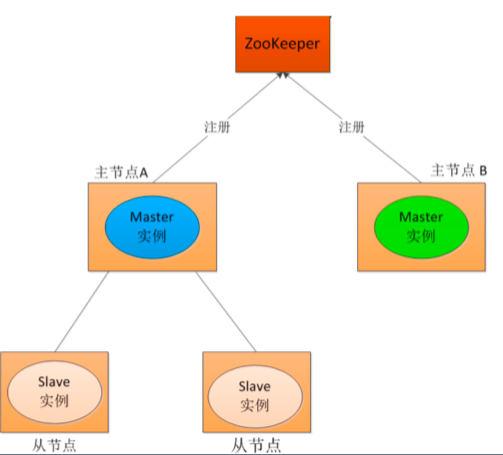
分布式系统脑裂
在一个分布式系统中,不同服务器获得了互相冲突的数据信息或者执行指令,导致整个集群陷入混乱,数据损坏,称作分布式系统脑裂。
数据库主主备份
zooKeeper 保证多台服务器数据存储的一致性。
zooKeeper 作为管理中心,对故障服务器做仲裁。
分布式一致性算法 Paxos
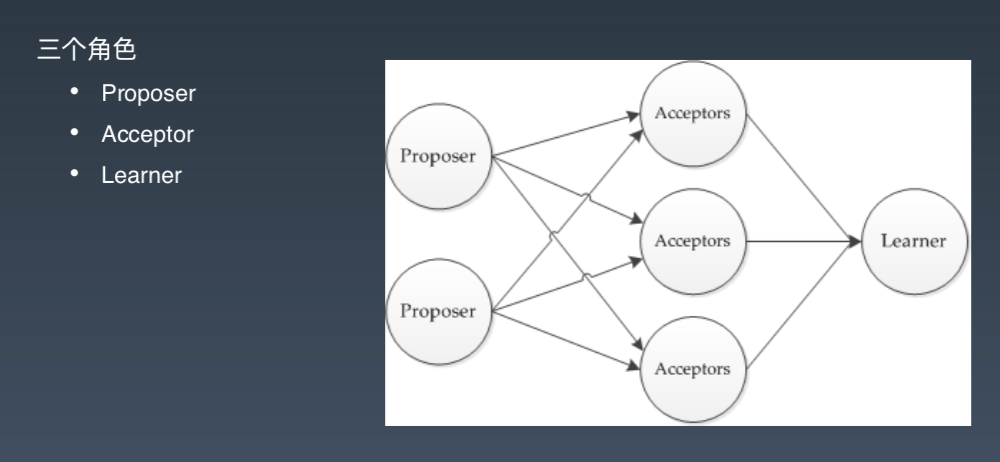
三个角色
- Proposer:提交提案。
- Acceptor:接受提案。
- Learner:Acceptor 超过半数,Learner 就会接受这个提案。
三个阶段
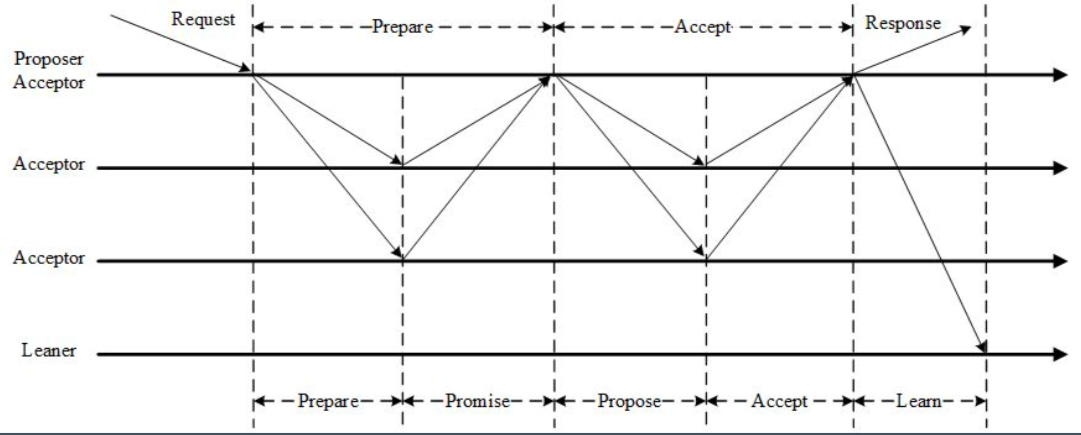
- 第一阶段:Prepare 阶段。Proposer 向 Acceptors 发出 Prepare 请求,Acceptors 针对收到的 Prepare 请求进行 Promise 承诺。
- 第二阶段:Accept 阶段。Proposer 收到多数 Acceptors 承诺的 Promise 后,向 Acceptors 发出 Propose 请求,Acceptors 针对收到的 Propose 请求进行 Accept 处理。
- 第三阶段:Learn 阶段。Proposer 在收到多数 Acceptors 的 Accept 之后,标志着本次 Accept 成功,决议形成,将形成的决议发送给所有 Learners。
唯一性
Proposer 生成全局唯一且递增的 Proposal ID(可使用时间戳加 ServerID),向所有 Acceptors 发送 Prepare 请求,这里无需携带提案内容,只携带 Proposal ID 即可。
Acceptors 收到 Prepare 和 Propose 请求后
- 不再接受 Proposal ID 小于等于当前请求的 Prepare 请求。
- 不再接受 Proposal ID 小于当前请求的 Propose 请求。
ZooKeeper 架构
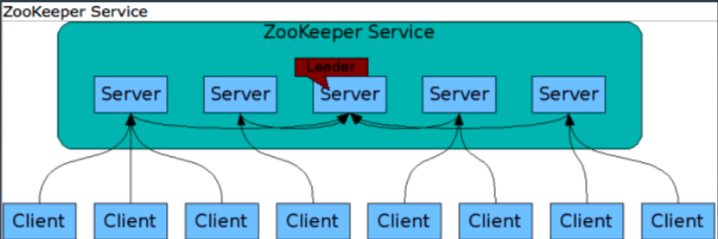
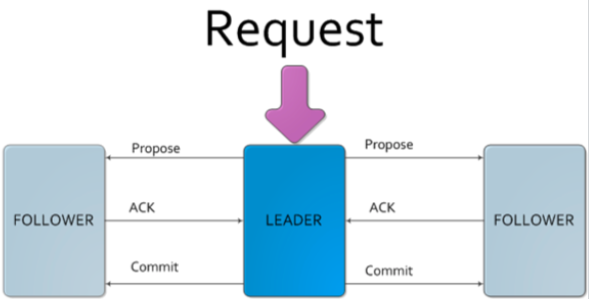
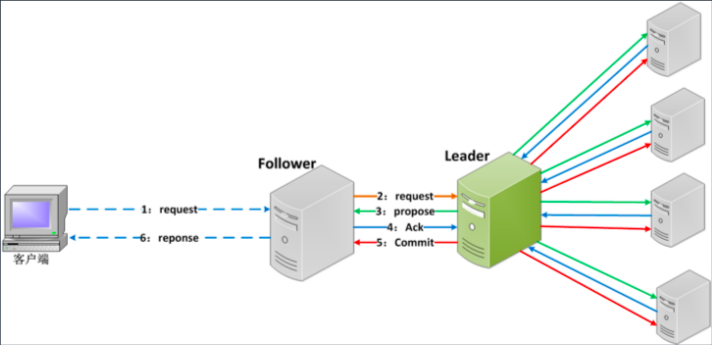
Zab 协议
客户端发起请求,会走到 leader。leader 向 follower 发起 Propose,如果返回 ack,说明状态正常。
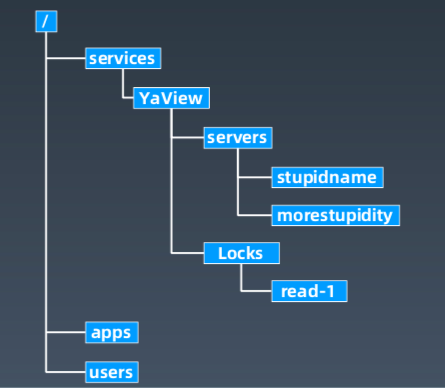
