梯度下降
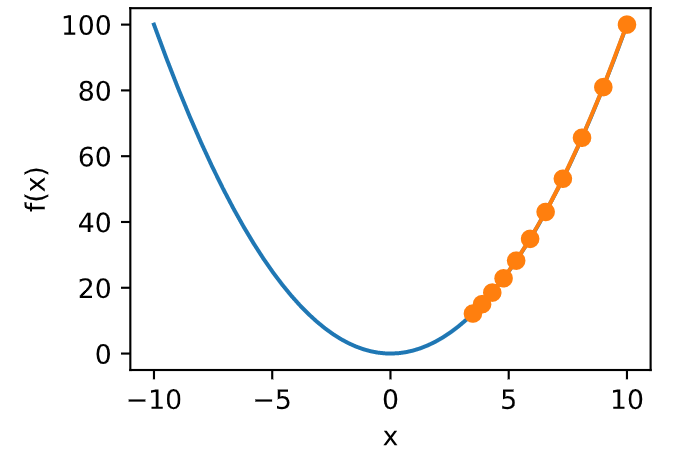
一维梯度下降
证明:沿梯度反方向移动自变量可以减小函数值
泰勒展开:
f(x+ϵ)=f(x)+ϵf′(x)+O(ϵ2)
代入沿梯度方向的移动量 ηf′(x):
f(x−ηf′(x))=f(x)−ηf′2(x)+O(η2f′2(x))
f(x−ηf′(x))≲f(x)
x←x−ηf′(x)
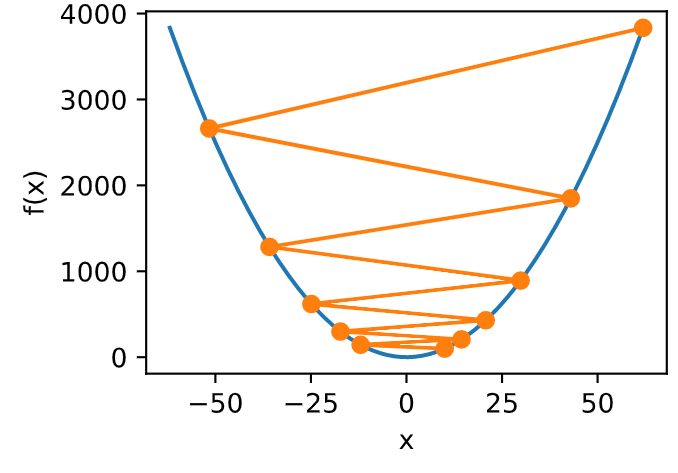
学习率
- 0.05
1.1
-
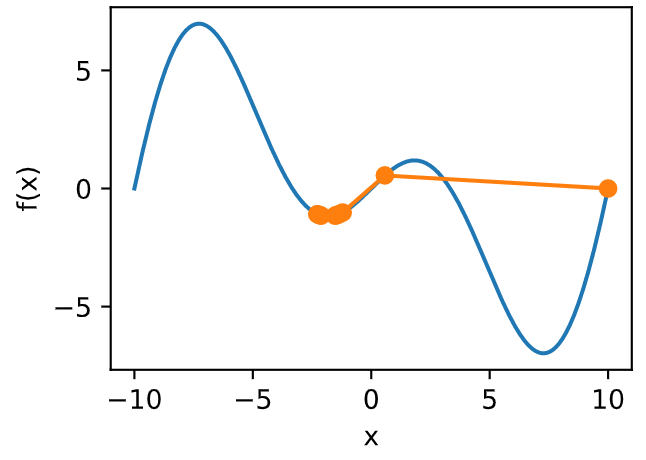
收敛性分析
只考虑在函数为凸函数, 且最小值点上 f″(x∗)>0 时的收敛速度:
令 xk 为第 k 次迭代后 x 的值, ek:=xk−x∗ 表示 xk 到最小值点 x∗ 的距离,由 f′(x∗)=0:
0=f′(xk−ek)=f′(xk)−ekf′′(xk)+12ek2f′′′(ξk)for some ξk∈[xk−ek,xk]
两边除以 f″(xk), 有:
ek−f′(xk)/f′′(xk)=12ek2f′′′(ξk)/f′′(xk)
代入更新方程 xk+1=xk−f′(xk)/f′′(xk), 得到:
xk−x∗−f′(xk)/f′′(xk)=12ek2f′′′(ξk)/f′′(xk)
xk+1−x∗=ek+1=12ek2f′′′(ξk)/f′′(xk)
当 12f′′′(ξk)/f′′(xk)≤c 时,有:
ek+1≤cek2预处理 (Heissan阵辅助梯度下降)
x←x−ηdiag(Hf)−1∇x
-
随机梯度下降
随机梯度下降参数更新
对于有 n 个样本对训练数据集,设 fi(x) 是第 i 个样本的损失函数, 则目标函数为:
f(x)=1n∑i=1nfi(x)
其梯度为:
∇f(x)=1n∑i=1n∇fi(x)
使用该梯度的一次更新的时间复杂度为 O(n)
随机梯度下降更新公式 O(1):
x←x−η∇fi(x)
且有:
Ei∇fi(x)=1n∑i=1n∇fi(x)=∇f(x)动态学习率

一开始学习率要大,尽快收敛
-
小批量随机梯度下降
batch介于1和total之间
- batch过小,没有很好地利用并行性,引入噪声
- batch过大,更新一次的计算复杂度高,更新慢,噪声最小

若有收获,就点个赞吧
0 人点赞
