大纲如下:
- 计算图与 Pytorch 的动态图机制(计算图的概念,动态图与静态图的差异和搭建过程)
- Pytorch 的自动求导机制
- 基于前面所学玩一个逻辑回归
- 总结梳理
2. 计算图与 Pytorch 的动态图机制
2.1 计算图
前面已经整理了张量的一系列操作,而深度学习啊, 其实就是对各种张量进行操作,随着操作的种类和数量的增大,会导致各种想不到的问题,比如多个操作之间该并行还是顺序执行,底层的设备如何协同,如何避免冗余的操作等,这些问题都会影响我们算法的执行效率,甚至会出现一些 bug。 而计算图就是为了解决这些问题而产生的, 那么什么是计算图呢?
计算图是用来描述运算的有向五环图。 主要有两个因素: 节点和边。 其中节点表示数据,如向量,矩阵,张量, 而边表示运算,如加减乘除,卷积等。下面我们看一下具体这东西具体是什么样子: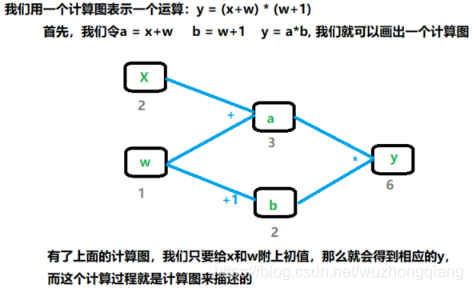
使用计算图的好处不仅让计算看起来更加简洁,还有个更大的优势就是让梯度求导也变得更加方便。下面我们看看 y 对 w 进行求导的过程: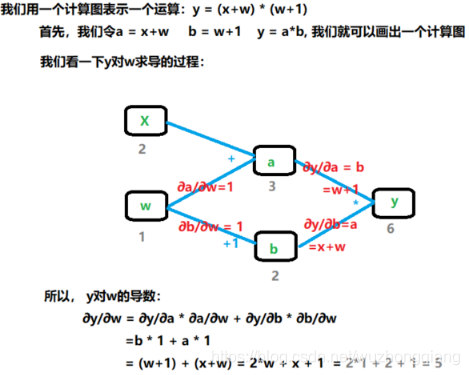
y 对 w 求导,就是从计算图中找到所有 y 到 w 的路径。把各个路径的导数进行求和。我们通过程序来验证一下: ``` w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) b = torch.add(w, 1) y = torch.mul(a, b)
y.backward() print(w.grad)
下面,我们基于这个计算图来说几个张量里面重要的属性:1. 叶子节点这个属性 (还记得张量的属性里面有一个 is_leaf 吗):<br />叶子节点: 用户创建的节点, 比如上面的 x 和 w。叶子节点是非常关键的,在上面的正向计算和反向计算中,其实都是依赖于我们叶子节点进行计算的。<br />is_leaf: 指示张量是否是叶子节点。<br />为什么要设置叶子节点的这个概念的? 主要是为了节省内存,因为我们在反向传播完了之后,非叶子节点的梯度是默认被释放掉的。我们可以根据上面的那个计算过程,来看看 w,x, a, b, y 的 is_leaf 属性,和它们各自的梯度情况:```jsonprint("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)is_leaf:True True False False Falsegradient:tensor([5.]) tensor([2.]) None None None
我们可以发现, 只有 w, x 的 is_leaf 属性是 True, 说明这俩是叶子节点。 gradient 上,也只有叶子节点的梯度被保留了下来, a, b, y 的梯度都默认释放了,所以是空。但是我们如果想用这里面的某个梯度呢? 比如我想保留 a 的梯度, 那么可以使用 retain_grad() 方法。 就是在执行反向传播之前, 执行一行代码: a.retain_grad() 即可。``` w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) a.retain_grad() b = torch.add(w, 1) y = torch.mul(a, b)
y.backward()
print(“gradient:\n”, w.grad, x.grad, a.grad, b.grad, y.grad)
gradient: tensor([5.]) tensor([2.]) tensor([2.]) None None
2. grad_fn: 记录创建该张量时所用的方法(函数),记录这个方法主要**用于梯度的求导**。要不然怎么知道具体是啥运算?
