web开发中常见的小细节
(一)获取项目路径相关
1.动态获取web项目的根路径
webContent(MyEclipse中是webRoot)
request.getContextPath()
2.在index.jsp请求转发到Servlet或者jsp或者目录
//请求到jsp
<%request.getRequestDispatcher(“/jsp/index.jsp”).forward(request, response); %>
//在首页添加个目录
>点击进入项目1
//请求到servlet地址
<%request.getRequestDispatcher(“/product/index.action”).forward(request, response); %>
在index请求转发到Servlet
通常使用场景是输入项目名就到我指定的首页.![Web[笔记] - 图1](/uploads/projects/zjj1994@javabasic/962f2d62aae1e01645df548b600f01a3.jpeg)
3./和/和.do的一些东西
/表示所有 杠就是什么都可以,可以没内容
/ 表示是所有的名称 杠就是后面必须得有访问名字
.do
servlet访问优先级问题,都有通配符的情况下.
/和*.do
只要有/ 就比不带杠的优先级高, 这点讲师已经验证过了.
4.html页面跳转到别的url
5.web资源(静态资源和动态资源)
1.静态资源
假如一个文件,在服务器端打开是什么样的,在客户端打开也是什么样的,这就是静态资源
比如:html, js,css,图片(动态也算,在服务端怎么动,在客户端也怎么动),视频,音频
2.动态资源
一个页面写完之后同样的代码,可能客户端我看到结果和你看到的结果是不一样的.比如百度网站,登录了,不同账户登录后显示的页面也不一样.
比如:jsp,Servlet(本质就是java程序),php,asp
6.web阶段请求响应乱码问题(框架没用)
![Web[笔记] - 图2](/uploads/projects/zjj1994@javabasic/e0e37968a58e1c38f8b84960fb719c75.jpeg)
浏览器跨域问题
![Web[笔记] - 图3](/uploads/projects/zjj1994@javabasic/1695e553fcf2a704f930fa8bd58d85e5.jpeg)
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任意一个不同,都是跨域,一个服务器请求另外一个服务器就是跨域,跨域前提就是有两个应用(两台机器)
域名:
主域名不同 http://www.baidu.com/index.html –>http://www.sina.com/test.js 子域名不同 http://www.666.baidu.com/index.html –>http://www.555.baidu.com/test.js 域名和域名ip http://www.baidu.com/index.html –>http://180.149.132.47/test.js端口:
http://www.baidu.com:8080/index.html–> http://www.baidu.com:8081/test.js协议:
http://www.baidu.com:8080/index.html–> https://www.baidu.com:8080/test.js
浏览器对于javascript的同源策略的限制,例如a.cn下面的js不能调用b.cn中的js,对象或数据(因为a.cn和b.cn是不同域(不同域就是域名,端口,协议有一个不同就是跨域)),所以跨域就出现了.
协议主机端口 任意一个不同就是跨域
1. 比如本项目的ajax忽然访问百度,主机不一样,这个就是跨域了
2. 还有frem模版技术,
!!!!! href 把当前浏览器的地址栏执向新的地址(href 不算跨域)
解决跨域
如果在代码实现以后在每个代码都得写转java对象转json的步骤十分麻烦,我们是接口的提供方,我们并不知道客户调用的时候需要不需要跨域,所以就更高层级,在我们框架级,或者整体的项目级别的解决掉,而不是在代码里面逐步解决掉(在代码逐步写问题是:成本很高(一般工程师不了解的话看不懂),用统一支持的jsonp方法 消息转换器,用的多的是返回对象的转换器.
很简单的一个办法
只需要在controller类上添加注解@CrossOrigin 即可!这个注解其实是CORS的实现。
CORS(Cross-Origin Resource Sharing, 跨源资源共享)是W3C出的一个标准,其思想是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。因此,要想实现CORS进行跨域,需要服务器进行一些设置,同时前端也需要做一些配置和分析。本文简单的对服务端的配置和前端的一些设置进行分析。
Request
Tomcat收到客户端的http请求,会针对每一次请求,分别创建一个代表请求的request对象、和代表响应的response对象.
我们在创建Servlet的时候,实现Servlet接口或者继承HttpServlet,不管哪一种,都有一些方法需要重写:service方法和doGet/doPost方法。这些方法都有两个参数:一个代表http请求的request对象,和一个代表http响应的response对象。
service方法的参数是ServletRequest,doGet/doPost的参数是HttpServletRequest。HttpServletRequest是ServletRequest子接口,功能更为强大,应用更方便。我们用的是HttpServletRequest。
Request 是一个http请求 作用是接收客户端发的数据,既然request对象代表http请求,那么我们获取浏览器提交过来的数据,找request对象即可.
request是一个域对象
域对象主要作用是数据共享,域对象必定会有三个方法:
setAttribute(String name, Object value) //放数据进去的
getAttribute(String name); //取数据的
removeAttribute(String name); //用来删除数据的
request域对象的生命周期:
何时创建:一次请求开始
何时销毁:一次请求结束(request里面的数据就会被销毁了.)
作用范围:一次请求链中
(一)request的API
1.请求转发
request.getRequestDispatcher(“/login.jsp”).forward(request, response);
写路径永远都是以”/”开头 , 如果是Servlet访问Servlet 或者 Servlet 访问jsp 这两种方式 都不需要加项目名, 只需要加地址,因为是内部资源访问.
2.操作请求行数据
格式: 请求方式 请求的资源 协议/版本
String method = request.getMethod(); 获取请求方式
String contextPath = request.getContextPath() 获取当前的项目名
String getRemoteAddr() 获取请求者的ip地址
String getProtocol() 获取请求协议和版本,了解,没什么用
3.操作请求头
格式: key:value(value可以为多个值)
String value = request.getHeader(String name);获取单一请求头数据
Enumeration getHeaders(String name) :获取指定头的所有值(了解,没用)
常见的请求头:
(掌握)user-agent:获取浏览器的信息
(掌握)referer:获取网页来源(若地址是直接在地址栏上敲的 返回的null)
4.操作请求体(获取请求参数)
String getParameter(String name) // 获取页面传来的参数的(页面传过来的值是5个以的)
String[] getParameterValues(String name) //接收多值的
Map
| @ApiOperation(value = “支付回调”, notes = “支付回调”)
@GetMapping(“/payCallBack”)
public SuccessVo payCallBack(HttpServletRequest httpServletRequest) {
Map
Iterator
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry) iterator.next();
String key = (String) entry.getKey();
String[] value = (String[])entry.getValue();
System.out.println(“key:” + key + “—-“ + “value:” + Arrays.toString(value));
/key:asda—-value:[2123]
key:sasdss—-value:[1212]/
}
return new SuccessVo(parameterMap);
} |
| —- |
(二)通过request获取请求路径的不同方法的区别
1、request.getRequestURL() 返回的是完整的url,包括Http协议,端口号,servlet名字和映射路径,但它不包含请求参数。
2、request.getRequestURI() 得到的是request URL的部分值,并且web容器没有decode过的
3、request.getContextPath() 返回 the context of the request.
4、request.getServletPath() 返回调用servlet的部分url.
5、request.getQueryString() 返回url路径后面的查询字符串
示例: 当前url:http://localhost:8080/CarsiLogCenter_new/idpstat.jsp?action=idp.sptopn
request.getRequestURL() :http://localhost:8080/CarsiLogCenter_new/idpstat.jsp
request.getRequestURI() :/CarsiLogCenter_new/idpstat.jsp
request.getContextPath():/CarsiLogCenter_new
request.getServletPath(): /idpstat.jsp
request.getQueryString():action=idp.sptopn
(三)HttpServletRequest
HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过这个对象的方法,可以获得客户这些信息。简单来说,要得到浏览器信息,就找HttpServletRequest对象.
HttpServletRequest常用方法
获得客户机【浏览器】信息
getRequestURL方法返回客户端发出请求时的完整URL。
getRequestURI方法返回请求行中的资源名部分。
getQueryString 方法返回请求行中的参数部分。
getPathInfo方法返回请求URL中的额外路径信息。额外路径信息是请求URL中的位于Servlet的路径之后和查询参数之前的内容,它以“/”开头。
getRemoteAddr方法返回发出请求的客户机的IP地址
getRemoteHost方法返回发出请求的客户机的完整主机名
getRemotePort方法返回客户机所使用的网络端口号
getLocalAddr方法返回WEB服务器的IP地址。
getLocalName方法返回WEB服务器的主机名
获得客户机请求头
getHeader方法
getHeaders方法
getHeaderNames方法
获得客户机请求参数(客户端提交的数据)
getParameter方法
getParameterValues(String name)方法
getParameterNames方法
getParameterMap方法
1.防盗链
//获取到网页是从哪里来的 String referer = request.getHeader(“Referer”); //如果不是从我的首页来或者从地址栏直接访问的, if(referer ==null ||!referer.contains(“localhost:8080/zhongfucheng/index.jsp”) ){ //回到首页去 response.sendRedirect(“/zhongfucheng/index.jsp”); return; } //能执行下面的语句,说明是从我的首页点击进来的,那没问题,照常显示 response.setContentType(“text/html;charset=UTF-8”); response.getWriter().write(“路飞做了XXXXxxxxxxxxxxxxxxxx”); |
|---|
(四)请求转发和重定向概念
重定向最少2次请求,请求转发只有一次
重定向的地址会发生改变,请求转发地址不会发生改变
重定向是response,请求转发是request的方法
方法:
xxxAttribute();
作用:
多个servlet之间的资源通信—request里的数据可以被多个servlet共享
原因: 因为在请求转发中,对个servlet使用的是同一个request对象
当请求转发结束(响应结束的时候),request也就销毁了,request中存的数据就不存在
总结:请求转发不只可以执行多个servlet,还可以做多个servlet之间的资源共享,
因为在请求转发中多个servlet使用的是同一个request,而且request也有保存数据的xxxAttribute()方法
大白话:
重定向:你来找我,我让你去找别人
请求转发:你来找我,我帮你去找别人
请求转发和重定向的区别:见图![Web[笔记] - 图4](/uploads/projects/zjj1994@javabasic/fa5dcbae0f8e69c97f7fee5238d0d1a8.jpeg)
如果要传递数据(用request域)就用请求转发,否则就推荐使用重定向
重定向时的网址可以是任何网址
转发的网址必须是本站点的网址
重定向与请求转发使用
前后两个页面 有数据传递 用请求转发,没有则用重定向。
比如servlet查询了数据需要在页面显示,就用请求转发。
比如servlet做了update操作跳转到其他页面,就用重定向。
(五)Spring获取request的几种方式
https://www.yuque.com/docs/share/8acabf62-ef3d-490c-b6d3-49264202886b?#
Response
我们在创建Servlet的时候,实现Servlet接口或者继承HttpServlet,不管哪一种,都有一些方法需要重写:service方法和doGet/doPost方法。
这些方法都有两个参数:一个代表http请求的request对象,和一个代表http响应的response对象。
service方法的参数是ServletResponse,doGet/doPost的参数是HttpServletResponse。HttpServletResponse是ServletResponse子接口,功能更为强大,应用更方便。我们用的是HttpServletResponse(工作用的多,对应response响应)。
response对象代表http响应,那么我们向浏览器输出数据,找response对象即可。
(一)response的API
![Web[笔记] - 图5](/uploads/projects/zjj1994@javabasic/039cbaebe32d9fd595d9be7cac8d8fc9.jpeg)
(二)响应行响应头响应体
设置响应状态码:
response.setStatus(int code);//仅仅设置响应状态码
response.sendError(int code);//设置状态码。如果是错误码的话,页面报错
1 操作响应行
格式:
协议/版本 状态码 状态码说明 HTTP/1.1 200 OK
常用的方法:
操作状态码:5种状态码
1 2 3 :正常的响应
4 5:有问题的响应
(理解)setStatus(状态码):针对的是 1xx 2xx 3xx
response.setStatus(302)
需要一个响应头
(了解)sendError(int code):针对的是 4xx 5xx
2 操作响应头(重点)
格式:
key:value(value可以是多个值)
常用的方法:
setHeader(String key,String value):设置字符串形式的响应头
常用的响应头:
2 content-type:设置文件的mime类型 并且通知浏览器用什么编码打开
(了解)response.setHeader(“content-type”,”文件的mime类型;charset=utf-8”);
(重要)response.setContentType(“文件的mime类型;charset=utf-8”); 固定的处理响应的中文乱码
4 content-disposition:文件下载专用头
response.setHeader(“content-disposition”,”attachment;filename=”+文件名称);
设置响应头的API
设置响应头:
response.setHeader(String name, String value);
response.setIntHeader(String name, int value);
response.setDateHeader(String name, long value);
追加响应头:
response.addHeader(String name, String value);
response.addIntHeader(String name, int value);
response.addDateHeader(String name, long value);
3 操作响应体
页面上要展示的内容
常用方法:
PrintWriter getWriter():字符流
ServletOutputStream getOutputStream():字节流
注意:
若是能写的出来的内容用字符流,其他全用字节流
中文乱码问题
字符流和字节流不能同时出现
服务器会自动帮我们关闭这2个流.
