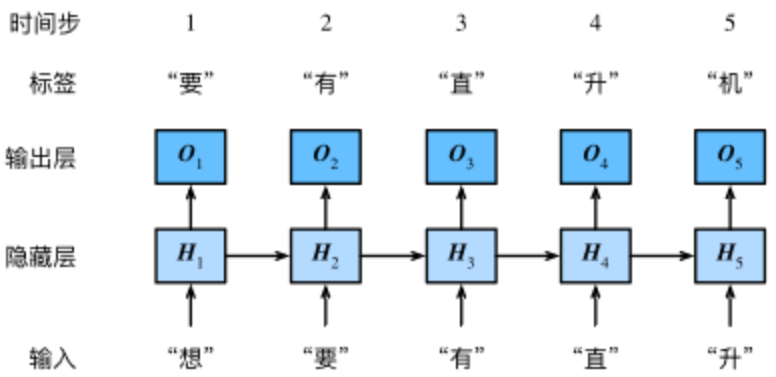
- 我们的目的是基于当前的输入与过去的输入序列,预测序列的下一个字符。
循环神经网络引入一个隐藏变量H,用Ht表示HH在时间步t的值。Ht的计算基于Xt和Ht−1,可以认为Ht记录了到当前字符为止的序列信息,利用Ht对序列的下一个字符进行预测。
构造
假设Xt∈Rn×d是时间步t的小批量输入,Ht∈Rn×h是该时间步的隐藏变量,则:
Ht=ϕ(XtWxh+Ht−1Whh+bh).由于引入了Ht−1Whh,Ht能够捕捉截至当前时间步的序列的历史信息
- 由于Ht的计算基于Ht−1,上式的计算是循环的,使用循环计算的网络即循环神经网络(recurrent neural network)。
裁剪梯度
- 由于循环神经网络中参数共享,加之其循环的特性,容易出现梯度消失或者是爆炸的情况
- 裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 g,并设裁剪的阈值是θ。裁剪后的梯度
困惑度
我们通常使用困惑度(perplexity)来评价语言模型的好坏。
困惑度(perplexity)的基本思想是:给测试集的句子赋予较高概率值的语言模型较好。
当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
由公式可知,句子概率越大,语言模型越好,迷惑度越小。**
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
显然,任何一个有效模型的困惑度必须小于类别个数。在RNN中,必须小于词典大小vocab_size。
定义模型训练函数
跟之前章节的模型训练函数相比,这里的模型训练函数有以下几点不同:
- 使用困惑度评价模型。
- 在迭代模型参数前裁剪梯度。
- 对时序数据采用不同采样方法将导致隐藏状态初始化的不同。
- 随机采样:对于每一个batch都需要初始化隐藏状态,因为相邻batch之间没有任何关系
- 相邻采样:只需要在开始初始化隐藏状态,因为相邻batch之间样本也是相邻的

若有收获,就点个赞吧
0 人点赞
