论文地址:https://arxiv.org/pdf/1709.03188.pdf 原文地址:https://mp.weixin.qq.com/s/SllWrfbDDCSgzS2VwLDwRQ
简介
图处理在许多应用领域越来越流行,但是关于在实践中图如何使用的研究较少。
文章做了扩展调查,包括:89 位用户的在线调查,对大量图软件产品的邮件列表、源代码库、白皮书的调研以及对这些产品的六位用户和两名开发者的个人访谈。
在线调查主要为了回答四大问题:
- 用户所有的图数据的类型;
- 用户运行的图计算;
- 用户使用的图软件类型;
- 用户在处理图时所面临的挑战。
主要发现:
- Variety:各种各样的图在实践中涵盖了各种各样的实体,一些适用于关系型数据库的传统企业数据比如产品、订单、交易等成了参与者图中常见的数据形式;
- Ubiquity of very large graphs:实践中,许多图非常大,通常包含超出 10 亿条边,不只是大型企业,很多小企业也拥有大规模的图数据;
- Challenge of scalability:可扩展性是目前面临最紧迫的挑战,现有软件最大的局限性就在于高效处理大图的能力;
- Visualization:可视化是在图处理流程中十分流行且处于中心位置的任务,是用户及扩展性挑战之后第二紧迫的挑战,这常常与查询语言挑战联系在一起;
- Prevalence of RDBMses:目前关系型数据库在图数据管理与处理中还充当着重要的角色。
调查方法
调查问卷形式:
- 多项选择(Multiple-choice)
- 简短答案(Short-answer)
共 34 道题分为 6 大类:
- 人口统计问题
- 图数据集
- 图计算与机器学习
- 图软件
- 主要挑战
- 工作任务分解
