大纲如下:
进行优化器的具体概念之前,我们得看看优化器要干一个什么样的事情, 我们知道了机器学习的五个步骤: 数据 -> 模型 -> 损失 -> 优化器 -> 迭代训练。 我们通过前向传播的过程,得到了模型输出与真实标签的差异,我们称之为损失, 有了损失,我们会进入反向传播过程得到参数的梯度,那么接下来就是优化器干活了,优化器要根据我们的这个梯度去更新参数,使得损失不断的减低。 那么优化器是怎么做到的呢? 下面我们从三部分进行展开,首先是优化器的概念,然后是优化器的属性和方法,最后是常用的优化器。
2.1 什么是优化器
Pytorch 的优化器: 管理并更新模型中可学习参数的值, 使得模型输出更接近真实标签。
我们在更新参数的时候一般使用梯度下降的方式去更新, 那么什么是梯度下降呢? 说这个问题之前得先区分几个概念:
- 导数: 函数在指定坐标轴上的变化率
- 方向导数: 指定方向上的变化率
- 梯度: 一个向量, 方向为方向导数取得最大值的方向
我们知道梯度是一个向量,它的方向是导数取得最大值的方向,也就是增长最快的方向,而梯度下降就是沿着梯度的负方向去变化,这样函数的下降也是最快的。所以我们往往采用梯度下降的方式去更新权值,使得函数的下降尽量的快。
2.2 Optimizer 的基本属性和方法
下面我们学习 Pytorch 里面优化器的基本属性:
- defaults: 优化器超参数,如momentum 的值,衰减系数等
- state: 参数的缓存, 如 momentum 的缓存(使用前几次梯度进行平均)
- param_groups: 管理的参数组, 这是个列表,每一个元素是一个字典,在字典中有 key,key 里面的值才是我们真正的参数(这个很重要, 进行参数管理)
- _step_count: 记录更新次数, 学习率调整中使用, 比如迭代 100 次之后更新学习率的时候,就得记录这里的 100.
优化器里面的基本方法:
了解了优化器的基本属性和方法之后,我们去代码中看看优化器的运行机制了, 依然是代码调试的方法, 还记得我们的人民币二分类任务吗? 我们进行优化器部分的调试:我们在优化器的定义那打上断点,然后 debug
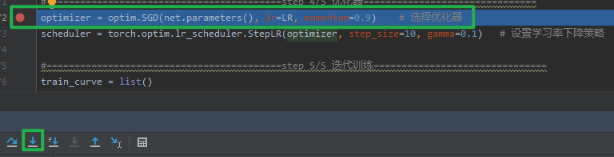
点击步入,进入 sgd.py 的 SGD 类: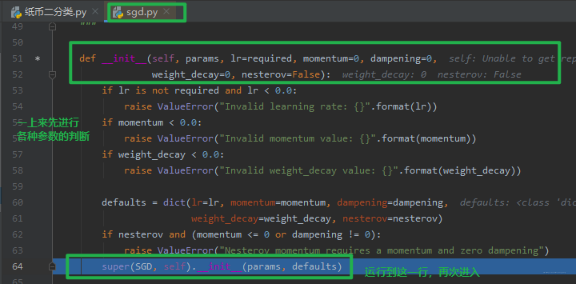
SGD 类是继承于 optimizer 的,所以我们将代码运行到父类初始化的这一行,点击步入,看看是如何初始化的: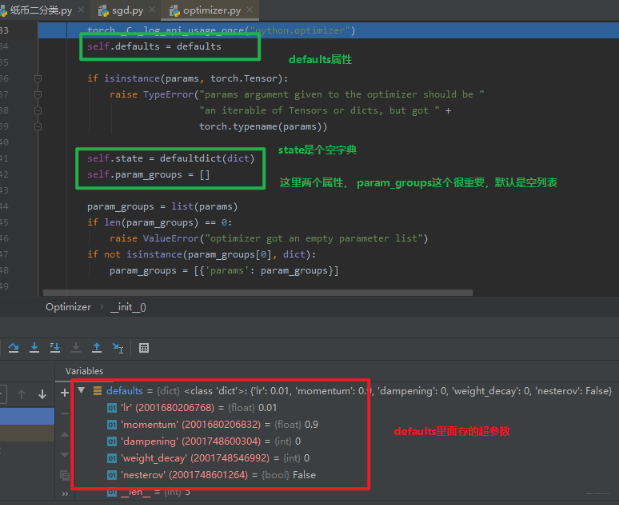
这里就是 optimizer 的init初始化部分了,可以看到上面介绍的那几个属性和它们的初始化方法,当然这里有个最重要的就是参数组的添加,我们看看是怎么添加的: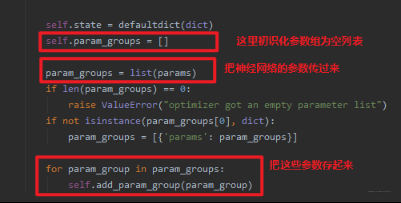
