概述
流的操作类型主要分为两种: 中间操作、终端操作。
中间操作
一个流可以后面跟随零个或多个中间操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的,仅仅调用到这类方法,并没有真正开始流的遍历,真正的遍历需等到终端操作时,常见的中间操作有 filter、map 等
终端操作
一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。终端操作的执行,才会真正开始流的遍历。如 count、collect 等
流操作
java.util.stream.Stream中的Stream接口定义了许多操作。它们可以分为两大类。我们再来看一下前面的例子:
List<String> names = menu.stream() //从菜单获得流.filter(d -> d.getCalories() > 300) //中间操作.map(Dish::getName) //中间操作.limit(3) //中间操作.collect(toList()); //将Stream转换为List
你可以看到两类操作:
filter、map和limit可以连成一条流水线;
collect触发流水线执行并关闭它。
可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。 这两类操作。这种区分有什么意义呢?
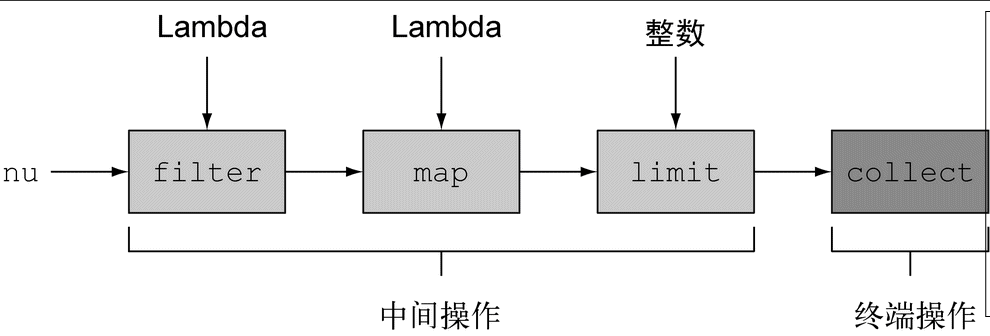
中间操作
诸如filter或sorted等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理。
为了搞清楚流水线中到底发生了什么,我们把代码改一改,让每个Lambda都打印出当前处理的菜肴(就像很多演示和调试技巧一样,这种编程风格要是搁在生产代码里那就吓死人了,但是学习的时候却可以直接看清楚求值的顺序):
List<String> names =menu.stream().filter(d -> {System.out.println("filtering" + d.getName());return d.getCalories() > 300;}) ←─打印当前筛选的菜肴.map(d -> {System.out.println("mapping" + d.getName());return d.getName();}) ←─提取菜名时打印出来.limit(3).collect(toList());System.out.println(names);
此代码执行时将打印:
filtering porkmapping porkfiltering beefmapping beeffiltering chickenmapping chicken[pork, beef, chicken]
你会发现,有好几种优化利用了流的延迟性质。第一,尽管很多菜的热量都高于300卡路里,但只选出了前三个!这是因为limit操作和一种称为短路的技巧,我们会在下一章中解释。第二,尽管filter和map是两个独立的操作,但它们合并到同一次遍历中了(我们把这种技术叫作循环合并)。
终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如List、Integer,甚至void。例如,在下面的流水线中,forEach是一个返回void的终端操作,它会对源中的每道菜应用一个Lambda。把System.out.println传递给forEach,并要求它打印出由menu生成的流中的每一个Dish:
menu.stream().forEach(System.out::println);
使用流
总而言之,流的使用一般包括三件事:
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
流的流水线背后的理念类似于构建器模式。1在构建器模式中有一个调用链用来设置一套配置(对流来说这就是一个中间操作链),接着是调用built方法(对流来说就是终端操作)。

若有收获,就点个赞吧
0 人点赞
