中心性算法(Centrality Algorithms)用于识别图中特定节点的角色及其对网络的影响。中心性算法能够帮助我们识别最重要的节点,帮助我们了解组动态,例如可信度、可访问性、事物传播的速度以及组与组之间的连接。尽管这些算法中有许多是为社会网络分析而发明的,但它们已经在许多行业和领域中得到了应用。
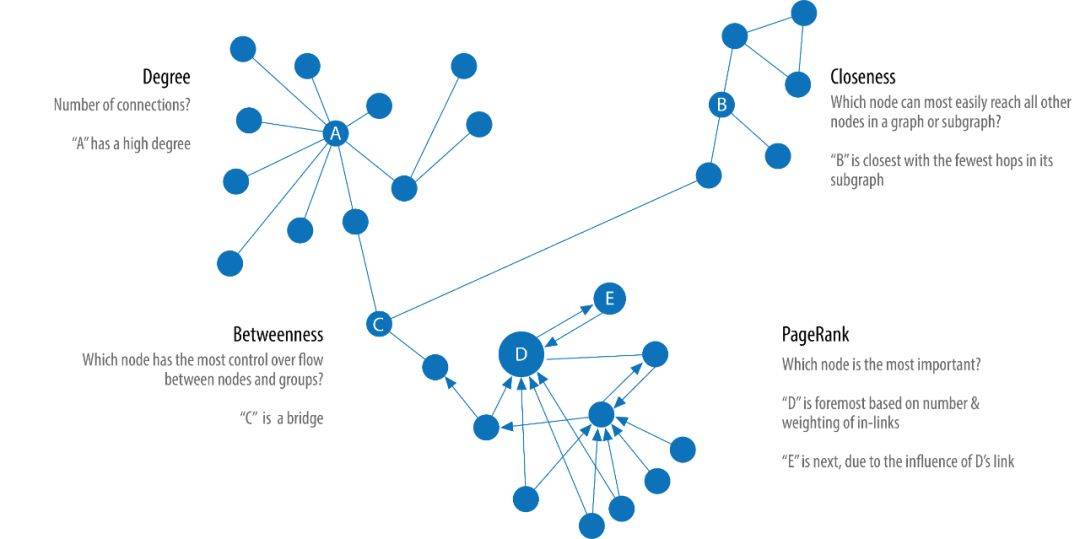
Degree Centrality
Degree Centrality (度中心性,以度作为标准的中心性指标)可能是整篇博文最简单的 “算法” 了。Degree 统计了一个节点直接相连的边的数量,包括出度和入度。Degree 可以简单理解为一个节点的访问机会的大小。例如,在一个社交网络中,一个拥有更多 degree 的人(节点)更容易与人发生直接接触,也更容易获得关注。
一个网络的平均度(average degree),是边的数量除以节点的数量。当然,平均度很容易被一些具有极大度的节点 “带跑偏” (skewed)。所以,度的分布(degree distribution)可能是表征网络特征的更好指标。
如果你希望通过出度入度来评价节点的中心性,就可以使用 degree centrality。度中心性在关注直接连通时具有很好的效果。应用场景例如,区分在线拍卖的合法用户和欺诈者,欺诈者由于尝尝人为太高拍卖价格,拥有更高的加权中心性(weighted centrality)。
Closeness Centrality
Closeness Centrality(紧密性中心性)是一种检测能够通过子图有效传播信息的节点的方法。紧密性中心性计量一个节点到所有其他节点的紧密性(距离的倒数),一个拥有高紧密性中心性的节点拥有着到所有其他节点的距离最小值。
对于一个节点来说,紧密性中心性是节点到所有其他节点的最小距离和的倒数: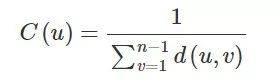
其中 u 是我们要计算紧密性中心性的节点,n 是网络中总的节点数,d(u,v) 代表节点 u 与节点 v 的最短路径距离。更常用的公式是归一化之后的中心性,即计算节点到其他节点的平均距离的倒数,你知道如何修改上面的公式吗?对了,将分子的 1 变成 n-1 即可。
理解公式我们就会发现,如果图是一个非连通图,那么我们将无法计算紧密性中心性。那么针对非连通图,调和中心性(Harmonic Centrality)被提了出来(当然它也有归一化的版本,你猜这次n-1应该加在哪里?):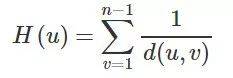