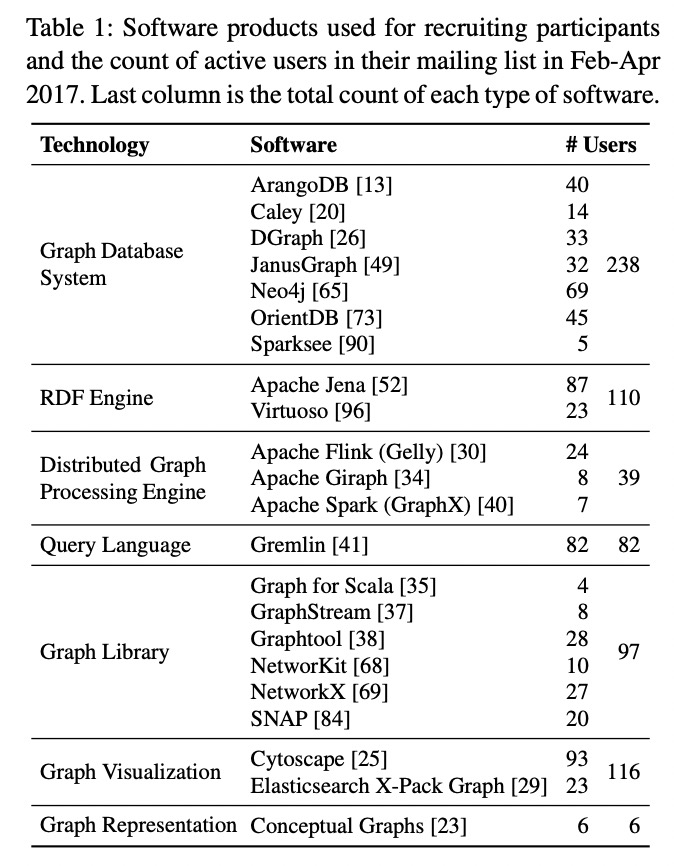
参与者招募:
- 来自于 22 款常用图处理软件的公共用户邮件列表,尽可能全面的招募来自不同图技术领域的用户
- 通过发邮件等方式招募 89 名参与者
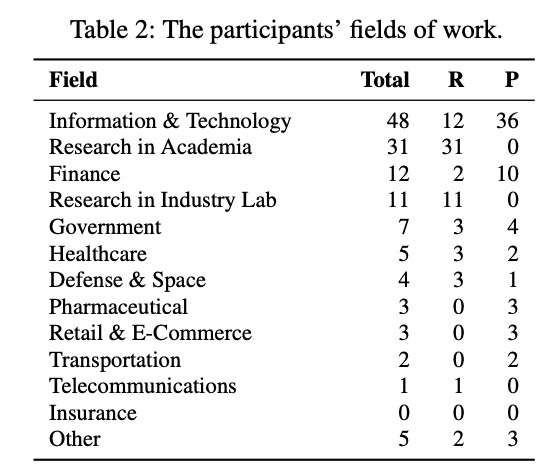
- 参与者主要分布于学术界(36)和工业界(53)的 17 个领域
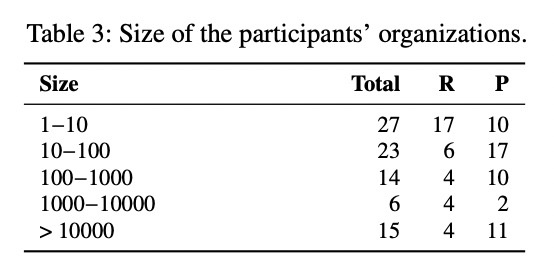
- 参与者所供职企业的规模从几人到上万人不等
- 参与者中多为工程师、研究者、数据分析师、经理,也有少部分的叫架构师、运维人员和学生
Review
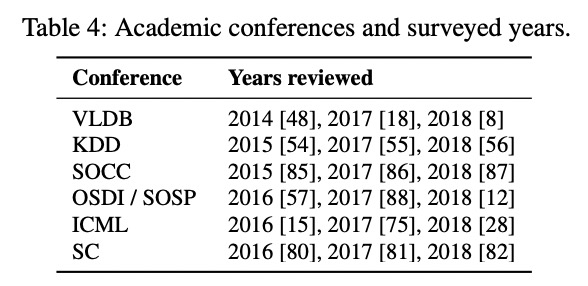
学术刊物调研:
- 调查了 7 个学术会议中三年的图处理相关论文;
- 这些会议具体涉及领域包括:数据库、数据挖掘、机器学习、操作系统、高性能计算与云计算,选择这些会议中直接研究图计算或者是开发图处理软件的文章,最终选择了 252 篇论文;
- 对于这些论文,文章统计了:
- 实验使用的图数据集
- 论文中出现的图与机器学习计算
- 论文中使用的图软件
邮件与代码仓库调用:
- 为了解决参与者回答中产生的一些问题,进一步确定用户面临的具体挑战,文章调查了:
- 22 款软件产品
- 20 款开源软件代码库
- 图可视化工具 Gephi、GraphViz 的 email 和 issue
- 在调查的超过 6000 封 email 和 issue 中,大多是关于较难的工程性任务,其中 299 封有助于确定图处理面临的挑战。
图数据集
真实世界实体表示
调查参与者使用的图数据集所涉及的实体分为以下几类:
- 人类:职工、顾客以及这些实体之间的交互
- 非人类实体:产品、交易、网页等 7 大类 52 种
- RDF 或者语义网
- 科学实体:化学分子或生物蛋白质
两大发现:
- 种类(Variety):实际应用中的图数据涵盖了各种实体,不局限于能想到的社交网络、基建网络、地图等
- 产品图(Products graphs):产品-订单-交易 是工业场景中最常见的图数据实体,尽管这些实体十分适用于关系型数据库,但是企业能够在其关联中分析价值,另外,科学实体在学界和业界都有广泛应用。
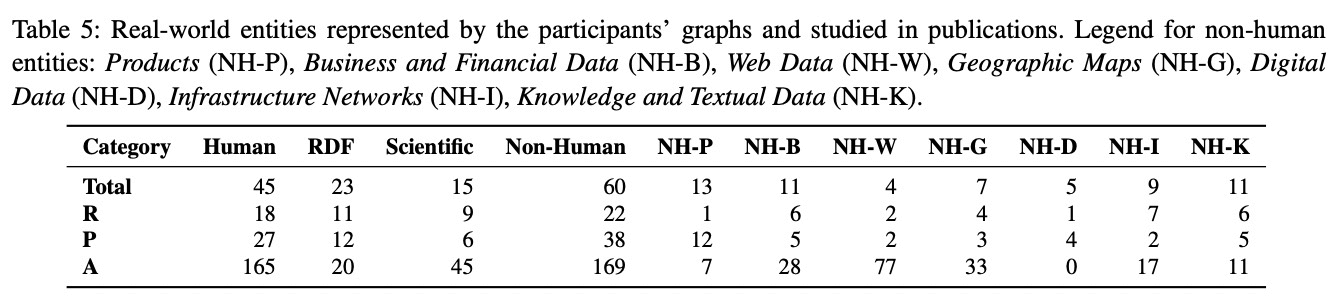
图数据规模
通过调查参与者图数据的规模指标,发现了大图的普遍性:
- 大量的参与者使用了大规模的图
- 并不是只有大型组织使用超大图,小规模组织同样会有大图
- 这些大图涉及了多个领域,表示了各种各样的实体
- 对多于 1B 条边的参与者进一步调查发现 7 个用户的图中边的规模超过了千亿,这些大图表示了产品交易以及金融、农业等领域的实体
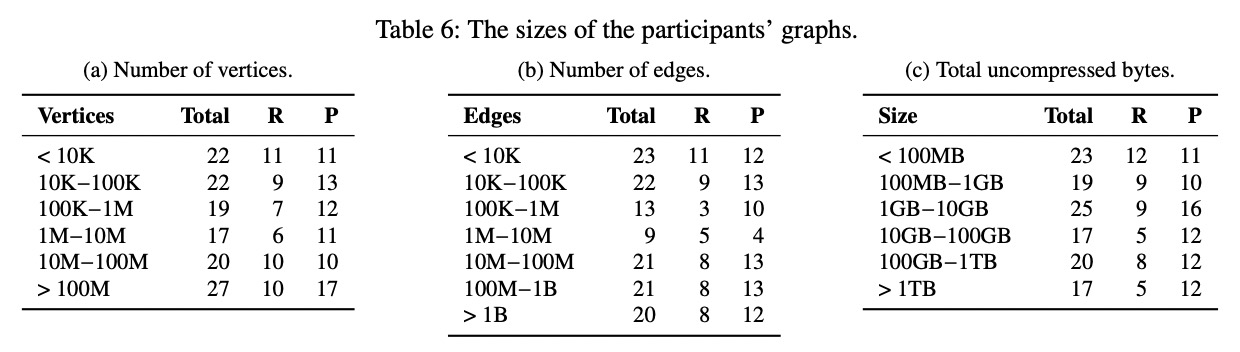

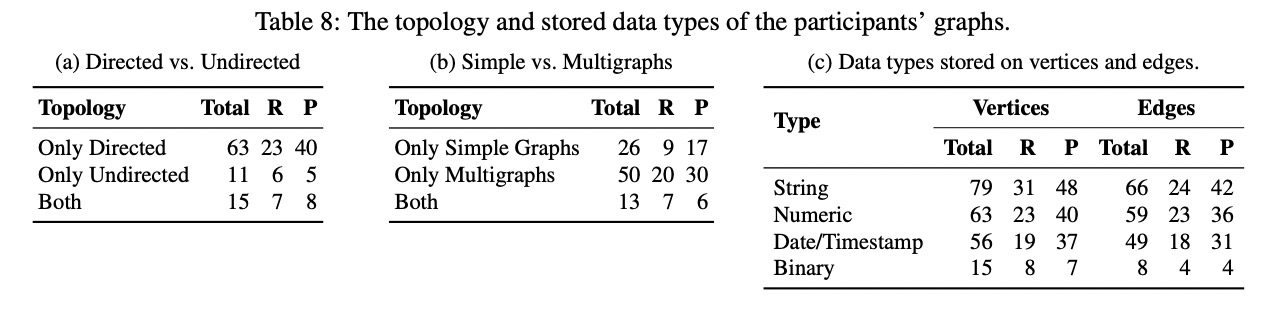
图数据其他问题
拓扑结构:
- 有向图、无向图
- 简单图、多重图
节点与边存储数据类型:
- 字符串
- 数值型
- 日期或时间戳
- 二进制
- 其他:JSON、list、地理坐标等
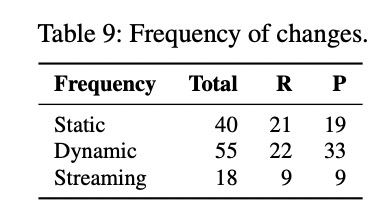
动态性:
- 静态数据
- 动态数据
- 流数据
计算
图计算
通过调查所有 13 中图计算在从业者和研究者中都被使用过,并且除了邻居查询和可达性查询,其他算法在参与者和学术初版物中的流行程度相当。
