词嵌入基础
- 我们在“循环神经网络的从零开始实现”一节中使用 one-hot 向量表示单词,虽然它们构造起来很容易,但通常并不是一个好选择。
- 一个主要的原因是,one-hot 词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。
- Word2Vec 词嵌入工具的提出正是为了解决上面这个问题,它将每个词表示成一个定长的向量,并通过在语料库上的预训练使得这些向量能较好地表达不同词之间的相似和类比关系,以引入一定的语义信息。
- 基于两种概率模型的假设,我们可以定义两种 Word2Vec 模型:
- Skip-Gram 跳字模型:假设背景词由中心词生成,即建模 P(wo∣wc),其中 wc 为中心词,wo 为任一背景词;
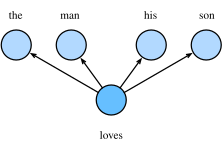
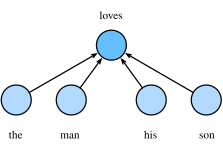
- CBOW (continuous bag-of-words) 连续词袋模型:假设中心词由背景词生成,即建模 P(wc∣Wo),其中 Wo 为背景词的集合。
数据预处理
- 载入数据集
- 建立下标到token, token到下标的映射
- 二次采样
- 文本数据中一般会出现一些高频词,如英文中的“the”“a”和“in”。
- 通常来说,在一个背景窗口中,一个词(如“chip”)和较低频词(如“microprocessor”)同时出现比和较高频词(如“the”)同时出现对训练词嵌入模型更有益。
- 因此,训练词嵌入模型时可以对词进行二次采样。 具体来说,数据集中每个被索引词 wi 将有一定概率被丢弃,该丢弃概率为

- 其中 f(wi) 是数据集中词 wi 的个数与总词数之比,常数 t 是一个超参数(实验中设为 10−4)。- 可见,只有当 f(wi)>t 时,我们才有可能在二次采样中丢弃词 wi,并且越高频的词被丢弃的概率越大
-
Skip-Gram 跳字模型
在跳字模型中,每个词被表示成两个 d 维向量,用来计算条件概率。
- 中心词和背景词
- 假设这个词在词典中索引为 i ,当它为中心词时向量表示为 vi∈Rd,而为背景词时向量表示为 ui∈Rd 。
- 设中心词 wc 在词典中索引为 c,背景词 wo 在词典中索引为 o,我们假设给定中心词生成背景词的条件概率满足下式:
负采样近似
- 由于 softmax 运算考虑了背景词可能是词典 V 中的任一词,对于含几十万或上百万词的较大词典,就可能导致计算的开销过大。
- 负采样方法用以下公式来近似条件概率
 :
:



若有收获,就点个赞吧
0 人点赞
