- 什么是 G1 GC
- G1 内存布局
- G1 Young GC
- G1 Remembered Set
- G1 Young GC Phase
- G1 Old GC
- G1 Old GC Phases
- G1 的核心要素
- G1 GC 阶段
- Young Collection
- Marking Initiation
- Concurrent Marking Stages
- 递增压缩(又称 Mixed Collection)
- G1调整注意事项
- Adjusting Each Mixed Collection
- Components of a G1 GC Pause
- Humongous Objects Requirements
- Fragmentation In The G1 Collector
- G1 Mixed GC(Region) Liveness Threshold
- Humongous Objects
- Promotion/Evacuation Failures In The G1 Collector
- Allocation and Promotion Rates
- SATB
- G1 logging
- ">

- 命令行选项最佳实践
- 什么时候用 G1
- 参考
什么是 G1 GC
- G1 是 HotSpot 低延迟的收集器。
- 第一次论文发表可以追溯到 2004 年
- 从 JDK 7u4 (2012年4月)开始使用并支持
- 是 CMS 的长期替代品。
- 在 JDK 9 中成为默认的 GC
- JEP 248:http://openjdk.java.net/jeps/248
- 低延迟的价值超过了高吞吐。
- 主要用于 Java 应用。
- 另外 ParallelGC 仍然可用。
- G1 非常容易调节。
- 只需设置两个参数:java -Xmx32G -XX:MaxGCPauseMillis=100
- 调节 最大的 STW 暂停时间
- XX:MaxGCPauseMillis=<>
- 默认 200ms
- G1是分代收集器。
- G1 实现两类 GC 算法。
- 年轻代 GC
- Stop The World,Parallel,Copying
- 老年代 GC
- 并发标记
- 增量压缩
- 年轻代 GC
G1 GC 是 Garbage-First Garbage Collector 的缩写,它是给 Java 虚拟机用的垃圾收集器,通过 -XX:+UseG1GC 参数来启用。在 JDK 7u4 版本中正式推出。