w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) a.retain_grad() b = torch.add(w, 1) y = torch.mul(a, b)
y.backward()
print(“grad_fn:\n”, w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
None None
这个属性,会记录变量具体是怎么得到的, 比如两数相加,或者两数相乘,这样反向计算梯度的时候才能使用相应的法则求变量的梯度。 当然知道是用于反向传播即可。<a name="6Lw72"></a>## 2.2 Pytorch 的动态图机制根据计算图的搭建方式,可以将计算图分为动态图和静态图。- 静态图: 先搭建图,后运算。高效,不灵活(TensorFlow)- 动态图: 运算与搭建同时进行。灵活,易调节(Pytorch)这个就类似于旅游的时候你找旅行团还是自己去旅游一样,找旅行团的这种就类似于静态图,游览的路线和流程都已经确定,跟着走就行了。 如果你熟悉 TensorFlow 的话,会知道 TensorFlow 的计算方式,是先把图搭建好,然后开启一个会话, 在那里面才开始喂入数据进行流动计算, 在这个过程中,张量就会根据搭建好的图进行计算。 我们可以看看上面的那个例子:```jsonw = tf.constant(1.)x = tf.constant(2.)a = tf.add(w, x)b = tf.add(w, 1)y = tf.multiply(a, b)print(y)with tf.Session() as sess:print(sess.run(y))
而自己去旅游这个就类似于动态图,游览的路线和流程都不确定,想去哪去哪,随时调整。Pytorch 就是采用的这种机制,这种机制就是边建图边执行,从上面的例子中也能看出来,比较灵活, 有错误可以随时改,也更接近我们一般的想法。毕竟没有谁做一件事情之前就能把所有的流程都能规划好,一般人都是有一个大体的框架,然后一步一步边走边调整。依然是上面的例子:
w = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)print(y)
这里会发现直接就算出了 y 的结果,这说明上面的每一步都进行了计算。
3. Pytorch 的自动求导机制
Pytorch 自动求导机制使用的是 torch.autograd.backward 方法, 功能就是自动求取梯度。
- tensors 表示用于求导的张量,如 loss。