这里重点说一下这个,我们还记得初始化 SGD 的时候传入了一个形参:optim.SGD(net.parameters(), lr=LR, momentum=0.9),这里的net.parameters() 就是神经网络的每层的参数, SGD 在初始化的时候, 会把这些参数以参数组的方式再存起来, 上图中的 params 就是神经网络每一层的参数。
下面我们跳回去, 看看执行完这个初始化参数变成了什么样子:
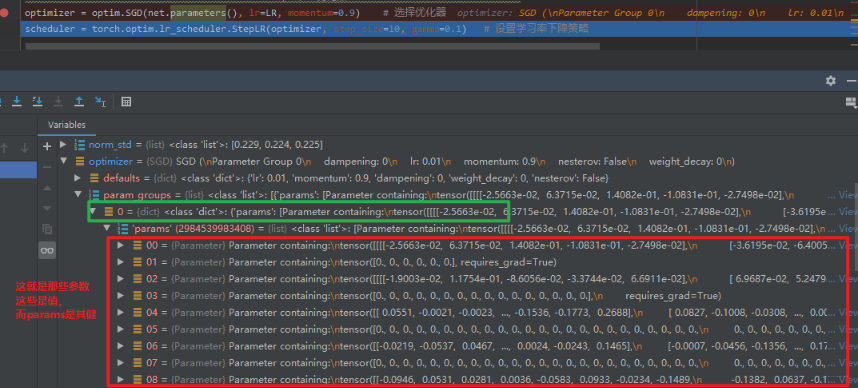
这就是优化器的初始化工作了, 初始化完了之后, 我们就可以进行梯度清空,然后更新梯度即可:
这就是优化器的使用了。
下面我们学习优化器具体的方法:
- step(): 一次梯度下降更新参数
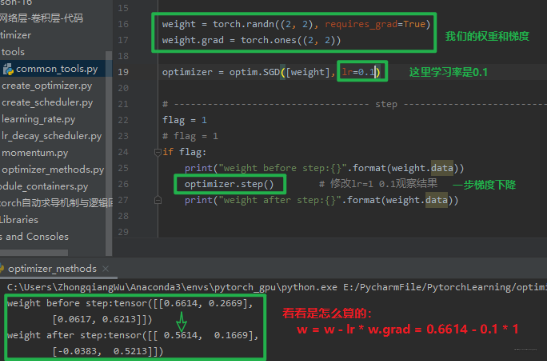
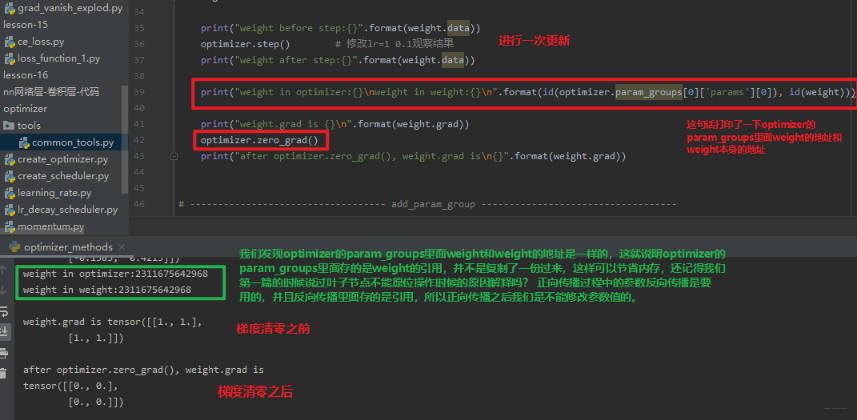
- zero_grad():将梯度清零
- add_param_group(): 添加参数组
这个是在模型的迁移学习中非常实用的一个方法,我们看看怎么用: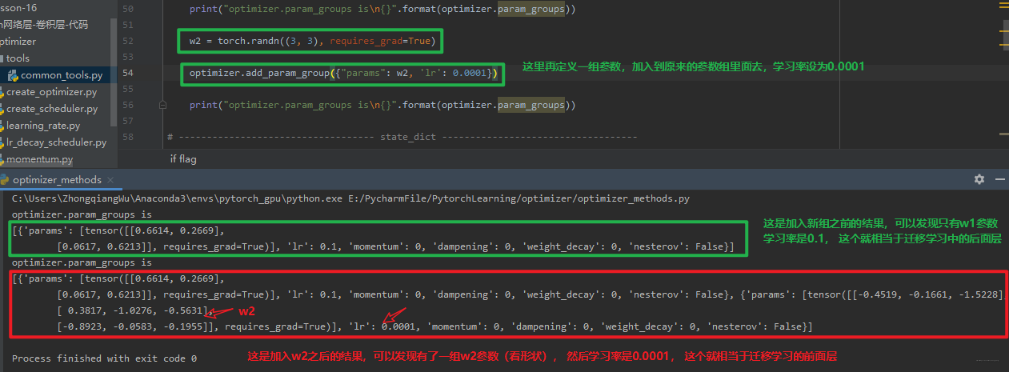
- state_dict() 和 load_state_dict()
这两个方法用于保存和加载优化器的一个状态信息,通常用在断点的续训练, 比如我们训练一个模型,训练了 10 次停电了, 那么再来电的时候我们就得需要从头开始训练,但是如果有了这两个方法,我们就可以再训练的时候接着上次的次数继续, 所以这两个也非常实用。
首先是 state_dict()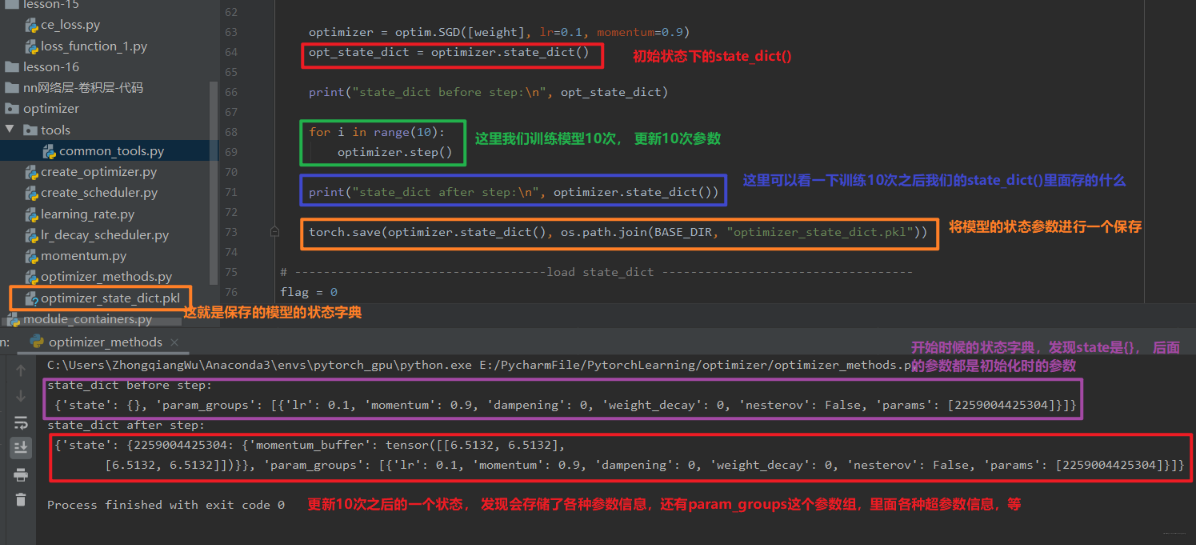
我们可以看到,state_dict() 方法里面保存了我们优化器的各种状态信息,我们通过 torch.save 就可以保存这些状态到文件 (.pkl), 这样假设此时停电了。 好,我们就可以通过 load_state_dict() 来导入这个状态信息,让优化器在这个基础上进行训练,看看是怎么做的?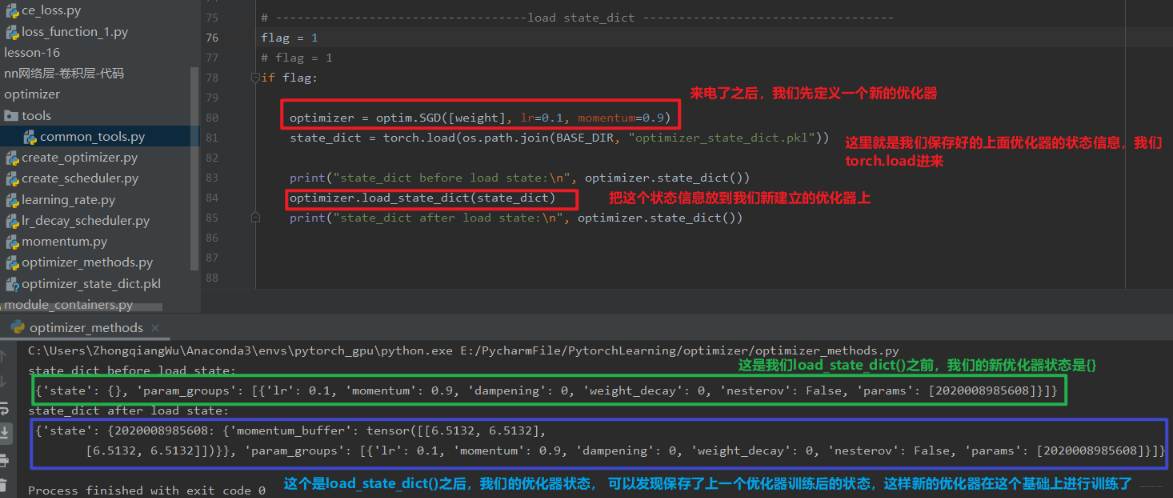
好了,这就是优化器的初始化和优化器的 5 个方法的使用了。了解了这些知识之后,我们就知道了优化器的运行机制,管理和更新模型的可学习参数(管理是通过各种属性,尤其是 param_groups 这个重要的属性,而更新是通过各种方法,主要是 step() 方法进行更新)。 那么究竟有哪些常用的优化器呢? 它们又用于什么场景呢? 下面我们就来看看:
2.3 常用的优化器
这次我们会学习 Pytorch 中的 10 种优化器,但是在介绍这些优化器之前,得先学习两个非常重要的概念, 那就是学习率和动量。 我们先从学习率开始:
