本文原创作者:@木暖、 @张绣(xiugang.zxg)

TensorBoard 是 TensorFlow 的一个可视化工具,其中的网络图模块采用分层复合图可视化了机器学习的模型训练的过程 以及 过程中子步骤以方便研究人员观察神经网络训练过程。该布局算法可以用于可视化具有分组信息的有向图。 其目标是将节点根据边的方向布局成带有层次结构的图, 并支持对组节点的子节点进行布局。 如:将存在主/子流程的流程图 按照流程顺序逐层排列。本文会从背景介绍,算法原理,代码分析,组件效果,和应用场景这五个模块重点介绍如何实现这样一个分层复合图的布局。
背景介绍
介绍分层复合图的布局算法之前,首先给出关于分层图,复合图的定义,来帮助我们了解其分层复合图布局算法所要解决的两个核心问题。
分层图是对有向图中的节点根据边的方向分层布局后得到的具有层级结构的图。如下图的第一张图中,节点根据自顶向下的边的指向排列在不同的层级中,能够更加直观的观察到节点之间的序列关系和边的流向。
复合图是指节点存在分组关系的有向图。分组关系的存在导致在布局过程中,需要优先考虑同组节点具有更相近的位置。
分层复合图是同时可视化了分组关系和层级关系的图。可以更直观的展示节点之间的序列关系和组合关系。它的布局算法上所要解决的核心目标是:
- 层级关系直观,且不存在空层;
- 分组关系明确, 在同一分组中的节点需要排列在同一层级,且位置相连 。

相关工作