- retain_graph 表示保存计算图, 由于 Pytorch 采用了动态图机制,在每一次反向传播结束之后,计算图都会被释放掉。如果我们不想被释放,就要设置这个参数为 True
- create_graph 表示创建导数计算图,用于高阶求导。
- grad_tensors 表示多梯度权重。如果有多个 loss 需要计算梯度的时候,就要设置这些 loss 的权重比例。
这时候我们就有疑问了啊? 我们上面写代码的过程中并没有见过这个方法啊? 我们当时不是直接 y.backward() 吗? 哪有什么 torch.autograd.backward() 啊? 其实,当我们执行 y.backward() 的时候,背后其实是在调用后面的这个函数, 不行? 我们来调试一下子就清楚了: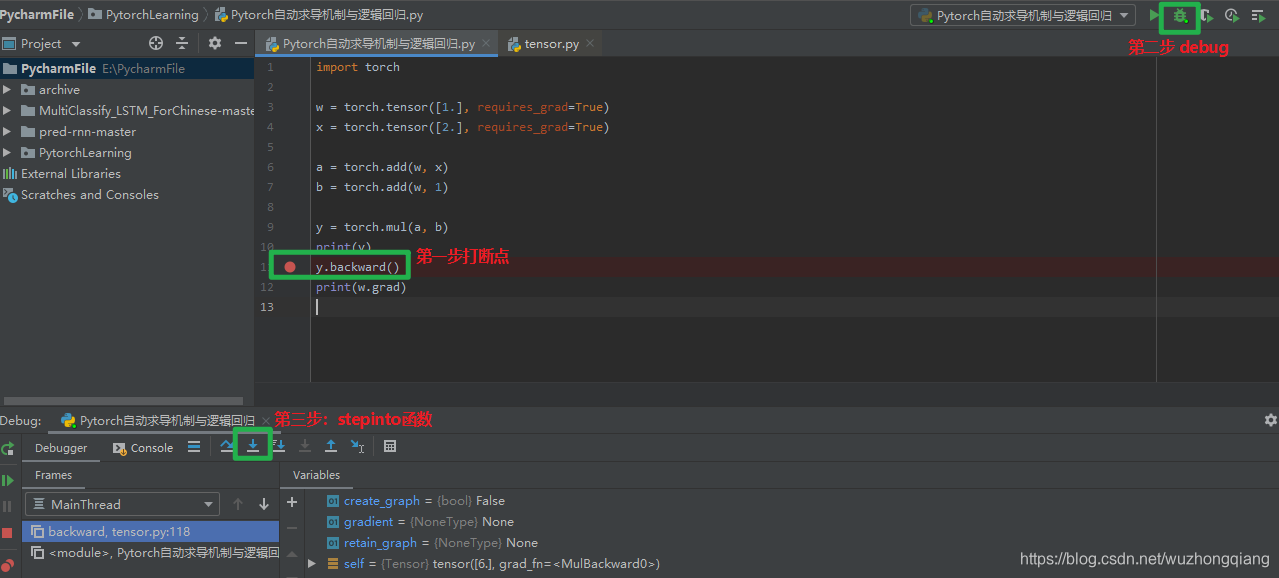
我们在这一行打断点,然后进行调试。 我们进入这个函数之后,会发现:
def backward(self, gradient=None, retain_graph=None, create_graph=False):torch.autograd.backward(self, gradient, retain_graph, create_graph)
这样就清楚了,这个 backward 函数就是在调用这个自动求导的函数。
backward() 里面有个参数叫做 retain_graph, 这个是控制是否需要保留计算图的, 默认是不保留,即一次反向传播之后,计算图就会被释放掉,这时候,如果再次调用 y.backward, 就会报错: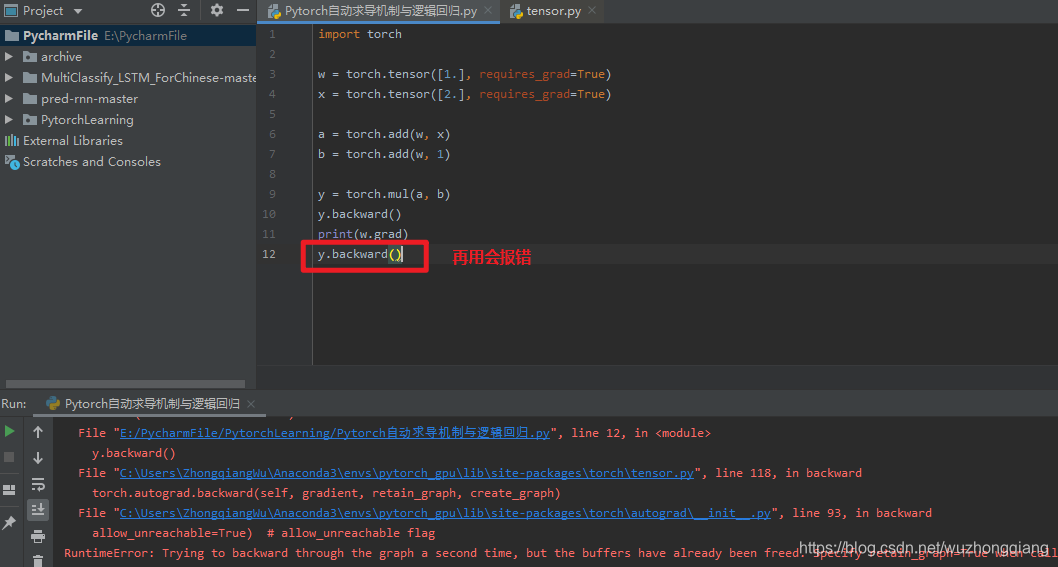
报错信息就是说的计算图已经释放掉了。 所以我们把第一次用反向传播的那个 retain_graph 设置为 True 就 OK 了:
y.backward(retain_graph=True)
这里面还有一个比较重要的参数叫做 grad_tensors, 这个是当有多个梯度的时候,控制梯度的权重,这个是什么意思,依然拿上面的那个举例: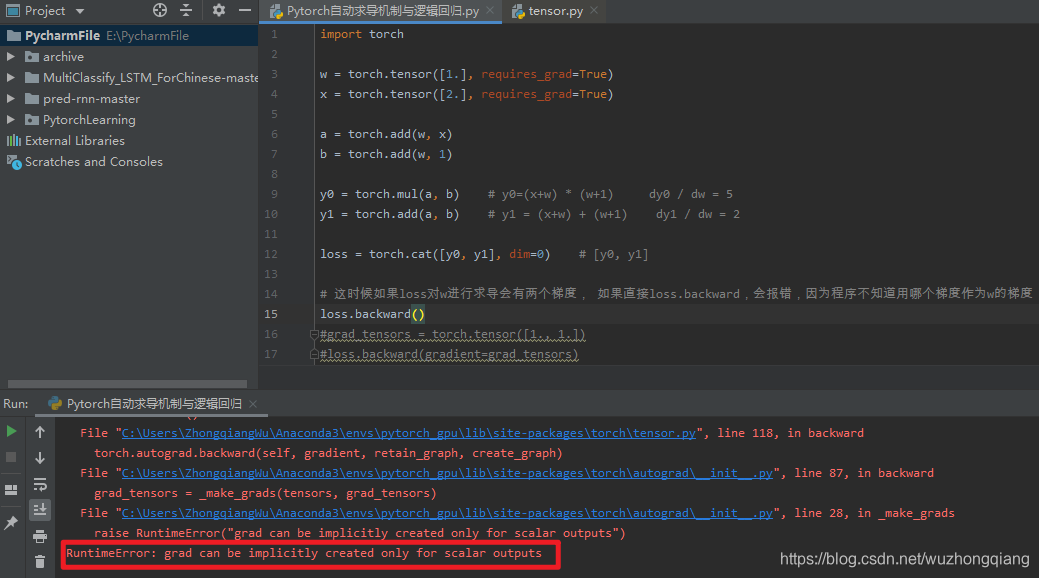
上面这个过程会报错,这时候我们就需要用到 gradient 这个参数了, 给两个梯度设置权重,最后得到的 w 的梯度就是带权重的这两个梯度之和。
grad_tensors = torch.tensor([1., 1.])loss.backward(gradient=grad_tensors)print(w.grad)grad_tensors = torch.tensor([1., 2.])loss.backward(gradient=grad_tensors)print(w.grad)