设置响应体的API
(1)字符型响应体的设置
PrintWriter writer = response.getWriter();
writer.write(“”);
字符型响应体的中文乱码:
原因:
response缓冲区默认采用iso-8859-1字符集,不支持中文
解决方案:
设置response缓冲区采用utf-8字符集
并且,指定客户端浏览器也采用utf-8字符集
response.setContentType(“text/html;charset=utf-8”);
(2)字节型响应体的设置
通常用来向客户端的页面上发送一些图片、音频之类的二进制数据
ServletOutputStream os = response.getOutputStream();
(三)调用getOutputStream()方法向浏览器输出数据[需要研究使用有效果]
调用getOutputStream()方法向浏览器输出数据,getOutputStream()方法可以使用print()也可以使用write(),它们有什么区别呢?我们试验一下。代码如下
//获取到OutputStream流
ServletOutputStream servletOutputStream = response.getOutputStream();
//向浏览器输出数据
servletOutputStream.print(“aaaa”);
注意输出中文会有乱码的情况
//获取到OutputStream流
ServletOutputStream servletOutputStream = response.getOutputStream();
//向浏览器输出数据
servletOutputStream.print(“中国!”);
为什么会出现异常呢?在io中我们学过,outputStream是输出二进制数据的,print()方法接收了一个字符串,print()方法要把“中国”改成二进制数据,Tomcat使用IOS 8859-1编码对其进行转换,“中国”根本对ISO 8859-1编码不支持。所以出现了异常
//设置头信息,告诉浏览器我回送的数据编码是utf-8的
response.setHeader(“Content-Type”, “text/html;charset=UTF-8”);
response.getOutputStream().write(“你好呀我是中国”.getBytes(“UTF-8”));
(四)调用getWriter()方法向浏览器输出数据
对于getWriter()方法而言,是Writer的子类,那么只能向浏览器输出字符数据,不能输出二进制数据
使用getWriter()方法输出中文数据,代码如下:
这样返回给前端的就是json格式的数据
| @Override
protected boolean onAccessDenied(ServletRequest request, ServletResponse response) {
JSONObject jsonObject = new JSONObject();
jsonObject.put(“code”, 999);
jsonObject.put(“message”, “登陆已过期,请重新登陆”);
PrintWriter out = null;
HttpServletResponse res = (HttpServletResponse) response;
try {
res.setCharacterEncoding(“UTF-8”);
res.setContentType(“application/json”);
out = response.getWriter();
out.println(jsonObject);
} catch (Exception e) {
} finally {
if (null != out) {
out.flush();
out.close();
}
}
return false;
} |
| —- |
(五)httpServletResponse.getWriter().write(result)
前端访问没有这个路径的接口,按理来说应该抛404的异常的,结果抛出Cannot call sendError() after the response has been committed 这个异常,
错误详解
https://blog.csdn.net/baiyang_liu/article/details/8076104
解决办法就是用下面的代码块儿抛出异常
这个场景是自定义异常被shiro框架内部捕获了,无奈之下只能用这种方式抛出错误信息给前端.
| public static void sendErrorMessageToFrontEnd(HttpServletResponse httpServletResponse_) _throws IOException {
httpServletResponse.setContentType(“application/json;charset=utf-8”);
httpServletResponse.setHeader(“Access-Control-Allow-Origin”, “*”);
String result = JSONObject.toJSONString_(_new ResultVO_(_false, 401, “您已长时间未登录,请重新登录”));
httpServletResponse.getWriter().write(result);
} |
| —- |
(六)getWriter和getOutputStream细节
getWriter()和getOutputStream()两个方法不能同时调用。如果同时调用就会出现异常
Servlet程序向ServletOutputStream或PrintWriter对象中写入的数据将被Servlet引擎从response里面获取,Servlet引擎将这些数据当作响应消息的正文,然后再与响应状态行和各响应头组合后输出到客户端。
Servlet的serice()方法结束后【也就是doPost()或者doGet()结束后】,Servlet引擎将检查getWriter或getOutputStream方法返回的输出流对象是否已经调用过close方法,如果没有,Servlet引擎将调用close方法关闭该输出流对象.
(七)重定向使用以及原理
使用
重定向的特点:
1 最少2个请求,只有第一个是手动的,剩下的都是自动的
2 地址栏会发生改变
// 重定向—第一种写法(了解)
/response.setStatus(302);
response.setHeader(“location”, “/day31/sd9”);/
// 重定向—第二种写法(掌握) /项目名/Servlet
response.sendRedirect(request.getContextPath()+“/listController”);
重定向的原理![Web[笔记] - 图6](/uploads/projects/zjj1994@javabasic/ed97cc01480960c4b472b8e8711d4e4d.jpeg)
点击登录的时候,会提交给servlet,servlet就是java程序,能够接收参数,然后去数据库进行校验, 如果(正确)通过了,让客户端跳转到首页里面去.
给他一次http响应, 给出响应头,客户端浏览器自动发起请求根据上次的响应的响应头里面的路径找到资源,然后服务器在给响应回去.
!!!总共发起两次请求第一次是手动发起的请求,服务端告诉客户端位置(通过响应头)去找资源,第二次是客户端自动发起的.
(八)定时刷新跳转到别的网址
定时刷新 基本固定的东西,不需要背诵
response.setHeader(“refresh”,”秒数;url=跳转的地址”)
案例
demo:五秒跳转到百度:
response.setHeader(“refresh”, “5;url=http://www.baidu.com“);
(九)总结头(重点)
解决中文乱码<br /> response.setContentType("text/html;charset=utf-8")<br /> <br /> 文件下载专用头(浏览器端的下载框)<br /> response.setHeader("content-disposition","attachment;filename="+文件名称); <br /> <br /> response.setContentType("mineType")---给浏览器返回文件类型的<br />
Cookie&Session会话技术
会话技术:当你打开一个浏览器的时候,意味着会话开始了,会话开始和结束之间 浏览器和服务器可以产生N多交互,当你关闭该浏览器的时候,意味着会话结束了,简单说可以存储浏览器和服务器交互之间产生的数据,这些数据可以存在cookie里 也可以存在session里.
如果是没有状态的会话的话,张三和李四同时访问一个网站, 后端服务器不知道是张三在请求,还是李四在请求.
Http协议是一种无状态的协议,浏览器主动发送一个请求,web服务器被动地回应一个结果,主要浏览器发出的请求消息完全一样,不管消息是从哪个主机上哪种浏览器上发出的,web服务器都会用完全一样的方式进行回应.web服务器并不关心两次访问请求是否是同一个浏览器发出来的,还是两个浏览器分别发出来的,所以web服务器不能识别出哪些请求是同一个浏览器发出来的.即使浏览器发送完一次访问请求之后立马又发送一次请求,Web服务器依然不知道下一次请求和上一次请求是一个浏览器发送出来的.
由于Http协议本身不具有会话状态,要想在web应用程序中维持会话状态信息和实现有状态的会话管理.
Web服务器在一段时间内通常会同时接收到多个客户端浏览器的访问请求,Web服务器首先要能从大量的请求消息中区分出哪些请求消息属于同一个会话(同一个浏览器的访问请求).然后再将来自同一个浏览器的访问请求组织成一个会话过程.
浏览器对发送出的每个请求消息都进行标识,属于同一个会话中的请求消息都附带同样的标识号,属于不同会话的请求的消息附带的是不同的标识号,这个标识号就是会话ID(SessionID).
会话ID可以通过Cookie技术在请求消息中进行传递,也可以作为请求URL的附加参数进行传递,会话ID(SessionID)是Web服务器为每个客户端浏览器分配的唯一代号.