连通分量查找算法尤其是在从业者中十分流行,该算法可能是大部分任务中移除离群点或边的预处理或者清洗步骤。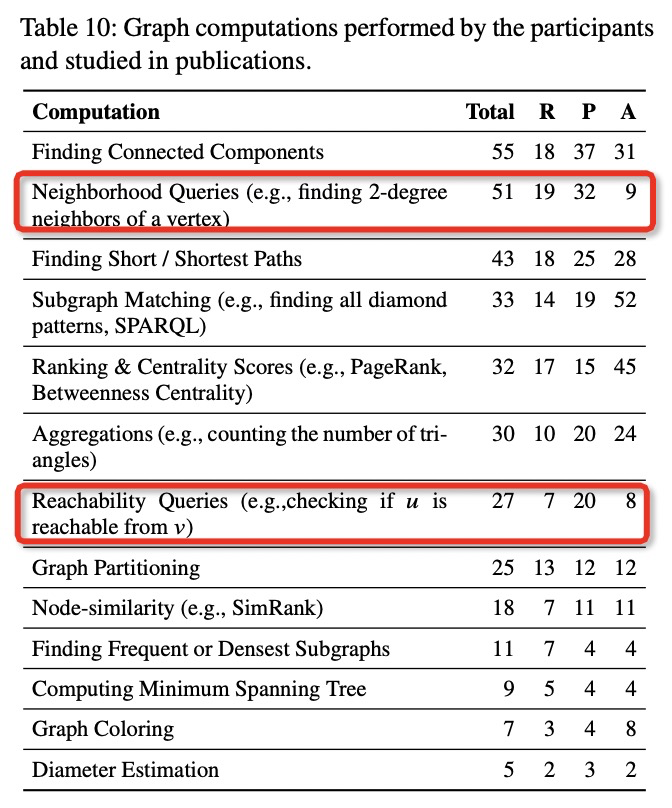
机器学习计算
机器学习在图数据上应用十分广泛,其中,聚类最为常用,使用机器学习解决的最为普遍的问题是社区检测。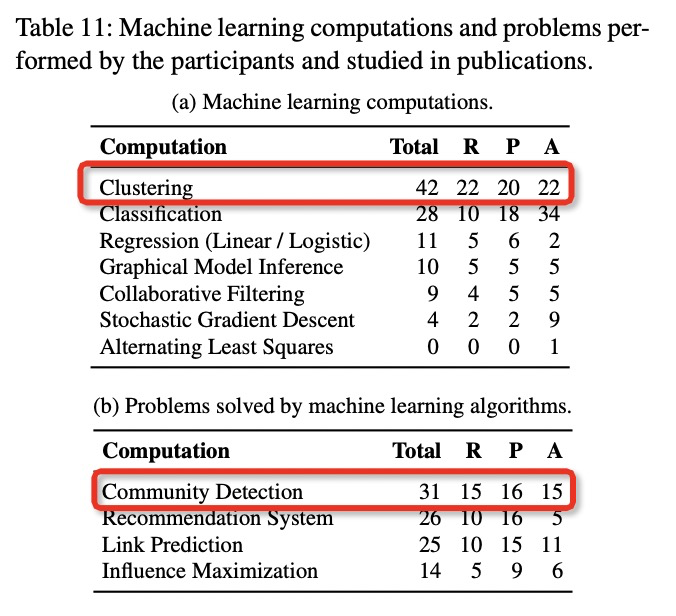
其他计算问题
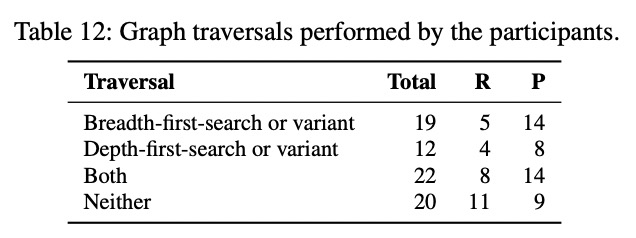
流计算,共 32 个参与者进行过流计算或增量计算,4 名参与者使用的计算为图或节点级别的统计和聚合操作,3 名使用近似连通分量、k-core 的增量或流计算。
图软件
软件类型
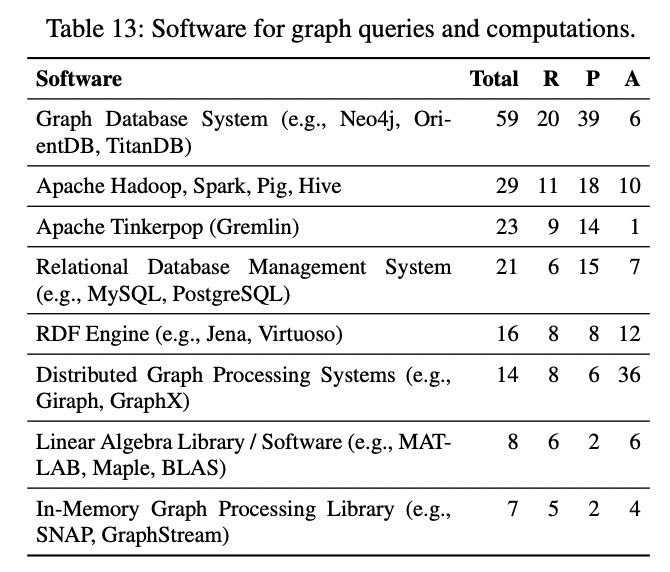
图查询与图计算软件:
- 图数据库系统十分流行
- RDBMS 十分流行
- DGPS 在工业界应用并不广泛
非查询任务软件:
- 图可视化是一项非常常见且非常重要的任务
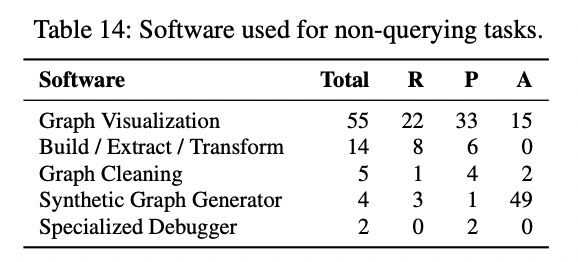
其他软件问题
软件架构方面,用户的选择与其拥有的图规模相关,分布式对应着大规模的图数据是最受欢迎的选择,其他的架构还有单机并行和单机串行。
多格式数据存储,33 名受访者采用多形式存储图数据,最常用的是关系型数据库和图数据库结合。
实际挑战
调查发现的挑战
通过调查,发现主要存在以下挑战:
- 可扩展性:在大图上加载或更新数据以及执行图计算效率较低
- 可视化
- 查询语言与 API:具体挑战包括查询语言的表达能力、与标准的一致性、与现有系统 API 的集成。

审查发现的挑战