除了 backward() 方法,还有一个比较常用的方法叫做:torch.autograd.grad(), 这个方法的功能是求取梯度, 这个可以实现高阶的求导。
- outputs: 用于求导的张量, 如 loss
- inputs: 需要梯度的张量, 如上面例子的 w
- create_graph: 创建导数计算图,用于高阶求导
- retain_graph: 保存计算图
- grad_outputs: 多梯度权重
拿个例子看一下就明白了这个方法如何使用了:
x = torch.tensor([3.], requires_grad=True)y = torch.pow(x, 2)grad_1 = torch.autograd.grad(y, x, create_graph=True)print(grad_1)grad_2 = torch.autograd.grad(grad_1[0], x)print(grad_2)
这个函数还允许对多个自变量求导数:
x1 = torch.tensor(1.0,requires_grad = True)x2 = torch.tensor(2.0,requires_grad = True)y1 = x1*x2y2 = x1+x2(dy1_dx1,dy1_dx2) = torch.autograd.grad(outputs=y1,inputs = [x1,x2],retain_graph = True)print(dy1_dx1,dy1_dx2)(dy12_dx1,dy12_dx2) = torch.autograd.grad(outputs=[y1,y2],inputs = [x1,x2])print(dy12_dx1,dy12_dx2)
关于 Pytorch 的自动求导系统要注意:
- 梯度不自动清零 就是每一次反向传播,梯度都会叠加上去, 这个要注意, 举个例子:```python w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True)
for i in range(4): a = torch.add(w, x) b = torch.add(w, 1) y = torch.mul(a, b)
y.backward()print(w.grad)
tensor([5.]) tensor([10.]) tensor([15.]) tensor([20.])