现有的许多图可视化库都有支持分层复合图的可视化,如 Dagre, Tensorboard Graph, ccNetViz 等。以下是对这几个图可视化库在分层复合图绘制上的性能,布局,空间利用率 以及 组件独立性的调研和对比。
Dagre.js 是一种经典的分层图可视化库。 但底层的 Graphlib 没有考虑分组关系的处理。 Dagre 库的贡献者又加入了 Cluster 的处理, 但空间利用率不高。
TensorBoard 的 Graph 组件是 Google 团队开发的机器学习模型流程的可视化组件,实现了对带有分组信息的有向图的分层绘制。他基于 Dagre 的分层图实现,加入了自己的 hack,具有强大的布局能力,性能,和空间利用率,但缺点是没有公开可复用的独立组件。
算法原理
分层图布局的算法包括三个核心步骤,节点分层,层内节点排序,和坐标优化。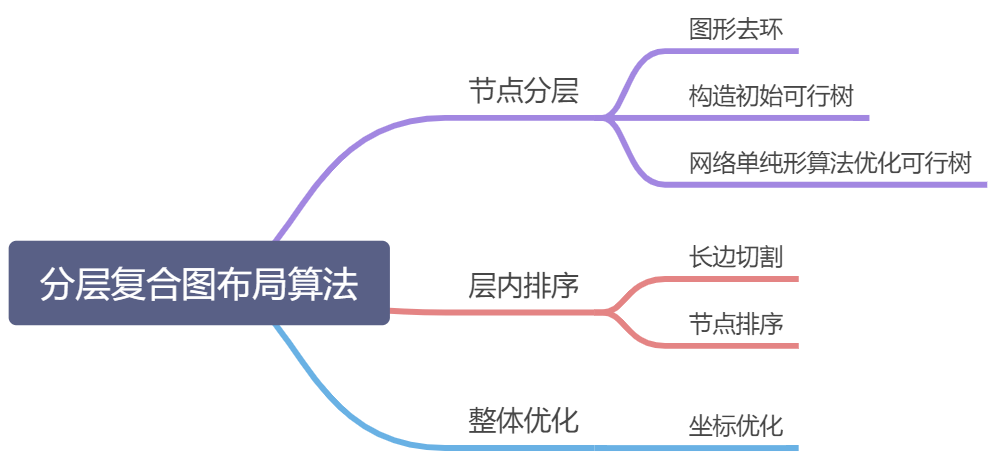
下图展示了分层复合图布局的核心步骤,以及每个过程中输出的结果。给定一个初始的有向图和分组图,第一步需要对节点分配最优层级,得到具有层级值的图。第二步,对每层的节点进行排序,得到减少了交叉边的层级图。最后,根据给定节点的父子关系,调整节点之间的坐标间距,得到最终平衡美观的分层图布局。
层次分配
节点分层的目标是将有向图中的所有节点按照统一的边方向排列,以展示更清晰的层级结构。
节点分层过程涉及了图形去环的数据预处理和层级分配。根据边的方向分配初始层级,再用网络单纯形算法优化分层结果。
图形去环(预处理)
