机器翻译和数据处理
机器翻译(MT)
- 将一段文本从一种语言自动翻译为另一种语言
- 用神经网络解决这个问题通常称为神经机器翻译(NMT)
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
数据预处理
将数据集清洗
句子长度不一致,需要用
填充至最大长度 - 计算loss时需要忽略掉
填充的部分
- 计算loss时需要忽略掉
- 利用TensorDataset和DataLoader将数据集转化成batch的输入
Encoder-Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出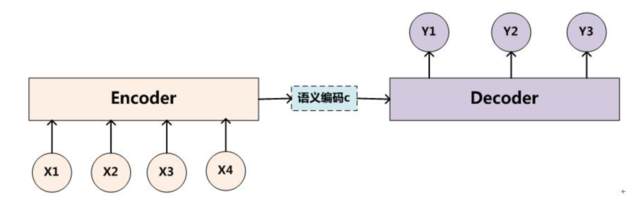
Sequence to Sequence模型
模型:
训练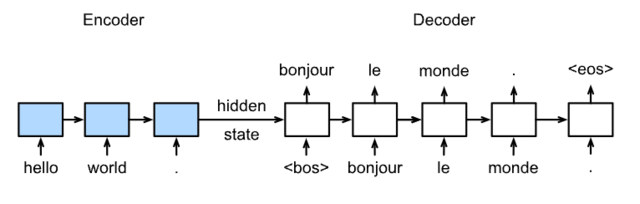
预测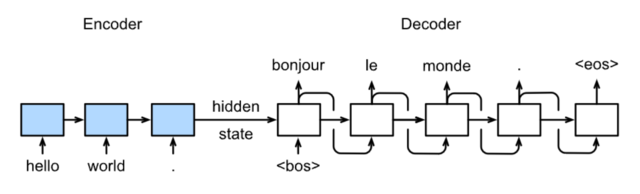
具体结构:
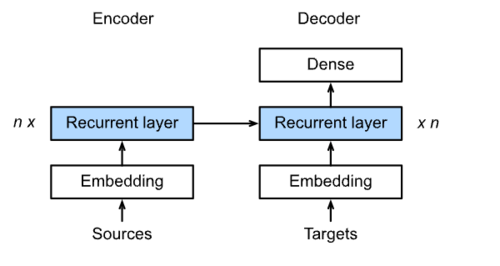
Beam Search
简单greedy search: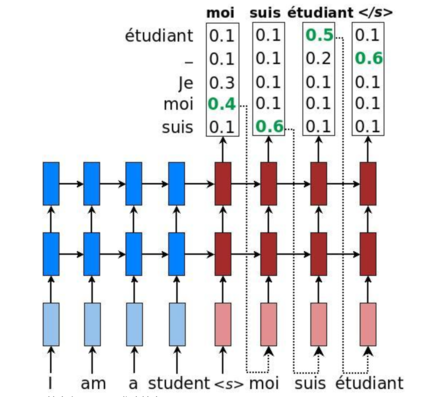
维特比算法:选择整体分数最高的句子(搜索空间太大) 集束搜索: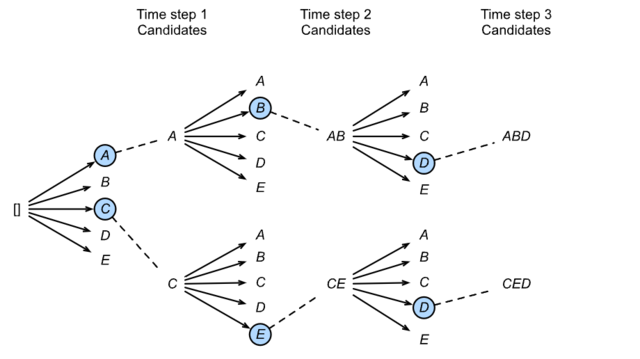

若有收获,就点个赞吧
0 人点赞
