总结
1.如果HashMap没有被初始化的时候,就进行初始化
2.对key求hash值,然后再计算下标,
3.如果没有碰撞,就直接放入桶中
4.如果碰撞了,就以链表的方式链接到最后
5.如果链表长度超过阈值,就把链表转成红黑树
6.如果链表长度低于6,就把红黑树转回链表
7.如果节点已经存在就替换旧的值
8.如果桶满了(容量16*加载因子0.75),就需要resize(扩容2倍后重排)
原理图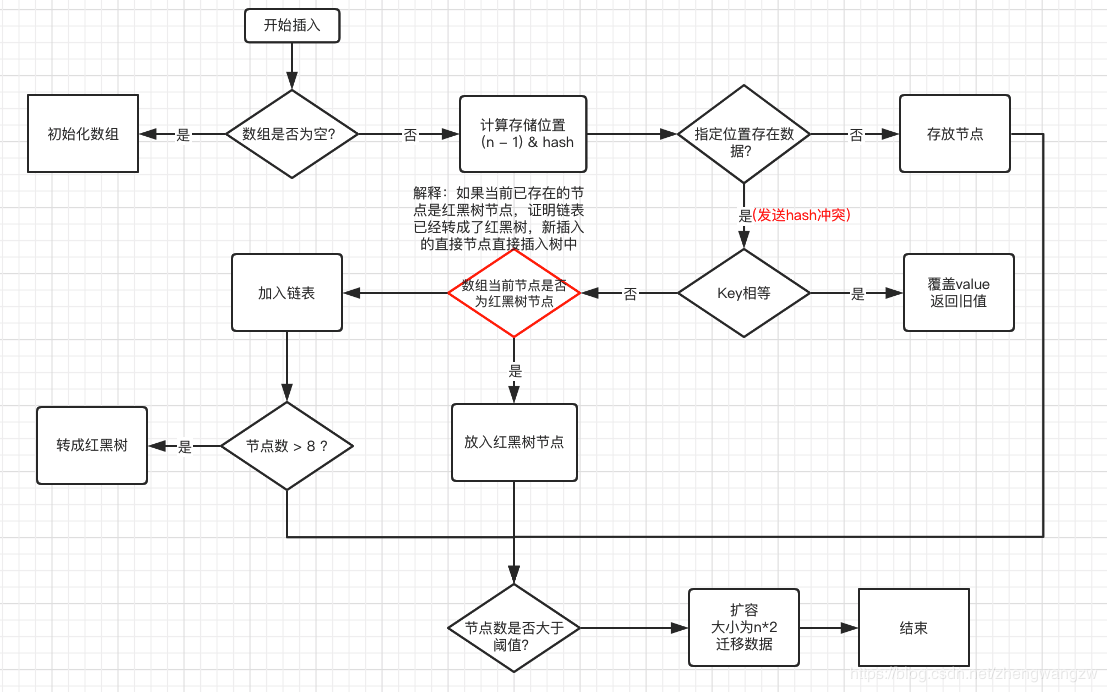
- 判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过 (n - 1) & hash 计算应当存放在数组中的下标 index;
- 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
- 存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,
用新的value替换原数据(onlyIfAbsent为false); - 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;
(如果当前节点是树型节点证明当前已经是红黑树了) - 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64,
大于的话链表转换为红黑树; - 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
详细说明
put(K,V)方法,hash算法 和 hash寻址算法
- put的时候,先通过hash算法处理hashcode,然后通过寻址算法定位到该元素在数组的位置,然后判断应该放在数组还是链表或者红黑树中
- hash算法
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
- ps:hashcode是int型,4个字节,一个字节8个bit,一共32位
- 先定义个变量: key的hashcode右移 16位,其实就是把原来的hashcode值的高16位放到低16位,高16位补0。然后画图讲解:

- 相当于拿hashcode的低16为和高16位做异或操作(不一样的为1,一样的为0),让高16位也参与到运算中(正常来说集合的大小是不会特别大的,2的16次幂就6万多了,虽然hashmap允许的最大值是2的30次幂),所以,hash值的后16位90%的情况下都不会参与运算。但是现在高16位和低16位异或后,低16位就同时保留了高低两部分的特征,降低hash冲突。
- 为什么说可以降低hash冲突,因为如果两个key,解析的hashcode可能低16为一样的,但是如果这么异或一下,就不一样了
- 寻址算法:
- 为什么说可以降低hash冲突,因为如果两个key,解析的hashcode可能低16为一样的,但是如果这么异或一下,就不一样了
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//注意这里的 (n - 1) & hashif ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//省略下面的代码...
- 寻址算法,会拿经过hash算法的hashcode 跟 (数组大小 - 1),做与操作,这样做相当于对数组大小取模,但是效率上要比取模高的多,直接做位运算省去了转成10进制的步骤,但是这么做有一个前提,集合大小必须是2的n次方
- 这里解释下为什么 只有集合大小是2的n次方,他们与操作才等同于取模
- 假设,数组大小为 (2的3次方 - 1 ) = 7
- 那么,二进制表示,就是 1 1 1
- 与操作的意思是,只有两边都是1,才是1
- 因为,数组大小为7,二进制 1 1 1,前面都是0补全的
- 那么,hashcode的二进制除了后3位,其他的就没意义了,因为要做与操作,而数组的前面都是0,不管hashcode前面是1还是0,都没有用,做完与操作就是0
- 那么hashcode的有效长度只有后三位,共有8种情况
0 0 0 = 00 0 1 = 10 1 0 = 20 1 1 = 31 0 0 = 41 0 1 = 51 1 0 = 6
- 跟数组大小的二进制 1 1 1做与操作,那就是
0 0 0 & 1 1 1 = 0 ps: 0 % 7 余 70 0 1 & 1 1 1 = 1 ps: 1 % 7 余 10 1 0 & 1 1 1 = 2 ps: 2 % 7 余 20 1 1 & 1 1 1 = 3 ps: 3 % 7 余 31 0 0 & 1 1 1 = 4 ps: 4 % 7 余 41 0 1 & 1 1 1 = 5 ps: 5 % 7 余 51 1 0 & 1 1 1 = 6 ps: 6 % 7 余 61 1 1 & 1 1 1 = 7 ps: 7 % 7 余 0
- 发现没有,这样就跟取模是一个效果。
- 如果不设成2的n次方,那数组的二进制就有可能是 0 1 0 ,那hashcode的有效值就变成1位了,那数组中有的地方一直没元素,有的地方一直冲突
- 判断该元素存放在哪里
- 如果hash寻址之后,这个位置的元素为null,那么直接放里
- 如果这个位置的元素不为空,会走一个遍历,这个元素的.next,为null停
- 进入循环之后,先判断,hash值是否相等(即使hash值不相等,也可能定位到同一个位置),key的equals是否相等,如果满足这两个条件,说明这两个元素的key是一样的,直接替换掉,循环break
- 如果那两个条件不成立,说明hash冲突,那么会一直循环到最后一个元素,如果没有一个元素符合上述两个条件,那么最后一个元素的next指向本次插入的元素
- 本次put操作暂不考虑红黑树情况,下节讲,当链表的大小长度大于等于8的时候,会字段转换成红黑树
- 如果不转红黑树,当链表过长的时候,时间复杂度会变成O(n)

若有收获,就点个赞吧
0 人点赞