第一步是图形去环。去环是因为环路的存在会导致分层结果多样化,既不利于分层,又会导致结果的不稳定。通过下图的案例来展示该问题,从图中可以看到 A-B-C-A 构成了一条环路,那么生成的分层图可以以 A 为顶层,也可以以 B 为顶层,又或者以 C 为顶层,得到三种不同的结果。当环路增多时,那么结果集可能会更多。从过程来看,环路不利于对分层结果的优化,容易在分层过程中陷入循环。从交互体验上来看,每次布局结果都不同会造成不好的用户体验。
了解了去环操作的必要性之后,开始对有向图进行去环,去环过程主要包括检测环路和打破环路。
第一,检测环路,从任意起点深度优先搜索,如果已访问的节点被再次访问,则说明有环。
第二,打破环路。打破环路有许多方法:可以把环内节点收缩为一个节点,或者把环内节点排布在同一层级。收缩成一个节点会误认为是属于同一个分组,排列在同一层级则丢失了环路的层级结构。所以本文所述的这个算法为了得到信息更齐全更准确的分层结构,是通过对图中的环路中的边进行反转,从而打破环路的。
在布局的计算过程,由于环路被打破了,可以生成固定的分层结构,在最终渲染的过程中,再将被反转了的边方向恢复,从而保证信息的准确度。

由于寻找最少的反转边集是个 NP 难的问题,在反转环路边的过程中,本文采用了一种优化算法,优先反转那些同时存在于多个环路中的边来尽可能的少反转边。而在存在的环路数量相等的情况下,为了保证反转的稳定,优先反转首个访问到的环路边。
虚拟节点引入
