Transformer的概念以及相对于与传统CNN、RNN的优势 Transformer的实现,Multi-head Attention、FFN、AddNorm还有Encoder、Decoder等子模块
- 我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs)。让我们进行一些回顾:
- CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
- RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
- 为了整合CNN和RNN的优势,[Vaswani et al., 2017] 创新性地使用注意力机制设计了Transformer模型。
- 该模型利用attention机制实现了并行化捕捉序列依赖
- 并且同时处理序列的每个位置的tokens
- 上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
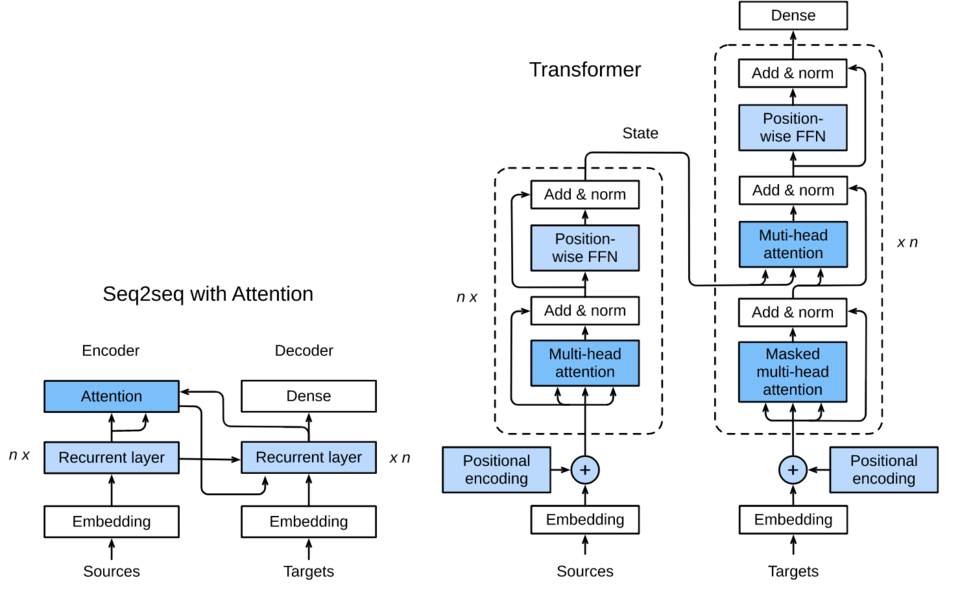
下图展示了Transformer模型的架构,与seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
- Transformer blocks:将seq2seq模型中的循环网络替换为了Transformer Blocks
- 该模块包含多头注意力层(Multi-head Attention Layers)以及position-wise feed-forward networks(FFN)
- 对于解码器来说,增加一个多头注意力层被用于接受编码器的隐藏状态。
- Add and norm:多头注意力层和前馈网络的输出分别被送到“add and norm”层进行处理
- 该层包含残差结构以及层归一化。
- Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。
多头注意力层
自注意力(self-attention)
- 序列的每一个元素对应的key,value,query是完全一致的。
- 如图10.3.2 自注意力输出了一个与输入长度相同的表征序列
- 循环神经网络相比,自注意力对每个元素输出的计算是并行的,所以我们可以高效的实现这个模块。
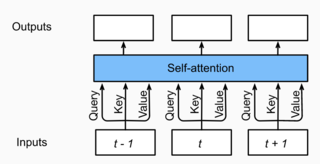
自注意力结构
- 多头注意力层包含h个并行的自注意力层,每一个这种层被成为一个head。
- 对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这h个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。
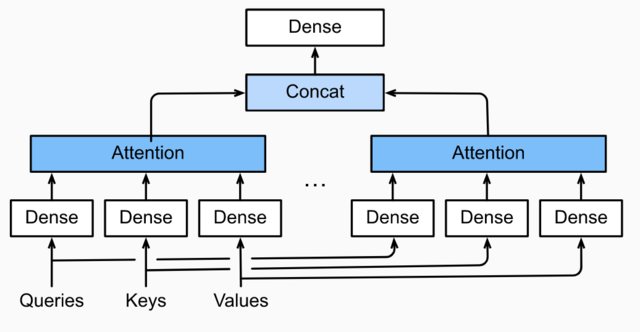
多头注意力Fig.10.3.3 多头注意力
