Set集合
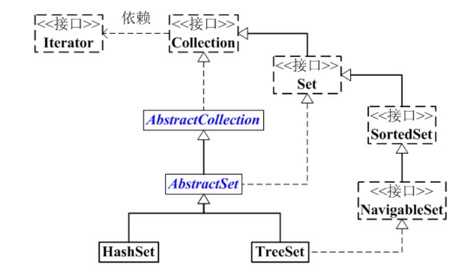
(01) Set 是继承于Collection的接口。它是一个不允许有重复元素的集合。(02) AbstractSet 是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了Set中的绝大部分函数,为Set的实现类提供了便利。(03) HastSet 和 TreeSet 是Set的两个实现类。 HashSet依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的。 TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是有序的。
Set集合是基于Map来实现的,不允许空值,不允许重复,没有索引(无序),最多只能存一个null
HashSet的值其实就是HashMap的key. value就是写死的PRESENT
set集合常见实现类
1:HashSet;底层是一个哈希表结构;
2:LinkedHashSet;链表加哈希表的数据结构;实质上,LinkedHashSet是HashSet的子类,除了保证了元素迭代的顺序与保存的顺序一致外,其他方法都与HashSet一致;
哈希表结构
哈希表是以关键码值映射对应的元素位置的方式来保存数据的一种数据结构;

1.hashCode与equals
hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode: 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
通过我们可以看出:hashCode() 的作用就是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
hashCode()与equals()的相关规定
如果两个对象相等,则hashcode一定也是相同的
两个对象相等,对两个对象分别调用equals方法都返回true
两个对象有相同的hashcode值,它们也不一定是相等的
因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
2.获取线程安全的Set集合
| private final Set Collections.newSetFromMap(new ConcurrentHashMap<>(16)); |
|---|
TreeSet
TreeSet是一个有序的Set集合
API构造,数据结构,遍历方式介绍
参考:
https://www.yuque.com/docs/share/7fb4fe83-fda3-41fc-83b8-1068ece69ba1?#

若有收获,就点个赞吧
0 人点赞