据官网介绍,G1 是一种服务的垃圾收集器,应用在多处理器和大容量内存环境中。在实现高吞吐量的通俗,尽可能满足垃圾收集暂停时间的要求。
它是专门针对以下应用场景设计的:
- 像 CMS 收集器一样,能与应用线程并发执行。
- 整理空闲空间更快。
- 需要 GC 停顿时间更好预测。
- 不希望牺牲大量的吞吐性能。
- 不需要更大的 Java Heap。
G1 收集器的设计目标是取代 CMS 收集器,和 CMS 相比,G1 是一个有整理内存过程的垃圾收集器,不会产生很多碎片。G1 的 Stop The World(STW)更可控,G1 在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
以下介绍 G1 相关的技术,方便我们真实的项目中能够使用的游刃有余。
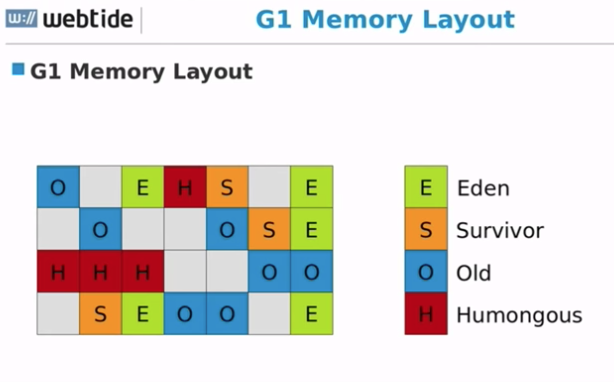
G1 内存布局
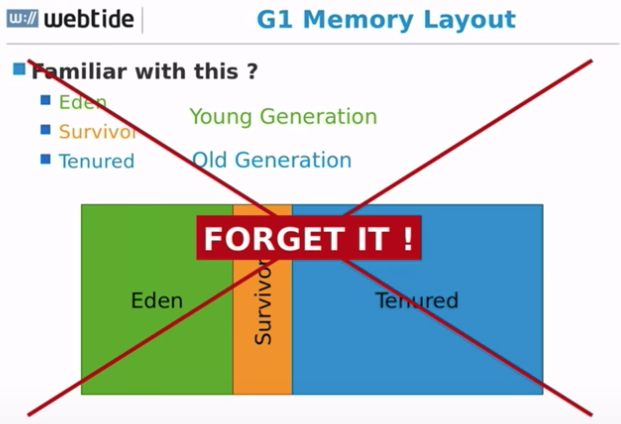
- G1 把 Heap 划分为非常小的 Regions
- 目标要有 2028 个 Regions,可通过 -XX:G1HeapReginSize=<>来设置
- 所以 Heap 大的话,Region 就大。
- 分为 Eden,Survivor,Old Regions。
- Humongous Regions
- 单个对象的大小 > 这个 Region 的 50%
- 通常是 byte[] 或者 char[]
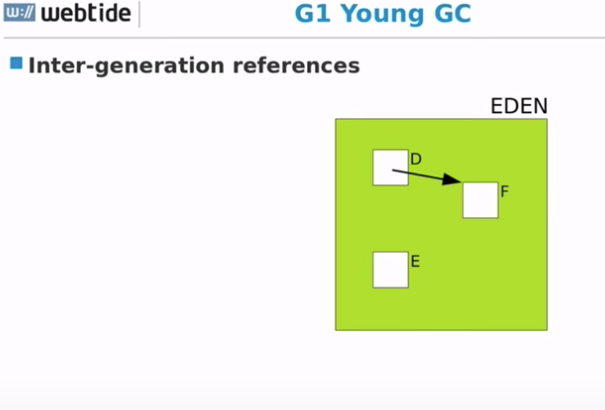
G1 Young GC
- JVM 启动,G1 准备好 Eden Regions。
- 应用程序运行,然后把对象分配到 Eden Regions。
- Eden Regions 不断的填充对象。
- 当所有的 Eden Regions 满的时候,触发 Young GC。
分配不是应用程序所做的唯一一件事,它还做另一件事
- 应用程序不只是分配内存。
- 应用程序会修改已存在对象的引用。
- 一个 Old 对象可能会引用一个 Eden 对象。比如 一个 Old Map 刚刚 put() 进一个新的 entry。
- G1 必须跟踪这些代与代之间的引用。比如(Old | Humongous)->(Eden| Survivor) pointers
代与代之间的引用
