迭代法:之前提过,我们不能含糊地记说:“中序遍历是先访问左子树,再访问根节点,再访问右子树。”
这么描述是不准确的,容易产生误导。
因为无论是前、中、后序遍历,都是先访问根节点,再访问它的左子树,再访问它的右子树。
区别在哪里?比如中序遍历,它是将 do something with root(处理当前节点)放在了访问完它的左子树之后。比方说,打印节点值,就会产生「左 根 右」的打印顺序。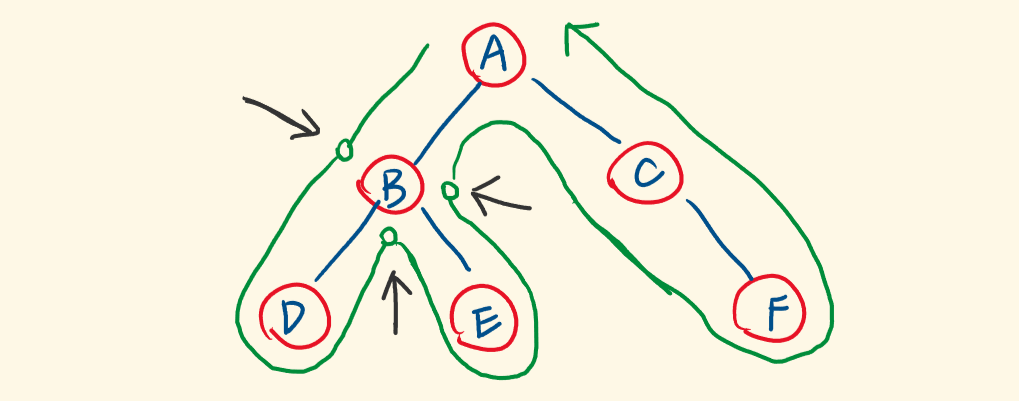
前、中、后序遍历都是基于DFS,节点的访问顺序如上图所示,每个节点有三个不同的驻留阶段,即每个节点会被经过三次:
- 在递归它的左子树之前。
- 在递归完它的左子树之后,在递归它的右子树之前。
- 在递归完它的右子树之后。
我们将 do something with root 放在这三个时间点之一,就分别对应了:前、中、后序遍历。
所以,它们的唯一区别是:在什么时间点去处理节点,去拿他做文章。
下面的伪代码是『中序遍历』的模板。
复杂度分析
- 时间复杂度:O(n),其中 n 为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
- 空间复杂度:O(n)。空间复杂度取决于递归的栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。 ```go //1,递归 func inorderTraversal(root *TreeNode) []int { res := []int{} //暂存一个数组 来存二叉树的值 inerder(root, &res) //递归函数,父节点,遍历值 return res //返回结果数组 }
func inerder(root TreeNode, res []int) { if root == nil { //终止条件,根节点为空 return }
inerder(root.Left,res) //中序遍历,前中后子树,核心三句*res = append(*res,root.Val)inerder(root.Right,res) //用递归函数的方式,取右节点值