会发现,每次 w 的梯度都会累加, 执行了四次,最后是 20 了。这样就会发生错误了,尤其是训练神经网络的时候特别注意。毕竟我们肯定不是训练一次,所以每一次反向传播之后,我们**要手动的清除梯度**<br />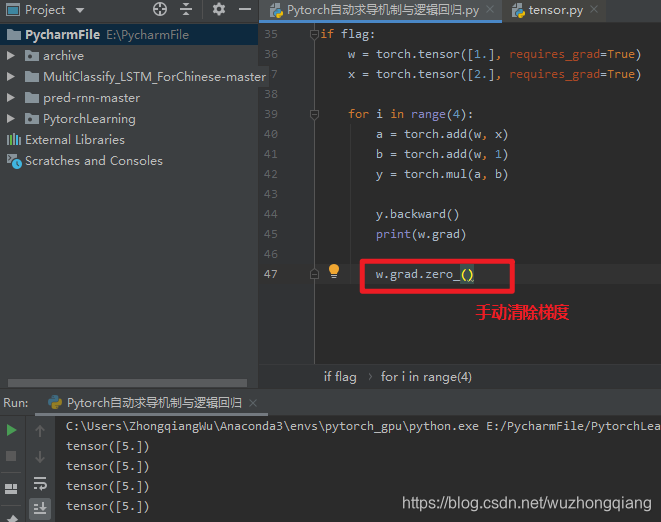<br />这里会发现个 zero_(), 这里有个下划线,这个代表原位操作, 后面第三条会详细说。2. 依赖于叶子节点的节点, requires_grad 默认为 True, 这是啥意思?<br />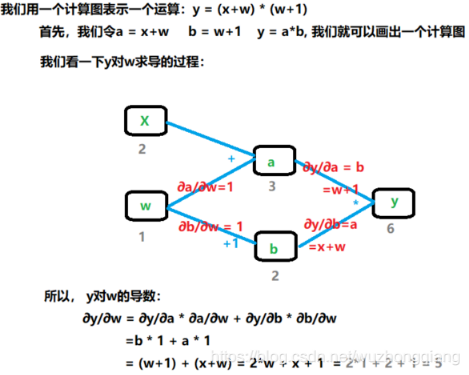<br />拿上面的计算图过来解释一下,依赖于叶子节点的节点,在上面图中 w,x 是叶子节点,而依赖于叶子节点的节点,其实这里说的就是 a,b, 也就是 a,b 默认就是需要计算梯度的。 这个也好理解,因为计算 w,x 的梯度的时候是需要先对 a, b 进行求导的,要用到 a, b 的梯度,所以这里直接默认 a, b 是需要计算梯度的。 在代码中,也就是这个意思:
w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) b = torch.add(w, 1)
y = torch.mul(a, b)
print(w.requires_grad, a.requires_grad, b.requires_grad)
3. 叶子节点不可执行 in-place(这个 in-place 就是原位操作)<br />首先先看看什么是 in-place 操作, 这个操作就是在原始内存当中去改变这个数据,这个理解起来的话,其实就是这个意思: 我们拿一个 a+1 的例子看一下,我们知道数字的话理论上是一个不可变数据对象,类似于字符串,元组这种,比如我假设 a=1, 然后我执行 a=a+1, 这样的话,a 虽然是 2,但是这两个 a 其实指向的对象是不一样的,原来的 1 并没有改变,执行 a+1, **是新建了一个对象出来**, 然后改变了原来 a 的指向。 这就是数字的不可变现象。 如果不理解,对比一下子就清楚了, 我们知道列表示可变的,假设 a=[1,5,3],我们可以 a.append(4),此时 a 指向的对象就变成了[1,5,3,4],但其实是在原对象[1,2,3]上进行的添加,**此过程没有新对象产生**。 我们还可以 a.sort(), 这时候 a 指向的对象就变成了[1, 3, 4, 5], 但依然是原对象上进行的改变。 说清楚了吧? 没有的话可以看看我 python 查缺补漏的第一篇文章, 那里面说的更详细些。