Wasserman and Faust 提出过另一种计算紧密性中心性的公式,专门用于包含多个子图并且子图间不相连接的非连通图: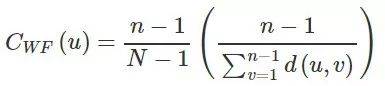
其中,N 是图中总的节点数量,n 是一个部件(component)中的节点数量。
当我们希望关注网络中传播信息最快的节点,我们就可以使用紧密性中心性。
Betweenness Centrality
中介中心性(Betweenness Centrality)是一种检测节点对图中信息或资源流的影响程度的方法。它通常用于寻找连接图的两个部分的桥梁节点。因为很多时候,一个系统最重要的 “齿轮” 不是那些状态最好的,而是一些看似不起眼的 “媒介”,它们掌握着资源或者信息的流动性。
中介中心性算法首先计算连接图中每对节点之间的最短(最小权重和)路径。每个节点都会根据这些通过节点的最短路径的数量得到一个分数。节点所在的路径越短,其得分越高。计算公式: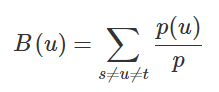
其中,p 是节点 s 与 t 之间最短路径的数量,p(u) 是其中经过节点 u 的数量。下图给出了对于节点 D 的计算过程: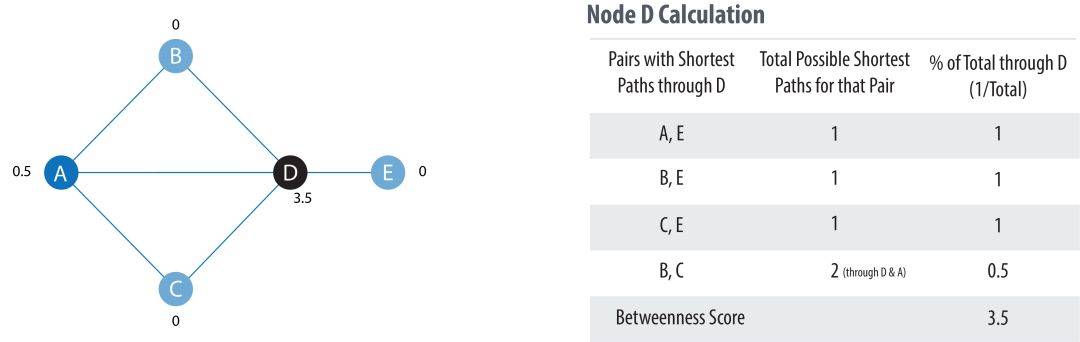
当然,在一张大图上计算中介中心性是十分昂贵的。所以我们需要更快的,成本更小的,并且精度大致相同的算法来计算,例如 Randomized-Approximate Brandes。我们不会对这个算法继续深入,感兴趣的话,可以去了解一下,算法如何通过随机(Random)和度的筛选(Degree)达到近似的效果。
中介中心性在现实的网络中有广泛的应用,我们使用它来发现瓶颈、控制点和漏洞。例如,识别不同组织的影响者,他们往往是各个组织的媒介,例如寻找电网的关键点,提高整体鲁棒性。
PageRank
在所有的中心性算法中,PageRank 是最著名的一个。它测量节点传递影响的能力。PageRank 不但考虑节点的直接影响,也考虑 “邻居” 的影响力。例如,一个节点拥有一个有影响力的 “邻居”,可能比拥有很多不太有影响力的 “邻居” 更有影响力。PageRank 统计到节点的传入关系的数量和质量,从而决定该节点的重要性。
PageRank 算法以谷歌联合创始人拉里·佩奇的名字命名,他创建了这个算法来对谷歌搜索结果中的网站进行排名。不同的网页之间相互引用,网页作为节点,引用关系作为边,就可以组成一个网络。被更多网页引用的网页,应该拥有更高的权重;被更高权重引用的网页,也应该拥有更高权重。原始公式: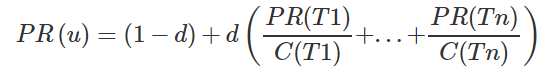