}
<a name="jEIip"></a>
#### 中序遍历的迭代实现
搞清楚概念后,怎么用栈去模拟递归遍历,并且是中序遍历呢?<br />dfs 一棵树如下图,先递归节点A,再递归左子节点B,再递归左子节点D,一个个压入递归栈。<br />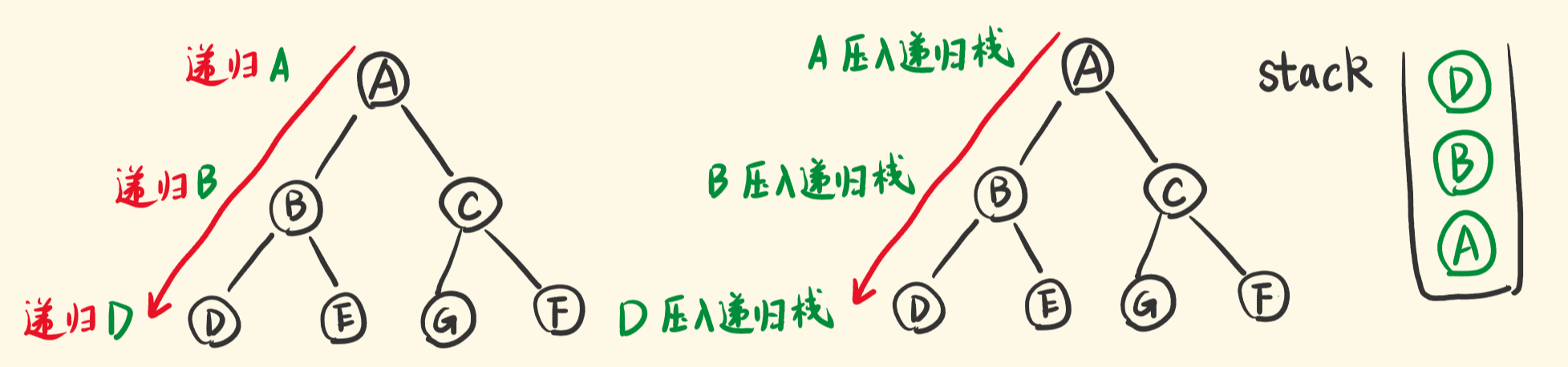<br />也就是说,先不断地将左节点压入栈<br />DFS的访问顺序是:根节点、左子树、右子树,现在要访问(牵扯出)栈中的节点的右子树了。<br />并且是先访问『位于树的底部的』即『位于栈的顶部的』节点的右子树。<br />于是,让栈顶节点出栈,出栈的同时,把它的右子节点压入栈,相当于递归右子节点。<br />因为是中序遍历,在栈顶节点的右子节点压栈之前,要处理出栈节点的节点值,将它输出。<br />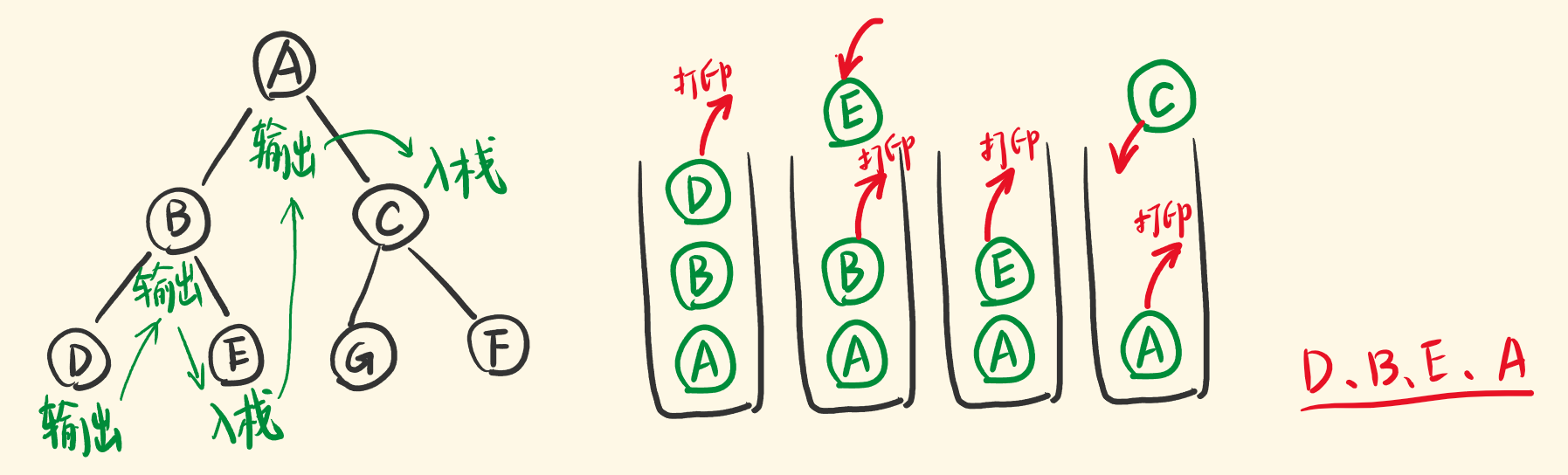<br />新入栈的右子节点(右子树),就是对它递归。和节点A、B、D的压栈一样,它们都是子树。<br />递归不同的子树要做一样的事情,一样要先将它的左子节点不断压栈,然后再出栈,带出右子节点入栈。<br />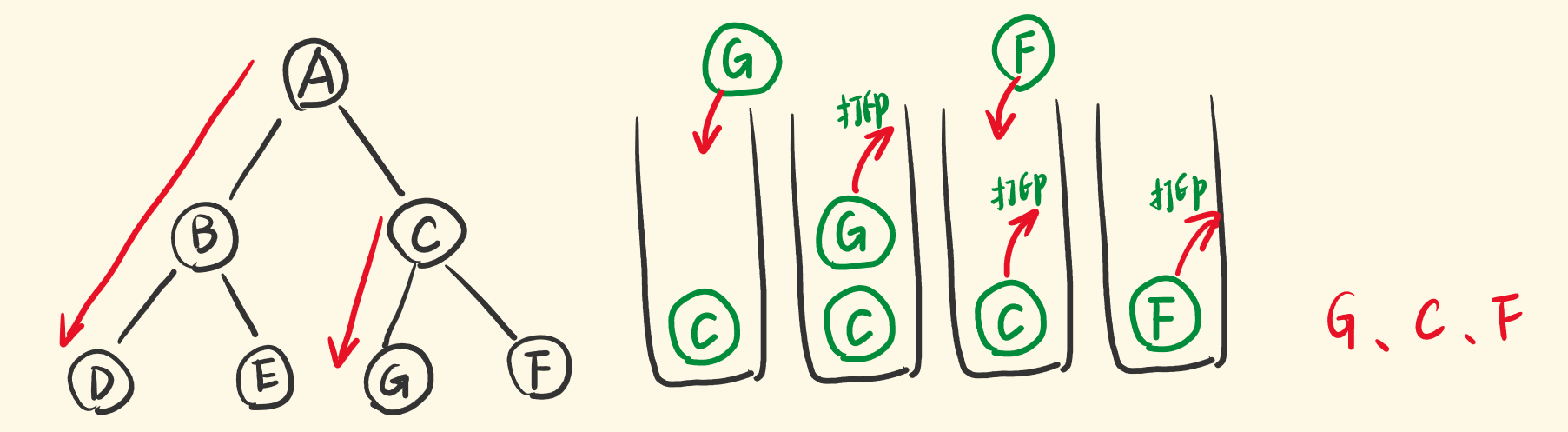<br />即栈顶出栈的过程,也要包含下面代码<br />**复杂度分析**
- 时间复杂度:O(n),其中 n为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
- 空间复杂度:O(n)。空间复杂度取决于栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n)的级别。
```go
//2.迭代
func inorderTraversal(root *TreeNode) []int{
//1,二叉树初始赋值,定义栈是二叉树结构,res是数组结构
stack := []*TreeNode{}
res := []int{}
