在merge的 mapper的 shuffle block id
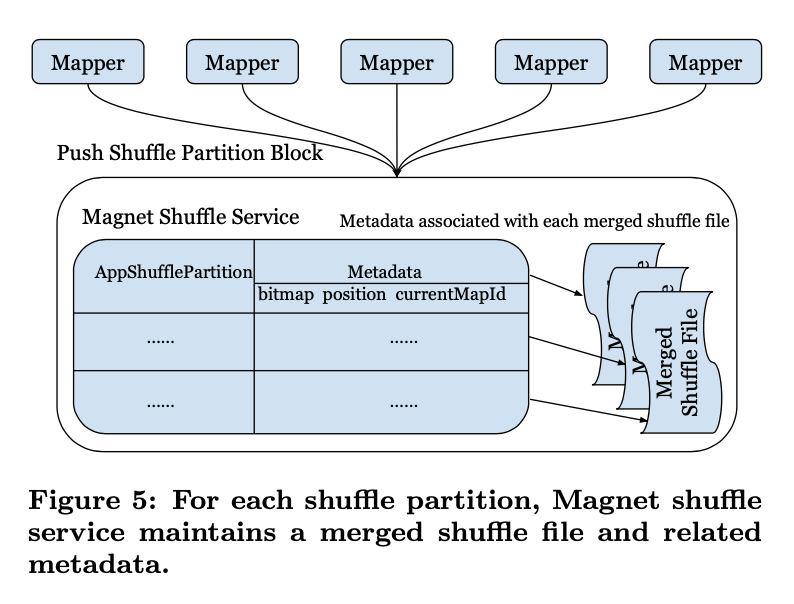
这样首先可以根据发送来的shuffle blocks的元数据判断数据是否已经merge过了,避免重复存储。通过currentMapId来避免多个mapper端数据同时往一个文件merge的问题,而position offset 则可以用作在merge 失败的时候可以依旧保持文件能读到最近一次成功的位置。下一次重写的时候会依旧从position offset进行覆盖写入。通过这几个元数据管理,就可以很优雅的处理在文件merge过程中的写重复,写冲突和写失败的问题。
Best effort
在Magent的设计中,push/merge的失败,并不会影响整个任务的流程,可以fallback到读取mapper端未merge的数据。
- 如果map task 在写入本地shuffle数据完成之前失败了,那么map端task会进行重跑
- 如果map端push/merge失败,那么这部分数据就会直接从mapper端读取
- 如果reduce fetch merge block失败,那么也会fallback到从mapper端读取
我理解要实现这样的目的,原始数据就需要被保留,所以可以看到在架构图中Magent Shuffle Service实际上会和executor一起部署(还支持其他的部署形式)。在executor端作为external shuffle service的角色存在,mapper端的数据产出完之后就由本地的shuffle service 节点托管了。所以他可以在以上2、3两种失败场景下提供fallback的读取能力。
同时数据是否Merge完的信息是在Spark Driver中通过MapStatus和 MergeStatus两个结构来进行维护的,下游读取数据时就是由driver来进行是否fallback的逻辑。
从整体上看Push/Merge 的操作可以理解为完全由Magent Shuffle Service节点托管的数据搬迁合并的动作(将各个mapper处的数据搬迁合并成redcuer端的数据),通过数据写两次的行为使得mapper端写数据和合并解耦,并且在fault tolerance的设计中也利用了写两次这个行为所带来的备份的好处。
同时我们需要关注到虽然通过这个操作,将mapper端的随机读取转化成了顺序读取,但是在shuffle service时merge时,其实还是random write,这在数据重组的过程中是必然的。但是由于os cache 和 disk buffer的存在,会使得random write的吞吐比random read的吞吐大很多。
Flexible Deployment Strategy
Magnet支持两种模式的部署
- on-perm 表示和Spark计算集群一起部署,作为external shuffle service的方式存在。