通过对调查结果的审查,发现还存在图数据库系统与 RDF 引擎对接、图可视化软件、查询语言、分布式图处理系统和库等方面的挑战。
图数据库系统与 RDF 引擎:
- High-degree 节点:用户系统以特殊方式处理这些节点,比如在遍历时跳过经过这些节点的路径
- 超边:超边可表示多元关系,在图数据库系统或 RDF 引擎中没有原生的超边表示方法
- 版本和历史分析:用户希望能存储变更历史从而支持边和节点的多版本间的分析
- 模式与约束:用户希望在图上定义模式作为数据约束,比如无环图限制、节点特定属性约束等
- 触发器:用户希望图数据库能具备触发器功能
图可视化软件:
- 可定制性:自定义渲染图布局和设计的能力
- 布局:常见挑战是画出用户心中所想的特定布局
- 动态图可视化:动态表示节点的删除、添加和更新
- 大型图的渲染
查询语言:
- 子查询:查询的表达能力以及性能,一个查询作为另一个查询的一部分,如将 SQL 嵌入到 SPARQL 中
- 多个图之间的查询:如使用一个图中的遍历结果开始另一个图中的遍历,类似于关系型数据库中的多表查询
- 能够对过慢的查询调试分析,使用索引加速
分布式图处理系统和库:
- 现成算法:用户希望能在这些软件中添加可以直接用的现成算法而不是低层次的编程接口,直接使用已实现算法比算法的实现更有价值
- 图生成器:生成不同类型的图如随机正则图或者随机有向幂律图,用以算法测试
- GPU 支持:用户有在 GPU 上运行图算法的需求
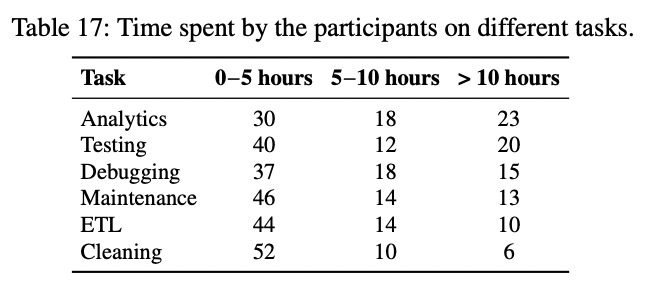
根据调查在六个图处理任务中,参与者工作量的分解情况:
- 在分析测试环节耗时最多
- 在 ETL 和清洗环节耗时较少
白皮书中的应用
白皮书的调查对象共包括 4 款图数据库和 4 款 RDF 引擎:
- 图数据库:ArangoDB、Neo4j、OrientDB、Sparkee;
- RDF 引擎:AllegroGraph、AnzoGraph、GraphDB by Ontotext、Stardog
三大最受欢迎的应用分别是数据集成、个性化推荐和欺诈检测。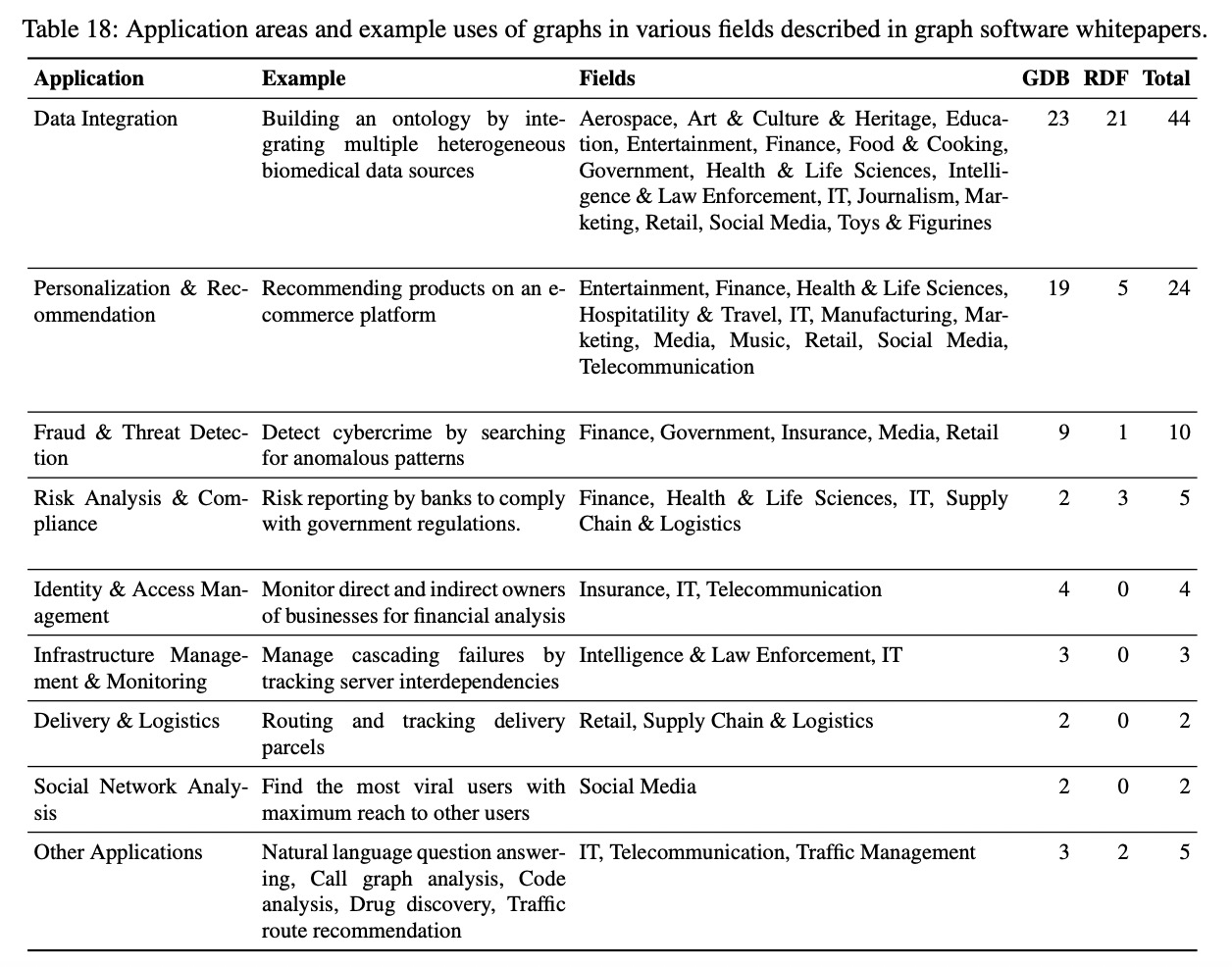
数据集成:
- 也称为主数据管理、知识图谱创建
- 将多源数据构建成统一的异质图
- 白皮书强调客户发现半结构化图模型的数据集成比结构化关系表更容易
个性化推荐:
- 使用基于图的应用数据来个性化用户交互行为,从而为商家的顾客提供更好的推荐服务
欺诈检测:
- 相较于 SQL 查询,一些欺诈模式可以通过子图查询更容易地表达。
面谈中的应用
我们邀请了 8 位受访者进行面谈,其中 4 位来自在线调查参与者,另外 4 位来自邀请,8 位受访者的具体情况:
- 两位大型企业图技术的 IT 咨询师
- 两位大型企业的开发者(Alibaba、Siemens)
- 一位 Amazon 知识图谱首席科学家
- 三位工程师分别来自 FullContact、State Grid、OpenBEL
访谈的具体问题:
- 具体介绍一个使用图数据的业务
- 询问关于使用的图数据、运行的图计算、使用的图软件的细节
- 在哪使用图可视化、是否在图上使用流计算、是否用图进行机器学习计算
通过以上的访问,我们有以下发现:
- 使用图表示事务性业务数据的应用均没有将图数据库或者 RDF 存储作为主要的记录系统。关系型数据库作为主要存储系统,事务数据则是被复制进图软件中进行使用
- 图可视化被用作数据探索、调试、查询公式以及企业展示工具
- 受访者均没有在图上使用流计算,提及的动态图处理是以几小时或者几天为一个窗口,应用中的计算一般为批计算