//2,一直找到最底层 的左节点
for root != nil || len(stack) >0 {
for root != nil { //结束遍历条件,父节点为空
stack = append(stack,root) //存进所以父节点,层层放置
root = root.Left //走最左路径
}
//3,弹出栈,模拟递归过程
root = stack[len(stack)-1] //向上回溯父节点,核心四句
stack = stack[:len(stack)-1] //栈的深度减一
res = append(res,root.Val) //左中右,存储进res数组里,遍历的节点值
root = root.Right //拿到右节点
}
return res
}
明确这三种遍历都是基于DFS递归,清楚概念,再明白递归其实是压栈出栈的操作,比照着,用一个栈,去模拟递归栈,用迭代,去模拟递归的逻辑,就不难写出迭代法的代码。
方法三:颜色标记法
时间复杂度为o(2n),此外空间消耗也大一些o(n)
其实这边的灰白标注,类似于其他地方使用的 visited 记录的概念,作用就是不要重复处理同一个节点的左右子树。 可以将遍历过左右节点的元素放入 visited 中,即里面的节点都是灰色节点,不在里面的则是白色节点。每次 pop 出一个节点,通过判断其是否包含在 visited 中确定是遍历其左右节点,还是直接打印。用标记的方法来解决,该结点标记为灰色意味着已经访问该结点的左右子结点,这样和递归的思路就有些类似了。本质:模拟递归,修改最后入栈顺序,就可以通用了。
这个题解的宗旨就是使用一个颜色或者任何东西,记录节点的访问次数。在中序中,节点第二次访问会被输出。因此使用颜色,或者hash表来记录节点的访问次数,次数使用hash表来记录
栈是一种 先进后出的结构,出栈顺序为左,中,右
那么入栈顺序必须调整为倒序,也就是右,中,左
//3,颜色标记法2,通法=变化顺序即可,反序变颜色
func inorderTraversal(root *TreeNode) []int {
