hash函数是先拿到 key 的hashcode,是一个32位的int值,然后让hashcode的高16位和低16位进行异或操作。
这么设计有二点原因:
- 一定要尽可能降低hash碰撞,越分散越好;
- 算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
为什么采用hashcode的高16位和低16位异或能降低hash碰撞?hash函数能不能直接用key的
hashcode?
因为key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围
为-2147483648~2147483647,前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松
散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,如果
HashMap数组的初始大小才16,用之前需要对数组的长度取模运算,得到的余数才能用来访问数组下
标。
源码中模运算就是把散列值和数组长度-1做一个”与”操作,位运算比取余%运算要快。
这也正好解释了为什么HashMap的数组长度要取2的整数幂。因为这样(数组长度-1)正好相当于一个bucketIndex = indexFor(hash, table.length);static int indexFor(int h, int length) {return h & (length-1);}12345
“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初
始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如
下,结果就是截取了最低的四位值。
10100101 11000100 00100101& 00000000 00000000 00001111----------------------------------00000000 00000000 00000101 //高位全部归零,只保留末四位1234
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更
要命的是如果散列本身做得不好,分布上成等差数列的漏洞,如果正好让最后几个低位呈现规律性重
复。
此时“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,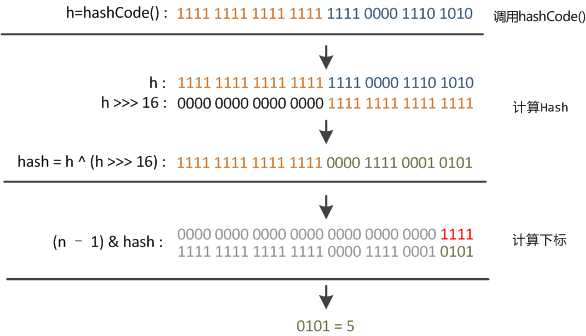
右移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低
位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保
留下来。
最后我们来看一下Peter Lawley的一篇专栏文章《An introduction to optimising a hashing
strategy》里的的一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它
们做低位掩码,取数组下标。
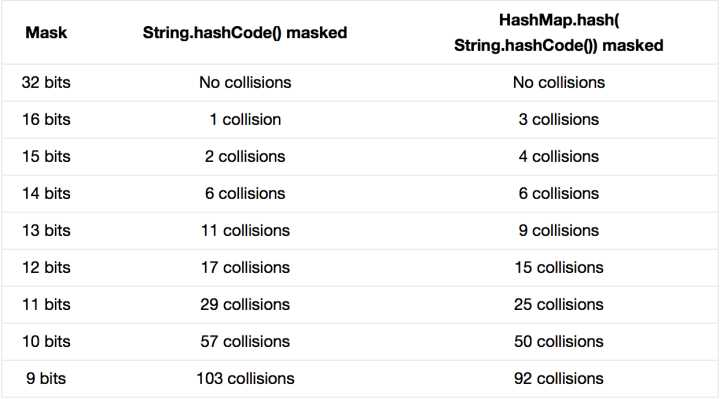
结果显示,当HashMap数组长度为512的时候(29),也就是用掩码取低9位的时候,在没有扰动函数
的情况下,发生了103次碰撞,接近30%。而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近
10%。看来扰动函数确实还是有功效的。
另外Java1.8相比1.7做了调整,1.7做了四次移位和四次异或,但明显Java 8觉得扰动做一次就够了,做
4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次了。
下面是1.7的hash代码:
static int hash(int h) {h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}1234

若有收获,就点个赞吧
0 人点赞