- 受访者谈及的在图上的机器学习应用主要是提取代表业务实体的节点的特征向量,进而完成一些机器学习预测任务
推荐应用
阿里巴巴电商平台关键词推荐,涉及到大型知识图谱并行遍历寻路并排序。有两大特点:
- 严格的延迟要求:推荐需要在几毫秒之内完成
- 图的规模以及图的生成:最初由其他数据源自动生成的超大规模图谱。
阿里电商平台知识图谱有三种类型的节点,分别是:
- 产品,阿里销售产品的子集,千万量级
- 产品类别,如鞋类、电子产品等
- 概念,指向大量具体和抽象的现实世界实体的总括术语,小部分由企业内部手工编制,一些来自中文百科,大部分是来自用户使用过的搜索关键词,亿级
有两种类型的边,分别是:
- 产品-类别:一般情况,一个产品属于一种类别,千万量级
- 概念-产品、概念-类别:指产品或类别与概念之间的关系,通过分析用户利用关键词搜索并点击购买的行为日志或者对评论文本分析自动生成,并带有指代关系强度的权重,千亿量级
推荐计算,每个用户被标记一些概念表示他们已知的一些属性,由这些属性进行 4-hop 的 BFS 找到新概念,根据路径上边的权重对这些概念赋予相关性权重并加以排序,将其中一些属性返回给用户,整个计算在 4ms 内完成。
自建分布式图数据库,利用分布式键值存储节点和边结构和属性,部分存储在内存中,部分存储于固态硬盘,支持 Gremlin 语言和属性图模型,遍历时使用 Gremlin 遍历接口查询出的路径结果的后续处理有其他自定义语言编写。
西门子自动化系统配置推荐系统,将产品信息与用户行为结合建模成知识图谱,将 KG 存入 RDF 系统中,其中产品信息来自于领域本体同时包含了语义关系和产品架构,过去产品配置信息来自于历史解决方案。使用 KG 而不是关系表存储有以下两个原因:
- 数据模型的灵活性
