这是Facebook在FlinkForward2021上的一个talk, 主题如下
在前面的论文中分析了Facebook的实时计算引擎的设计和选型的考量,里面提到了Facebook的实时计算引擎为了满足易用性和性能不同维度的需求,研发了多套实时计算系统如Puma``Stylus``Swift分别使用SQL,C++,Swift来进行研发。但是多套引擎也带来了很多问题,可选择的引擎太多,不同的引擎的功能重叠,对用户和对于引擎维度都有很大的成本。为了能让用户获得一致性的体验,其内部选择将多套引擎整合成一套也就是XStream。 
XStream架构分层
他有以下的一些特点
- 基于
Stylus的一个Native C++的执行引擎 - 基于统一的SQL语言,统一的流,批,交互式的查询语言
- 使用解释执行而不是编译执行的模式
- 和presto/spark 共享使用了向量化的SQL执行引擎


SQL上使用标准的SQL2016的语法和Presto统一,并且做了Multi-tumble 和 Mulit-slide window的拓展工作
编译执行的方式就是根据SQL生成的AST tree进行codegen,然后进行编译执行。编译执行的坏处主要是
- 每个pipeline都会生成一个binary文件
- scale up down不友好
- 依赖问题
- 编译时间较长
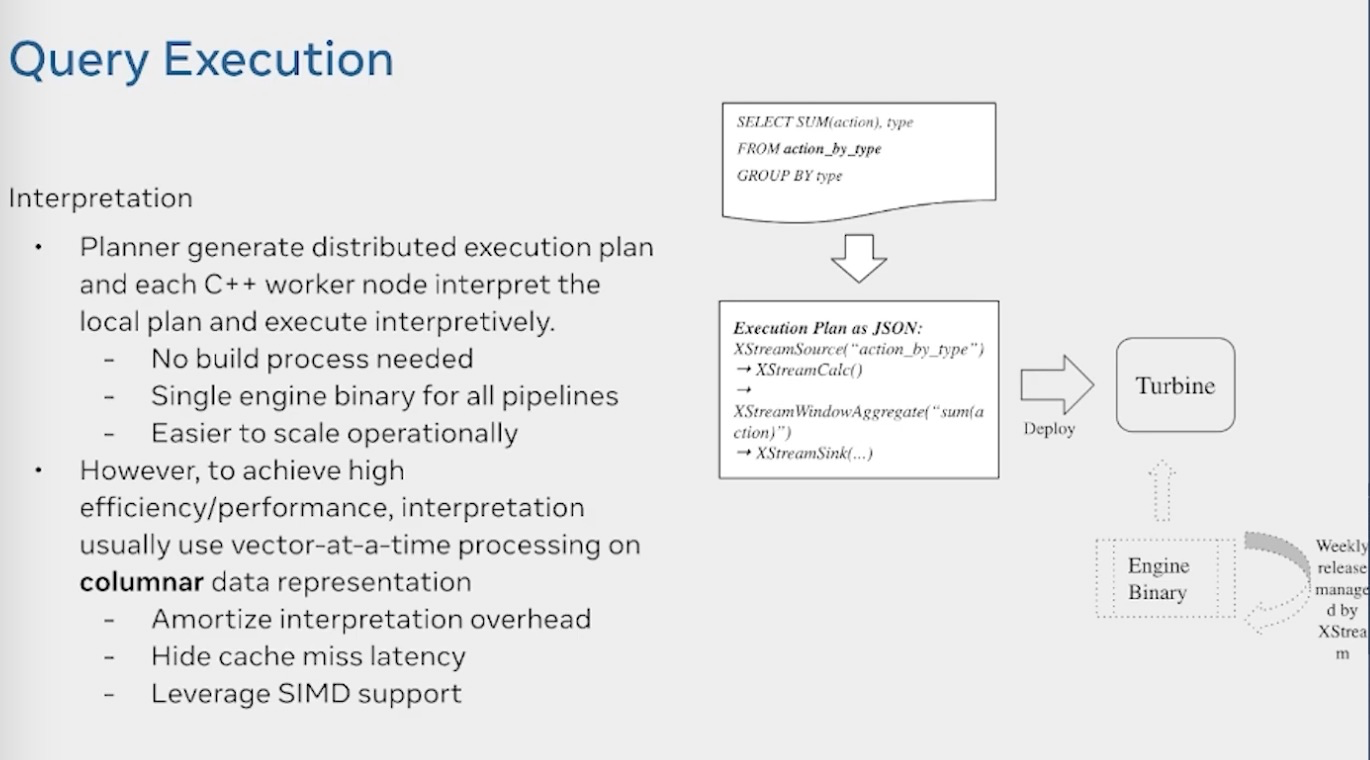
最终他们采用的是解释执行的模式。由C++ worker解释执行,一个作业只有一个binary,但是解释执行的效率肯定没有编译执行的效率高,因此他们使用了以下手段来提速
- 使用列式存储+向量化处理模式
- 利用simd指令加速