1.session和cookie的区别和比较
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
1、存取方式的不同
Cookie中只能保管ASCII字符串,假如需求存取Unicode字符或者二进制数据,需求先进行编码。Cookie中也不能直接存取Java对象。若要存储略微复杂的信息,运用Cookie是比拟艰难的。
而Session中能够存取任何类型的数据,包括而不限于String、Integer、List、Map等。Session中也能够直接保管Java Bean乃至任何Java类,对象等,运用起来十分便当。能够把Session看做是一个Java容器类。
2、隐私策略的不同
Cookie存储在客户端阅读器中,对客户端是可见的,客户端的一些程序可能会窥探、复制以至修正Cookie中的内容。而Session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
假如选用Cookie,比较好的方法是,敏感的信息如账号密码等尽量不要写到Cookie中。最好是像Google、Baidu那样将Cookie信息加密,提交到服务器后再进行解密,保证Cookie中的信息只要本人能读得懂。而假如选择Session就省事多了,反正是放在服务器上,Session里任何隐私都能够有效的保护。
3、有效期上的不同
使用过Google的人都晓得,假如登录过Google,则Google的登录信息长期有效。用户不用每次访问都重新登录,Google会持久地记载该用户的登录信息。要到达这种效果,运用Cookie会是比较好的选择。只需要设置Cookie的过期时间属性为一个很大很大的数字。
由于Session依赖于名为JSESSIONID的Cookie,而Cookie JSESSIONID的过期时间默许为–1,只需关闭了阅读器该Session就会失效,因而Session不能完成信息永世有效的效果。运用URL地址重写也不能完成。而且假如设置Session的超时时间过长,服务器累计的Session就会越多,越容易招致内存溢出。
4、服务器压力的不同
Session是保管在服务器端的,每个用户都会产生一个Session。假如并发访问的用户十分多,会产生十分多的Session,耗费大量的内存。因而像Google、Baidu、Sina这样并发访问量极高的网站,是不太可能运用Session来追踪客户会话的。
而Cookie保管在客户端,不占用服务器资源。假如并发阅读的用户十分多,Cookie是很好的选择。关于Google、Baidu、Sina来说,Cookie或许是唯一的选择。
5、浏览器支持的不同
Cookie是需要客户端浏览器支持的。假如客户端禁用了Cookie,或者不支持Cookie,则会话跟踪会失效。关于WAP上的应用,常规的Cookie就派不上用场了。
假如客户端浏览器不支持Cookie,需要运用Session以及URL地址重写。需要注意的是一切的用到Session程序的URL都要进行URL地址重写,否则Session会话跟踪还会失效。关于WAP应用来说,Session+URL地址重写或许是它唯一的选择。
假如客户端支持Cookie,则Cookie既能够设为本浏览器窗口以及子窗口内有效(把过期时间设为–1),也能够设为一切阅读器窗口内有效(把过期时间设为某个大于0的整数)。但Session只能在本阅读器窗口以及其子窗口内有效。假如两个浏览器窗口互不相干,它们将运用两个不同的Session。(IE8下不同窗口Session相干)
6、跨域支持上的不同
Cookie支持跨域名访问,例如将domain属性设置为“.biaodianfu.com”,则以“.biaodianfu.com”为后缀的一切域名均能够访问该Cookie。跨域名Cookie如今被普遍用在网络中,例如Google、Baidu、Sina等。而Session则不会支持跨域名访问。Session仅在他所在的域名内有效。
仅运用Cookie或者仅运用Session可能完成不了理想的效果。这时应该尝试一下同时运用Cookie与Session。Cookie与Session的搭配运用在实践项目中会完成很多意想不到的效果。
(二)cookie
1.cookie产生的过程
1.浏览器第一次访问服务端时,服务器此时肯定不知道他的身份,所以创建一个独特的身份标识数据,格式为key=value,放入到Set-Cookie字段里,随着响应报文发给浏览器。
2.浏览器看到有Set-Cookie字段以后就知道这是服务器给的身份标识,于是就保存起来,下次请求时会自动将此key=value值放入到Cookie字段中发给服务端。
3.服务端收到请求报文后,发现Cookie字段中有值,就能根据此值识别用户的身份然后提供个性化的服务。
![Web[笔记] - 图7](/uploads/projects/zjj1994@javabasic/9d92a9206f1a4472df208d4ea470f53e.jpeg)
接下来我们用代码演示一下服务器是如何生成,我们自己搭建一个后台服务器,这里我用的是SpringBoot搭建的,并且写入SpringMVC的代码如下。
| @RequestMapping(“/testCookies”) public String cookies(HttpServletResponse response){ response.addCookie(new Cookie(“testUser”,”xxxx”)); return “cookies”; } |
|---|
项目启动以后我们输入路径http://localhost:8005/testCookies,然后查看发的请求。可以看到下面那张图使我们首次访问服务器时发送的请求,可以看到服务器返回的响应中有Set-Cookie字段。而里面的key=value值正是我们服务器中设置的值。
![Web[笔记] - 图8](/uploads/projects/zjj1994@javabasic/90768597feba0968d6d31a45c9445d0b.jpeg)
接下来我们再次刷新这个页面可以看到在请求体中已经设置了Cookie字段,并且将我们的值也带过去了。这样服务器就能够根据Cookie中的值记住我们的信息了。![Web[笔记] - 图9](/uploads/projects/zjj1994@javabasic/d3fc02a837c652569af5e87e5eff6776.jpeg)
接下来我们换一个请求呢?是不是Cookie也会带过去呢?接下来我们输入路径http://localhost:8005请求。我们可以看到Cookie字段还是被带过去了。![Web[笔记] - 图10](/uploads/projects/zjj1994@javabasic/6765db07d12bec049744de2dc7d9f410.jpeg)
那么浏览器的Cookie是存放在哪呢?如果是使用的是Chrome浏览器的话,那么可以按照下面步骤。
在计算机打开Chrome
在右上角,一次点击更多图标->设置
在底部,点击高级
在隐私设置和安全性下方,点击网站设置
依次点击Cookie->查看所有Cookie和网站数据
然后可以根据域名进行搜索所管理的Cookie数据。所以是浏览器替你管理了Cookie的数据,如果此时你换成了Firefox等其他的浏览器,因为Cookie刚才是存储在Chrome里面的,所以服务器又蒙圈了,不知道你是谁,就会给Firefox再次贴上小纸条。![Web[笔记] - 图11](/uploads/projects/zjj1994@javabasic/136e37ac0f15604062f281ab36507341.jpeg)
2.cookie机制概念
Cookies 是服务器在本地机器上存储的小段文本并随每一个请求发送至同一个服务器。IETF RFC 2965 HTTP State Management Mechanism 是通用 cookie 规范。网络服务器用 HTTP 头向客户端发送 cookies,在客户终端,浏览器解析这些 cookies 并将它们保存为一个本地文件,它会自动将同一服务器的任何请求缚上这些 cookies 。
具体来说 cookie 机制采用的是在客户端保持状态的方案。它是在用户端的会话状态的存贮机制,他需要用户打开客户端的 cookie 支持。cookie 的作用就是为了解决 HTTP 协议无状态的缺陷所作的努力。
正统的 cookie 分发是通过扩展 HTTP 协议来实现的,服务器通过在 HTTP 的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的 cookie。然而纯粹的客户端脚本如 JavaScript 也可以生成 cookie。而 cookie 的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的 cookie,如果某个 cookie 所声明的作用范围大于等于将要请求的资源所在的位置,则把该 cookie 附在请求资源的 HTTP 请求头上发送给服务器。
cookie 的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成 cookie 的作用范围。若不设置过期时间,则表示这个 cookie 的生命期为浏览器会话期间,关闭浏览器窗口,cookie 就消失。这种生命期为浏览器会话期的 cookie 被称为会话 cookie。会话 cookie 一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。若设置了过期时间,浏览器就会把 cookie 保存到硬盘上,关闭后再次打开浏览器,这些 cookie 仍然有效直到超过设定的过期时间。存储在硬盘上的 cookie 可以在不同的浏览器进程间共享,比如两个 IE 窗口。而对于保存在内存里的 cookie,不同的浏览器有不同的处理方式。
而 session 机制采用的是一种在服务器端保持状态的解决方案。同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以 session 机制可能需要借助于 cookie 机制来达到保存标识的目的。而 session 提供了方便管理全局变量的方式 。
session 是针对每一个用户的,变量的值保存在服务器上,用一个 sessionID 来区分是哪个用户 session 变量, 这个值是通过用户的浏览器在访问的时候返回给服务器,当客户禁用 cookie 时,这个值也可能设置为由 get 来返回给服务器。
就安全性来说:当你访问一个使用 session 的站点,同时在自己机子上建立一个 cookie,建议在服务器端的 session 机制更安全些,因为它不会任意读取客户存储的信息。
3.Cookie中的参数设置
说到这里,应该知道了Cookie就是服务器委托浏览器存储在客户端里的一些数据,而这些数据通常都会记录用户的关键识别信息。所以Cookie需要用一些其他的手段用来保护,防止外泄或者窃取,这些手段就是Cookie的属性。
| 参数名 | 作用 | 后端设置方法 |
|---|---|---|
| Max-Age | 设置cookie的过期时间,单位为秒 | cookie.setMaxAge(10) |
| Domain | 指定了Cookie所属的域名 | cookie.setDomain(“”) |
| Path | 指定了Cookie所属的路径 | cookie.setPath(“”); |
| HttpOnly | 告诉浏览器此Cookie只能靠浏览器Http协议传输,禁止其他方式访问 | cookie.setHttpOnly(true) |
| Secure | 告诉浏览器此Cookie只能在Https安全协议中传输,如果是Http则禁止传输 | cookie.setSecure(true) |
下面我就简单演示一下这几个参数的用法及现象。
Path
设置为cookie.setPath(“/testCookies”),接下来我们访问http://localhost:8005/testCookies,我们可以看到在左边和我们指定的路径是一样的,所以Cookie才在请求头中出现,接下来我们访问http://localhost:8005,我们发现没有Cookie字段了,这就是Path控制的路径。![Web[笔记] - 图12](/uploads/projects/zjj1994@javabasic/8ce3092ebee8bde09472a36a1154d8af.jpeg)
Domain
设置为cookie.setDomain(“localhost”),接下来我们访问http://localhost:8005/testCookies我们发现下图中左边的是有Cookie的字段的,但是我们访问[http://172.16.42.81:8005/testCookies](http://172.16.42.81:8005/testCookies),看下图的右边可以看到没有Cookie的字段了。这就是Domain控制的域名发送Cookie。
![Web[笔记] - 图13](/uploads/projects/zjj1994@javabasic/db3a9ba4bfd963d59f9145193b93ff2a.jpeg)
接下来的几个参数就不一一演示了,相信到这里大家应该对Cookie有一些了解了。
4.java代码操作Cooker
demo(无视掉 方法的返回值)
/**
cookie练习
*/
@GetMapping(“/lmxi”)
public R lmxi(HttpServletResponse response
, HttpServletRequest request){
/创建并且设置cookie (键值对形式)/
Cookie cookie = new Cookie(“cookieKey”,“cookieValue”);
/设置cookie的路径,目的如果java存放的路径和JavaScript存放的路径不一样
结果就是用JavaScript获取不到java设置的cookie,
* 如何查看JavaScript的cookie路径,你可以用JavaScript保存一个cookie
* 这样的话你就可以通过浏览器看到JavaScript的cookie路径了<br /> * */
cookie.setPath(**"/"**);
/通过response发送设置好的cookie
底层自动帮你写Set-Cookie的响应头
/
response.addCookie(cookie);
/*自动从请求头中获取cookie信息,并且切割并封装成多个cookie对象
是数组形式的*/
Cookie[] cookies = request.getCookies();
/打印的是地址值: cookies = [Ljavax.servlet.http.Cookie;@7417bdc9 ,
此时无法直接获取cookie的值 /
System.out.println(“cookies = “ + cookies);
/*
获取cookie的key方法:getName() 返回值String
获取cookie的value方法:getValue() 返回值String
循环遍历打印信息是:
cookie的key = cookieKey
cookie的value = cookieValue
/
*for (Cookie cookie1 : cookies) {System.out.println(“cookie的key = “ + cookie1.getName());
System.out.println(“cookie的value = “ + cookie1.getValue());
}
return R.ok();
![Web[笔记] - 图14](/uploads/projects/zjj1994@javabasic/fc877cb1a6a77e7f40c352a394950614.jpeg)
5.cookie不能跨域
很多人在初学的时候可能有一个疑问:在访问Servlet的时候浏览器是不是把所有的Cookie都带过去给服务器,会不会修改了别的网站的Cookie.
答案是否定的。Cookie具有不可跨域名性。浏览器判断一个网站是否能操作另一个网站的Cookie的依据是域名。所以一般来说,当我访问baidu的时候,浏览器只会把baidu颁发的Cookie带过去,而不会带上google的Cookie。
6.Cookie的有效期以及设置
Cookie的有效期是通过setMaxAge()来设置的。
如果MaxAge为正数,浏览器会把Cookie写到硬盘中,只要还在MaxAge秒之前,登陆网站时该Cookie就有效【不论关闭了浏览器还是电脑】
如果MaxAge为负数,Cookie是临时性的,仅在本浏览器内有效,关闭浏览器Cookie就失效了,Cookie不会写到硬盘中。Cookie默认值就是-1。这也就为什么在我第一个例子中,如果我没设置Cookie的有效期,在硬盘中就找不到对应的文件。
如果MaxAge为0,则表示删除该Cookie。Cookie机制没有提供删除Cookie对应的方法,把MaxAge设置为0等同于删除Cookie
Cookie的生命周期:
一般情况:会话级别cookie,保存在浏览器的缓存中。默认情况下,关闭当前会话,浏览器保存的cookie会全部消失
会话开启 —————-(cookie存活)—————会话结束——(cookie销毁的)
这里的会话级别一般指的是浏览器打开到浏览器关闭.
