作者:慕课网
链接:https://www.zhihu.com/question/28557115/answer/584744188
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
数一数年限,据我接触REST到现在也差不多有8年左右了。可能大家现在对从JavaScript客户端直接访问服务器API这种模式非常的习以为常,但在8年前,Web并不是现在这个样子的。所以,要说REST,我们先来看看在REST流行之前Web客户端是如何访问服务器接口的。
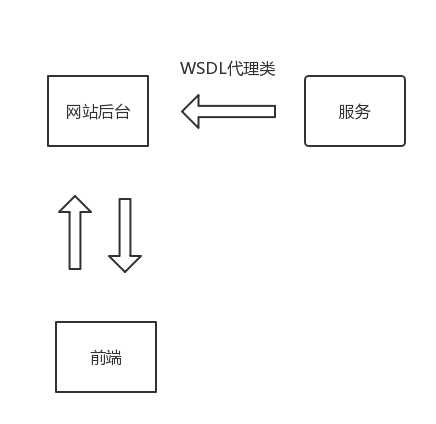
早期在移动端没有流行之前,Web API的概念还非常的弱,当时是网站盛行的年代,基本遵循着后台-前端的模型。后台产生数据,然后通过“模板”的形式将数据绑定到前端HTML代码里(渲染)。如下图所示:
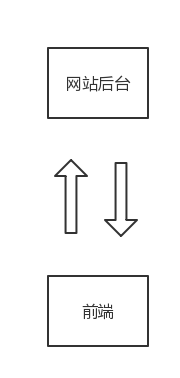
那么这里就有一个“域”的概念,JavaScript只能访问同一个域的服务器。比如我们将一个站点部署在A这个域名http://www.a.com下,那么这个站点的前端JavaScript只能访问域名为http://www.a.com的服务端。如果我们需要访问非A站点的其他“服务”怎么办?看看下图:
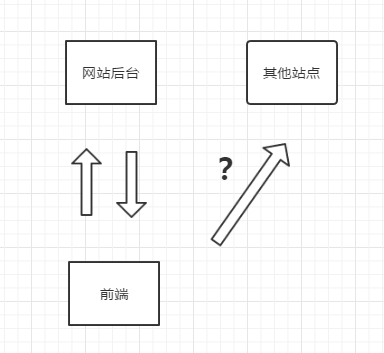
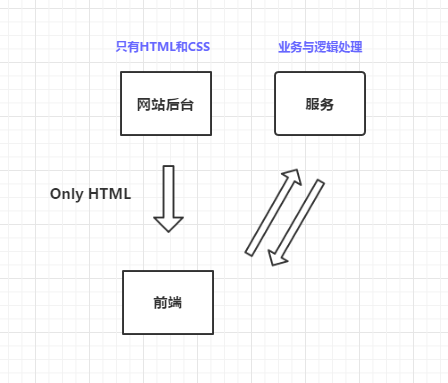
在当时通用的做法是使用SOAP,Simple Object Access Protocol,简单对象协议,它使用XML作为数据的描述。我们看看使用SOAP的解决方案:
JavaScript是不能直接访问SOAP服务的,需要首先访问自己的网站后台,再有网站后台访问SOAP服务。而且不同语言的网站后台,方位SOAP服务都需要有首先生成自己特定语言的“代理类”,Java有Java的、C#有C#的,这相当的繁琐与不好理解。这个时候我们的思考点来了,网站的后台对我来说意义是什么? 我为什么不能直接访问服务?为什么我不能把网站里的业务代码也提取成服务,最后变成以下的理想情况:
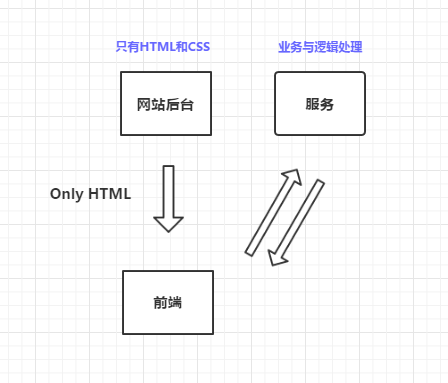
网站的后台几乎是个“壳子”,只负责网站本身的HTML页面、CSS、JavaScript文件等静态页面。而业务逻辑,交给服务来提供就好了。这样做的最大的好处是,业务变得独立了,可以被多个“网站”来共享访问了。有没有觉得挺熟悉?这个模式就是现在VUE、AngularJS等框架做的单页面应用程序。但是,在当时这种模式并不流行。我在很多年前就尝试这样的思维来构建Web,但是由于没有现在VUE、AngularJS等强大的SPA框架支持,效果并不好。但,我相信这种简洁的模式是Web的未来。我一向崇尚简洁,当年丢掉Flex、Silverlight、http://ASP.Net WebForm,独独选择JavaScript就是因为其他几个封装太多。