- KG 更接近用户概念化数据的方式
在推进算法方面,主要包括:
- 给出解决方案中的部分实体,系统(以历史配置方案为基本事实)推荐最可能完成解决方案的产品
- 基于张量分解,行列对应于实体(万级),每个切面对应一种关系
- 张量来自于根据图数据训练的模型
这类应用有两个共同点:子图模式查询和使用图可视化。
阿里巴巴虚假交易检测,主要用于检测平台上商家用于提高排名而发起的虚假交易,主要搜索两种模式:环模式和二分图模式。
环模式:
- Pattern:卖家 P1 付钱给虚假买家 P2 让 P2 购买 P1 产品
- 输入图:包括的数据有阿里商家的金融账户数据以及社交信息
- 技术栈:
- 由 10s 级金融交易数据构建边
- 从内部分布式图数据库中提取必要的邻居
- 在抽取的图中搜索单点特解模式,抽取的图含有百万节点和边,应用延迟约 30s
二分图模式:
- Pattern:大量虚假顾客购买同一个卖家销售的产品集合
- 输入图:包括商家、产品、顾客的图,sells 边连接商家和产品,purchased 连接产品和用户,选择几天内的事务数据,亿级节点、十亿级边
- 技术:使用线下运行的单点自定义构建内存图数据库
- 挑战:
- 在不枚举模式实例的情况下检测节点是该模式的一部分
- 可扩展性,如果要应用在更大时间区间的交易中,需要在数千亿边中寻找模式
其他模式:
- 支付宝赌博活动检测:支付宝账户与支付宝群组构成的近似二分图
- 阿里云网络攻击检测:IP 地址、端口、域名等构成的图,搜索其中的星型模式,对几天内的千亿级边的快照进行搜索。
大型金融机构的欺诈检测应用,搜索模式相当复杂难以详细描述,广义来说是在图中长路径中搜索关联账户,其中靠近这些路径中心的节点具有异常高的事务数量。

若有收获,就点个赞吧
0 人点赞