特殊情况:持久化cookie,保存在浏览器对应的硬盘上,
手动设置Cookie的有效期方法:cookie.setMaxAge(60602430); // 设置最大生存时间(秒) 参数里面写时间
-1 会话级别的cookie。默认
>0 会把cookie持久化保存硬盘上
如果cookie过期了,浏览器就不会传递这个cookie了
关闭或移除cookie:0 立即过期
*设置有效期的原理:设置有效时间的Cookie,浏览器会把Cookie数据保存到磁盘文件上,关闭浏览器再打开浏览器Cookie会一直存在,直到Cookie超过有效期 自动失效为止。注意:手动清除浏览器缓存,可以清除所有Cookie
Cookie的有效路径
默认情况下,访问 生成Cookie的资源所在的路径 才会携带Cookie
比如:
/day37_cookie_session/aa/cookie1 生成的Cookie
/day37_cookie_session/aa 生成Cookie的资源所在的路径,这个路径是有效路径
访问/day37_cookie_session/cookie2 不在有效路径里,所以客户端不会携带Cookie
访问/day37_cookie_session/aa/cookie.html 在有效路径里,客户端会携带这个Cookie
手动设置有效路径:
cookie.setPath(String uri);//cookie.setPath(“/day37_cookie_session”);
或者里面写 request.getContextPath()
清除客户端已经存在的Cookie(了解)
并没有实际删除客户端已经存在的Cookie的方法。要实现这样的效果,做法:创建一个同name同path的Cookie把Cookie的有效期设置为0,把这个Cookie发送到客户端,会覆盖掉原有的Cookie,有效期为0,已过期
7.Cookie保存中文
中文属于Unicode字符,英文数据ASCII字符,中文占4个字符或者3个字符,英文占2个字符。
解决:Cookie使用Unicode字符时需要对Unicode字符进行编码。
保存cookie
//对Unicode字符进行编码
Cookie cookie = new Cookie(“country”,URLEncoder.encode(name, “UTF-8”));
取出cookie的值
我们发现Cookie保存在硬盘的中文数据是经过编码的,那么我们在取出Cookie的时候要对中文数据进行解码
Cookie[]cookies = request.getCookies();
for(int i =0;cookies != null &&i
String name = cookies[i].getName();
//经过URLEncoding就要URLDecoding
String value =URLDecoder.decode(cookies[i].getValue(),”UTF-8”);
printWriter.write (name +”———“+value);
}
8.JavaScript操作cookie
/添加cookie/
$(function(){
/*练习 cookie*/
**$**.ajax({
**type**:**"get"**,
**url**:**"/api/emergency/emergencyplan/lmxi"**,
success:**function**(){
/*设置cookie 设置cookie值其实可以从ajax的回调函数里面来获取<br /> * */<br /> **document**.**cookie**=**"key属性=这个是value属性"**;
}<br /> })<br /> <br /> <br />查看浏览器这时候就有cookie了<br />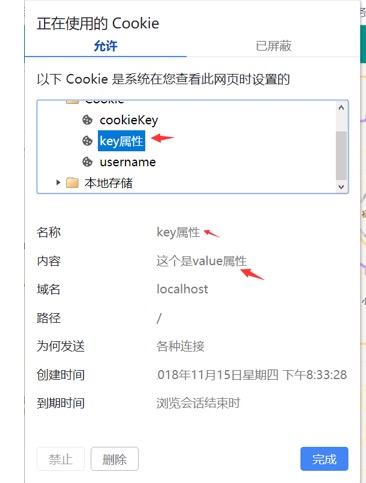<br />在别的js代码获取cookie<br />**$**(**'#addYJSJ-show'**).click(**function**() {
/*获取cookie的值并且打印出来*/
**var **x = **document**.**cookie**;
alert(x)<br />
})
打印的是两个cookie,第一个cookie是之前设置的,只要你浏览器没有关闭cookie就一直存在,一旦关闭cookie就消失了.
想要使用就得切割了.![Web[笔记] - 图15](/uploads/projects/zjj1994@javabasic/ba9d723c57e05585656927d62a6a9ba0.jpeg)
9.JavaScript获取java设置的cookie.
JavaScript获取cookie的方式不变,还是 var x = document.cookie; 来获取 ,然后alert(x) 查看cookie的内容,需要注意的是,如果java设置的cookie路径和JavaScript的cookie路径不一样的话,是无法通过JavaScript获取java设置的cookie的.如何查看JavaScript的cookie路径,你可以用JavaScript保存一个cookie 这样的话你就可以通过浏览器看到JavaScript的cookie路径了
/**
cookie session练习
*/
@GetMapping(“/lmxi”)
public R lmxi(HttpServletResponse response
, HttpServletRequest request){
/创建并且设置cookie (键值对形式)/
Cookie cookie = new Cookie(“java”,“从java代码创建的cookie”);
/设置cookie的路径,目的如果java存放的路径和JavaScript存放的路径不一样
结果就是用JavaScript获取不到java设置的cookie,
如何查看JavaScript的cookie路径,你可以用JavaScript保存一个cookie
这样的话你就可以通过浏览器看到JavaScript的cookie路径了
/
/!!!!!!重点是在这里,设置cookie的路径/cookie.setPath(“/“);
/*通过response发送设置好的cookie
底层自动帮你写Set-Cookie的响应头
*/
response.addCookie(cookie);/*自动从请求头中获取cookie信息,并且切割并封装成多个cookie对象
是数组形式的*/
Cookie[] cookies = request.getCookies();
return R.ok();
}
![Web[笔记] - 图16](/uploads/projects/zjj1994@javabasic/62f0bfeefce47efd7376af01a1954b72.jpeg)
$(‘#addYJSJ-show’).click(function() {
/*获取cookie的值并且打印出来*/
**var **x = **document**.**cookie**;
alert(x)
}
})
![Web[笔记] - 图17](/uploads/projects/zjj1994@javabasic/1134d54c3d05af65e796fef938da867b.jpeg)
(三)Session
Session 是另一种记录浏览器状态的机制。不同的是Cookie保存在浏览器中,Session保存在服务器中。用户使用浏览器访问服务器的时候,服务器把用户的信息以某种的形式记录在服务器,这就是Session.
使用Cookie和附加URl参数都可以讲上一次请求的状态信息传递到下一次请求中,但是如果传递的状态信息较多,将极大降低网络传输效率和增大服务端程序处理的难度,即使这样,传递的信息也是非常有限的,为此,各种服务器端的开发方案都提供了一种将会话状态保存在服务器端的技术,即Session技术.
当程序需要为某个客户端的请求创建一个 session 时,服务器首先检查这个客户端的请求里是否已包含了一个 session 标识(称为 session id),如果已包含则说明以前已经为此客户端创建过 session,服务器就按照 session id 把这个 session 检索出来使用(检索不到,会新建一个),如果客户端请求不包含 session id,则为此客户端创建一个 session 并且生成一个与此 session 相关联的 session id,session id 的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个 session id 将被在本次响应中返回给客户端保存。
保存这个 session id 的方式可以采用 cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发挥给服务器。一般这个 cookie 的名字都是类似于 SEEESIONID。但 cookie 可以被人为的禁止,则必须有其他机制以便在 cookie 被禁止时仍然能够把 session id 传递回服务器。
经常被使用的一种技术叫做 URL 重写,就是把 session id 直接附加在 URL 路径的后面。还有一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把 session id 传递回服务器。
Cookie 与 Session 都能够进行会话跟踪,但是完成的原理不太一样。普通状况下二者均能够满足需求,但有时分不能够运用 Cookie,有时分不能够运用 Session。
什么时候创建session对象:当客户端没有携带JSESSIONID,在执行request.getSession()方法时会创建新的session对象
什么时候获取原有的session对象:当客户端携带了JSESSIONID,在执行request.getSession()方法时,会获取到JSESSIONID对应 的session对象,而不再创建。
![Web[笔记] - 图18](/uploads/projects/zjj1994@javabasic/7d9b284560fe7a6c57206d5626ab2ddf.jpeg)
1 如何保证在一次会话中,使用的都是一个session对象。
session基于cookie(JSESSIONID) ,session中的数据:只能在一次会话中存活
2 为什么浏览器关闭了,session对象就换了呢?浏览器一关闭cookie销毁,里面的jsessionid丢失了,就无法对应之前的session对象。服务器发现你没有jsessionid,就判断你是第一次来,就会给你再创建一个新的session对象。
1.session简介
Cookie是存储在客户端方,Session是存储在服务端方,客户端只存储SessionId
在上面我们了解了什么是Cookie,既然浏览器已经通过Cookie实现了有状态这一需求,那么为什么又来了一个Session呢?这里我们想象一下,如果将账户的一些信息都存入Cookie中的话,一旦信息被拦截,那么我们所有的账户信息都会丢失掉。所以就出现了Session,在一次会话中将重要信息保存在Session中,浏览器只记录SessionId一个SessionId对应一次会话请求。
![Web[笔记] - 图19](/uploads/projects/zjj1994@javabasic/5bacb48e6ef2336cd9295f55653750bc.jpeg)
| @RequestMapping(“/testSession”) @ResponseBody public String testSession(HttpSession session){ session.setAttribute(“testSession”,”this is my session”); return “testSession”; } @RequestMapping(“/testGetSession”) @ResponseBody public String testGetSession(HttpSession session){ Object testSession = session.getAttribute(“testSession”); return String.valueOf(testSession); } |
|---|
这里我们写一个新的方法来测试Session是如何产生的,我们在请求参数中加上HttpSession session,然后再浏览器中输入http://localhost:8005/testSession进行访问可以看到在服务器的返回头中在Cookie中生成了一个SessionId。然后浏览器记住此SessionId下次访问时可以带着此Id,然后就能根据此Id找到存储在服务端的信息了。
![Web[笔记] - 图20](/uploads/projects/zjj1994@javabasic/318430228c0126ed512876b9e9a024dc.jpeg)
此时我们访问路径http://localhost:8005/testGetSession,发现得到了我们上面存储在Session中的信息。那么Session什么时候过期呢?
客户端:和Cookie过期一致,如果没设置,默认是关了浏览器就没了,即再打开浏览器的时候初次请求头中是没有SessionId了。
服务端:服务端的过期是真的过期,即服务器端的Session存储的数据结构多久不可用了,默认是30分钟。
![Web[笔记] - 图21](/uploads/projects/zjj1994@javabasic/3e1d3c486d554a71b4c5f9b5542676a3.jpeg)
既然我们知道了Session是在服务端进行管理的,那么或许你们看到这有几个疑问,Session是在在哪创建的?Session是存储在什么数据结构中?接下来带领大家一起看一下Session是如何被管理的。
Session的管理是在容器中被管理的,什么是容器呢?Tomcat、Jetty等都是容器。接下来我们拿最常用的Tomcat为例来看下Tomcat是如何管理Session的。在ManageBase的createSession是用来创建Session的。
| @Override public Session createSession(String sessionId) { //首先判断Session数量是不是到了最大值,最大Session数可以通过参数设置 if ((maxActiveSessions >= 0) && (getActiveSessions() >= maxActiveSessions)) { rejectedSessions++; throw new TooManyActiveSessionsException( sm.getString(“managerBase.createSession.ise”), maxActiveSessions); } // 重用或者创建一个新的Session对象,请注意在Tomcat中就是StandardSession // 它是HttpSession的具体实现类,而HttpSession是Servlet规范中定义的接口 Session session = createEmptySession(); // 初始化新Session的值 session.setNew(true); session.setValid(true); session.setCreationTime(System.currentTimeMillis()); // 设置Session过期时间是30分钟 session.setMaxInactiveInterval(getContext().getSessionTimeout() 60); String id = sessionId; if (id == null) { id = generateSessionId(); } session.setId(id);// 这里会将Session添加到ConcurrentHashMap中 sessionCounter++; //将创建时间添加到LinkedList中,并且把最先添加的时间移除 //主要还是方便清理过期Session SessionTiming timing = new SessionTiming(session.getCreationTime(), 0); synchronized (sessionCreationTiming) { sessionCreationTiming.add(timing); sessionCreationTiming.poll(); } *return session } |
|---|
到此我们明白了Session是如何创建出来的,创建出来后Session会被保存到一个ConcurrentHashMap中。可以看StandardSession类。
| protected Map |
|---|
到这里大家应该对Session有简单的了解了。
> Session是存储在Tomcat的容器中,所以如果后端机器是多台的话,因此多个机器间是无法共享Session的,此时可以使用Spring提供的分布式Session的解决方案,是将Session放在了Redis中。
2.session生命周期和有效期
- Session在用户第一次访问服务器Servlet,jsp等动态资源就会被自动创建,Session对象保存在内存里
2. 如果访问HTML,IMAGE等静态资源Session不会被创建。
3. Session生成后,只要用户继续访问,服务器就会更新Session的最后访问时间,无论是否对Session进行读写,服务器都会认为Session活跃了一次。
4. 由于会有越来越多的用户访问服务器,因此Session也会越来越多。为了防止内存溢出,服务器会把长时间没有活跃的Session从内存中删除,这个时间也就是Session的超时时间。
5. Session的超时时间默认是30分钟.
6. Session的有效期与Cookie是不同的,session的周期指的是不活动的时间,如果我们设置session 是10秒,在10秒内,没有访问session,session中属性就会失效,如果在9秒的时候,你访问了session,则会重新计时
7. 如果你重启了Tomcat,或者reload web应用,session就会失效.