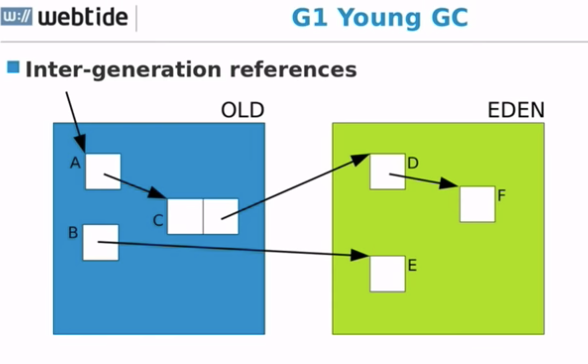
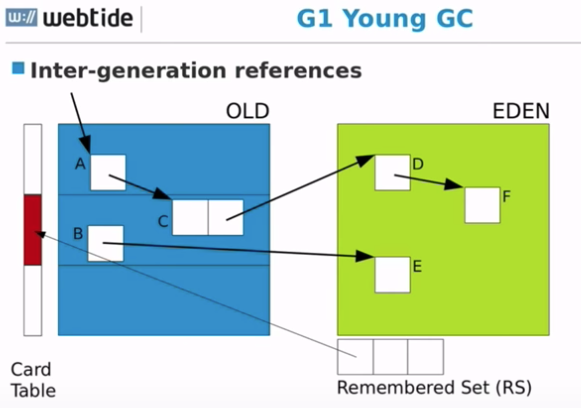
每个 Region 都有一个 Rset,记录了哪些 Region 的哪些对象引用了本 Region 的对象。
Card Table 是个数据结构,它说明的特定 Region 前一个的确切位置
追踪代与代之间的引用需要 G1 Remembered Set
G1 Remembered Set
队列是更便宜的数据结构。G1 Thread,
Write barrier
write barrier 直译的话是「写屏障」,不太好理解。它本质上是一小段代码,JVM 注入到我们写的代码中,每次我们写一个赋值操作,比如object.filed =
- 这些操作记录会保存在card中
- card保存在队列中(dirty card queue)这个跟card table应该不是一回事。这就相当于一个标记说,这块区域dirty了。
- 队列分为4个区域,白,绿,黄,红。
写操作越来越多,这个队列就越来越长。
- 写操作排队到白色区域,nothing happens
- 写操作继续增长,排队到绿色区域,g1 启动refinement 线程,这个线程会说,我知道这块区域被修改了,我需要更新Remember Set(为什么不立即更新Remember Set而要搞这么复杂?因为如果每次都更新Remember Set,会比较消耗资源,而且如果好多线程都想去写这个Remember Set,可能还会有竞争的问题。g1的做法是用队列保存这些操作,g1 是唯一一个写这个数据结构的)
- 到黄色区域,refinement线程增多
- 到红色区域,g1就不再让排队了,而是让 Application 来帮忙,让 Application 运行另一段代码,这样Application 运行慢了,写队列也变慢了,g1 就能 catch up (赶上)消费这个队列甚至排空队列,这样就能更新 RSet。
总结一下:
- a write barrier tracks pointer updates
- object.field =
- 每次指针的触发都会被写入
- 这些操作记录会保存在card中
- 卡片存储在队列中。
- 队列分为4个区域:白色,绿色,黄色和红色。
G1 Young GC Phase
【结构】
- G1 Stop The World
- G1 builds a Collection Set