对于复合图而言,需要考虑分组关系和组节点的占位,否则会产生下图中(A)中边和组的边界交错的问题。为了解决边和组节点的框线交错的问题, 可以引入虚拟节点,用于给组节点的框线占位。在分层步骤中,只需考虑纵向的占位,所以,如下图(B)所示,引入了组节点的上,下边界节点,再进行分层。在分层过程中,由于边界框线和节点的占位高度不同,分层过程中不能将虚拟节点和正常节点在同一层排列,便于节省空间。
层级分配
引入了虚拟节点之后,根据最长路径算法先分配一个初始层级。然后再使用网络单纯形算法优化层级分配的结果。下图是层级分配的步骤介绍,首先根据最长路径算法,先找到图中的最长路径,如 A-G-H-I-L,然后把路径尽头对齐, 逆向路径来计算层级,从而生成一个初始的层级。
这样的初始层级能够快速产出一个可行结果,保证所有的节点都能根据边的方向顺序排列在不同的层级,但是可能会导致不必要的长边,也可能会导致节点会堆积在底层。所以需要使用网络单纯形算法迭代的切割边,来产生更紧凑的图,最终得到一个具有最优层级分配的图。
层内排序
得到了初始的分层数据,需要对层内节点排序以减少交错边。减少交错通常是逐层做优化。在这一步骤中同样主要做了两件事: 切割长边(预处理)和对层内节点排序。
切割长边(预处理)
为什么要切割长边?因为跨越层级的长边也会与层中节点交错。 下图中的(A)演示了这种长边交错问题。可以看到, A-L,A-E 是两条长边,如果如图中所示 C, G 节点和这两条长边产生了交错。那么为了保证在对层内节点排序的时候能够考虑到跨层级的长边的占位, 需要将存在长边的图转换为所有边都只连接相邻层级节点的图。从而方便优化边的交错。