Zookeeper 的树状记录结构
Zookeeper API
String create(path, data, acl, flags)void delete(path, expectedVersion)Stat setData(path, data, expectedVersion)(data, Stat) getData(path, watch)Stat exists(path, watch)String[] getChildren(path, watch)void sync(path)List multi(ops)
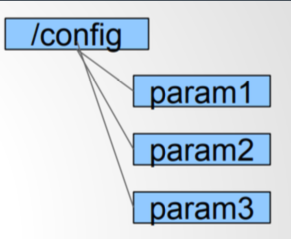
配置管理
Administrator
• setData(“/config/param1”, “value”,-1)
Consumer
• getData(“/config/param1”, true)
选 master
- getdata(“/servers/leader”, true)
- if successful follow the leader described in the data and exit
- create(“/servers/leader”, hostname, EPHEMERAL)
- if successful lead and exit
- goto step 1
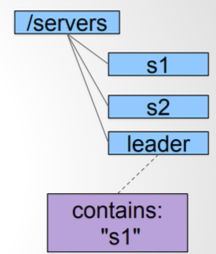
选 master(Python)

集群管理(负载均衡与失效转移)
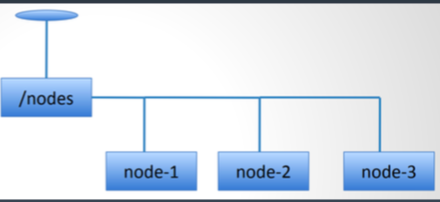
Monitoring process:
- Watch on /nodes
- On watch trigger do getChildren(/nodes, true) 3. Track which nodes have gone away
Each Node:
- Create /nodes/node-${i} as ephemeral nodes
- Keep updating /nodes/node-${i} periodically for node status changes (status updates could be load/iostat/cpu/others)
Zookeeper 性能
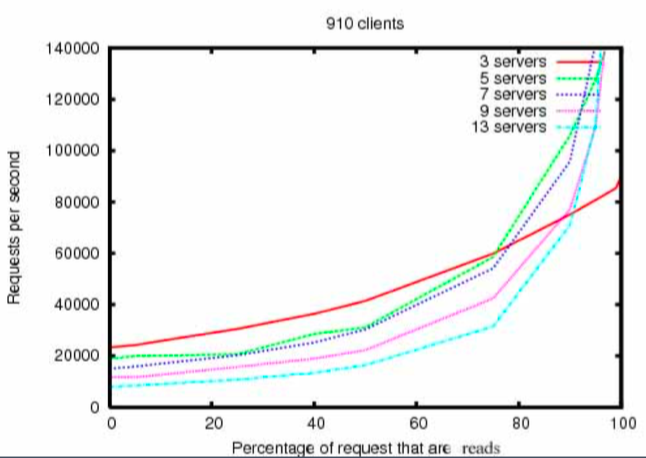
- 读比写的吞吐能力更强;
- 3 servers 比 13 server 初期吞吐量更低。

若有收获,就点个赞吧
0 人点赞