type node struct { //1,定义颜色,0表示白色,为遍历,1表示灰色,遍历过
Color int
Node *TreeNode
}
stack := make([]node, 0) //2,初始化栈,手动维护
rootNode := node{0, root} //初始化根节点
stack = append(stack, rootNode) //3,把根节点依次放入栈中,第一次入栈
res := make([]int,0)
for len(stack) >0 { //4,入栈的模拟,父节点依次入栈
n := stack[len(stack)-1]
stack = stack[:len(stack)-1]
if n.Node == nil { //5,入栈模拟,结束条件,没有父节点时
continue
}
if n.Color == 0 { //6.入栈模拟,核心,对白色的,未标记的进行遍历,入栈右中左,反序出栈
stack = append(stack, node{0, n.Node.Right})
stack = append(stack, node{1, n.Node}) //访问后,白色变灰色
stack = append(stack, node{0, n.Node.Left})
} else {
res = append(res , n.Node.Val)
//7,颜色为灰色,因为中序中根节点会被访问2次,输出第二次访问结果
}
}
return res
}
莫里斯遍历
用递归和迭代的方式都使用了辅助的空间,而莫里斯遍历的优点是没有使用任何辅助空间。
缺点是改变了整个树的结构,强行把一棵二叉树改成一段链表结构。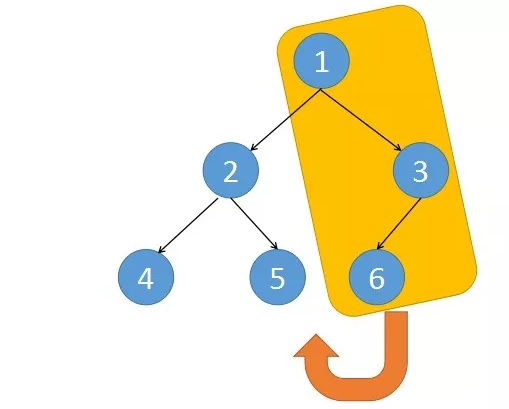
我们将黄色区域部分挂到节点5的右子树上,接着再把2和5这两个节点挂到4节点的右边。
这样整棵树基本上就变改成了一个链表了,之后再不断往右遍历。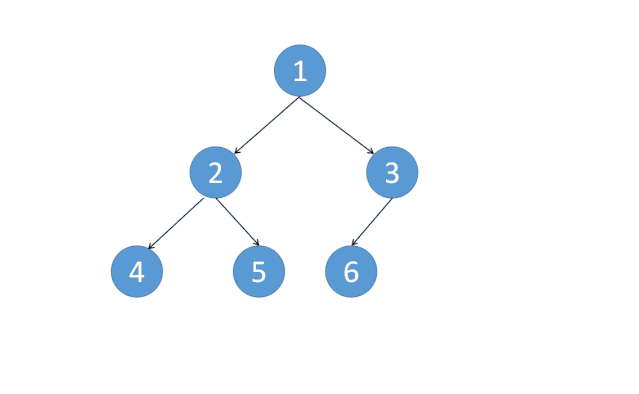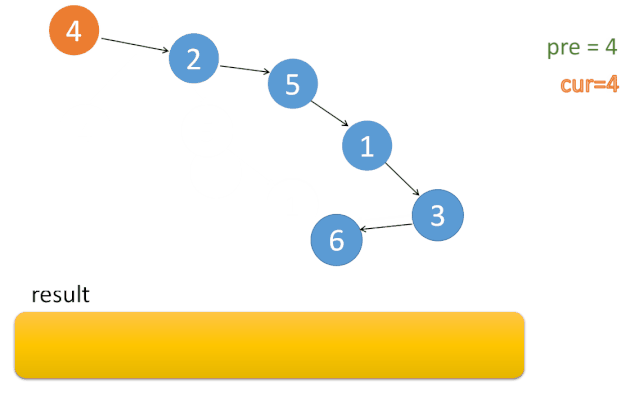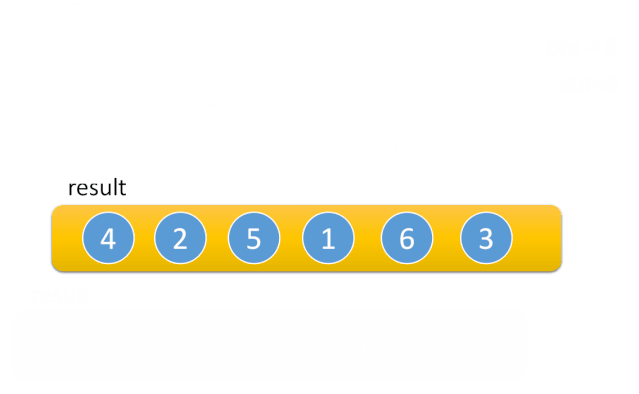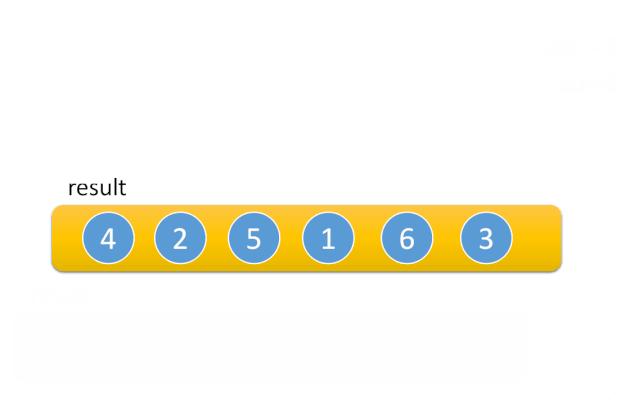
