介绍了注意力机制的概念和框架 介绍了点积注意力机制和多层感知机注意力机制的实现 最后介绍了使用注意力机制的seq2seq模型
注意力机制
- 解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。
- 例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。
- 在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。
-
注意力机制框架
Attention 是一种通用的带权池化方法,输入由两部分构成:
- 询问(query)Query 𝐪∈ℝ𝑑𝑞
- 键值对(key-value pairs)。𝐤𝑖∈ℝ𝑑𝑘,𝐯𝑖∈ℝ𝑑𝑣
- attention layer得到输出与value的维度一致 𝐨∈ℝ𝑑𝑣.
- 对于一个query来说,attention layer 会与每一个key计算注意力分数并进行权重的归一化,输出的向量o则是value的加权求和,而每个key计算的权重与value一一对应。
- 为了计算输出,我们首先假设有一个函数α 用于计算query和key的相似性,然后可以计算所有的 attention scores a1,…,an by
ai=α(q,ki).
- 我们使用 softmax函数 获得注意力权重:
b1,…,bn=softmax(a1,…,an).
- 最终的输出就是value的加权求和:
o=∑i=1nbivi.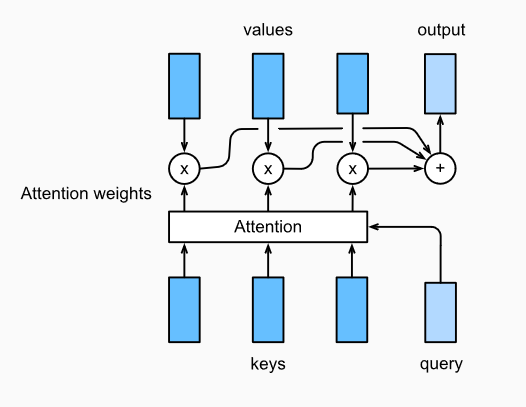
不同的attetion layer的区别在于score函数的选择
点积注意力
The dot product 假设query和keys有相同的维度, 即 ∀i,𝐪,𝐤𝑖∈ℝ𝑑. 通过计算query和key转置的乘积来计算attention score,通常还会除去 d 减少计算出来的score对维度𝑑的依赖性,如下
𝛼(𝐪,𝐤)=⟨𝐪,𝐤⟩/d
假设 𝐐∈ℝ𝑚×𝑑 有 m 个query,𝐊∈ℝ𝑛×𝑑 有 n 个keys. 我们可以通过矩阵运算的方式计算所有 mn 个score:
𝛼(𝐐,𝐊)=𝐐𝐊𝑇/d多层感知机注意力
在多层感知器中,我们首先将 query and keys 投影到 ℝℎ .为了更具体,我们将可以学习的参数做如下映射 𝐖𝑘∈ℝℎ×𝑑𝑘 , 𝐖𝑞∈ℝℎ×𝑑𝑞 , and 𝐯∈ℝh . 将score函数定义
𝛼(𝐤,𝐪)=𝐯𝑇tanh(𝐖𝑘𝐤+𝐖𝑞𝐪)
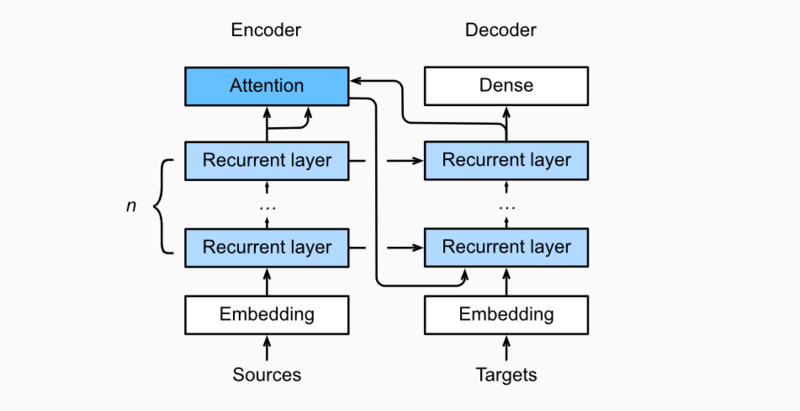
. 然后将key 和 value 在特征的维度上合并(concatenate),然后送至 a single hidden layer perceptron 这层中 hidden layer 为 ℎ and 输出的size为 1 .隐层激活函数为tanh,无偏置.引入注意力机制的Seq2seq模型
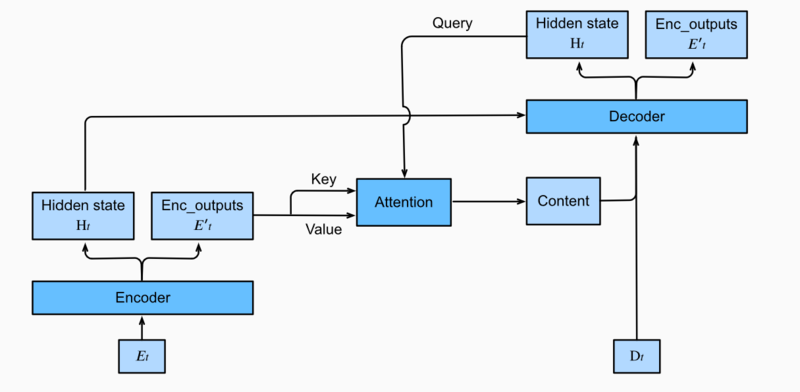
在时间步为t的时候,attention layer保存着encodering看到的所有信息——即encoding的每一步输出。
- 在decoding阶段
- 解码器的t时刻的隐藏状态被当作query
- encoder的每个时间步的hidden states作为key和value进行attention聚合.
- Attetion model的输出当作成上下文信息context vector,并与解码器输入Dt拼接起来一起送到解码器:

若有收获,就点个赞吧
0 人点赞