- 这个是为了保存将要探测的region的。
- 在Young GC,Collection Set 只有Eden region和Survivor region
【阶段】
- 第一阶段:Root Scanning
- 扫描staic和每个线程栈里的local对象(static and local objects)
- 第二阶段:Update RS(更新 RS)
- 清空dirty card queue,更新RS,使得RS里面是最新的状态
- 第三阶段:Process RS(处理 RS)
- 从CollectionSet出发,看里面每一个region的RS,找到指向每个region里的对象,进而找到整个引用的图,探测出哪些是活着的
- 第四阶段:Object Copy(对象拷贝【重要的阶段】)
- 遍历对象相互引用的图
- 拷贝活跃的对象到新的区域,Survivor 或 Old Regions。
- 第五阶段:Reference Processing(引用处理)
- 发现引用的类型 Soft,Weak,Phantom,Final,JNI Week references,对不同的类型做相应的处理。【比如弱引用,可以安排后续的垃圾收集】
- 总是开启 -XX:+ParallelRefProcEnabled【并行应用处理开启】
- 获得更多细节使用 -XX:+PrintReferenceGC【比如 G1 处理了多少个引用】
G1 会跟踪不同阶段的时间,来实现 autotune(自动调节以达到我们期望的暂停时间)
- 比如可以减少要处理的 region 数
- 比如自动减小 eden 区的大小,这样每次回收操作也会变短
G1 Young GC
- E and S regions 疏散到新的 S 和 O regions。
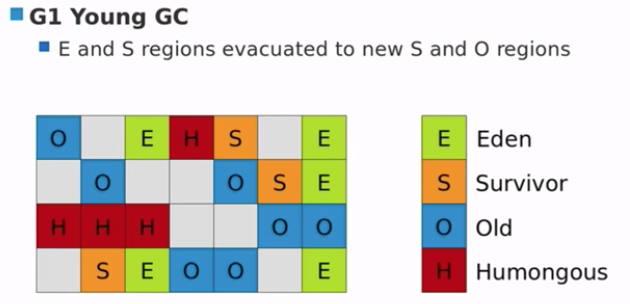
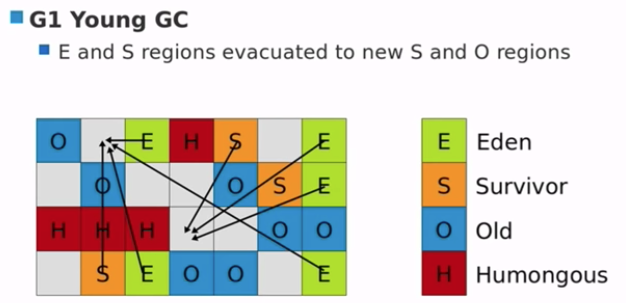
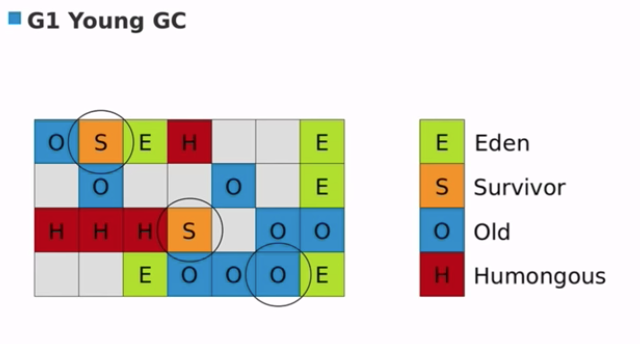
G1 Old GC
- G1 基于 heap 的使用率触发 Old GC
- 默认是 45%
- 通过
-XX:InitiatingHeapOccupancyPercent来调整
- Old GC 包含 old region 标记
- 找到所有在 old regions 的活跃对象
- old region 标记是并发的
