优化与估计
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
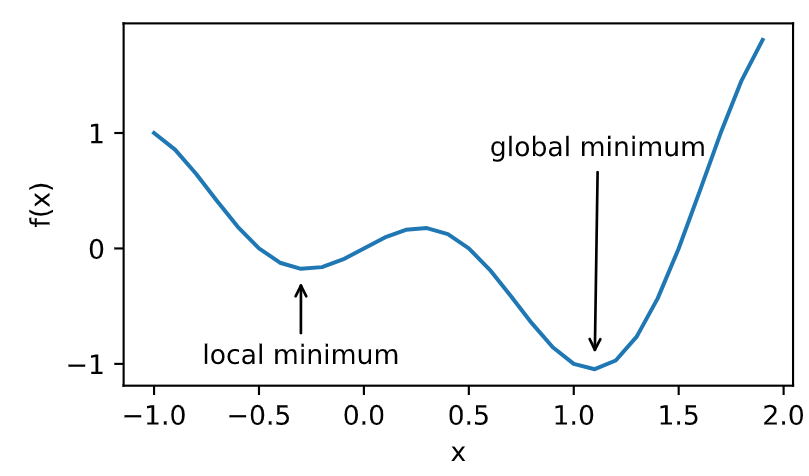
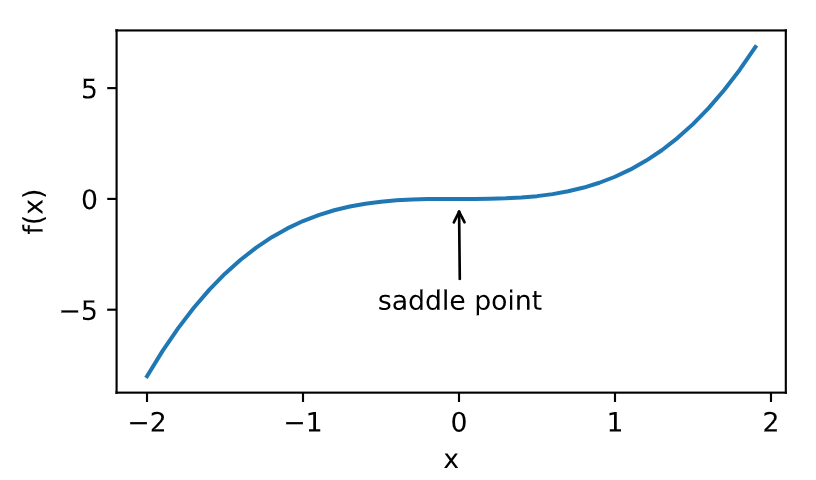
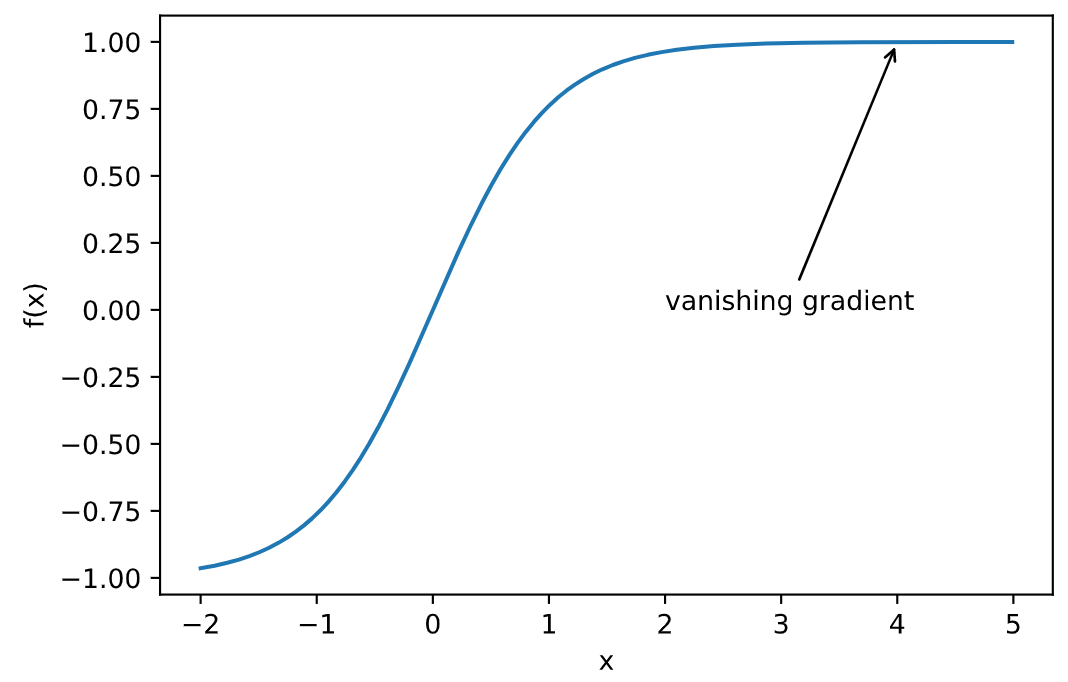
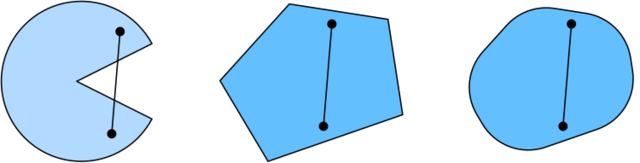
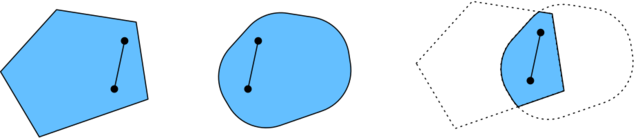
函数
λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
- 无局部极小值
- 与凸集的关系
- 二阶条件
无局部最小值
证明:假设存在 x∈X 是局部最小值,则存在全局最小值 x′∈X, 使得 f(x)>f(x′), 则对 λ∈(0,1]:
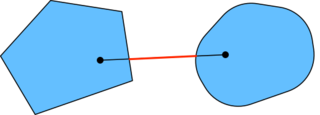
f(x)>λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)与凸集的关系