向量化提速用到了最近新起的velox的项目,它是一个C++向量化的SQL执行引擎,由Facebook开源,并在其内部用于Presto和Spark以及XStream的统一的运行时向量化加速,velox相关的可以参看这篇文章 Velox: 现代化的向量化执行引擎 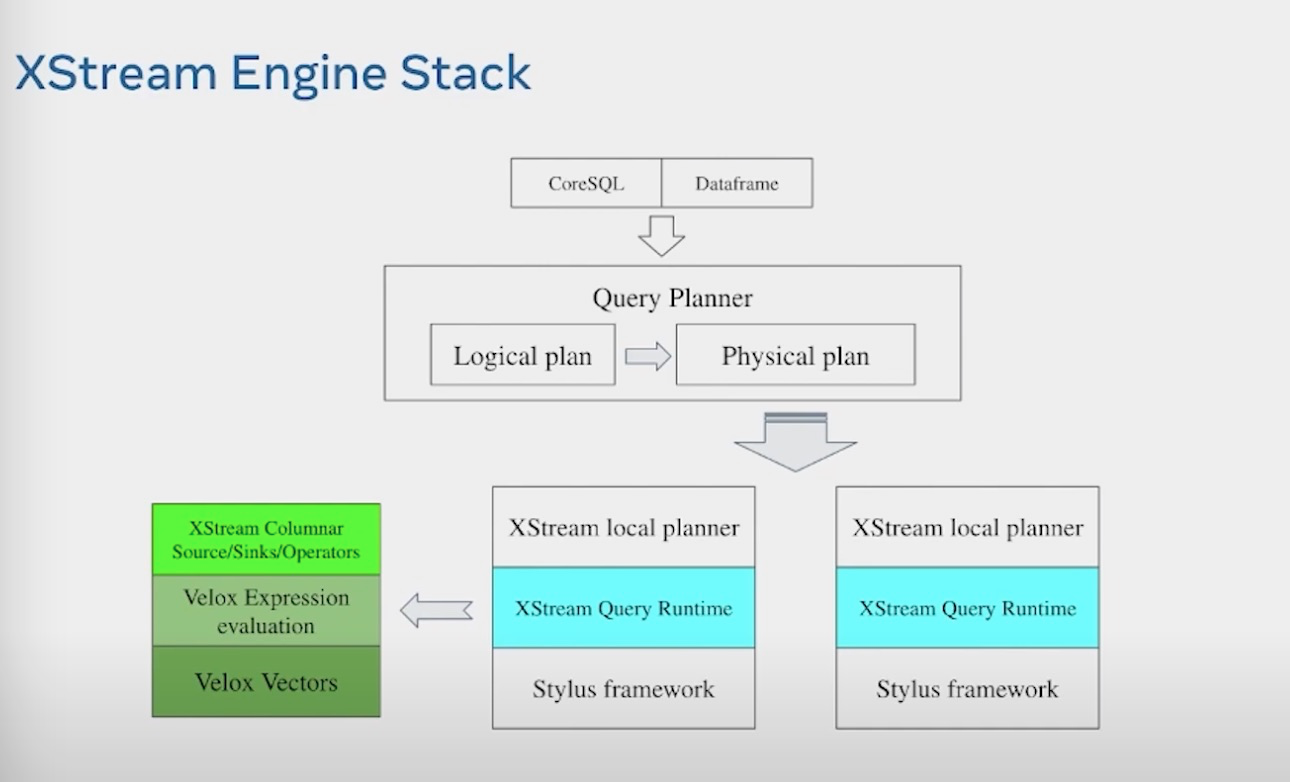
整体的XStream架构,提供CoreSQL和DataFrame两套api,编译成LogicalPlan和Physical Plan。然后分发到local worker进行处理。Local planner将其翻译成XStream operator, 然后利用Velox 来进行加速处理

Velox和XStream 编译型和解释型的对比数据
参考
https://www.youtube.com/watch?v=DNI54vc1ALQ&t=1158s&ab_channel=FlinkForward

若有收获,就点个赞吧
0 人点赞