其中,u 是我们想要计算 PageRank 的网页,T1 到 Tn 是引用的网页。d 被称为阻尼系数(damping factor),代表一个用户继续点击网页的概率,一般被设置为 0.85,范围 0~1。C(T) 是节点 T 的出度。
从理解上来说,PageRank 算法假设一个用户在访问网页时,用户可能随机输入一个网址,也可能通过一些网页的链接访问到别的网页。那么阻尼系数代表用户对当前网页感到无聊,随机选择一个链接访问到新的网页的概率。那么 PageRank 的数值代表这个网页通过其他网页链接过来(入度,in-degree)的可能性。那你能如何解释 PageRank 方程中的 1-d 呢?实际,1-d 代表不通过链接访问,而是随机输入网址访问到网页的概率。
PageRank 算法采用迭代方式计算,直到结果收敛或者达到迭代上限。每次迭代都会分两步更新节点权重和边的权重,详细如下图: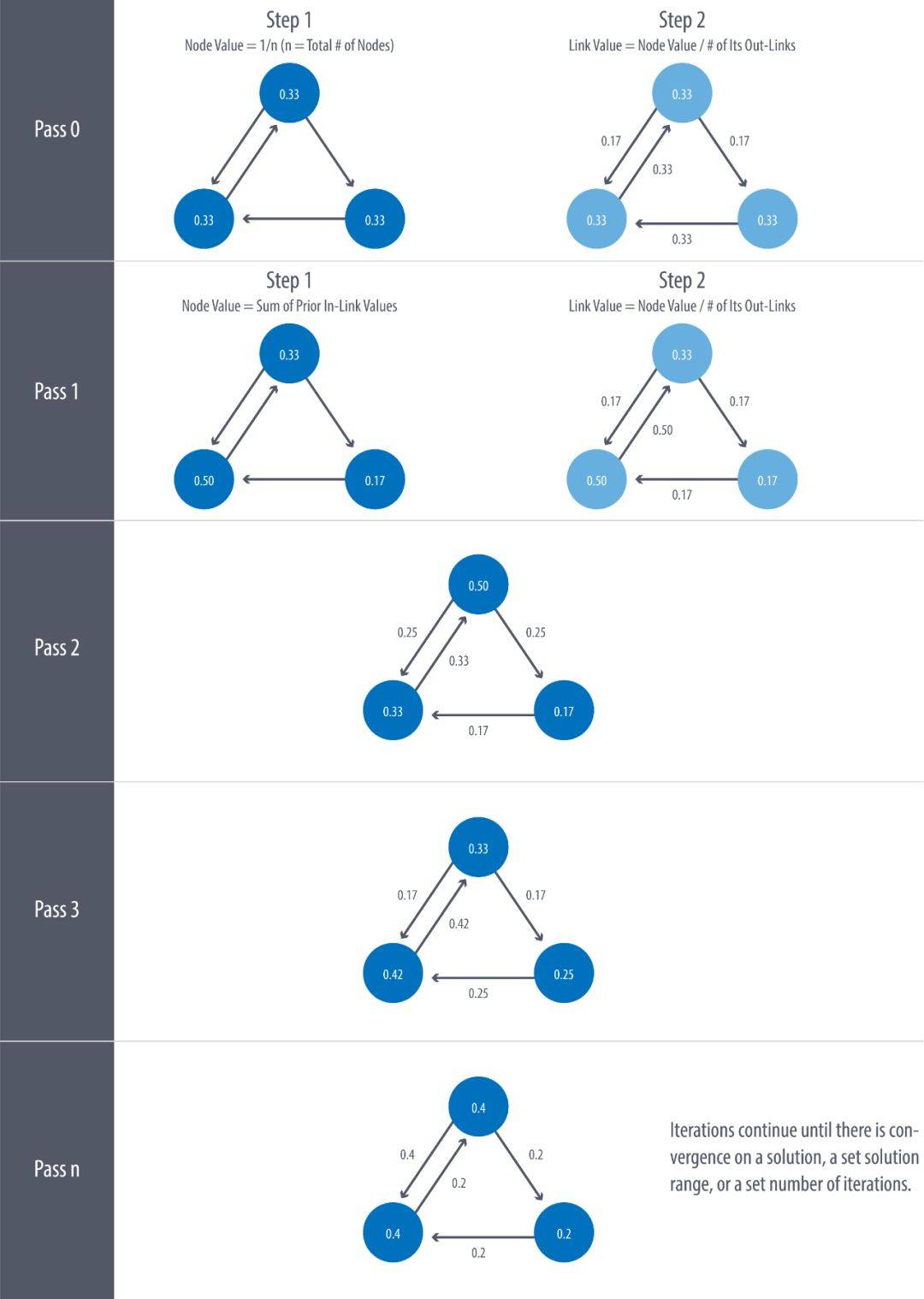
当然,上图的计算并没有考虑阻尼系数,那为什么一定要阻尼系数呢?除了我们定义的链接访问概率,有没有别的意义呢?从上图的过程中,我们可能会发现一个问题,如果一个节点(或者一组节点),只有边进入,却没有边出去,会怎么样呢?按照上图的迭代,节点会不断抢占 PageRank 分数。这个现象被称为 Rank Sink,如下图:
解决 Rank Sink 的方法有两个:
- 第一个,假设这些节点有隐形的边连向了所有的节点,遍历这些隐形的边的过程称为 teleportation;
- 第二个,使用阻尼系数,如果我们设置 d 等于 0.85,我们仍然有 0.15 的概率从这些节点再跳跃出去。
尽管阻尼系数的建议值为 0.85,我们仍然可以根据实际需要进行修改。调低阻尼系数,意味着访问网页时,更不可能不断点击链接访问下去,而是更多地随机访问别的网页。那么一个网页的 PageRank 分数会更多地分给他的直接下游网页,而不是下游的下游网页。
PageRank 算法已经不仅限于网页排名。例如:
- 寻找最重要的基因:我们要寻找的基因可能不是与生物功能联系最多的基因,而是与最重要功能有紧密联系的基因;
- who to follow service at twitter:Twitter使用个性化的 PageRank 算法(Personalized PageRank,简称 PPR)向用户推荐他们可能希望关注的其他帐户。该算法通过兴趣和其他的关系连接,为用户展示感兴趣的其他用户;
- 交通流量预测:使用 PageRank 算法计算人们在每条街道上停车或结束行程的可能性;
- 反欺诈:医疗或者保险行业存在异常或者欺诈行为,PageRank 可以作为后续机器学习算法的输入。

若有收获,就点个赞吧
0 人点赞
