新entry节点插入链表的时候是头插法还是尾插法
java8之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
为啥改为尾部插入呢?
有人认为是作者随性而为,没啥用,其实不然,其中暗藏玄机
首先我们看下HashMap的扩容机制:
帅丙提到过了,数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize。
什么时候resize呢?
有两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。

怎么理解呢,就比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
扩容?它是怎么扩容的呢?
分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,直接复制过去不香么?
卧槽这个问题!有点知识盲区呀!

1x1得 1 1x2 得 2 …. 有了,我想起来敖丙那天晚上在我耳边的话了:假如我年少有为不自卑,懂得什么是珍贵,那些美梦没给你,我一生有愧….什么鬼!
小姐姐:是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式—-> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
扩容前:

扩容后:

说完扩容机制我们言归正传,为啥之前用头插法,java8之后改成尾插了呢?
卧槽,我以为她忘记了!居然还是被问到了!
我先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了

现在我们要在容量为2的容器里面用不同线程插入A,B,C,假如我们在resize之前打个短点,那意味着数据都插入了但是还没resize那扩容前可能是这样的。
我们可以看到链表的指向A->B->C
Tip:A的下一个指针是指向B的
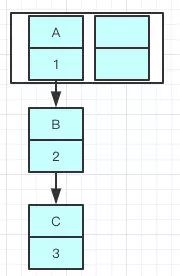
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?
B的下一个指针指向了A

一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,悲剧就出现了——Infinite Loop。
小伙子有点东西呀,但是你都都说了头插是JDK1.7的那1.8的尾插是怎么样的呢?
因为java8之后链表有红黑树的部分,大家可以看到代码已经多了很多if else的逻辑判断了,红黑树的引入巧妙的将原本O(n)的时间复杂度降低到了O(logn)。
Tip:红黑树的知识点同样很重要,还是那句话不打没把握的仗,限于篇幅原因,我就不在这里过多描述了,以后写到数据结构再说吧,不过要面试的仔,还是要准备好,反正我是经常问到的。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B

Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。

若有收获,就点个赞吧
0 人点赞