很多人认为模板引擎就是很好的前后端分离,可我不这么认为,SPA才是真正的前后端分离,他们之间使用AJax通信,前端就是最简单的HTML,前端开发人员一行服务器代码都看不到,这才是真的和语言无关,才是真正的前后端分离。
我来分析下,为什么以前SPA应用并不流行
第一,一个是网站的思维根深蒂固;
第二,就是出于性能考虑,单页面频繁的Ajax请求将给服务器造成巨大的压力。而网站网页的静态化技术已经是非常的成熟的了,所以SPA这个概念在早期并不怎么提倡。而且SPA也有自己的局限性,并不是所有的网站都适合用SPA来代替。但现在服务器缓存技术的发展(特别是Memcache和Redis出现后)大大的解决了服务器支持SPA负载过高的问题,甚至比传统的网页静态化技术更加的简单易用;再加上VUE、AngularJS强大的能力,这才使SPA真正的流行起来。
第三,前端要跨域访问服务器在当时并不是那么容易,没有一个标准的规范来定义跨域,各种旁门左道的跨域都不是那么的好用。
那么我个人认为有两个标致性的事物刷新了人们对于API和服务的理解:一个是移动端的流行,第二个就是REST理念的流行。
移动端我们就不谈了。我们来谈谈REST。我个人认为REST并不是什么技术,而是由于它的流行,让人们逐渐的接受了服务即资源,扩展和打破了开发者对Web的理解。
没有REST的时候,客户端可不可以直接跨域访问服务?可以。但并没有一个标准来引导开发者如何设计出适合服务的API接口。REST的流行,替代了SOAP(某些领域里SOAP还是有一席之地),它足够简单、轻量、语义明确,非常适合移动端盛行的这个年代。
REST:REpresentational State Transfer,中译为“表属性状态传递”。这是什么鬼?这并不重要,本来就个名字就源自于国外的一个博士的一篇论文。我们主要要知道基于这篇论文里的理论,衍生出了RESTFul API的接口设计风格。
我们一起来看看RESTFul API有哪些特点:
- 基于“资源”,数据也好、服务也好,在RESTFul设计里一切都是资源。
- 无状态。一次调用一般就会返回结果,不存在类似于“打开连接-访问数据-关闭连接”这种依赖于上一次调用的情况。
- URL中通常不出现动词,只有名词
- URL语义清晰、明确
- 使用HTTP的GET、POST、DELETE、PUT来表示对于资源的增删改查
- 使用JSON不使用XML
我举个例子:
网站:/get_user?id=3
RESTFul: GET /user/3 (GET是HTTP类型)
有些同学可能会说,GET、POST我也经常用啊。但是在网站里的GET和POST同RESTFul中的GET、POST是不一样的。网站里使用GET、POST的选择点在于,简单的用GET、复杂对象用POST;但在REST里,GET对应的是查询一个资源,而POST对应的是新增一个资源,意义是决然不同的。理解这一点非常重要。