那么如何切割跨层级的长边呢? 首先,引入虚拟节点, 安插到中间层级,来为这些跨越层级的边占位,如图(B)中绿色节点所示)。然后,将跨越层级的边替换为多条连接”虚拟节点”的单位长度边(单位长度指边的层级插为1),在图(B)中的虚线边是切割的单位长度边。需要说明的是,这些长边仅是在计算过程中被切割的,是为了方便找到最佳的绘制边的位置,在绘图过程中虚拟节点将会作为该长边在对应层级的拐点,如图 (C) 所示。
由于分组关系的存在,当长边所连接的两个节点在同一个分组的情况下, 切割长边时所产生的虚拟节点,需要将生成的虚拟节点分配到对应边所在的子图。
节点排序
长边切割后,我们得到了只有单位长度边的分层图,但由于上一步骤只对节点分层,而不进行排序, 所以可能会导致大量的交错。从图中可以看到,D-B 的边和 G-H的边产生了交错。 F-C 的边和 H-I 的边产生了交错。所以需要逐层优化节点的次序,减少边交错。
由于最小化这种边交错 是一个NP难的问题。所以它采用了一个启发式算法来逐步优化边的交错。这个启发式算法是自上而下,来逐层为节点排序,来减少交错的。 首先给出每一层节点的初始化顺序。然后执行一系列迭代尝试改进这个顺序。每次迭代从第一层遍历到最后一层,反之亦可。当访问某一层时,这一层每个顶点都会根据其关联的上一层顶点的位置分配一个权重。然后这一层的顶点会根据这个权重进行排序。这一层节点的排序后的节点序号,作为下一层节点排序的权重计算依据。