2.3.1 学习率
在梯度下降过程中,学习率起到了控制参数更新的一个步伐的作用, 参数更新公式我们都知道: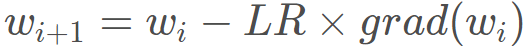
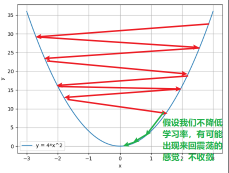
如果没有这个学习率 LR 的话,往往有可能由于梯度过大而错过我们的最优值,就是下面这种感觉: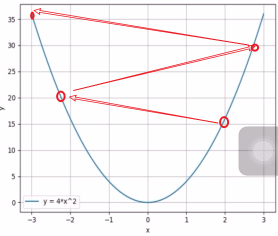
随着迭代次数的增加,反而越增越大, 就是因为这个步子太大了,跳过了我们的最优值。所以这时候我们想让他这个跨度小一些,就得需要一个参数来控制我们的这个跨度,这个就是学习率。 这样说起来,有点抽象,我们还是从代码中看看吧: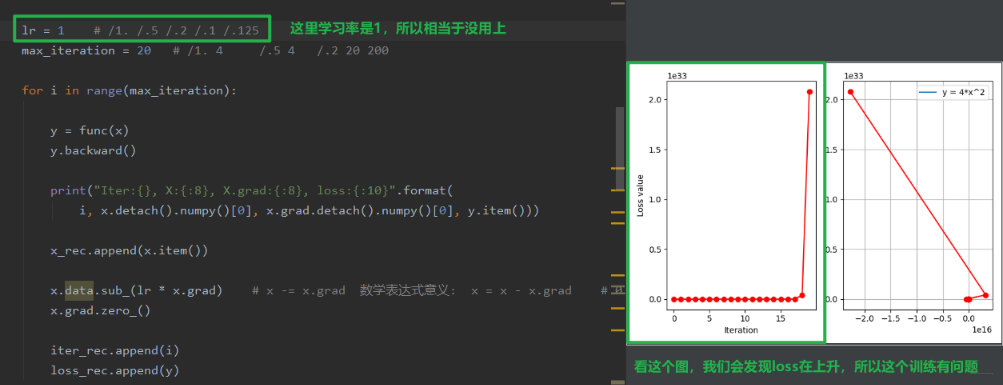
我们可以看一下上面的图像,loss 是不断上升的,这说明这个跨度是有问题的,所以下面我们尝试改小一点学习率,我们就可以发现区别了: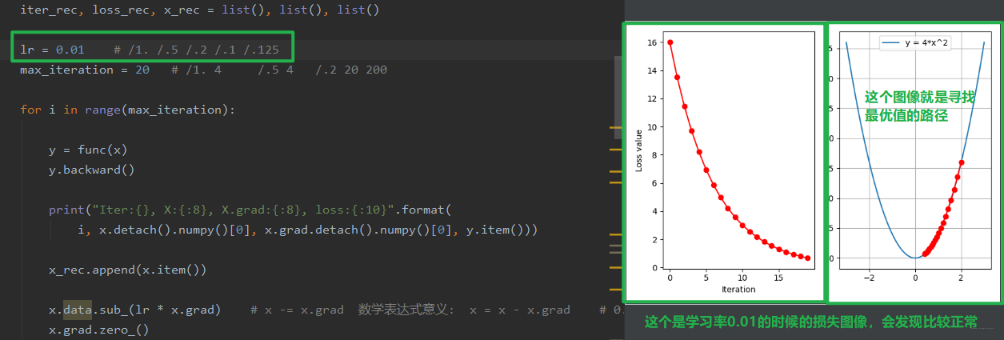
我们发现,当 loss 上升不降的时候,有可能是学习率的问题,所以我们一般会尝试一个小的学习率。 慢慢的去进行优化。
学习率一般是我们需要调的一个非常重要的超参数, 我们一般是给定一个范围,然后画出 loss 的变化曲线,看看哪学习率比较好,当然下面也会重点学习学习率的调整策略。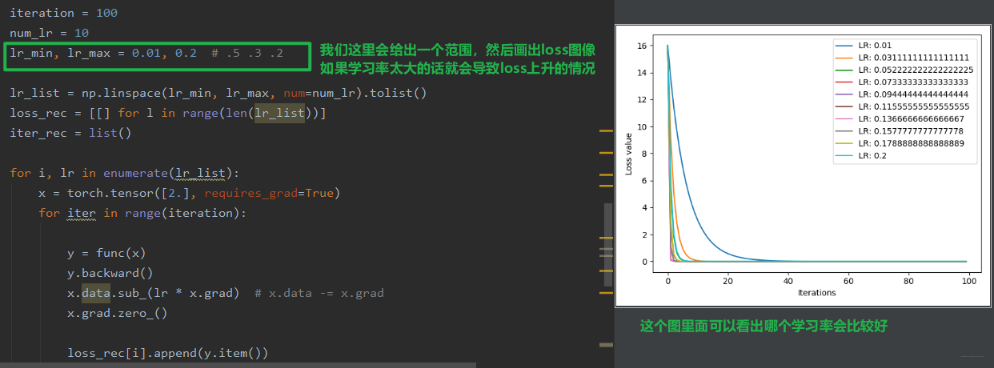
2.3.2 动量
Momentum:结合当前梯度与上一次更新信息, 用于当前更新。这么说可能有点抽象, 那么我们可以举个比较形象的例子: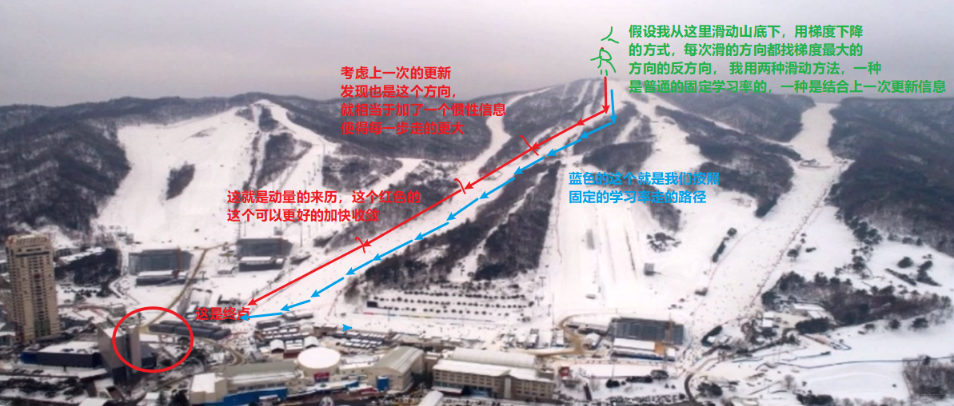
那么这个动量是怎么作用于我们的更新的呢? 在这之前,我们得先学习一个概念叫做指数加权平均, 指数加权平均在时间序列中经常用于求取平均值的一个方法,它的思想是这样,我们要求取当前时刻的平均值,距离当前时刻越近的那些参数值,它的参考性越大,所占的权重就越大,这个权重是随时间间隔的增大呈指数下降,所以叫做指数滑动平均。公式如下: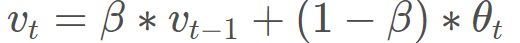
vt是当前时刻的一个平均值,这个平均值有两项构成,一项是当前时刻的参数值θt, 所占的权重是1−β, 这个β是个参数。 另一项是上一时刻的一个平均值, 权重是β。
当然这个公式看起来还是很抽象,丝毫没有看出点指数滑动的意思, 那么还是用吴恩达老师 PPT 里的一个例子解释一下吧:
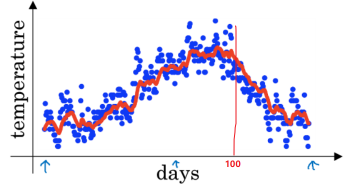