这里重点说原位操作, 将数字进行原位操作之后, 这个数字就类似于列表这种,是在本身的内存当中改变的数,这时候就没有新对象建立出来。 a+=1 就是一种原位操作。 我们看个例子吧:```pythona = torch.ones((1,))print(id(a), a)a = a + torch.ones((1,))print(id(a), a)a = torch.ones((1,))print(id(a), a)a += torch.ones((1,))print(id(a), a)
好了,原位操作差不多理解了吧。 其实比较简单。 那么为什么叶子节点不能进行原位操作呢? 先看看叶子节点进行原位操作是怎么回事? 下面这个报错: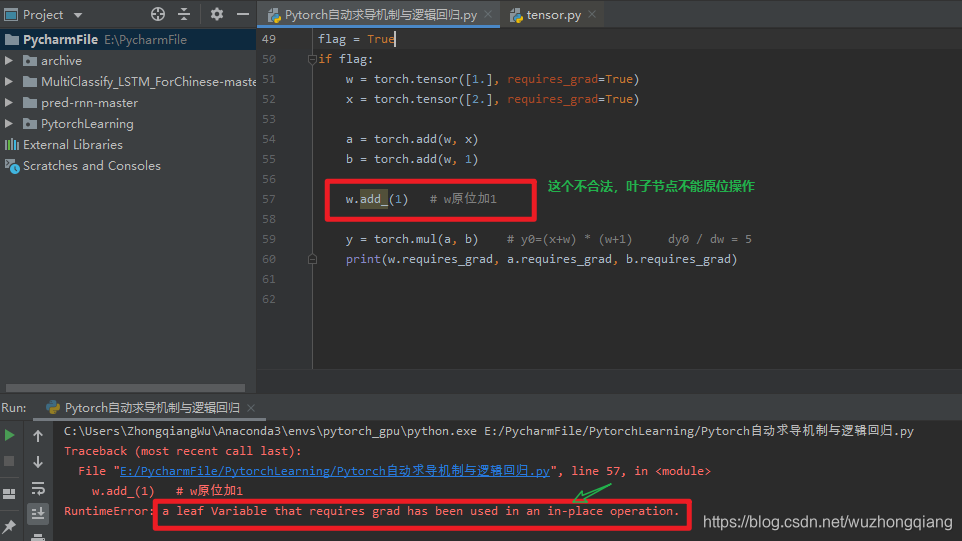
这是为什么呢? 这个要从计算图求取梯度的过程来理解,依然得把计算图拿过来: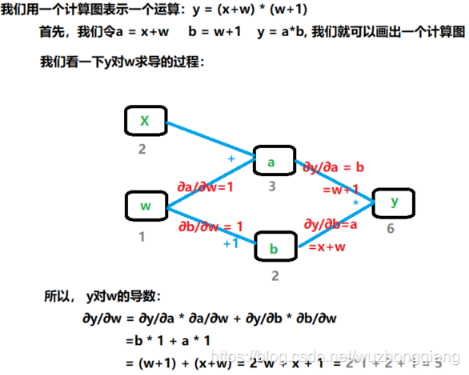
我们来看这个求取梯度的过程, 我们要求 w 的梯度的时候,我们发现会先∂y/∂a=w+1, 然后∂a/∂w, 也就是说反向传播的过程的∂y/∂a 就用到了 w, 这时候是怎么找到 w 的呢? 其实正向传播的时候,会把 w 的地址给记下来,然后反向传播的这一步,就是根据这个地址去找 w 的值。 如果在反向传播之前,就用原位操作把这个 w 的值给变了,那么反向传播再拿到这个 w 的值的时候,就出错了。 所以 Pytorch 不允许对叶子使用原位操作。 这就类似于去超市买东西存包取包的过程,假设我们去超市,需要把包先存到柜子,管理员给了我们一个号码牌 10 号,我们把包存进了 10 号柜子, 但如果管理员把 10 号柜子的东西换成了别人的包,你购物回来之后再拿 10 号的牌子去取自己的包,发现不在了,不就出错了?
前面已经学习了数据的载体张量,学习了如何通过前向传播搭建计算图,同时通过计算图进行梯度的求解,有了数据,计算图和梯度,我们就可以正式的训练机器学习模型了。接下来,我们就玩一个逻辑回归模型吧。
4. 逻辑回归模型
逻辑回归模型是线性的二分类模型,模型的表达式如下: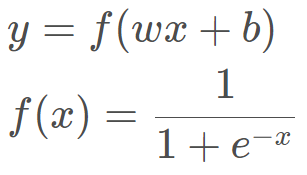
这里的f (x)就是 sigmoid 函数了, 也成为了 logistic 函数。 还记得 sigmoid 函数吗?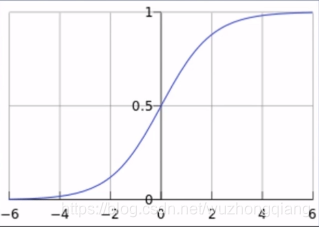
为什么说是二分类的问题呢?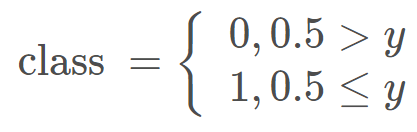
我们是根据这个 y 的取值进行分类的,当取值小于 0.5, 就判别为类别 0, 大于 0.5, 就判别为类别 1.