时间复杂度:找到每个前驱节点的复杂度是 O(n),因为 n个节点的二叉树有 n-1 条边,每条边只可能使用 2 次(一次定位到节点,一次找到前驱节点),故时间复杂度为 O(n)
空间复杂度:O(1)
func inorderTraversal(root *TreeNode) (res []int) {
for root != nil {
if root.Left != nil {
// predecessor 节点表示当前 root 节点向左走一步,然后一直向右走至无法走为止的节点
predecessor := root.Left
for predecessor.Right != nil && predecessor.Right != root {
// 有右子树且没有设置过指向 root,则继续向右走
predecessor = predecessor.Right
}
if predecessor.Right == nil {
// 将 predecessor 的右指针指向 root,这样后面遍历完左子树 root.Left 后,就能通过这个指向回到 root
predecessor.Right = root
// 遍历左子树
root = root.Left
} else { // predecessor 的右指针已经指向了 root,则表示左子树 root.Left 已经访问完了
res = append(res, root.Val)
// 恢复原样
predecessor.Right = nil
// 遍历右子树
root = root.Right
}
} else { // 没有左子树
res = append(res, root.Val)
// 若有右子树,则遍历右子树
// 若没有右子树,则整颗左子树已遍历完,root 会通过之前设置的指向回到这颗子树的父节点
root = root.Right
}
}
return
}

若有收获,就点个赞吧
0 人点赞