看上面这个温度图像,横轴是第几天,然后纵轴是温度, 假设我想求第 100 天温度的一个平均值,那么根据上面的公式: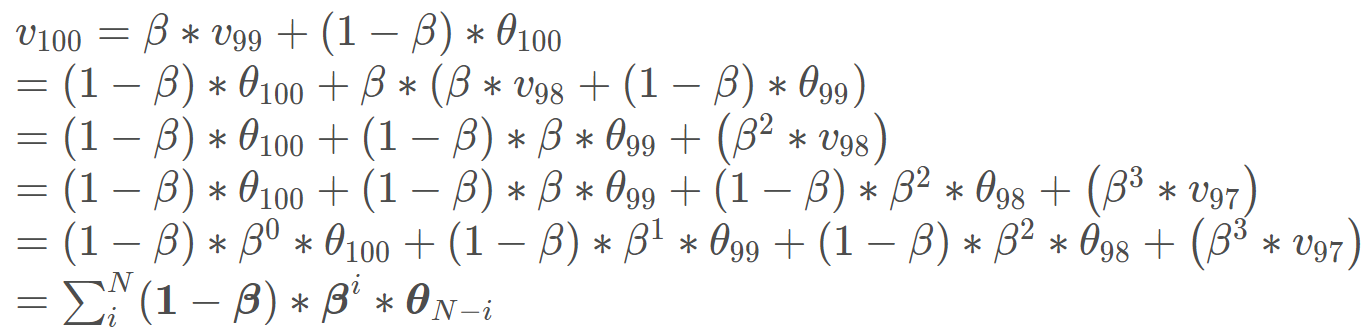
最下面这一行就是通式了,我们发现,距离当前时刻越远的那些θ值,它的权重是越来越小的,因为β小于 1, 所以间隔越远,小于 1 的这些数连乘,权重越来越小,而且是乘指数下降,因为这里是βi。 下面通过代码看一下这个权重,也就是(1−β)∗βi 是怎么变化的,亲身感受一下这里的指数下降:
距离当前时刻越远,对当前时刻的一个平均值影响就越小。距离当前时刻越近,对当前时刻的一个平均值影响越大,这就是指数加权平均的思想了。 这里我们发现,有个超参数β, 这个到底是干嘛的? 我们先来观察一个图, 还是上面的代码,我们设置不同的 β \beta β来观察一下这个权重的变化曲线:
我们可以发现,beta 越小,就会发现它关注前面一段时刻的距离就越短,比如这个 0.8, 会发现往前关注 20 天基本上后面的权重都是 0 了,意思就是说这时候是平均的过去 20 天的温度, 而 0.98 这个,会发现,关注过去的天数会非常长,也就是说这时候平均的过去 50 天的温度。所以beta 在这里控制着记忆周期的长短,或者平均过去多少天的数据,这个天数就是1/(1-β), 通常 beta 设置为 0.9, 物理意义就是关注过去 10 天左右的一个温度。 这个参数也是比较重要的, 还是拿吴恩达老师 PPT 的一张图片: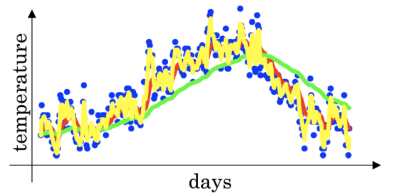
看上图,是不同 beta 下得到的一个温度变化曲线
- 红色的那条,是 beta=0.9, 也就是过去 10 天温度的平均值
- 绿色的那条,是 beta=0.98, 也就是过去 50 天温度的平均值
- 黄色的那条,beta=0.5, 也就是过去 2 天的温度的平均
可以发现,如果这个β很高, 比如 0.98, 最终得到的温度变化曲线就会平缓一些,因为多平均了几天的温度, 缺点就是曲线进一步右移, 因为现在平均的温度值更多, 要平均更多的值, 指数加权平均公式,在温度变化时,适应的更缓慢一些,所以会出现一些延迟,因为如果 β \beta β\=0.98,这就相当于给前一天加了太多的权重,只有 0.02 当日温度的权重, 所以温度变化时,温度上下起伏,当 β \beta β变大时,指数加权平均值适应的更缓慢一些, 换了 0.5 之后,由于只平均两天的温度值,平均的数据太少,曲线会有很大的噪声,更有可能出现异常值,但这个曲线能够快速适应温度的变化。 所以这个 β \beta β过大过小,都会带来问题。 一般取 0.9.

好了,理解了指数滑动平均之后,就来看看我们的 Momentum 了,其实所谓的 Momentum 梯度下降, 基本的想法是计算梯度的指数加权平均数,并利用该梯度更新权重, 我们看看在 Pytorch 中是怎么实现的:
- 普通的梯度下降:
- Momentum 梯度下降:

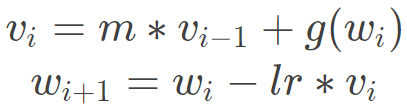
下面再通过代码看一下 momentum 的作用:
我们有 0.01 和 0.03 两个学习率,训练模型,我们看看 loss 的变化曲线: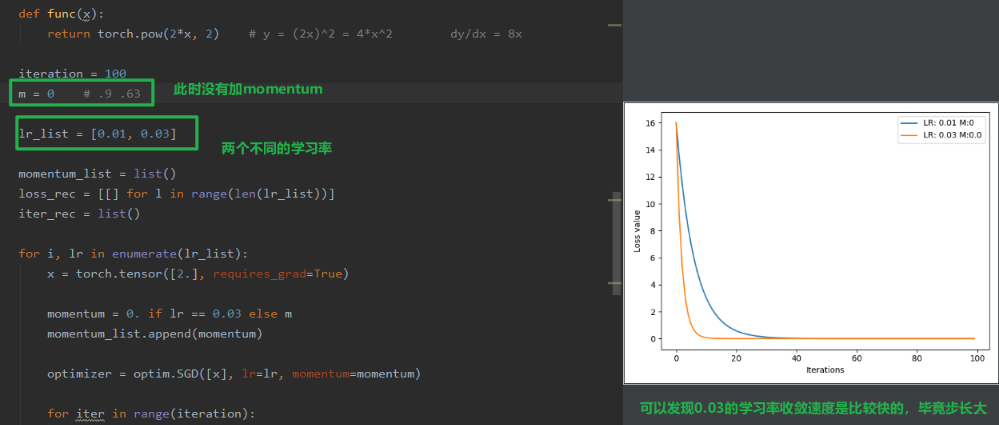
现在,我们给学习率 0.01 的这个加一个动量 momentum, 再看看效果: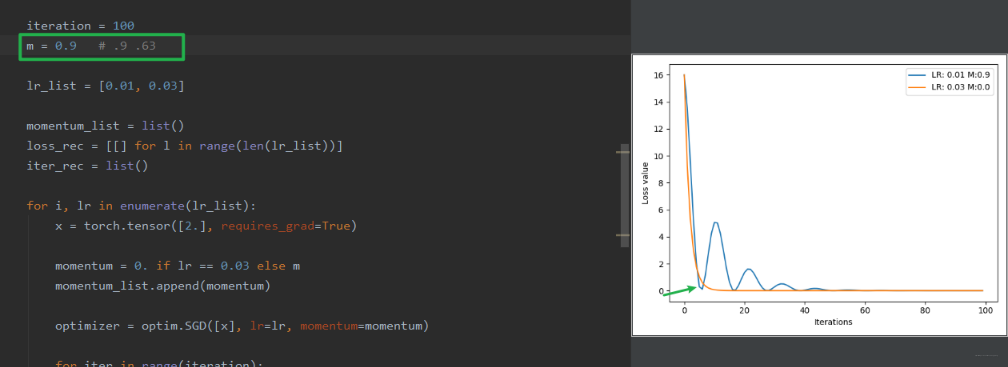
可以看到加上动量的 0.01 收敛的速度快了,但是前面会有震荡, 这是因为这里的 m 太大了,当日温度的权重太小,所以前面梯度一旦大小变化,这里就会震荡,当然会发现震荡会越来越小最后趋于平缓,这是因为不断平均的梯度越来越多。 这时候假设我们减少动量 m, 效果会好一些,比如 0.63: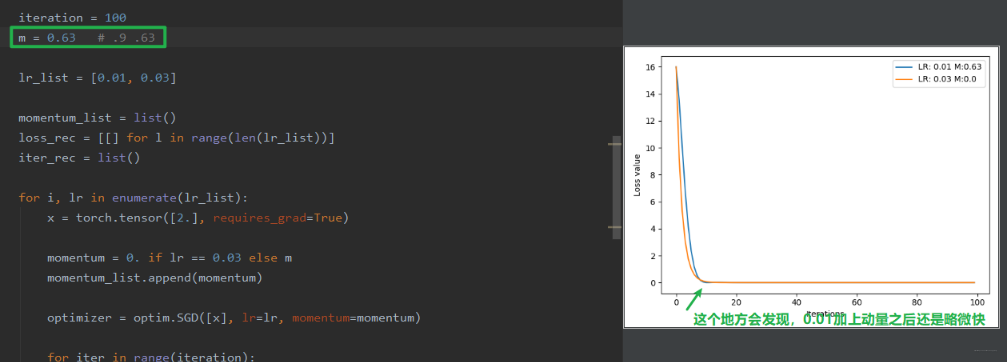
2.3.3 常用优化器介绍
- optim.SGD

- param: 管理的参数组
- lr: 初识学习率
- momentum:动量系数, beta
- weight_decay: L2 正则化系数
- nesterov: 是否采用 NAG
这个优化器是非常常用的。 然后下面列出 10 款优化器,具体的不去介绍, 可以大体了解有哪些优化器可用:
- optim.SGD: 随机梯度下降法
- optim.Adagrad: 自适应学习率梯度下降法
- optim.RMSprop: Adagrad 的改进
- optim.Adadelta: Adagrad 的改进
- optim.Adam: RMSprop 结合 Momentum
- optim.Adamax: Adam 增加学习率上限
- optim.SparseAdam: 稀疏版的 Adam
- optim.ASGD: 随机平均梯度下降
- optim.Rprop: 弹性反向传播
- optim.LBFGS: BFGS 的改进
这里面比较常用的就是optim.SGD和optim.Adam, 其他优化器的详细使用方法移步官方文档。
3. 学习率调整策略
上面我们已经学习了优化器,在优化器当中有很多超参数,例如学习率,动量系数等,这里面最重要的一个参数就是学习率。它直接控制了参数更新步伐的大小,整个训练当中,学习率也不是一成不变的,也可以调整和变化。 所以下面整理学习率的调整策略,首先是为什么要调整学习率,然后是 Pytorch 的六种学习率调整策略,最后是小结一下:
3.1 为什么要调整学习率
学习率是可以控制更新的步伐的。 我们在训练模型的时候,一般开始的时候学习率会比较大,这样可以以一个比较快的速度到达最优点的附近,然后再把学习率降下来, 缓慢的去收敛到最优值。 这样说可能比较抽象,玩过高尔夫球吗? 我们可以看一个例子:
我们开始的时候,一般是大力把球打到洞口的旁边,然后再把力度降下来,一步步的把球打到洞口,这里的学习率调整也差不多是这个感觉。
当然,再看一个函数的例子也行:
所以,在模型的训练过程中,调整学习率也是非常重要的,学习率前期要大,后期要小。Pytorch 中提供了一个很好的学习率的调整方法,下面我们就来具体学习,学习率该如何进行调整。
3.2 Pytorch 的学习率调整策略
在学习学习率调整策略之前,得先学习一个基类, 因为后面的六种学习率调整策略都是继承于这个类的,所以得先明白这个类的原理:
主要属性:
- optimizer: 关联的优化器, 得需要先关联一个优化器,然后再去改动学习率
- last_epoch: 记录 epoch 数, 学习率调整以 epoch 为周期
- base_lrs: 记录初始学习率
主要方法:
- step(): 更新下一个 epoch 的学习率, 这个是和用户对接
- get_lr(): 虚函数, 计算下一个 epoch 的学习率, 这是更新过程中的一个步骤
下面依然是人民币二分类的例子,看看 LRScheduler 的构建和使用: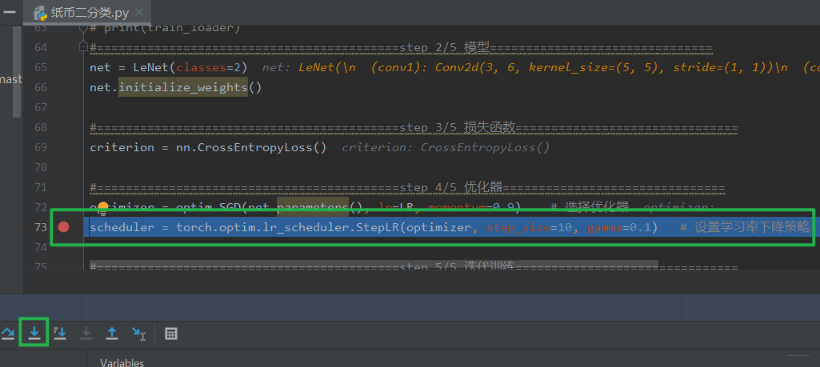
老规矩,打断点,debug,然后步入这个lr_scheduler.StepLR这个类。这个类就是继承_LRScheduler的。我们运行到初始化的父类初始化那一行,然后再次步入。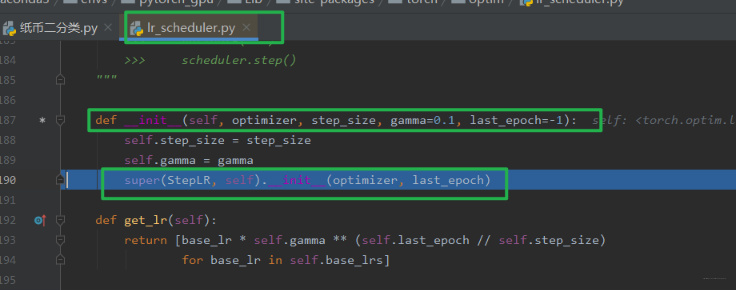
看看父类的这个__init__怎么去构建一个最基本的 Scheduler 的。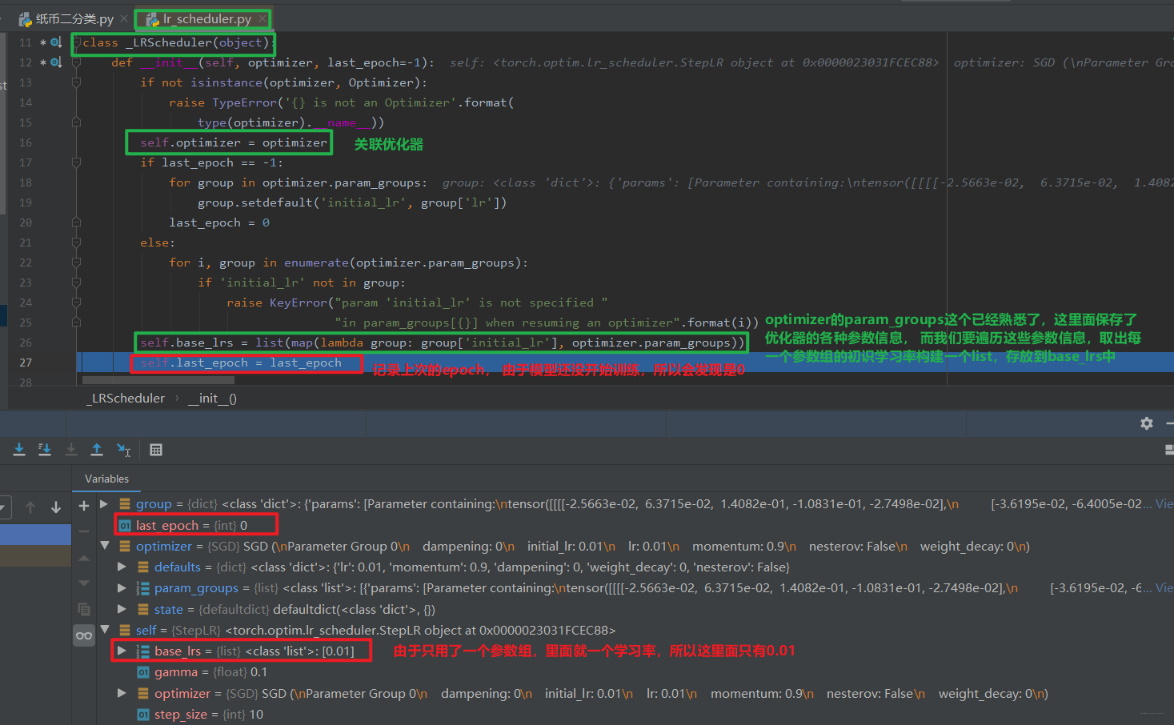
这样我们就构建好了一个 Scheduler。下面就看看这个 Scheduler 是如何使用的, 当然是调用 step() 方法更新学习率了, 那么这个 step() 方法是怎么工作的呢? 继续调试: 打断点,debug,步入:
步入之后,我们进入了_LRScheduler的step函数,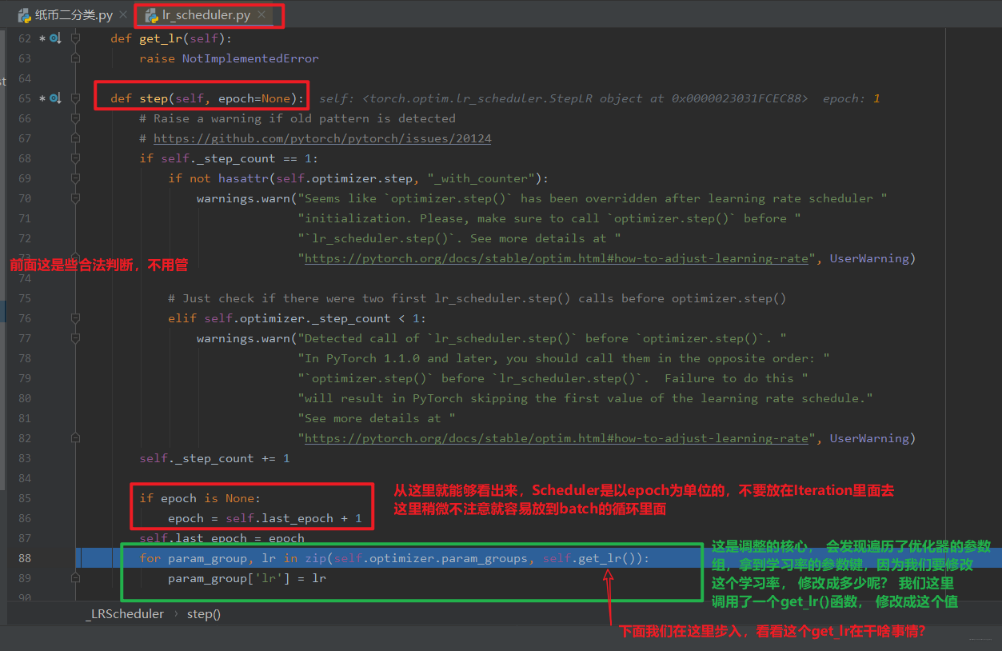
我们发现,这个跳到了我们的 StepLR 这个类里面,因为我们说过,这个 get_lr 在基类里面是个虚函数,我们后面编写的 Scheduler 要继承这个基类,并且要覆盖这个 get_lr 函数,要不然程序不知道你想怎么个衰减学习率法啊。 所以我们得把怎么减学习率通过这个函数告诉程序: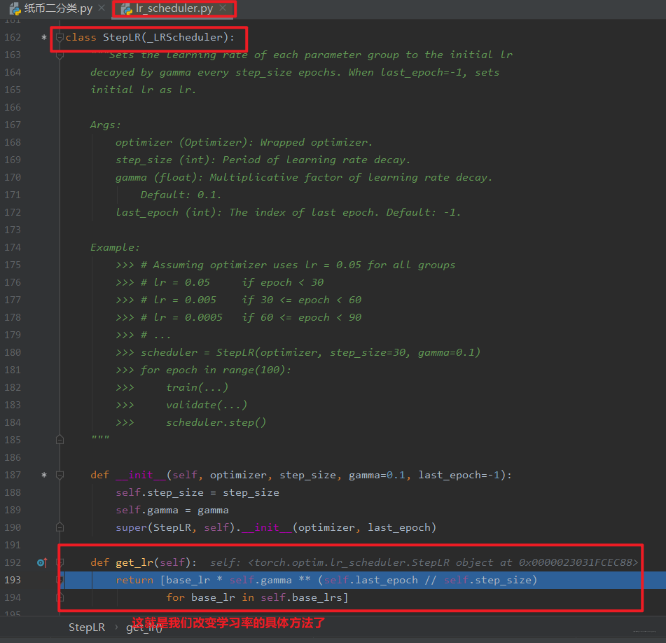
可以看到这里面就用到了初始化时候的 base_lr 属性。