通过上图例子来讲这个过程,第一个图使用默认节点排序,存在大量边交错,如 D-B 和 G-H、F-C 和 H-I 的。第一层节点是不需要进行额外排序的。所以从第二层节点开始计算权重(以重心法为例),由于 A 的序号是 0, 所以连接的 D 和 G 节点 根据上层节点的序号所算出的权重值均为 0,在权重相等的情况下,不需要对节点进行交换。所以 D 和 G 的序号分别为 0 和 1。然后根据 D 和 G 的节点序号以及与 F, H, B 的连接边,我们可以算出 F, H, B 的权重分别为 0,1,0, 由于 B 的权重小于 H,所以需要交换 B 和 H 节点。交换了 B 和 H 之后,可以看到减少了 D 到 B 的边 和 G 到 H 的边的交错,然后我们进一步计算 I、C 的权重,由于 C 连接了 F 和 B ,所以权重是 F 和 B 的节点序号的均值/中位数。 C 的权重小于I,所以需要对 I、C 节点交换次序。通过交换 I、C 节点,F-C 的边 和 H-I 的边交错也得到了避免。通过逐层的节点排序,优化了图中的边交错。
TensorBoard 所依赖的 Dagre 库在优化排序的过程中对权重的计算方法做了改进。常用的两个顶点权重分配算法分别是重心法(barycenter function)和中位数法(median function)。令 v 为顶点,P 为其相邻层级上相连顶点的位置列表。这里的位置指的是顶点在其层级上的顺序序号。重心法定义 v 的权重为 P 中元素的平均值。中位数法定义 v 的权重为 P 中元素的中位数。当 P 的元素个数为偶数时,中位数有两个。这就导致中位数法会有两个版本,一个版本总是采用左中位数,另一个版本总是采用右中位数。