那为什么称为线性呢?我们可以对比一下线性回归和逻辑回归的区别:
- 线性回归: 自变量是 X, 因变量是 y, 关系: y=wx + b, 图像是一条直线。是分析自变量 x 和因变量 y(标量) 之间关系的方法。 注意这里的线性是针对于 w 进行说的, 一个 w 只影响一个 x。决策边界是一条直线
逻辑回归:自变量是 X, 因变量是 y, 只不过这里的 y 变成了概率。 关系:
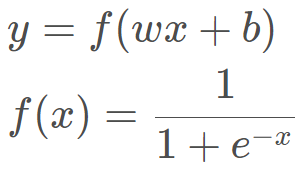
图像也是一条直线。 是分析自变量 x 与因变量 y(概率)之间的关系。 这里注意不要只看到那个 sigmoid 函数就感觉逻辑回归是非线性的。因为这个 sigmoid 函数在这里只是为了更好的描述分类置信度。 如果我们不用这个函数,其实也是可以进行二分类的,比如 wx+b>0, 我们判定为 1, wx+b<0, 我们判定类别 0, 这样其实也是可以的,就会发现,依然是一个 w 只影响一个 y, 决策边界是一条直线。所以依然是线性的。 关于线性和非线性模型的区别,这个解释不错:


这样就得到了逻辑回归的那个式子。 那么我们就来看看这个逻辑回归或者对数几率回归了, 我们知道线性回归,使用 w x + b去拟合数值 y, 而对数几率回归就是用 w x + b 去拟合一个几率。
原理说的差不多了,那就实践吧, 训练一个逻辑回归模型,先说一下机器学习模型训练的步骤:
- 数据模块(数据采集,清洗,处理等)
- 建立模型(各种模型的建立)
- 损失函数的选择(根据不同的任务选择不同的损失函数),有了 loss 就可以求取梯度
- 得到梯度之后,我们会选择某种优化方式去进行优化
- 然后迭代训练
后面建立各种模型,都是基于这五大步骤进行, 这个就相当于一个逻辑框架了。
下面就基于上面的五个步骤,看看 Pytorch 是如何建立一个逻辑回归模型,并分类任务的。我们下面一步一步来:
- 数据生成
这里我们使用随机生成的方式,生成 2 类样本(用 0 和 1 表示), 每一类样本 100 个, 每一个样本两个特征。```python “””数据生成””” torch.manual_seed(1)
sample_nums = 100 mean_value = 1.7 bias = 1
n_data = torch.ones(sample_nums, 2)
x0 = torch.normal(mean_valuen_data, 1) + bias
y0 = torch.zeros(sample_nums)
x1 = torch.normal(-mean_valuen_data, 1) + bias
y1 = torch.ones(sample_nums)
train_x = torch.cat([x0, x1], 0) train_y = torch.cat([y0, y1], 0)
2. 建立模型<br />这里我们使用两种方式建立我们的逻辑回归模型,一种是 Pytorch 的 sequential 方式,这种方式就是简单,易懂,就类似于搭积木一样,一层一层往上搭。 另一种方式是继承 nn.Module 这个类搭建模型,这种方式非常灵活,能够搭建各种复杂的网络。
“””建立模型”””
class LR(torch.nn.Module):
def init(self):
super(LR, self).init()
self.features = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):x = self.features(x)x = self.sigmoid(x)return x
lr_net = LR()
<br />另外一种方式,Sequential 的方法:
lr_net = torch.nn.Sequential( torch.nn.Linear(2, 1), torch.nn.Sigmoid() )
3. 选择损失函数<br />关于损失函数的详细介绍,后面会专门整理一篇, 这里我们使用二进制交叉熵损失