下面关于优化器的定义和使用的内部运行原理就可以稍微总结了,首先我们在定义优化器的时候,这时候会完成优化器的初始化工作, 主要有关联优化器 (self.optimizer属性), 然后初始化last_epoch和base_lrs(记录原始的学习率,后面get_lr方法会用到)。 然后就是用 Scheduler,我们是直接用的step()方法进行更新下一个 epoch 的学习率(这个千万要注意放到 epoch 的 for 循环里面而不要放到 batch 的循环里面 ),而这个内部是在_Scheduler类的step()方法里面调用了get_lr()方法, 而这个方法需要我们写 Scheduler 的时候自己覆盖,告诉程序按照什么样的方式去更新学习率,这样程序根据方式去计算出下一个 epoch 的学习率,然后直接更新进优化器的_param_groups()里面去。
好了,下面就可以学习 Pytorch 提供的六种学习率调整策略:
- StepLR
功能: 等间隔调整学习率

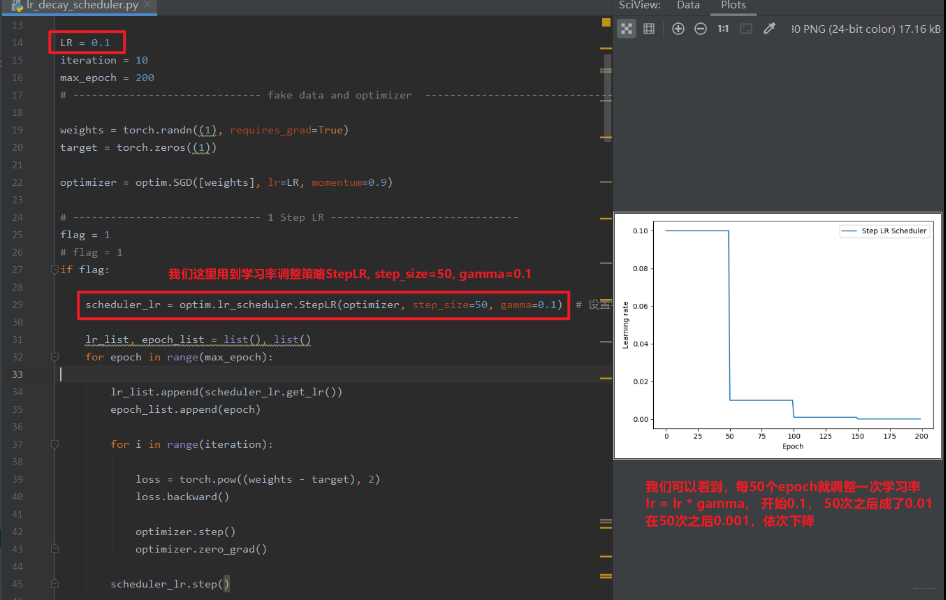
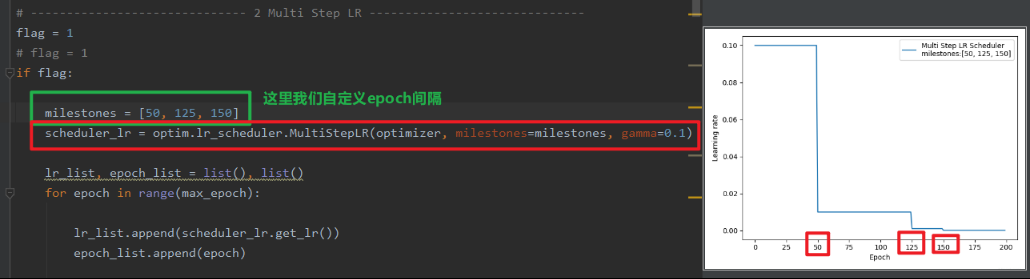
- MultiStepLR
功能: 按给定间隔调整学习率

- ExponentialLR
功能:按指数衰减调整学习率
gamma 表示指数的底了。 调整方式:
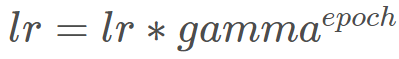
这个观察一下代码:
- CosineAnnealingLR
功能:余弦周期调整学习率
T_max 表示下降周期,只是往下的那一块。 eta_min 表示学习率下限, 调整方式: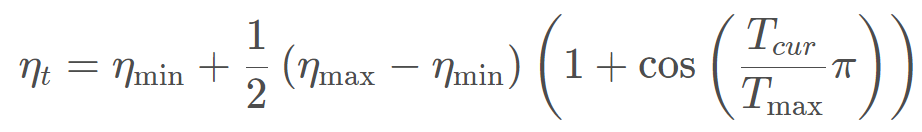
下面直接从代码中感受: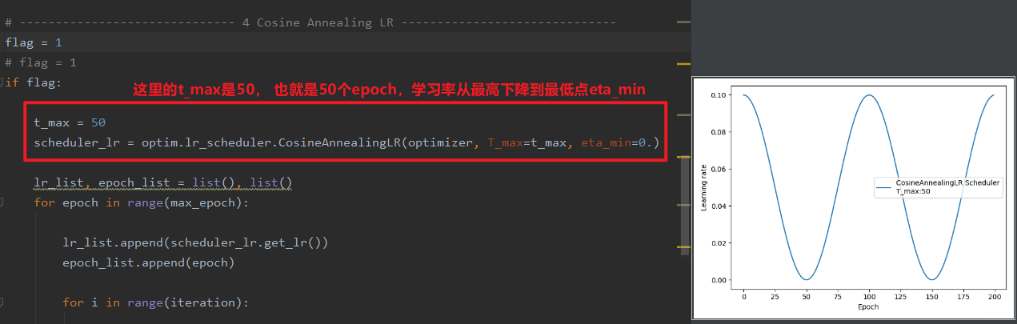
- ReduceLRonPlateau
功能: 监控指标, 当指标不再变化则调整, 这个非常实用。可以监控 loss 或者准确率,当不在变化的时候,我们再去调整。
主要参数:- mode: min/max 两种模式(min 就是监控指标不下降就调整,比如 loss,max 是监控指标不上升就调整, 比如 acc)
- factor: 调整系数,类似上面的 gamma
- patience: “耐心”, 接受几次不变化, 这一定要是连续多少次不发生变化
- cooldown: “冷却时间”, 停止监控一段时间
- verbose: 是否打印日志, 也就是什么时候更新了我们的学习率
- min_lr: 学习率下限
- eps: 学习率衰减最小值
下面我们直接从代码中学习这个学习率调整策略的使用: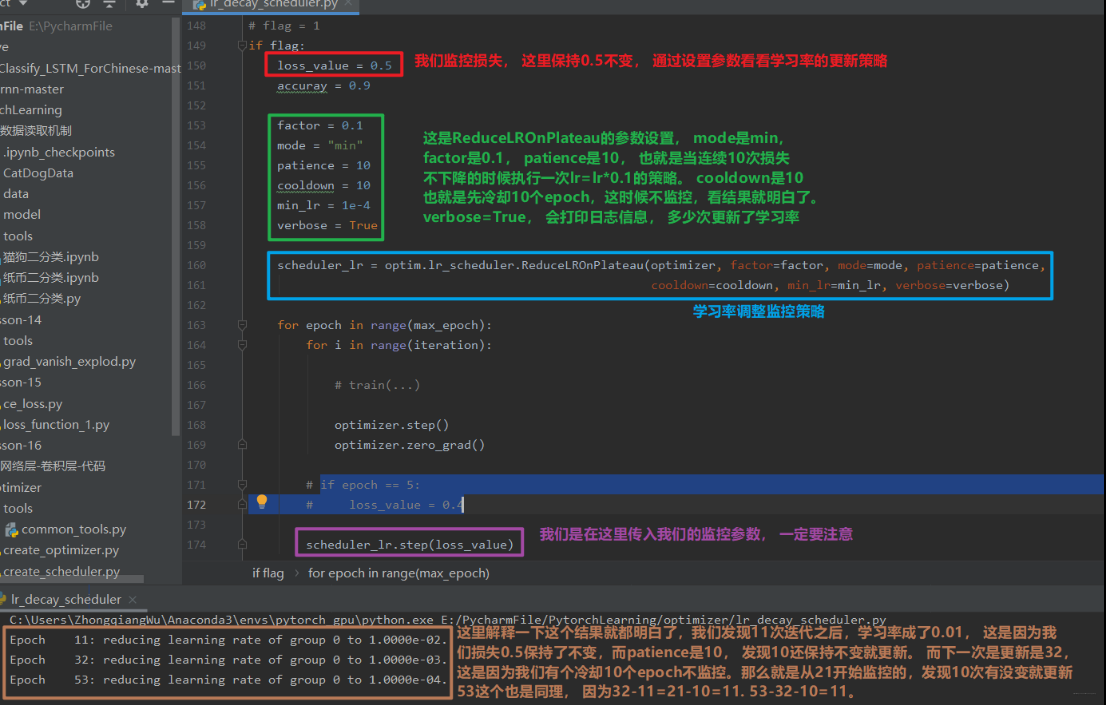
上面是学习率一直保持不变,如果我们在第 5 个 epoch 更新一下子,那么这个更新策略会成什么样呢?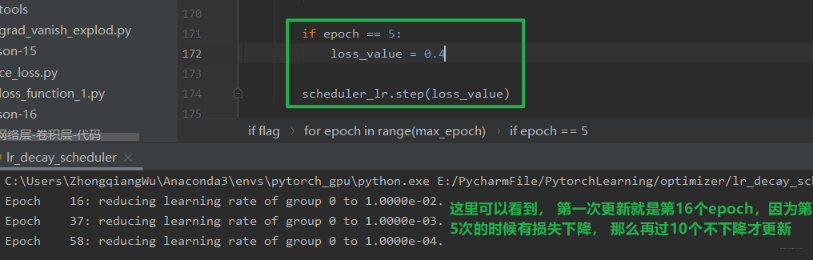