8. cookie的生命周期是按累计时间来计算的,不管你用户有没有访问session.
3.session实现原理
用现象说明问题,我在Servlet4中的代码设置了Session的属性
//得到Session对象
HttpSession httpSession = request.getSession();
//设置Session属性
httpSession .setAttribute(“name”,”看完博客就要点赞!!”);
接着在Servlet7把Session的属性取出来
String value =(String)request.getSession().getAttribute(“name”);
printWriter.write(value);
自然地,我们能取到在Servlet4中Session设置的属性![Web[笔记] - 图22](/uploads/projects/zjj1994@javabasic/d6f8ac32361edd68e062ff4b91ab56cd.jpeg)
接着,我在浏览器中新建一个会话,再次访问Servlet7![Web[笔记] - 图23](/uploads/projects/zjj1994@javabasic/a24da0d92a6b9467796d8b233623cd43.jpeg)
再次访问接口访问空指针异常了.![Web[笔记] - 图24](/uploads/projects/zjj1994@javabasic/6939abbb896caf353928534dc72d225c.jpeg)
疑问: 服务器是如何实现一个session为一个用户浏览器服务的.(为什么服务器能够为不同的用户浏览器提供不同的session)?
HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一个用户。于是乎:服务器向用户浏览器发送了一个名为JESSIONID的Cookie,它的值是Session的id值。其实Session依据Cookie来识别是否是同一个用户。
简单来说:Session 之所以可以识别不同的用户,依靠的就是Cookie
该Cookie是服务器自动颁发给浏览器的,不用我们手工创建的。该Cookie的maxAge值默认是-1,也就是说仅当前浏览器使用,不将该Cookie存在硬盘中.
我们来捋一捋思路流程:当我们访问Servlet4的时候,服务器就会创建一个Session对象,执行我们的程序代码,并自动颁发个Cookie给用户浏览器.![Web[笔记] - 图25](/uploads/projects/zjj1994@javabasic/d111d96c54fab84ee1b3298c35e2f15e.jpeg)
当我们用同一个浏览器访问Servlet7的时候,浏览器会把Cookie的值通过http协议带过去给服务器,服务器就知道用哪一Session。![Web[笔记] - 图26](/uploads/projects/zjj1994@javabasic/744c198f67aed32965409f79f63f84b2.jpeg)
而当我们使用新会话的浏览器访问Servlet7的时候,该新浏览器并没有Cookie,服务器无法辨认使用哪一个Session,所以就获取不到值
浏览器禁用了Cookie,Session还能用吗?
上面说了Session是依靠Cookie来识别用户浏览器的。如果我的用户浏览器禁用了Cookie了呢?绝大多数的手机浏览器都不支持Cookie,那我的Session怎么办?
解决方案是 URL地址重写
4.java操作Session
特别提示,在利用session保存数据的时候,如果以后不需要使用session了请及时清除掉session,否则会出现数据错乱问题,比如我上传图片信息保存到session了,然后我保存商品同时进行关联保存时候读取了session的图片信息后, 在关联保存完同时就需要根据session的key清除掉这个对应的session,不然我下次没有再上传图片的时候进行保存商品,读取的session里面的数据是上一个保存的数据,这样就会造成数据错乱.
获取session
HttpSession对象在用户第一次访问网站的时候自动被创建, 你可以通过调用HttpServletRequest的getSession方法获取该对象。 getSession有两个重载方法:
HttpSession getSession()
HttpSession getSession(boolean create)
没有参数的getSession方法会返回当前的HttpSession, 若当前没有, 则创建一个返回。
getSession(false)返回当前HttpSession, 如当前存在, 则返回null
getSession(true)返回当前HttpSession, 若当前没有, 则创建一个getSession(true)同getSession()一致。
获取值
setAttribute()与getAttribute()
可以通过HttpSession的setAttribute方法将值放入HttpSession, 该方法签字如下:
void setAttribute(java.lang.String name, java.lang.Object value)
1请注意, 不同于URL重新、 隐藏域或cookie, 放入到HttpSession 的值, 是存储在内存中的, 因此, 不要往HttpSession放入太多对象或大对象。 尽管现代的Servlet容器在内存不够用的时候会将保存在HttpSessions的对象转储到二级存储上, 但这样有性能问题, 因此小心存储。
注意放到HttpSession的值不限于String类型, 可以是任意实现java.io.Serializable的java对象, 因为Servlet容器认为必要时会将这些对象放入文件或数据库中, 尤其在内存不够用的时候, 当然你也可以将不支持序列化的对象放入HttpSession, 只是这样, 当Servlet容器视图序列化的时候会失败并报错。
调用setAttribute方法时, 若传入的name参数此前已经使用过, 则会用新值覆盖旧值。
通过调用HttpSession的getAttribute方法可以取回之前放入的对象, 该方法的签名如下:
java.lang.Object getAttribute(java.lang.String name)
1HttpSession 还有一个非常有用的方法, 名为getAttributeNames, 该方法会返回一个Enumeration 对象来迭代访问保存在HttpSession中的所有值:
java.util.Enumeration
1注意, 所有保存在HttpSession的数据不会被发送到客户端, 不同于其他会话管理技术, Servlet容器为每个HttpSession 生成唯一的标识, 并将该标识发送给浏览器, 或创建一个名为JSESSIONID的cookie, 或者在URL后附加一个名为jsessionid 的参数。 在后续的请求中, 浏览器会将标识提交给服务端, 这样服务器就可以识别该请求是由哪个用户发起的。 Servlet容器会自动选择一种方式传递会话标识, 无须开发人员介入。
可以通过调用 HttpSession的getId方法来读取该标识:
java.lang.String getId()
HttpSession的过期设置
HttpSession.还定义了一个名为invalidate 的方法。 该方法强制会话过期, 并清空其保存的对象。 默认情况下, HttpSession 会在用户不活动一段时间后自动过期, 该时间可以通过部署描述符的 session-timeout元素配置, 若设置为30, 则会话对象会在用户最后一次访问30分钟后过期, 如果部署描述符没有配置, 则该值取决于Servlet容器的设定。
大部分情况下, 你应该主动销毁无用的HttpSession, 以便释放相应的内存。
HttpSession 的getMaxInactiveInterval方法可以查看会话多久会过期。 该方法返回一个数字类型, 单位为秒。 调用setMaxInactiveInterval 方法来单独对某个HttpSession 设定其超时时间:
void setMaxInactiveInterval(int seconds)
若设置为0, 则该HttpSession 永不过期。 通常这不是一个好的设计, 因此该 HttpSession 所占用的堆内存将永不释放, 直到应用重加载或Servlet容器关闭。
Session API
long getCreationTime();【获取Session被创建时间】
String getId();【获取Session的id】
long getLastAccessedTime();【返回Session最后活跃的时间】
ServletContext getServletContext();【获取ServletContext对象】
void setMaxInactiveInterval(int var1);【设置Session超时时间】
int getMaxInactiveInterval();【获取Session超时时间】
Object getAttribute(String var1);【获取Session属性】
Enumeration getAttributeNames();【获取Session所有的属性名】
void setAttribute(String var1, Object var2);【设置Session属性】
void removeAttribute(String var1);【移除Session属性】
void invalidate();【销毁该Session】
boolean isNew();【该Session是否为新的】
|
public R lmxi(HttpServletResponse response
, HttpServletRequest request){
/创建session/
HttpSession session = request.getSession();
/存数据到session域里面/
session.setAttribute(“JavaKey”,“从java代码里面获取的session”);
/根据key获取session/
Object key = session.getAttribute(“JavaKey”);
/输出结果: AAAAA——-:从java代码里面获取的session/
System.out.println(“AAAAA——-:”+key);
/根据key删除session/
session.removeAttribute(“JavaKey”);
/输出结果: BBBBB——-:null/
Object key2 = session.getAttribute(“JavaKey”);
System.out.println(“BBBBB——-:”+key2) ;
return R.ok();
} |
| —- |
| /获取session/
HttpSession session = request.getSession();
/获取session的id/
String id = session.getId();
/打印: id = e38b49e2-24ec-4937-8c14-92066db23bf5/
System.out.println(“id = “ + id);
/*判断session是不是新创建的 session.isNew()
- 第一次打开浏览器访问网址session就是新创建的,id也是重新分配的
- 如果你不关闭浏览器再访问用的还是以前的session,id也是以前的
- 如果你关闭浏览器了 再打开就会创建新的session,id也会重新分配
- /
System.out.println(session.isNew()?“是新创建的”:“不是新创建的”);/设置session的有效期,是当前会话的失效时间 ,以秒为单位/
session.setMaxInactiveInterval(30 60); | | —- |
5.session域对象生命周期
创建:第一次调用getSession()方法的时候
销毁:
1、主动销毁 invalidate();
2、session 30分钟自动过期,过期后销毁(离开电脑30分钟不点击)
tomcat配置文件中:
tomcat/conf/web.xml
3、服务器非正常关闭 [断电、强制关机重启、]
【服务器正常关闭,session不销毁】
【浏览器关闭,session也不销毁,但是找不到了】
6.session共享的几种方式
详细说明:
https://www.cnblogs.com/lyjin/p/6293570.html
1.基于IP地址的Hash策略:
将同一用户的请求都集中在一台服务器上,这台服务器上保存了该用户的Session信息。
缺点:单点部署发生宕机时,Session丢失。
2.每台tomcat都存一份:
可以用Tomcat自带的插件进行Session同步,使得多台应用服务器之间自动同步Session,保持一致。如果一台发生故障,负载均衡会遍历寻找可用节点,Session也不会丢失。缺点:必须是Tomcat和Tomcat之间,Session的复制也会消耗系统的性能,使得同步给成员时容易造成内网流量瓶颈。
3.基于Redis的Session共享实现
1)原理:写一个Session过滤器拦截每一次请求,在这里检查由Cookie生成的SessionID,进行创建或获取。核心是实现使用装饰类,实现Session在Redis中的存取操作。
2)此处存取方式为 sessionID+sessionKey作为Redis的key ==== sessionValue作为Redis的value,这样保存了每次存取都从Redis中操作,效率更高。
3)注意:序列化方式推荐使用Apache下Commons组件——SerializationUtils 或 org.springframework.util.SerializationUtils。
![Web[笔记] - 图27](/uploads/projects/zjj1994@javabasic/75ab6c324a92476f17c83e74732e5981.jpeg)
7.什么情况下,会找不到session里的数据
- 客户端的JSESSIONID丢失了,找不到原本的session对象,session里的数据也会找不到
2. 客户端的JSESSIONID没有丢失,但是session对象销毁了,session里的数据会找不到
(四)sessionid
浏览器第一次请求服务器时,服务器会生成一个sessionId,并返回给浏览器,这个sessionId会被保存在浏览器的会话cookie中。如下图![Web[笔记] - 图28](/uploads/projects/zjj1994@javabasic/3b6753d04a0083056f0c72ac64c27bc3.jpeg)
在浏览器不关闭的情况下,之后的每次请求请求头都会携带这个sessionId到服务器。如下图![Web[笔记] - 图29](/uploads/projects/zjj1994@javabasic/ca4973389d04d8b2d49abce29249012f.jpeg)
session在服务器的默认有效时间是30分钟,可以通过3种方式去设置session的过期时间(具体那三种可以百度),下面通过代码的方式设置session过期时间为180秒
request.getSession().setMaxInactiveInterval(30*6);
在第二次请求3分钟后我们进行第三次请求,这个时候服务器中原有的session已经过期,所以服务器会生成一个新的sessionId返回给浏览器,并替换掉cookie中之前的sessionId,第三次请求cookie携带的还是之前的sessionId。如下图![Web[笔记] - 图30](/uploads/projects/zjj1994@javabasic/164a562750c7736a07d17aacf3048417.jpeg)
浏览器再次请求,cookie就会携带新的sessionId到服务器,如下图![Web[笔记] - 图31](/uploads/projects/zjj1994@javabasic/0363e48c89a273816bc48b6a60100052.jpeg)
通过sessionId我们可以做登陆过期,会话期间无需二次登陆等功能。
过滤器Filter
(一)概念
过滤器拦截的是URL![Web[笔记] - 图32](/uploads/projects/zjj1994@javabasic/df227c740a178ebc6bdb3d34026b6b7c.jpeg)
假如客户端要想访问servlet1的时候,先进入服务器软件内核—-进入过滤器Filter1—如果还有符合拦截条件的过滤器就还进入别的过滤器——到达servlet1
如果任何一个过滤器没有放行,那么request就没有传入到servlet里面
过滤器工作流程:客户端发起请求之后,在请求到达服务端之前,有一个东西先把他们拦截下来过滤一下,符合我们条件的放行,不符合条件的不放行,不符合的也可以改造一下再放行.