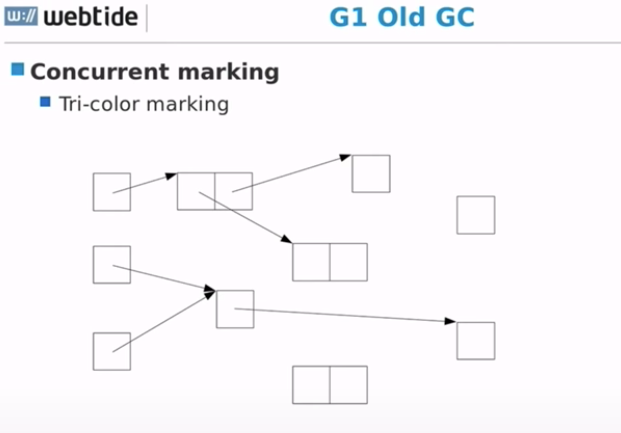
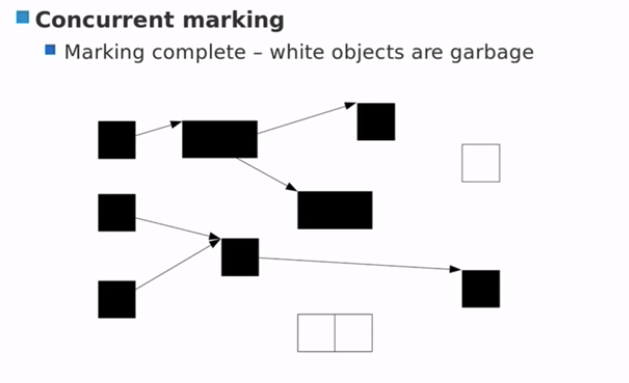
Concurrent marking
Tri-color marking
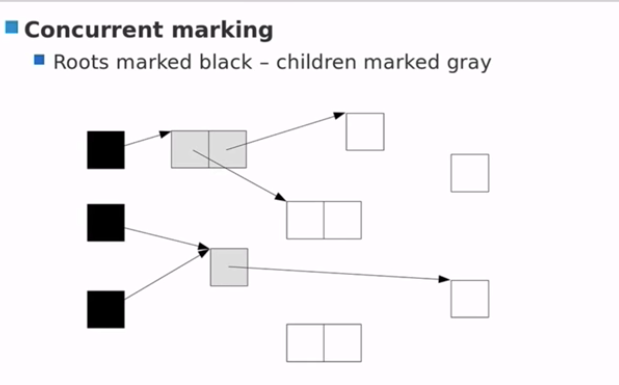
- roots 标记为黑色,children 标记为灰色
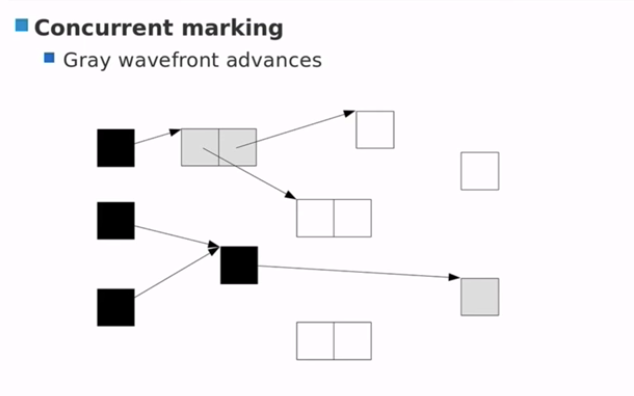
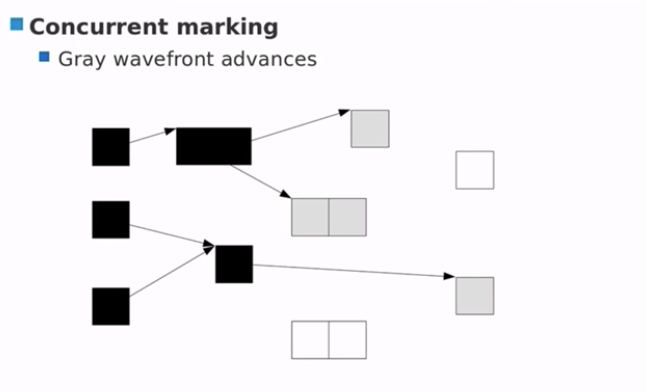
- 标记完成,白色对象成为垃圾
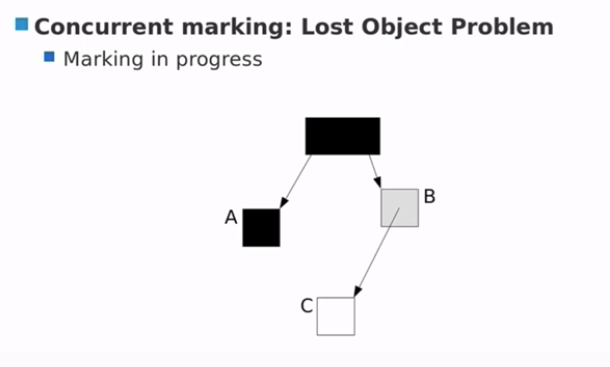
Concurrent marking:Lost Object Problem
【对象丢失问题】
- marking in progress
- Application write: B.c = null;
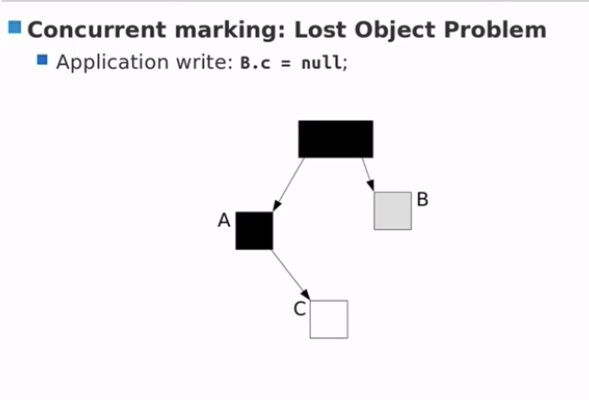
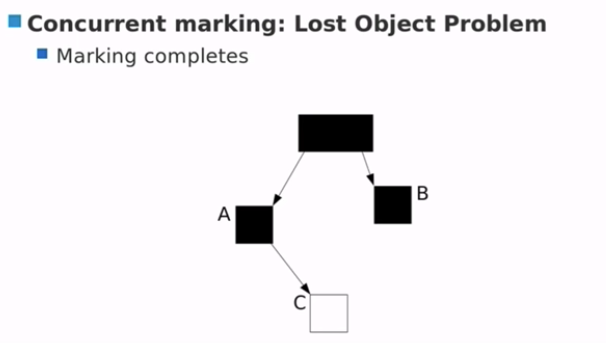
JVM 增加写屏障,检测每次删除指针的时间。
- G1 用写屏障来检测:B.c = null;
- 指明C的指针已经被删除了
- G1 现在对 C 有了了解
- C 依然保持活跃
G1 Old GC Phases
- G1 Stops The World
- Performs a Young GC
- 搭载 old region root 检测(initial-mark)
- G1 恢复应用线程
- 并发 old region 标记处理
- 保持引用追踪
- 计算每个 region 的活跃信息
- G1 Stop The World
- Remark 阶段
- SATB 队列处理
- 引用处理
- Cleanup 阶段
- 空的 old regions 会立刻重新使用
- 应用线程恢复

- Cleanup 阶段—>回收空的 old regions
- 什么是非空的 old regions
- 碎片怎么处理
- 非空的 old region 的处理
- 发生在下一次 Young GC 循环期间
- 不着急的清理 old regions 的垃圾
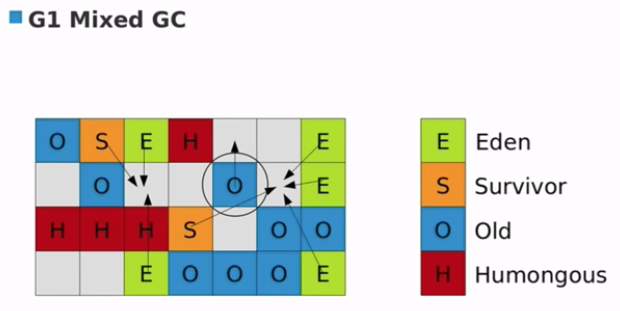
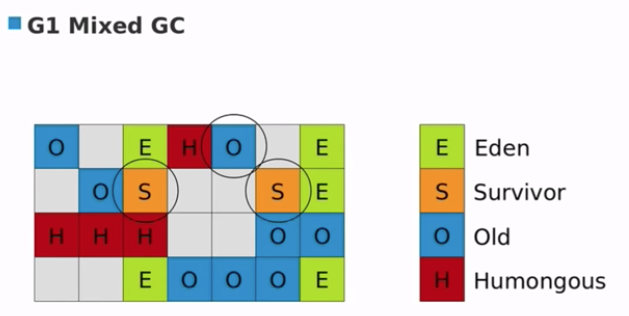