- cloud-based 表示以存算分离的模式部署,这样就是以Remote shuffle service的方式部署。
在on-perm的集群中,Spark driver可以很好的利用data locality的特性,在push/merge节点结束后,可以将reduce task尽可能调度到数据所在的节点上,可以直接读取本地数据,效率更高,减少了网络的传输也不容易失败。
Handling Stragglers and Data Skews
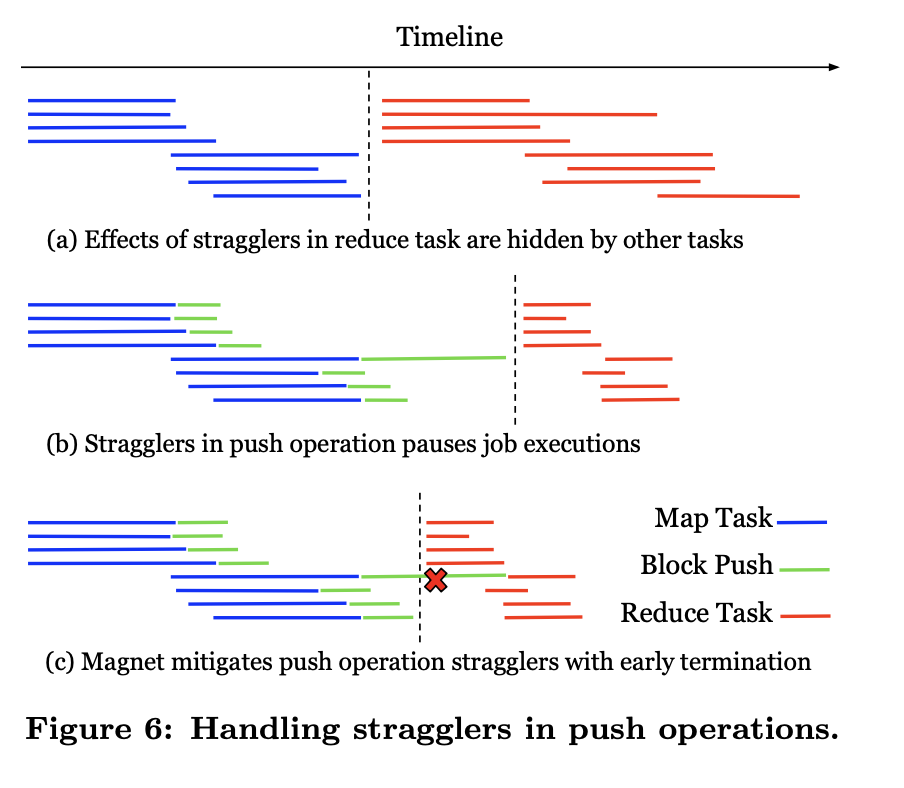
因为Spark计算引擎是BSP模型,所以在map端阶段全部完成之前reduce端不会开始计算,因此在Push/Megre阶段,为了防止部分Push/Merge较慢影响下游reduce task开始执行。Magnet支持了最大的超时机制,利用上面提到的fallback行为,在超时之后就标记该map端的分区为unmerged,这样就跳过了这部分慢节点,直接开始reduce阶段。
而针对数据倾斜场景,为了避免reduce端合并的文件过大,这时Magent的解法是和Spark的Adaptive execution 相结合,根据运行时采集到的每个block的大小,当block 大于某个阈值时,就在合并chunk的阶段跳过这种block,还是通过fallback行为直接读取原来mapper端较大的数据块
Parallelizing Data Transfer and Task Execution
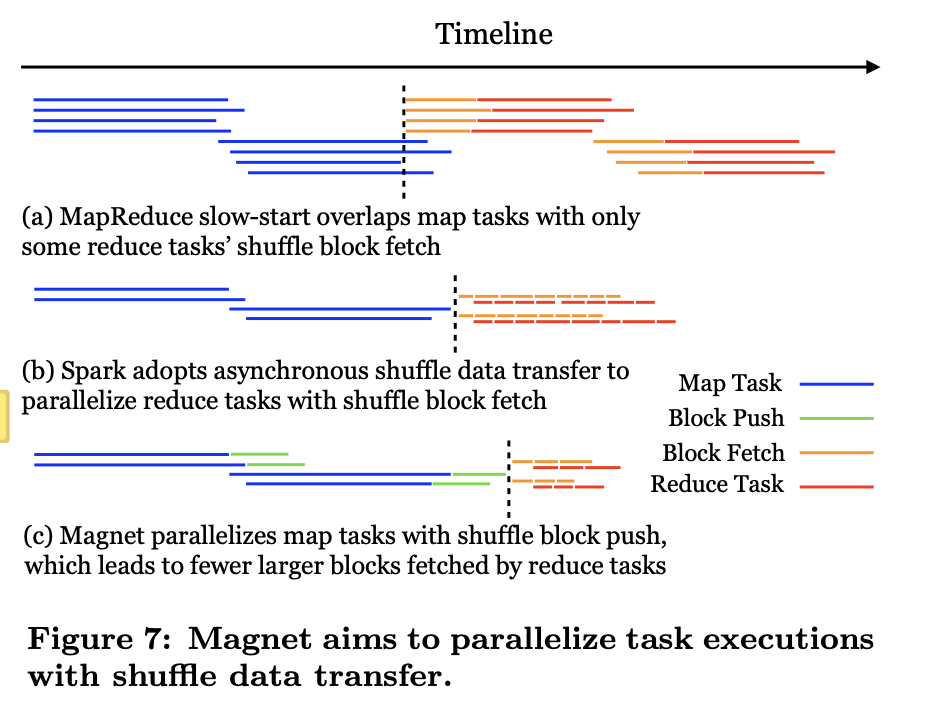
在Hadoop的Map-Reduce模型中,通过 “Slow start” 技术可以在Map task都完成之前,部分Reduce task可以先开始进行数据预拉,实现了比较有限的并行化
而在Spark中,通过数据拉取和数据处理的线程解耦,这两者有点类似于一组生产者和消费者。
而在Magnet中也采用了类似的技术,在mapper端Push task 和 mapper task解耦,但是这里不太理解这个mapper端解耦的收益,因为本身就是在mapper task结束之后才开始进行push task,也就不存在计算线程和io线程并行的说法。可以理解的是可以通过这个方式和mapper task的框架线程解耦。
然后在reduce端,为了最大化并行读取的能力,不会将reduce端的数据只合并成一个文件,而是切成多个MB大小的slice,然后reduce task可以发起并行读取的请求最大化的提高吞吐。
小结
从上面可以看出Magent的几个设计宗旨
- 尽可能的避免给shuffle service 增大负载
- 所有的排序的动作只会发生在mapper端或者reducer端,所以排序占用的资源是executor节点的
- merge时不会有数据buffer的动作,数据buffer在executor端完成,在Shuffle Service侧只要直接进行数据appen。