- 假设query,key和value的维度分别是dq、dk和dv。那么对于每一个头i=1,…,h,我们可以训练相应的模型权重Wq(i)∈Rpq×dq、Wk(i)∈Rpk×dk和Wv(i)∈Rpv×dv,以得到每个头的输出:
o(i)=attention(Wq(i)q,Wk(i)k,Wv(i)v)
- 这里的attention可以是任意的attention function,比如前一节介绍的dot-product attention以及MLP attention。
- 之后我们将所有head对应的输出拼接起来,送入最后一个线性层进行整合,这个层的权重可以表示为Wo∈Rd0×hpv
o=Wo[o(1),…,o(h)]
接下来我们就可以来实现多头注意力了,假设我们有h个头,隐藏层权重 hidden_size=pq=pk=pv 与query,key,value的维度一致。除此之外,因为多头注意力层保持输入与输出张量的维度不变,所以输出feature的维度也设置为 d0=hidden_size。
基于位置的前馈网络
它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。
Position-wise FFN由两个全连接层组成,他们作用在最后一维上。
它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。
这里 Layer Norm 与Batch Norm很相似
与循环神经网络不同,无论是多头注意力网络还是前馈神经网络都是独立地对每个位置的元素进行更新
- 这种特性帮助我们实现了高效的并行,却丢失了重要的序列顺序的信息。
- 为了更好的捕捉序列信息,Transformer模型引入了位置编码去保持输入序列元素的位置。
- 假设输入序列的嵌入表示 X∈Rl×d, 序列长度为l嵌入向量维度为d,则其位置编码为P∈Rl×d ,输出的向量就是二者相加 X+P。
- 位置编码是一个二维的矩阵,i对应着序列中的顺序,j对应其embedding vector内部的维度索引。我们可以通过以下等式计算位置编码:
Pi,2j=sin(i/100002j/d)
Pi,2j+1=cos(i/100002j/d)
for i=0,…,l−1 and j=0,…,⌊(d−1)/2⌋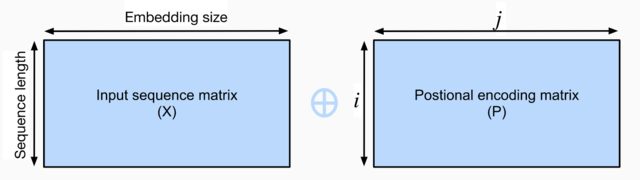
位置编码
编码器解码器
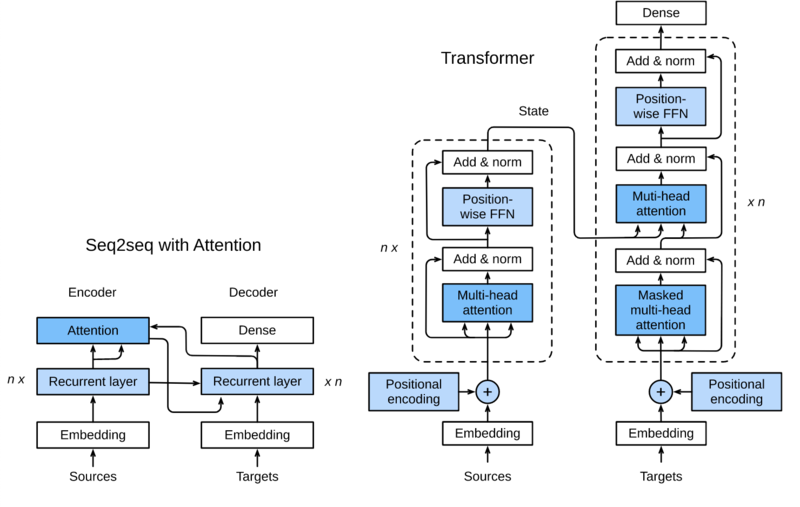
- Transformer 模型的解码器与编码器结构类似,增加了一个多头注意力层
- 接受编码器的输出作为key和value,decoder的状态作为query。
- 与编码器部分相类似,解码器同样是使用了add and norm机制,用残差和层归一化将各个子层的输出相连。
- 在第t个时间步,当前输入xt是query,那么self attention接受了第t步以及前t-1步的所有输入x1,…,xt−1。
- 在训练时,由于第t位置的输入可以观测到全部的序列,这与预测阶段的情形项矛盾,所以我们要通过将第t个时间步所对应的可观测长度设置为t,以消除不需要看到的未来的信息。

若有收获,就点个赞吧
0 人点赞