过滤器可以在客户端发起请求之后,请求到达目标资源之前,先对requset和response做一些预处理。然后把处理之后的request和response放行,最终到达目标资源。
Filter技术也是Servlet规范和的一种,开发模式和步骤和Servlet的开发步骤非常相似。
Filter技术:符合条件允许放行,不符合条件不允许放行,主要是用来对浏览器的请求进行过滤的
Spring中自定义过滤器(Filter)一般只有一个方法,返回值是void,当请求到达web容器时,会探测当前请求地址是否配置有过滤器,有则调用该过滤器的方法(可能会有多个过滤器),然后才调用真实的业务逻辑,至此过滤器任务完成。过滤器并没有定义业务逻辑执行前、后等,仅仅是请求到达就执行。
特别注意:过滤器方法的入参有request,response,FilterChain,其中FilterChain是过滤器链,使用比较简单,而request,response则关联到请求流程,因此可以对请求参数做过滤和修改,同时FilterChain过滤链执行完,并且完成业务流程后,会返回到过滤器,此时也可以对请求的返回数据做处理。
具体的看这个文档
![Web[笔记] - 图33](/uploads/projects/zjj1994@javabasic/c4243014c57dd698b79edfcd0bb3b2ed.jpeg)
(二)使用
- 创建Java类,实现Filter接口
2. 重写接口的方法(共有3个方法,重点关注doFilter方法)
注意,必须得重写这三个方法,不能只重写一个方法
,不然会报错(java.lang.AbstractMethodError)
3. 在web.xml里配置Filter(主要是配置过滤器要拦截哪些请求)
先创建一个java类实现Filter接口
| package com.lanmili.filter;
import javax.servlet.;
import java.io.IOException;
public class VerifyTokenFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
/*
* 在这里写业务逻辑<br />
*/<br />
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println(“———————“);
chain.doFilter(request, response);//这是放行的方法,如果不添加这个方法将永远不能放行
}
@Override
public void destroy() {
}
} |
| —- |
在去web.xml里面注册过滤器,只有注册之后服务器软件通过web.xml文件才能知道有过滤器存在.
| <filter>
<filter-name>VerifyTokenFilter</filter-name>
<filter-class>com.lanmili.filter.VerifyTokenFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>VerifyTokenFilter</filter-name>
<url-pattern>/</url-pattern>
</*filter-mapping> |
| —- |
1.API
init(FilterConfig filterConfig)
init是初始化的方法,服务器创建的时候,服务器软件会自动执行init方法init 方法在 Filter 生命周期中仅被执行一次
Web 容器在调用 init 方法时,会传递一个包含 Filter 的配置和运行环境信息的 FilterConfig 对象。
开发人员可以在 init 方法中完成与构造方法类似的初始化功能,要注意的是:如果初始化代码要使用到 FilterConfig 对象,这些代码只能在 init 方法中编写,而不能在构造方法中编写(尚未调用 init 方法,即并没有创建 FilterConfig 对象,要使用它则必然出错)。
参数作用:
1 可以获取当前filter的名称 filterConfig.getFilterName();
2.获取Filter的初始化参数 String aa = config.getInitParameter(“aa”);
获取所有的初始化参数(得到的是枚举对象,需要循环遍历取出)
Enumeration
while(names.hasMoreElements()){
String name = names.nextElement();
String value = config.getInitParameter(name);
System.out.println(name + “ : “ + value);
}
3. 获取ServletContext对象ServletContext context = config.getServletContext();
FilterConfig 接口
1、与普通的 Servlet 程序一样,Filter 程序也很可能需要访问 Servlet 容器。Servlet 规范将代表 ServletContext 对象和 Filter 的配置参数信息都封装到一个称为 FilterConfig 的对象中。
2、FilterConfig 接口则用于定义 FilterConfig 对象应该对外提供的方法,以便在 Filter 程序中可以调用这些方法来获取 ServletContext 对象,以及获取在 web.xml 文件中为 Filter 设置的友好名称和初始化参数。
3、FilterConfig接口定义的各个方法:
getFilterName 方法,返回
getServletContext 方法,返回 FilterConfig 对象中所包装的 ServletContext 对象的引用。
getInitParameter 方法,用于返回在 web.xml 文件中为 Filter 所设置的某个名称的初始化的参数值。
getInitParameterNames 方法,返回一个 Enumeration 集合对象。
doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain)
当一个 Filter 对象能够拦截访问请求时,Servlet 容器将调用 Filter 对象的 doFilter 方法。
其中,参数 request 和 response 为 Web 容器或 Filter 链中上一个 Filter 传递过来的请求和响应对象;参数 chain 为代表当前 Filter 链的对象。
参数:
ServletRequest:代表http请求的request
ServletResponse:代表http响应的response
FilterChain
FilterChain 接口的 doFilter 方法用于通知 Web 容器把请求交给 Filter 链中的下一个 Filter 去处理,如果当前调用此方法的 Filter 对象是Filter 链中的最后一个 Filter,那么将把请求交给目标 Servlet 程序去处理。
FilterChain:过滤器链对象,维护了要执行的过滤器的队列(比如本次请求可能有一堆过滤器请求拦截,
可能就一堆排队等着拦截过滤)
chain.doFilter(request, response);//放行请求
destroy()
该方法在 Web 容器卸载 Filter 对象之前被调用,也仅执行一次。可以完成与 init 方法相反的功能,释放被该 Filter 对象打开的资源,例如:关闭数据库连接和 IO 流。
2.过滤器的拦截方式
过滤器的拦截方式一共有4种,
REQUEST、FORWARD、INCLUDE、ERROR
默认是请求的方式:只有直接来源于浏览器的请求,才经过过滤器
| 过滤类型 | 作用 |
|---|---|
| REQUEST | 直接来源于浏览器的访问地址,(包含重定向) |
| FORWARD | 转发的时候经过过滤器 |
| INCLUDE | 页面包络另一个页面访问时也经过过滤器 |
| ERROR | 页面错误时经过过滤器 |
参考:
https://blog.csdn.net/Kato_op/article/details/80214456
(三)Filter的配置(在web.xml里面配置)
filter的匹配方式写法:3种
1 完全路径匹配: /sd1 /a/b/c/sd1 也可以/aaa/
2 目录匹配: /
3 扩展名匹配 .aaa .bbb
特点:
1 如果一个资源被多个filter都匹配成功是都执行
执行顺序是按照
2
标签
取值:REQUEST (默认值) 默认只拦截从浏览器过来的请求
FORWORD 只拦截请求转发的
总结:filter默认是只拦截浏览器过来的请求,不拦截请求转发的
如果想让filter拦截请求转发的,需要将
如果设置了这个值,需要注意的是:此时filter只拦截请求转发不拦截浏览器过来的
如果想让filter既拦截浏览器过来的又拦截请求转发的,需要2个都设置
———![Web[笔记] - 图34](/uploads/projects/zjj1994@javabasic/0bebd8db60c4062444497c2a92ed8a29.jpeg)
这是跳转错误页面的代码
(四)对方法功能进行增强
- 动态代理(语法难以理解,不常用)
2. 继承,然后重写父类的方法
3. 装饰者模式,把原本的对象进行包装,包装后的对象可以重写被包装对象的方法。
a) 创建装饰者类,要和被装饰者实现同一接口
b) 装饰者类里要有一个私有变量,在构造方法里把被包装的对象赋值给这个变量
c) 需要增强的方法,调用被装饰者的方法,然后再增加一些功能
d) 不需要增强的方法,直接调用被装饰者的方法即可(五)Filter的生命周期
3个和filter生命周期相关的方法:
初始化方法:init(FilterConfig filterConfig)
核心过滤方法:doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
销毁方法:destroy()
生命周期:当服务器启动的时候,先创建filter对象执行init方法
当浏览器访问到了要匹配的资源,filter的dofilter会执行,访问一次执行一次
当服务器关闭的时候,filter的destory方法执行
监听器Listener
(一)基本概念
listener:本质上是一个类,这个类是对其它javabean的状态变化进行监听的.重要程度最重要的时候Servlet,其次是Filter, 而监听器Listener用的就很少了,监听器类似js里面的事件可以监听某个对象的状态变化,一旦监听到状态变化,就可以完成某些工作。
作用:是对3个域对象的监听(ServletContext,ServletRequest,HttpSession)
1 监听3个域对象的创建和销毁
2 监听3个域对象属性的变化(XXXAttribute)
3 监听javabean在session中的状态变化
比如:javabean是否存在了session 是否从session中移除了
javabean是否被session带着序列化到磁盘 javabean是否被session带着序列化回服务器的内存中了(二)JS的事件和Listener事件对比
js里边事件相关的概念:
事件源:被监听的对象,一般指html标签
事件:用来监听事件源状态变化的。onclick, onsubmit, onchange, onload…..
响应行为:监听到事件源状态变化后,要执行代码
监听器里相关的概念:
事件源:被监听的对象。在JavaEE里边一般指三个域对象:context, session, requset(没有page域,因为太小了.)
监听器:用来监听事件状态变化的。有6+2个监听器
响应行为:监听到事件源状态变化以后,要执行的代码。需要我们编写代码来完成了
总结就是Listener就相当于java里面的事件.
