例一:
import java.util.regex.Matcher;import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String a = "1631 年,意大利传教士萨鲁布里诺(Agostino Salumbrino)" +"从南美洲秘鲁人那里获得了一种有效治疗热病的药物——金鸡纳树皮(cinchona bark)" +"并将之带回欧洲用于热病治疗,不久人们发现该药对间歇热具有明显的缓解作用。\n" +"1820 年,法国化学家佩尔蒂埃(Pierre Joseph)和药学家卡文托(Joseph Bienaimé Caventou)" +"从金鸡纳树皮分离治疗疟疾的有效成分并将之命名为奎宁(quinine)。";//需求:匹配所有四个连续数字//1. \\d 表示一个任意的数字String str = "\\d\\d\\d\\d";//2. 创建模式对象(即正则表达式对象Pattern pattern = Pattern.compile(str);//3. 创建匹配器//说明:创建正则表达式matcher,按照正则表达式规则,去匹配 a字符串Matcher matcher = pattern.matcher(a);//4. 开始匹配/** matcher.find()完成的任务* 1. 根据指定的规则,定位满足规则的子字符串(比如1631)* 2. 找到后,将子字符串的开始索引记录到matcher对象的属性int[] groups;* groups[0] = 0, 把该子字符串的结束的索引+1的值记录到groups[1] = 4* 3. 同时记录oldLast 的值为 子字符串的结束的索引 索引+1的值即4,即下次执行find时,就从4开始匹配** matcher.group(0)分析* 1. 根据groups[0]和groups[1]的记录位置,从字符串a中截取子字符串返回* 就是[0,4),索引包含0,不包含4*/while(matcher.find()){System.out.println("找到:" + matcher.group(0));}}}

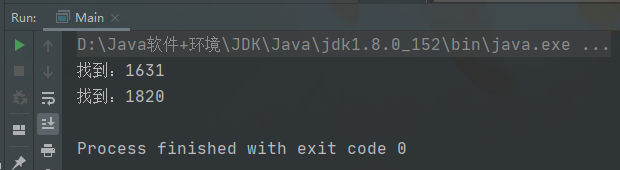
例二:
package test;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Main {public static void main(String[] args) {String a = "1631 年,意大利传教士萨鲁布里诺(Agostino Salumbrino)" +"从南美洲秘鲁人那里获得了一种有效治疗热病的药物——金鸡纳树皮(cinchona bark)" +"并将之带回欧洲用于热病治疗,不久人们发现该药对间歇热具有明显的缓解作用。\n" +"1820 年,法国化学家佩尔蒂埃(Pierre Joseph)和药学家卡文托(Joseph Bienaimé Caventou)" +"从金鸡纳树皮分离治疗疟疾的有效成分并将之命名为奎宁(quinine)。";//需求:匹配所有四个连续数字//1. \\d 表示一个任意的数字String str = "(\\d\\d)(\\d\\d)";//2. 创建模式对象(即正则表达式对象Pattern pattern = Pattern.compile(str);//3. 创建匹配器//说明:创建正则表达式matcher,按照正则表达式规则,去匹配 a字符串Matcher matcher = pattern.matcher(a);//4. 开始匹配/** matcher.find()完成的任务(考虑分组)* 什么是分组,比如:(\d\d)(\d\d),正则表达式中有()表示分组,第一个()表示第1组,第一个()表示第2组* 1. 根据指定的规则,定位满足规则的子字符串(比如(16)(31))* 2. 找到后,将子字符串的开始索引记录到matcher对象的属性int[] groups;* 2.1 groups[0] = 0, 把该子字符串的结束的索引+1的值记录到groups[1] = 4* 2.2 把第1组()匹配到的字符串 groups[2] = 0,groups[3] = 1 + 1 = 2* 2.3 把第2组()匹配到的字符串 groups[4] = 2,groups[5] = 3 + 1 = 4* 2.4 如果有更多的分组,依次类推…………* 3. 同时记录oldLast 的值为 子字符串的结束的索引 索引+1的值即4,即下次执行find时,就从4开始匹配** matcher.group(0)分析* 1. 根据groups[0]和groups[1]的记录位置,从字符串a中截取子字符串返回* 就是[0,4),索引包含0,不包含4*/while(matcher.find()){System.out.println("找到:" + matcher.group(0));System.out.println("第一组()匹配到的值=" + matcher.group(1));System.out.println("第二组()匹配到的值=" + matcher.group(2));}}}
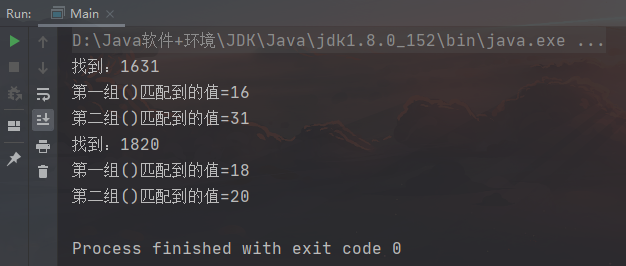
小结:
- 如果正则表达式有() 即分组
- 取出匹配的字符串的规则如下:
- group(0) 表示匹配的子字符串
- group(1) 表示匹配的子字符串的第一组子串
- group(2) 表示匹配的子字符串的第二组子串
- …………但是分组的数不能越界

若有收获,就点个赞吧
0 人点赞