- LambdaLR
功能: 自定义调整策略,这个也比较实用,可以自定义我们的学习率更新策略,这个就是真的告诉程序我们想怎么改变学习率了。并且还可以对不同的参数组设置不同的学习率调整方法,所以在模型的 finetune 中非常实用。
这里的 lr_lambda 表示 function 或者是 list。 这个我们从代码中进行学习: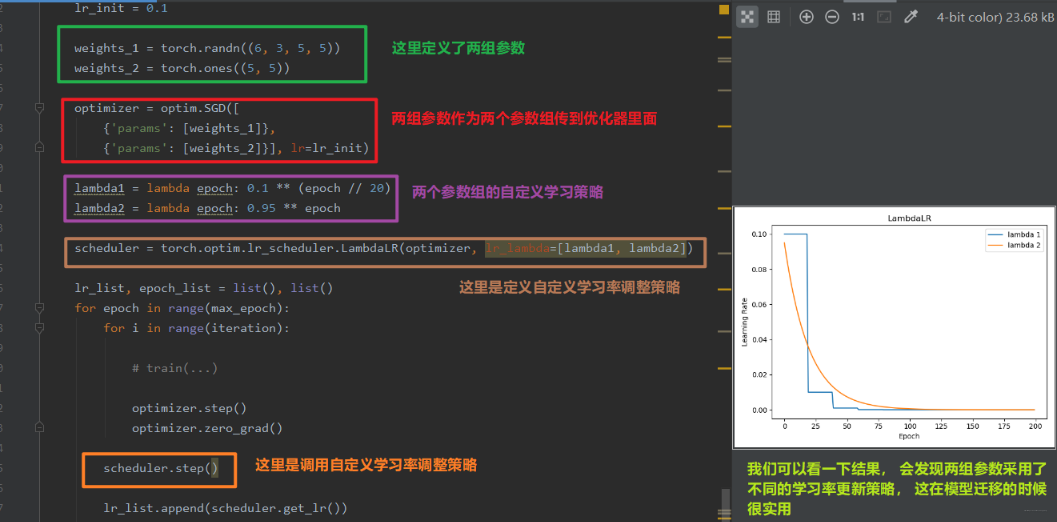
但这个过程到底是怎么实现的呢? 我们依然可以 debug 看一下过程,依然是调用get_lr()函数,但是我们这里看看这里面到底是怎么实现自定义的: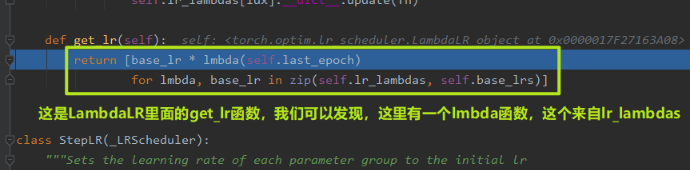
我们再这里再次 stepinto , 就会发现跳到了我们自定义的两个更新策略上来: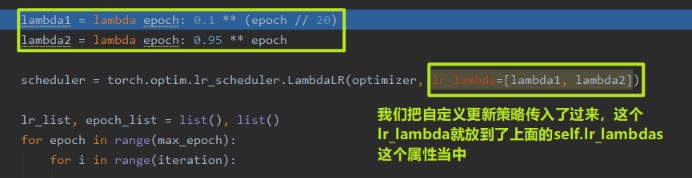
好了,六种学习率调整策略已经整理完毕,下面小结一下:
- 有序调整: Step、MultiStep、 Exponential 和 CosineAnnealing, 这些得事先知道学习率大体需要在多少个 epoch 之后调整的时候用
- 自适应调整: ReduceLROnPleateau, 这个非常实用,可以监控某个参数,根据参数的变化情况自适应调整
- 自定义调整:Lambda, 这个在模型的迁移中或者多个参数组不同学习策略的时候实用
调整策略就基本完了,那么我们得先有个初始的学习率啊, 下面介绍两种学习率初始化的方式:
- 设置较小数:0.01, 0.001, 0.0001
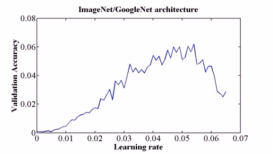
- 搜索最大学习率: 看论文《Cyclical Learning Rates for Training Neural Networks》, 这个就是先让学习率从 0 开始慢慢的增大,然后观察 acc, 看看啥时候训练准确率开始下降了,就把初始学习率定为那个数。
4. 总结
今天的内容就是这些了,还是有点多的,依然是快速梳理一遍,我们今天开始的优化器模块,优化器管理更新参数,不断降低损失。 首先从优化器本身开始学习,学习了优化器的基本属性和方法,并通过代码调试的方式了解了优化器的初始化和使用原理。 然后学习了常用的优化器,介绍了两个非常关键的概念学习率和动量, 学习了 SGD 优化器。 优化器中非常重要的一个参数就是学习率,在模型的训练过程中,对学习率调整非常关键,所以最后又学习了学习率的 6 种调整策略,从三个维度进行总结。
下面依然是一张导图把这次的知识拎起来,方便以后查阅: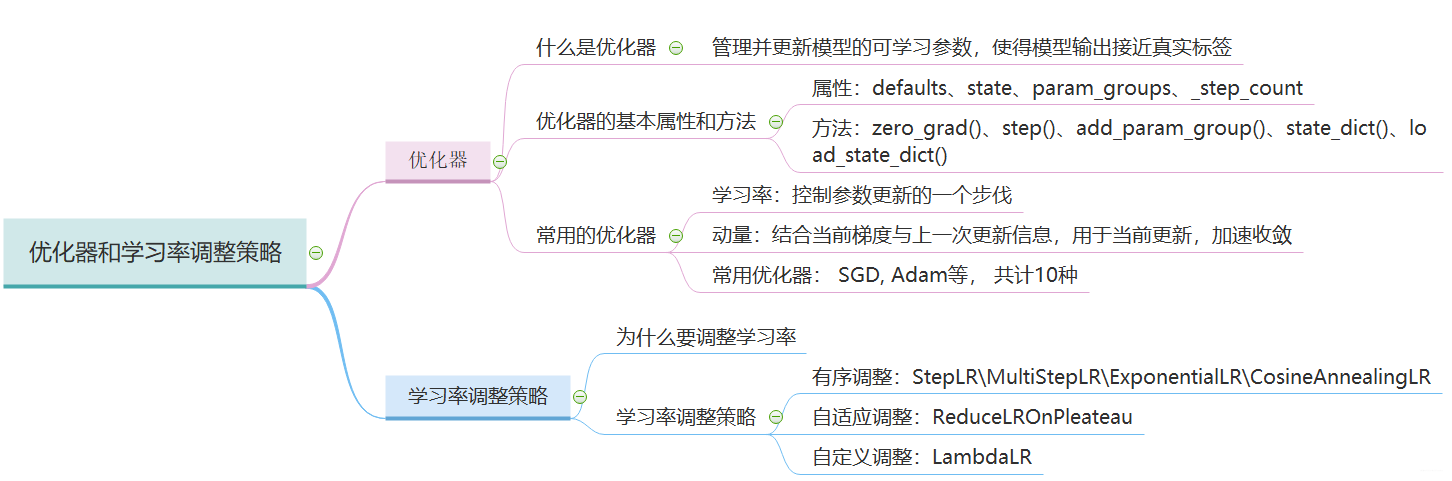

若有收获,就点个赞吧
0 人点赞