使用场景:使用监听器完成定时发送生日祝福邮件.(三)有哪些监听器
java已经提供了大量的监听器接口,每个监听器接口的作用不一样
监听3个域对象的创建和销毁:第一类监听器
ServletContextListener(必掌握)
ServletRequestListener
HttpSessionListener
监听3个域对象属性的变化: 第二类监听器
ServletContextAttributeListener
ServletRequestAttributeListener
HttpSessionAttributeListener
监听javabean在session中状态变化:第三类监听器
HttpSessionBindingListener
HttpSessionActivationListener—服务器正常关闭情况
下面两个是比较特殊的监听器:
有2个对象感知监听器,监听session域里的JavaBean对象的状态变化的
HttpSessionBindingListener:监听一个JavaBean对象和session的绑定状态(就是把JavaBean对象放在session域里面,接触绑定就是把JavaBean对象从session域里面移出了.)
HttpSessionActivationListener:监听session域里的JavaBean对象的钝化与活化状态
什么是钝化:一个JavaBean对象,如果这个类实现了序列号接口的话,就可以序列化存到磁盘文件里面,这个过程就被称之为钝化,
活化就是磁盘文件恢复成javabean对象(活化和钝化相反)
用的多的就是ServletContextListener,其他七个如果不做框架开发的话基本用不到,(四)监听器的基本开发步骤
- 创建Java类,实现监听器接口(根据想要监听的对象选择对应的监听器接口)
2. 重写接口的方法
3. 把监听器配置到web.xml里(五)域对象的监听器
创建监听器的步骤:
1. 创建Java类,实现监听器接口
2. 重写接口的方法
/
服务器软件会监听ServletContext的创建与销毁状态变化
/
public class MyServletContextListener implements ServletContextListener{
/
ServletContext对象创建时,这个方法会执行。
这个方法是用来监听ServletContext对象的创建的,一旦ServletContext对象被创建,服务器软件会调用这个方法
/
@Override
public void contextInitialized(ServletContextEvent sce) {
//System.out.println(“ServletContext对象已创建”);
//一般在这个方法里,做一些服务器一启动就需要完成的工作
/
比如:银行的利息计算,需要服务器一启动,就要开始执行这个任务 ,开启定时器
需要有一个定时器,第间隔24小时,就要计算一次利息 每天凌晨0:30:0开始计算利息
/
//创建第一次执行时间的日期对象
String firstTimeStr = “2017-10-18 15:26:00”;
SimpleDateFormat format = new SimpleDateFormat(“yyyy-MM-dd hh:mm:ss”);
Date firstTime = null;
try {
firstTime = format.parse(firstTimeStr);
} catch (ParseException e) {
e.printStackTrace();
}
//创建一个定时器对象,这个定时器对象没有要执行的任务
Timer timer = new Timer();
/
给定时器指派任务。参数:
1. task:要执行的任务
2. firstTime:任务第一次执行的时间
3. period:间隔时间 毫秒值
/
timer.schedule(new TimerTask() {
@Override
public void run() {
//把要做的事件写在run方法里。定时器时间一到,timer对象会自动调用这个对象的run方法
//System.out.println(“银行计算利息…..”);
}
}, firstTime, 31000);
}
@Override
public void contextDestroyed(ServletContextEvent sce) {
System.out.println(“ServletContext对象已销毁”);
}
}
3. 把监听器配置到web.xml里
com.itheima.listener.create.MyServletContextListener
(六)对象感知监听器
这两个监听器和上边的域对象的监听器不同:
不需要配置到web.xml中
这两个监听器是用在JavaBean上的1.HttpSessionBindingListener
监听的是JavaBean对象与session的绑定状态:
绑定状态:JavaBean对象被 放在了session域中,JavaBean对象绑定到session对象
解绑状态:把JavaBean对象从session域中移除了
步骤:
1. 创建JavaBean,实现HttpSessionBindingListener接口
2. 重写接口的方法
3. 把JavaBean对象放在session域中:会触发绑定事件
4. 把JavaBean对象从session域中移除:会触发解绑事件2.HttpSessionActivationListener
监听的是session中JavaBean对象的钝化与活化状态。
钝化状态:session中的JavaBean被序列化保存到了磁盘文件上
活化状态:服务器读取磁盘文件恢复成JavaBean对象保存到session域内存中
步骤:
1. 创建JavaBean,实现Serializable接口,以及HttpSessionActivationListener接口
2. 重写接口的方法
3. 把JavaBean对象放在session域中
4. 正常关闭服务器,session对象会被钝化,session中的对象也被钝化了:触发钝化事件
5. 重启服务器,服务器把磁盘文件恢复成session对象:触发活化状态(七)用定时器给过生日的人发邮件
技术分析:定时器 Timer类
java.util包下
创建定时器:new Timer()
定时方法:
schedule(TimerTask task, long delay, long period)
TimerTask task:要执行的任务
long delay:延迟的时间
long period:间隔的时间
延迟多长时间执行任务,然后间隔多长时间继续执行任务
schedule(TimerTask task, Date firstTime, long period)
TimerTask task:要执行的任务
Date firstTime:指定的时间
long period:间隔的时间
指定什么时间执行任务,然后间隔多长时间继续执行任务
技术分析:发邮件
邮件的概念:
邮件的客户端:网页形式 客户端形式(企业) 好处:可以在客户端里面多个邮箱 formail
邮件的服务器:起着接收和推送的功能
发邮件的服务器 SMTP服务器
接收邮件的服务器 pop/pop3/IMAP服务器
易邮
邮件的协议:
发邮件:SMTP协议
接收邮件:pop/pop3/IMAP协议
邮件发送的流程:见图
java代码的方式发邮件:
1 导包 mail.jar
2 写程序(工具类)
1 创建和邮件服务器的连接
2 创建邮件对象
3 发邮件
案例实现:作业
需求:当服务器一启动,就设置定时器(夜里12点)去数据库查询今日过生日的人,
给今日过生日的人发生日祝福邮件
步骤分析:
1 设置监听器(ServletContextListener) 监听服务器启动
2 设置定时器,让每晚12点去数据库查询 需要将今天的月和日传给数据库
3 获取到今天过生日的人后,遍历给每个人的邮箱发生日祝福ServletContext
ServletContext:直译Servlet上下文对象(是全局管理者)。
当tomcat服务器只要一启动,就会为部署在它上面的项目创建一个对应的ServletContext对象,它是用来管理整个项目所有servlet的.
ServletContext对象里封装了整个web应用的一些信息,可以获取web应用内任意一个资源的实际路径等等其它功能。
!!!整个web应用共用一个ServletContext对象,也是唯一的
当tomcat服务器关闭的时候,ServletContext对象会自动销毁
获取ServletContext对象:
在Servlet里任意位置执行下面的代码:
ServletContext getServletConfig().getServletContext() —不推荐,了解
ServletContext context = this.getServletContext(); — 推荐
ServletContext getServletContext()—推荐
ServletContext有什么用?
ServletContext既然代表着当前web站点,那么所有Servlet都共享着一个ServletContext对象,所以Servlet之间可以通过ServletContext实现通讯。
ServletConfig获取的是配置的是单个Servlet的参数信息,ServletContext可以获取的是配置整个web站点的参数信息
利用ServletContext读取web站点的资源文件
实现Servlet的转发【用ServletContext转发不多,主要用request转发】
ServletContext的作用是:
1 .获取配置文件中(web.xml)全局的初始化参数
2 .获取一个文件的MIME类型( 例如:一个html文件 mime类型:text/html text/css img/jpeg)
3 .管理文件 (例如:获取文件路径,根据文件获取流)
4 .资源共享(在本项目下的所有servlet都可以共享它)—最重要
1.获取全局的初始化参数(了解)
String paramValue = context.getInitParameter(String paramName);
2.获取web应用内资源的实际路径(涉及到资源加载文件下载的时候会用到它)
String realPath = context.getRealPath(服务端路径);
3.是一个域对象
ServletContext域对象的生命周期:
何时创建:服务器启动时
何时销毁:服务器关闭时
作用范围:整个web应用内
域对象必定有的三个方法:
setAttribute(String name, Object value);
getAttribute(String name);
removeAttribute(String name);
ServletContext的常用方法
获取全局的初始化参数
String getInitParameter(String name):获取指定的初始化参数
获取一个文件的MIME类型
getMimeType(String filename):获取文件的mime类型
mime类型:就是告诉浏览器你的文件是图像还是视频还是文本
具体解释: Ctrl 点击 查看百度百科
管理文件
getRealPath(String path):获取当前项目在tomcat服务器中的盘符根路径
例如:E:\apache-tomcat-7.0.52\apache-tomcat-7.0.52\webapps\day31
InputStream is=new FileInputStream(new File(path)) 之前的获取方式
getResourceAsStream(String path):根据文件获取流
资源共享的方法(可以把他当成一个map集合) (掌握)
setAttribute(String key,Object value):储存值
Object getAttribute(String key):获取值,若没有则返回一个null
removeAttribute(String key):移除值
ServletContext资源共享的方法:可以被多个servlet共享
原因:是因为在多个servlet中获取到的ServletContext对象是同一个.
Servlet
什么是Serlvet?
Servlet其实就是一个遵循Servlet开发的java类。Serlvet是由服务器调用的,运行在服务器端。
为什么要用到Serlvet?
我们编写java程序想要在网上实现 聊天、发帖、这样一些的交互功能,普通的java技术是非常难完成的。sun公司就提供了Serlvet这种技术供我们使用。
Servlet:Server Applet在服务端运行的java程序。是sun公司提供的一套规范(Servlet接口)。可以在客户端以url的形式,通过http协议来远程调用Servlet的API,Servlet可以动态的向客户端响应一些内容,
为什么是动态响应,因为servlet可以向客户端发一些东西到页面上去.它可以向客户端返回不同的内容.
servlet既可以和前端打交道,也可以调用其他的java代码,或者操作数据库与数据库交互.
作用:
1. 接收客户端的参数(比如接收浏览器中用户输入后提交的内容)
2. 完成业务请求(比如修改用户信息)
3. 向客户端动态响应一些内容(业务请求后要向客户端来些反馈)
Servlet三步骤:
1. 创建java类,实现Servlet接口
2. 重写接口的方法(共有5个方法,要学习的3个方法,重点关注service方法)
3. 在web.xml里配置Servlet(web.xml是web应用的清单)
servletDemo
com.itheima.test.ServletDemo
servletDemo
/demo
Servlet规范有三项技术:Servlet,Filter(过滤器),Listener(监听器,类似于js里面的事件,监听某些动作的)
1.Servlet是单例的
为什么Servlet是单例的
浏览器多次对Servlet的请求,一般情况下,服务器只创建一个Servlet对象,也就是说,Servlet对象一旦创建了,就会驻留在内存中,为后续的请求做服务,直到服务器关闭。
每次访问请求对象和响应对象都是新的
对于每次访问请求,Servlet引擎都会创建一个新的HttpServletRequest请求对象和一个新的HttpServletResponse响应对象,然后将这两个对象作为参数传递给它调用的Servlet的service()方法,service方法再根据请求方式分别调用doXXX方法。
线程安全问题
当多个用户访问Servlet的时候,服务器会为每个用户创建一个线程。当多个用户并发访问Servlet共享资源的时候就会出现线程安全问题。
原则:
如果一个变量需要多个用户共享,则应当在访问该变量的时候,加同步机制synchronized (对象){}
如果一个变量不需要共享,则直接在 doGet() 或者 doPost()定义.这样不会存在线程安全问题.