中位数法的表现始终比重心法要好,并且有轻微的理论优势。因为 Eades 和 Wormald 研究表明,对两层的图而言,采用中位数的布局边交叉数最多不会超过最小边交叉数的 3 倍。而重心法并没有类似的研究结果。而基于 Dagre 的节点排序方法是对中位数法的改进版本,主要做了两个方面的优化。第一个是当有两个中位数的时候,采用偏向更紧凑节点排布的内插值。第二个是采用一个启发式算法进一步减少排序后的明显边交叉,从而把指定排序转化成相对于顶点交换而言局部最优的排序。这个方法能够比原方法大约减少了 20-50% 的边交叉数。
坐标计算
得到了具有层级值和层内排序值的图后,需要根据平衡美观原则,计算图的水平坐标。一般采用通用的正交布局来计算节点坐标。正交布局的方法是:(1)根据树的深度将空间沿纵轴平均分成等高的区域。来 保证水平高度与垂直宽度(2)根据叶节点的数量, 将对应的区域沿横轴平均分成等宽的区域,将节点布置在每个区域的中心,来保证左右子树的平衡。通过正交布局得到了点的坐标后,边的坐标可由起始节点的坐标生成,完成全部的坐标计算。
源码解析
了解算法原理之后,为了进一步了解 TensorBoard 的源码如何实现这样一个分层复合图的。我们基于Tensorflow1.0.1@rc1 版本的 Tensorboard 配置了环境研究了其源码的构成。
API解析