- 尽力而为,数据备份读取提供更好的容错特性。并很好的利用了这两份数据做了更多的设计
- 尽管如今普遍都是存算分离的架构,但是在Magent的设计中data locality的特性还是占据的很重要的位置
How to evaluate
很多系统设计最后对于系统的测试设计其实也很有看点。在论文里提到了Magent采用了模拟和生产集群两个模式来最终衡量新的Shuffle Service的效果。
Magnet 开发了一个分布式的压测框架,主要可以模拟以下几个维度
- 模拟shuffle service集群所会创建的总的连接数
- 每个block块的大小
- 总的shuffle的数据量
并且可以模拟fetch和push的请求
- fetch请求会从一个Shuffle serice节点将block发送到多个客户端
- push请求会从多个客户端将数据发送到一个shuffle service节点
那衡量的指标有哪些
- 在不同的block大小下, Magnet完成Push Merge和Reduce fetch的时间已经Spark 原生Shuffle Service完成fetch的时间比较
- Disk IO 衡量在fetch 和 push的场景下,不同的block大小对于磁盘吞吐能力的影响
- Shuffle Service的资源开销 主要是测试单机的shuffle service,这里看到一个比较惊奇的数据,在测试的过程中的资源消耗为0.5c 300M,开销的确很小。
其他的指标数据就不一一列举了,可以查看原文相关章节获取
最后上线后的优化效果
Figure 1: Shuffle locality ratio increase over past 6 months

参考
https://mp.weixin.qq.com/s/8Fhn24vbZdt6zmCZRvhdOg Magent shuffle 解读
https://zhuanlan.zhihu.com/p/397391514 Magnet shuffle解读
https://zhuanlan.zhihu.com/p/67061627 spark shuffle 发展
https://mp.weixin.qq.com/s/2yT4QGIc7XTI62RhpYEGjw
https://mp.weixin.qq.com/s/2yT4QGIc7XTI62RhpYEGjw
https://www.databricks.com/session_na21/magnet-shuffle-service-push-based-shuffle-at-linkedin
https://issues.apache.org/jira/browse/SPARK-30602
https://www.linkedin.com/pulse/bringing-next-gen-shuffle-architecture-data-linkedin-scale-min-shen

若有收获,就点个赞吧
0 人点赞