好,我们接着来看一看RESTFul API的一些最佳实践原则:
- 使用HTTP动词表示增删改查资源, GET:查询,POST:新增,PUT:更新,DELETE:删除
- 返回结果必须使用JSON
- HTTP状态码,在REST中都有特定的意义:200,201,202,204,400,401,403,500。比如401表示用户身份认证失败,403表示你验证身份通过了,但这个资源你不能操作。
- 如果出现错误,返回一个错误码。比如我通常是这么定义的:
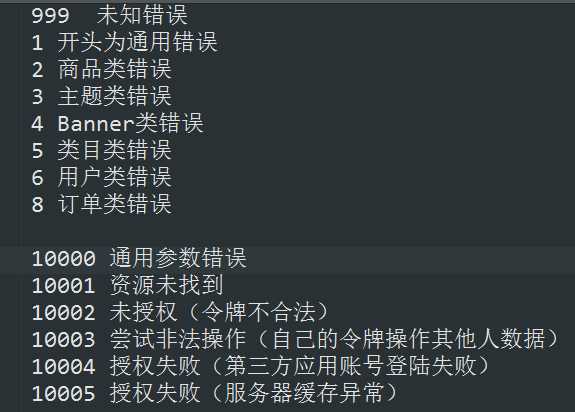
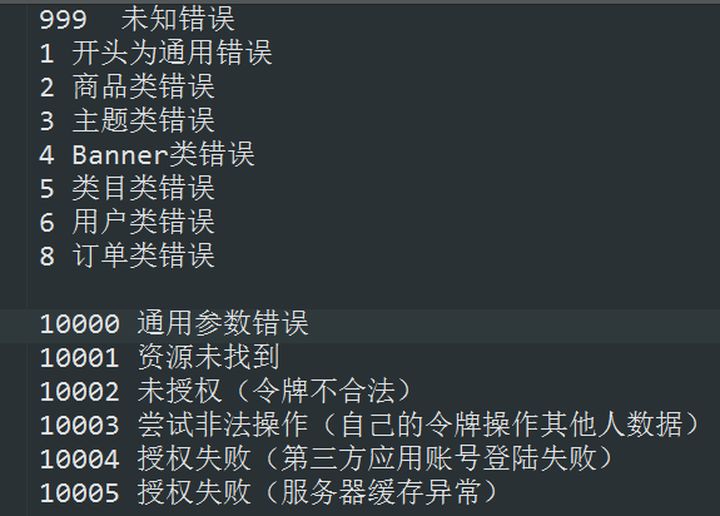
- API必须有版本的概念,v1,v2,v3
- 使用Token令牌来做用户身份的校验与权限分级,而不是Cookie。
- url中大小写不敏感,不要出现大写字母
- 使用 - 而不是使用 _ 做URL路径中字符串连接。
- 有一份漂亮的文档~(很重要)
以上只是列出了RESTFul的部分实践原则,并非全部。 给出一个典型的RESTFul API设计风格:
https://api.z.cn/v1/product/recent?page=3&size=20
以上URL非常容易理解,分页获取最新若干的Product资源。
最后,我们想聊一下,RESTFul API到底好用吗?某些情况好用,某些情况非常不好用。什么情况好用,什么情况不好用呢?
我的一个经验性的总结:对于开放的API,豆瓣、新浪微博、GitHub,好用,非常合适;对于内部开发,不好用。
基于资源型的RESTFul API 接口粒度和返回结果过于的“粗”,它通常返回的都是完整的数据模型,这对于客户端非常不友好。但开放API之所以开放,就是因为它不知道你到底需要什么返回结果,既然不知道,那么我干脆都返回给你。这样的好处是通用,但客户端不好处理。你只需要一个字段,服务器啪的丢给你十几个,作为客户端开发者你怎么想?
内部开发由于需求非常明确,通常来说服务器是不应该简单粗暴的直接甩资源实体给客户端的。那RESTFul API就不能接入到内部开发吗?当然不是,我们需要灵活一些借鉴RESTFul中的优点,来设计我们的内部API。那么如何简化,这就不是一篇文章能够说清楚的了,也没有一个统一的标准,需要自己去琢磨和体会。
最后举个例子吧,我个人在开发内部接口时会保留绝大多数的REST 特性,但我不会严格的只写增、删、改、查四个接口。必要的时候,还是要灵活处理一下。而且错误码、状态码这些非常优秀的特性,必须保留。
好了,关于RESTFul我们就介绍到这里。特别强调,接口设计是一个非常依赖于经验和重构的技术活儿,设计接口需要有一些艺术家的天赋(真实体会),你看GitHub的接口就非常的“美”。不要觉得很简单,真的比写代码还难。难道大家不觉得,有时候起名字真的是一件很难的事儿嘛?

若有收获,就点个赞吧
0 人点赞