组件实现
基于 TensorBoard,抽取了它的布局计算库,用于计算分层复合图的布局数据。根据布局计算库,我们封装了React版本的分层复合图,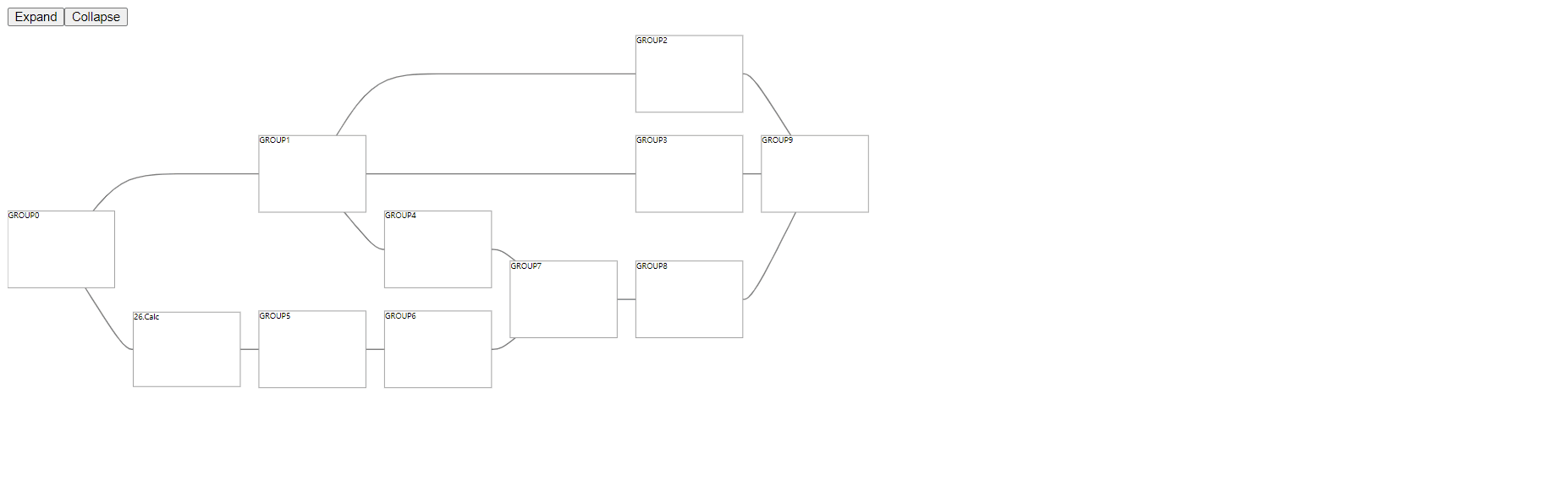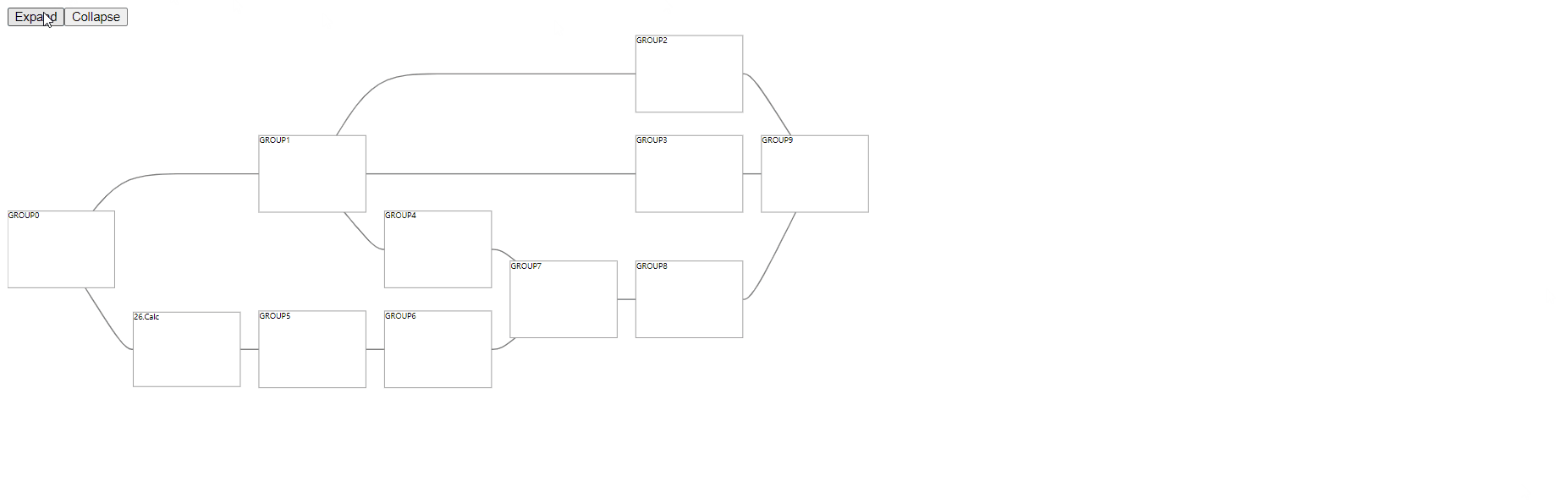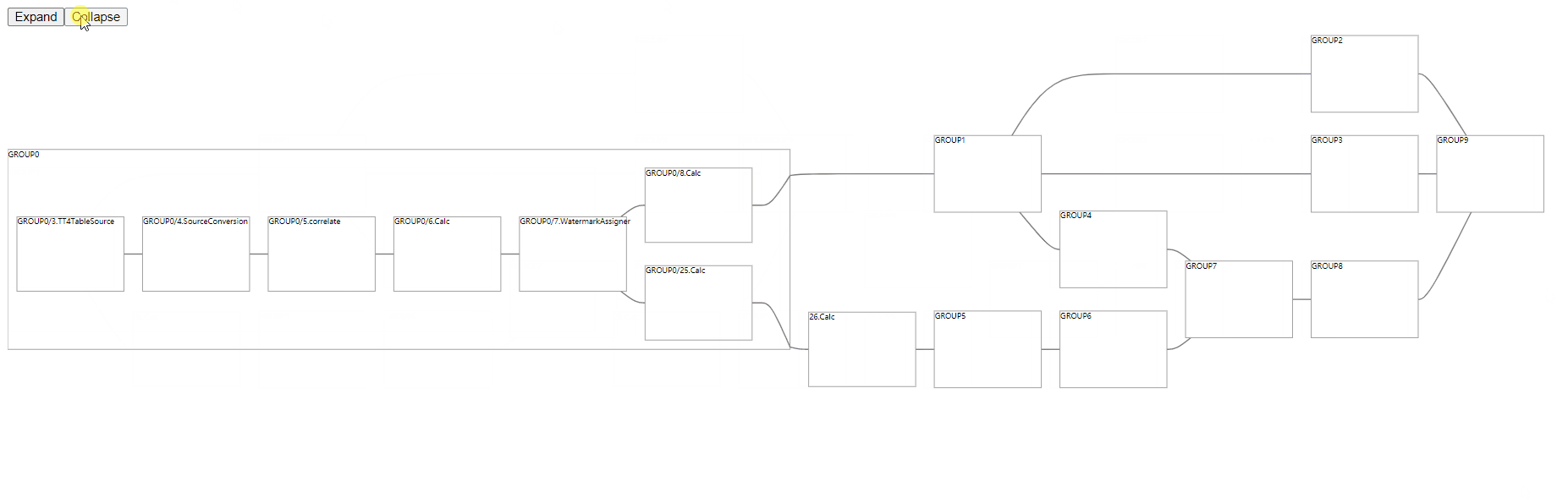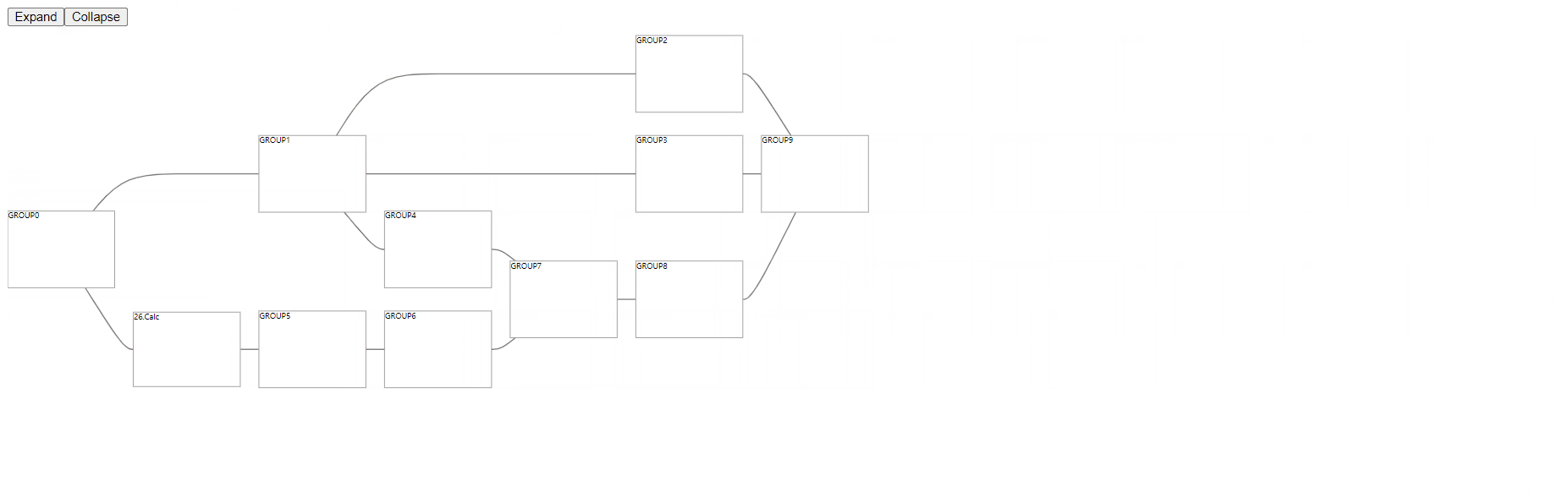
Tensorboard 的强大布局能力能够帮助我们很好的实现执行计划图的需求,我们接入到了 dataworks 的执行计划图功能中,替换了原有布局方案,解决了边交错和边重叠的问题。

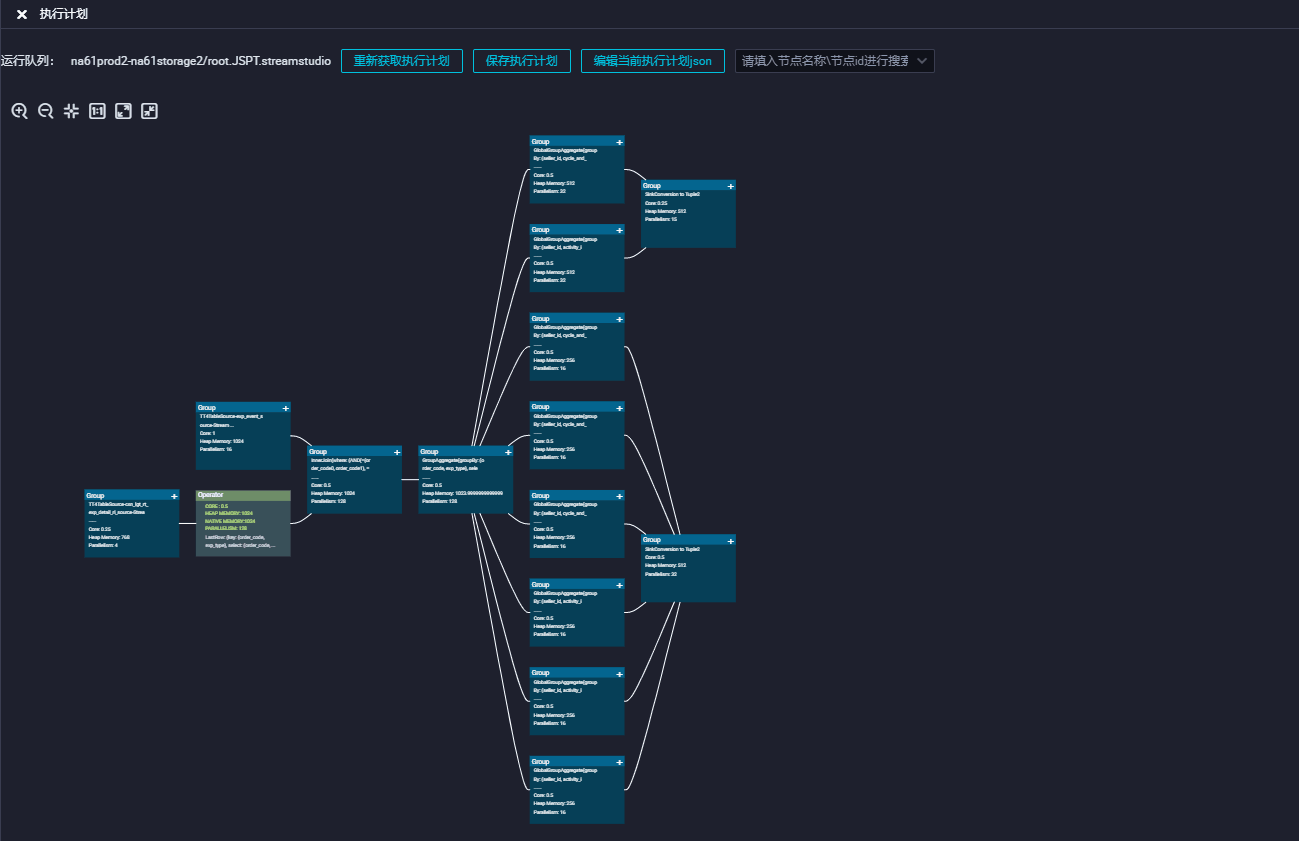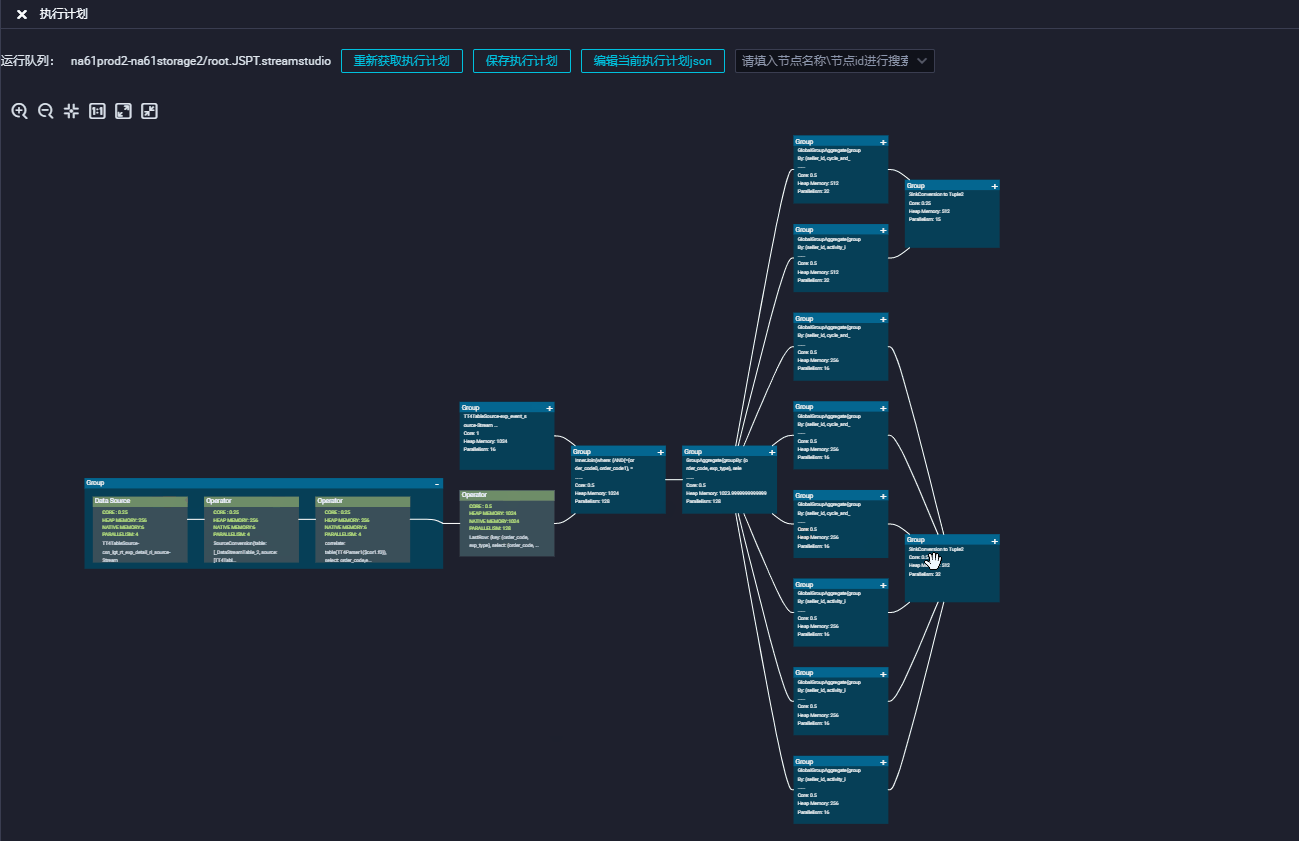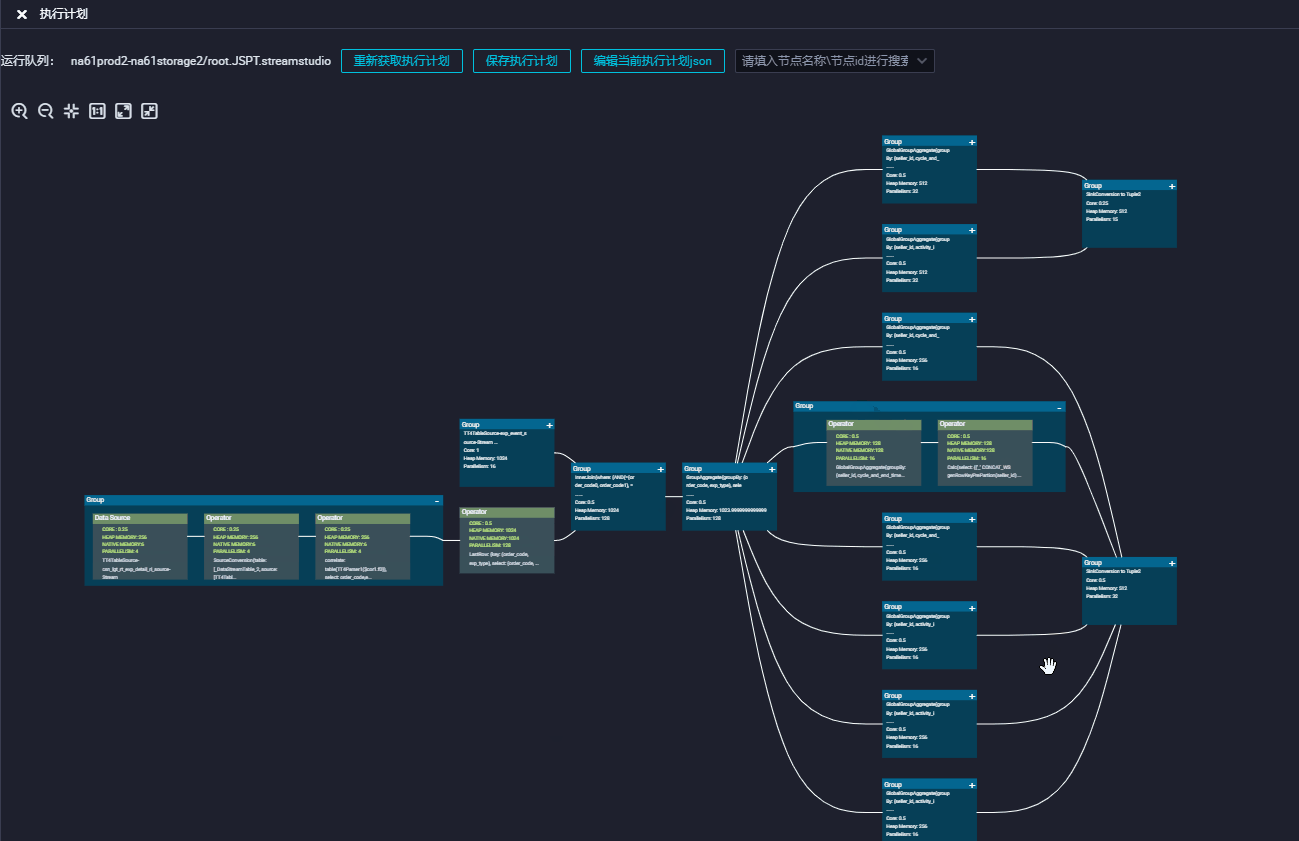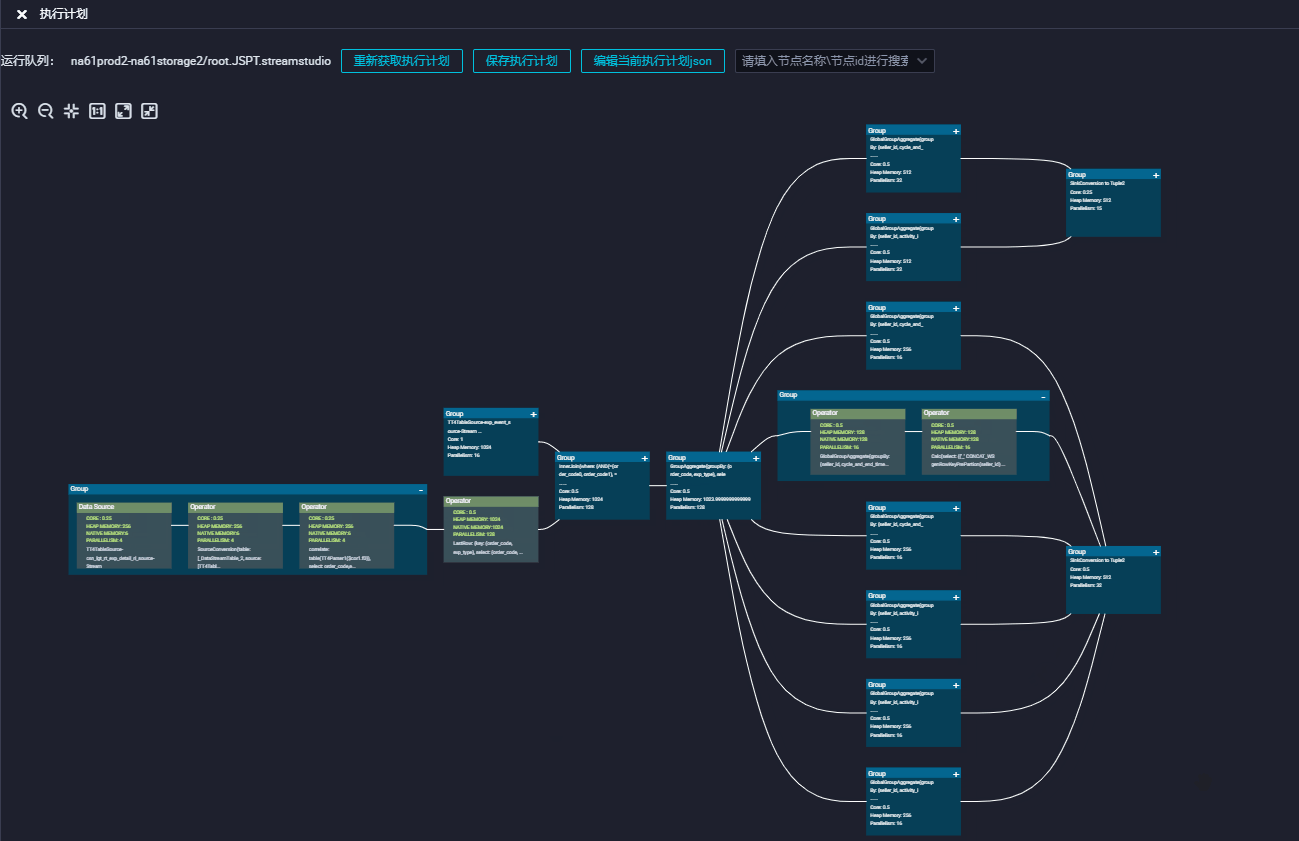
未来规划
分层复合图的布局算法、性能还有很多上升的空间。目前公开可复用的独立组件还是很缺乏,我们相信,在大规模网络数据的分析中,组合关系和序列关系的分析十分常见,我们团队会争取在会对该可视化图组件的布局、性能、可交互性进一步优化,并加入 组合嵌套的支持、动画效果的支持,争取达到业界领先的水准。

若有收获,就点个赞吧
0 人点赞