“””选择损失函数””” loss_fn = torch.nn.BCELoss()
4. 选择优化器<br />优化器的知识,后面也是单独会有一篇文章,这里我们就用比较常用的 SGD 优化器。关于这些参数,这里不懂没有问题,后面会单独的讲, 这也就是为啥要系统学习一遍 Pytorch 的原因, 就比如这个优化器,我们虽然知道这里用了 SGD,但是我们可能并不知道还有哪些常用的优化器,这些优化器通常用在什么情况下。
“””选择优化器””” lr = 0.01 optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
5. 迭代训练模型<br />这里就是我们的迭代训练过程了, 基本上也比较简单,在一个循环中反复训练,先前向传播,然后计算梯度,然后反向传播, 更新参数,梯度清零。
“””模型训练””” for iteration in range(1000):
y_pred = lr_net(train_x)loss = loss_fn(y_pred.squeeze(), train_y)loss.backward()optimizer.step()optimizer.zero_grad()if iteration % 20 == 0:mask = y_pred.ge(0.5).float().squeeze()correct = (mask == train_y).sum()acc = correct.item() / train_y.size(0)plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0')plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1')w0, w1 = lr_net.features.weight[0]w0, w1 = float(w0.item()), float(w1.item())plot_b = float(lr_net.features.bias[0].item())plot_x = np.arange(-6, 6, 0.1)plot_y = (-w0 * plot_x - plot_b) / w1plt.xlim(-5, 7)plt.ylim(-7, 7)plt.plot(plot_x, plot_y)plt.text(-5, 5, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))plt.legend()plt.show()plt.pause(0.5)if acc > 0.99:break
```
别看这么多,后面都是绘图的过程,不是重点,重点训练就是前面的那几步。 我们可以看看结果: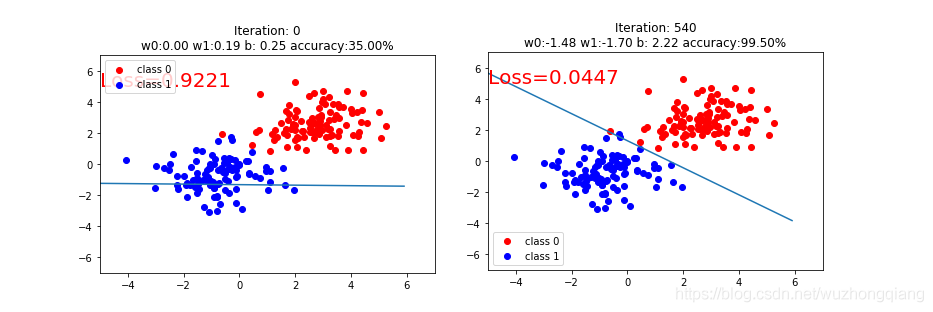
这就是我们的逻辑回归模型进行二分类的问题了。
5. 总结梳理
今天的学习内容结束,下面依然是快速的总结一下,首先基于前面的张量的知识我们又更进一步,学习了计算图的机制,计算图说白了就是描述运算过程的图, 有了这个图梯度求导的时候非常方便。 然后学习了 Pytorch 的动态图机制,区分了一下动态图和静态图。 然后学习了 Pytorch 的自动求导机制,认识了两个比较常用的函数 torch.autograd.backward() 和 torch.autograd.grad() 函数, 关于自动求导要记得三个注意事项: 梯度手动清零,叶子节点不能原位操作,依赖于叶子节点的节点默认是求梯度。 最后我们根据上面的所学知识建立了一个逻辑回归模型实现了一个二分类的任务, 下面依然是一张导图把这次学习的知识拎起来: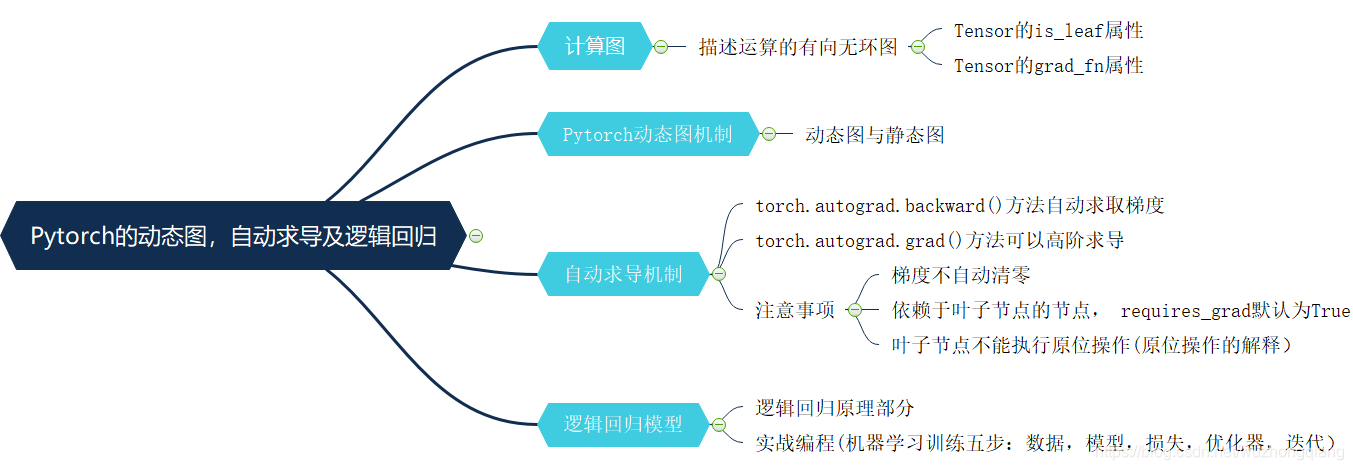
Ok, 后面我们就学习 Pytorch 的数据读取机制 DataLoader 和 Dataset 了, Rush 😉
https://blog.csdn.net/wuzhongqiang/article/details/105471435

若有收获,就点个赞吧
0 人点赞