2.Servlet与java Web开发
![Web[笔记] - 图35](/uploads/projects/zjj1994@javabasic/c620b9b0dd1f0b70ceb016b624f4c71f.jpeg)
(二)servlet的API
1.Servlet的生命周期(重点:面试)
- 加载Servlet。当Tomcat第一次访问Servlet的时候,Tomcat会负责创建Servlet的实例
2. 初始化。当Servlet被实例化后,Tomcat会调用init()方法初始化这个对象
3. 处理服务。当浏览器访问Servlet的时候,Servlet 会调用service()方法处理请求
4. 销毁。当Tomcat关闭时或者检测到Servlet要从Tomcat删除的时候会自动调用destroy()方法,让该实例释放掉所占的资源。一个Servlet如果长时间不被使用的话,也会被Tomcat自动销毁
5. 卸载。当Servlet调用完destroy()方法后,等待垃圾回收。如果有需要再次使用这个Servlet,会重新调用init()方法进行初始化操作。
6. 简单总结:只要访问Servlet,service()就会被调用。init()只有第一次访问Servlet的时候才会被调用。 destroy()只有在Tomcat关闭的时候才会被调用。
1. 何时创建
默认第一次请求Servlet的时候,服务器软件会创建Servlet对象
创建Servlet对象时,服务器软件会执行init方法
一个Servlet类,只有一个对象存在
(怎么知道我们要创建servlet,因为xml配置了类的全路径,由反射创建对象出来)
2. 何时销毁
服务器软件关闭时 或者 把web应用从服务器里移除的时候,会销毁Servlet对象
销毁Servlet对象时,服务器软件会执行destroy方法
3. 创建之后销毁之前,每次访问必定会执行的方法
每次为访问Servlet都必定会执行的方法是service方法
假如:一个Servlet,10个人分别访问了一次,问:有几个 Servlet对象?init方法执行了几次?destory方法执行了几次?service方法执行了几次?
(三) Servlet的API
以下三个都是接口,已经叫好的规范不能改.
init: servlet被创建的时候执行的
destory: servlet被销毁之前的时候执行的
servlet: servlet每次请求时候执行的1.init(ServletConfig config) 中文初始化的意思
作用:初始化方法,如果某些工作想要servlet一创建就被执行的,就把代码写在init方法里面.
参数:
ServletConfig:当前Servlet的配置信息对象,由服务器软件创建并传递进来
作用(了解,没有特别大的作用):
1. 获取Servlet的名称 config.getServletName()
2. 获取Servlet的初始化参数 config.getInitParameter(“name”)
3. 获取ServletContext对象 config.getServletContext();2.service(ServletRequest request, ServletResponse response) 中文服务的意思
作用:用来做业务处理方法,服务器自动调用方法,业务请求处理都要写在service方法里面
参数:
ServletRequest:对应http请求,可以获取http请求的所有数据,服务器软件会把http请求的所有数据封装到request对象里面,传递到servlet里面,我们拿到request对象可以获得http请求的所有数据.
获取客户端提交的参数:String value = request.getParameter(“XXX”);
!!! 注意XXX是前台页面请求form表单的name值得数据,无论get,post方法都可以获取到.
——————-
ServletResponse:对应http响应,可以向客户端设置一些数据
向客户端页面输出内容:response.getWriter().write(“”);
服务器软件创建response对象之后,传递到servlet里,我们拿到response对象之后,可以往里面设置一些数据,这些数据会被转换成http响应,最终发送回客户端.
!!!注意每次调用service方法时,传递进来的request response对象都是新的3.destroy()了解 销毁方法
作用:销毁方法
当Servlet对象被销毁的时候(被销毁之前,非静态方法如果被销毁就不会被调用,所以是被销毁之前),服务器软件会自动调用执行destroy方法
(四)servlet的配置
servletDemo1
com.itheima.servlet.ServletDemo1
aa
AA
bb
BB
3
servletDemo1
/aa/bb/
/demo1
<!—/aa/bb/ .jsp —>
(五)HttpServlet(重点:应用,现实开发大多都用这个)
Servlet规范提供了一种更简单的创建Servlet的方式:继承HttpServlet
在包上右键—new—Servlet—设置类的名称—设置访问路径—完成
/*
1. 表面上看当前类没有实现Servlet接口
当前类的父类的父类实现的Servlet接口,所以当前类也是一个Servlet
2. 表面上看当前类没有service方法,是doGet方法执行了
当前类的父类有service(ServletRequest, ServletResponse)方法,这个方法会执行。这个方法里做的事情:
1. 强转,把ServletRequest和ServletResponse强转成HttpServletRequest和HttpServletResponse
2. 调用父类自己的service(HttpServletRequest,HttpServletResponse)
2.1 获取请求方式
2.2 如果请求方式是get,调用doGet方法;如果请求方式是post,调用doPost方法
我们自己的类重写的父类的doGet和doPost方法,最终Servlet被访问时这两个方法会被调用
*/(六)web应用里路径的写法(重点)
注意:!!!!!!不要写相对路径
如果路径是给客户端浏览器使用的,就是客户端路径;如果路径是给服务器端使用的,是服务端路径。
客户端的绝对路径:
/web应用的名称/资源的路径
比如:![Web[笔记] - 图36](/uploads/projects/zjj1994@javabasic/182a074cebd354e098486f887c001b30.jpeg)
服务端的绝对路径:
不写web应用名称,直接写资源路径即可:/资源路径
比如:
/form.html
/admin/admin.html(七)页面跳转Servlet,不通过form和ajax方式
function del(pid)
{
var flag=confirm(“确认要删除该条商品吗?”);
if(flag)
{
// 带着pid给servlet
// 超链接 ?
// form表单
// js:location.href
// 设置servlet执行路径(必掌握)
location.href=”${pageContext.request.contextPath}/del?pid=”+pid;
}
}
web.xml文件详解
前言:一般的web工程中都会用到web.xml,web.xml主要用来配置,可以方便的开发web工程。web.xml主要用来配置Filter、Listener、Servlet等。但是要说明的是web.xml并不是必须的,一个web工程可以没有web.xml文件。
1、WEB工程加载web.xml过程
经过个人测试,WEB工程加载顺序与元素节点在文件中的配置顺序无关。即不会因为 filter 写在 listener 的前面而会先加载 filter。WEB容器的加载顺序是:ServletContext -> context-param -> listener -> filter -> servlet。并且这些元素可以配置在文件中的任意位置。
加载过程顺序如下:
1. 启动一个WEB项目的时候,WEB容器会去读取它的配置文件web.xml,读取和 两个结点。
2. 紧急着,容创建一个ServletContext(servlet上下文),这个web项目的所有部分都将共享这个上下文。
3. 容器将转换为键值对,并交给servletContext。
4. 容器创建中的类实例,创建监听器。
2、web.xml文件元素详解
1、schema
web.xml的模式文件是由Sun公司定义的,每个web.xml文件的根元素中,都必须标明这个 web.xml使用的是哪个模式文件。其它的元素都放在 之中。
<?xml version=”1.0” encoding=”UTF-8”?>xmlns=”http://java.sun.com/xml/ns/j2ee“
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“
xsi:schemaLocation=”http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd”></web-app>
2、Web应用图标
指出IDE和GUI工具用来表示Web应用的大图标和小图标。
/images/app_small.gif
/images/app_large.gif
3、Web应用名称
提供GUI工具可能会用来标记这个特定的Web应用的一个名称
就相当于给你的web.xml起个名字一样。没什么实质的用处,修改它给你的工程不会带来影响Tomcat Example
4、Web应用描述
给出于此相关的说明性文本Tomcat Example servlets and JSP pages.
5、上下文参数
声明应用范围内的初始化参数。它用于向 ServletContext提供键值对,即应用程序上下文信息。我们的listener, filter等在初始化时会用到这些上下文中的信息。在servlet里面可以通过getServletContext().getInitParameter(“context/param”)得到。
ContextParameter
test
It is a test parameter.
6、过滤器
将一个名字与一个实现javaxs.servlet.Filter接口的类相关联。
setCharacterEncoding
com.myTest.setCharacterEncodingFilter
encoding
UTF-8
setCharacterEncoding
/
7、监听器
com.listener.SessionListener
8、
用来声明一个servlet的数据,主要有以下子元素:
·指定servlet的名称
·指定servlet的类名称
·指定web站台中的某个JSP网页的完整路径
·用来定义参数,可有多个init-param。在servlet类中通过getInitParamenter(String name)方法访问初始化参数
·指定当Web应用启动时,装载Servlet的次序。当值为正数或零时:Servlet容器先加载数值小的servlet,再依次加载其他数值大的servlet。当值为负或未定义:Servlet容器将在Web客户首次访问这个servlet时加载它。
·用来定义servlet所对应的URL,包含两个子元素
·指定servlet的名称
·指定servlet所对应的URL
snoop
SnoopServlet
snoop
/snoop
snoop
SnoopServlet
foo
bar
Security role for anonymous access
tomcat
snoop
/snoop
9、会话超时配置
单位为分钟。
120
10、
htm
text/html
11、欢迎文件页
index.jsp
index.html
index.htm
12、错误页面
404
/NotFound.jsp
java.lang.NullException
/error.jsp
13、设置jsp
包括 .jsp和 两个子元素。其中 元素在JSP 1.2 时就已经存在;而 是JSP 2.0 新增的元素。
元素主要有八个子元素,它们分别为:
·:设定的说明
·:设定名称
·:设定值所影响的范围,如: /CH2 或 /
·:若为 true,表示不支持 EL 语法
·:若为 true,表示不支持 <% scripting %>语法
·:设定 JSP 网页的编码
·:设置 JSP 网页的抬头,扩展名为 .jspf
·:设置 JSP 网页的结尾,扩展名为 .jspf
Taglib
/WEB-INF/tlds/MyTaglib.tld
Special property group for JSP Configuration JSP example.
JSPConfiguration
/jsp/
true
GB2312
true
/include/prelude.jspf
/include/coda.jspf
对于Web 应用程式来说,Scriptlet 是个不乐意被见到的东西,因为它会使得HTML 与Java 程式码交相混杂,对于程式的维护来说相当的麻烦,必要的时候,可以在web.xml 中加上标签,设定所有的JSP 网页都不可以使用Scriptlet。 ,这个时候,如果我访问的url为http://localhost/test ,这个时候容器就会先 进行精确路径匹配,发现/test正好被servletA精确匹配,那么就去调用servletA,也不会去理会其他的servlet了。
3、Mapping规则
当一个请求发送到servlet容器的时候,容器先会将请求的url减去当前应用上下文的路径作为servlet的映射url,比如我访问的是http://localhost/test/aaa.html,我的应用上下文是test,容器会将http://localhost/test去掉,剩下的/aaa.html部分拿来做servlet的映射匹配。这个映射匹配过程是有顺序的,而且当有一个servlet匹配成功以后,就不会去理会剩下的servlet了。
其匹配规则和顺序如下:
1. 精确路径匹配。例子:比如servletA 的url-pattern为 /test,servletB的url-pattern为 /
2. 最长路径匹配。例子:servletA的url-pattern为/test/,而servletB的url-pattern为/test/a/,此时访问http://localhost/test/a时,容器会选择路径最长的servlet来匹配,也就是这里的servletB。
3. 扩展匹配,如果url最后一段包含扩展,容器将会根据扩展选择合适的servlet。例子:servletA的url-pattern:.action
以”/’开头和以”/”结尾的是用来做路径映射的。以前缀”.”开头的是用来做扩展映射的。所以,为什么定义”/.action”这样一个看起来很正常的匹配会错?因为这个匹配即属于路径映射,也属于扩展映射,导致容器无法判断。

若有收获,就点个赞吧
0 人点赞