对于凸函数 f(x),定义集合 Sb:={x|x∈X and f(x)≤b},则集合 Sb 为凸集
证明:对于点 x,x′∈Sb, 有 f(λx+(1−λ)x′)≤λf(x)+(1−λ)f(x′)≤b, 故 λx+(1−λ)x′∈Sb凸函数与二阶导数
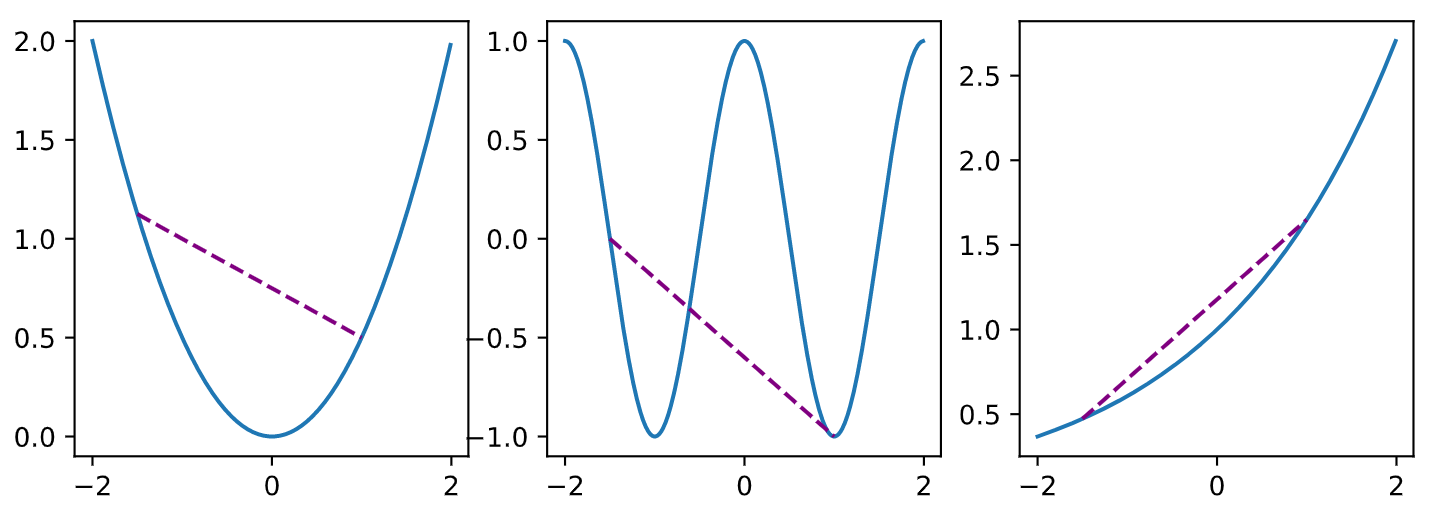
f″(x)≥0⟺f(x) 是凸函数
必要性 (⇐):
对于凸函数:
12f(x+ϵ)+12f(x−ϵ)≥f(x+ϵ2+x−ϵ2)=f(x)
故:
f′′(x)=limε→0f(x+ϵ)−f(x)ϵ−f(x)−f(x−ϵ)ϵϵ
f′′(x)=limε→0f(x+ϵ)+f(x−ϵ)−2f(x)ϵ2≥0
充分性 (⇒):
令 a
根据单调性,有 f′(β)≥f′(α), 故:
f(b)−f(a)=f(b)−f(x)+f(x)−f(a)=(b−x)f′(β)+(x−a)f′(α)≥(b−a)f′(α)限制条件

拉格朗日乘子法
Boyd & Vandenberghe, 2004
L(x,α)=f(x)+∑iαici(x) where αi≥0惩罚项
欲使 ci(x)≤0, 将项 αici(x) 加入目标函数,如多层感知机章节中的 λ2||w||2


若有收获,就点个赞吧
0 人点赞