G1 Mixed GC
- Mixed GC —搭载在 Young GC 之上
- 默认 G1 performs 8 mixed GC
- -XX:G1MixedGCCountTarget=8
- collection set 包含:
- Part(1/8) of the remaining Old Regions to collect
- Eden regions
- Survivor Regions
- 算法和 Young GC 一样
- Stop-The-World,Parallel,Coping
- Old Regions 有大多数垃圾的时候回被优先选择
- -XX:G1MixedGCLiveThresholdPercent
- 默认 85%
- G1 会浪费一部分 heap 空间
- -XX:G1HeapWastePercent
- 默认 5%
- Mixed GC 会停止
- 当 old Region 垃圾 <= waste threshold
- mixed gc 个数可能少于 8
G1 通用建议
- 避免 Full GCs
- Full GC 是单线程 并且真的很慢
- 也因为 G1 喜欢 大的 heap
- 为 Full GC 抓取 GC 日志
- -XX:+PrintAdaptiveSizePolicy
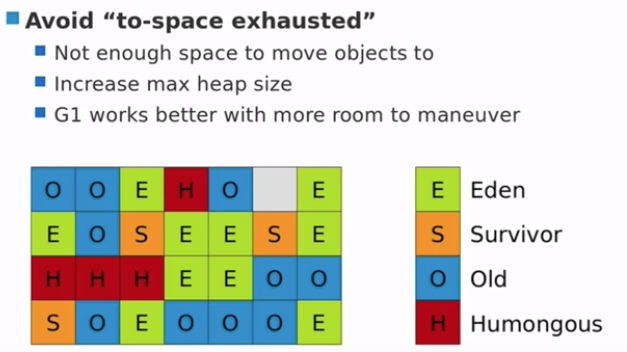
- 避免「to-space exhausted」
- 空间耗尽,不能存放对象
- 需要扩大最大堆大小
- 以腾出空间使G1正常运行
- 避免太多的 Humongous 分配
- -XX:+PrintAdaptiveSizePolicy 打印 GC 原因
- 增大最大堆大小
- 增加 Region 大小:-XX:G1HeapRegionSize
- 举例
- Max heap size 32G ->region size = 16M
- Humongous limit ->8M
- 分配12M数组
- 设置 Region大小到 32M
- HUmongous limit 现在 16M
- 12M 数组不再是 HUmongous
- 避免很长的引用处理
- 始终开启:-XX:+ParallelRefProcEnable
- 更多细节用:-XX:+PrintReferenceGC
- 找到 WeakReferences 的原因
- ThreadLocals
- RMI
- Third party libraries
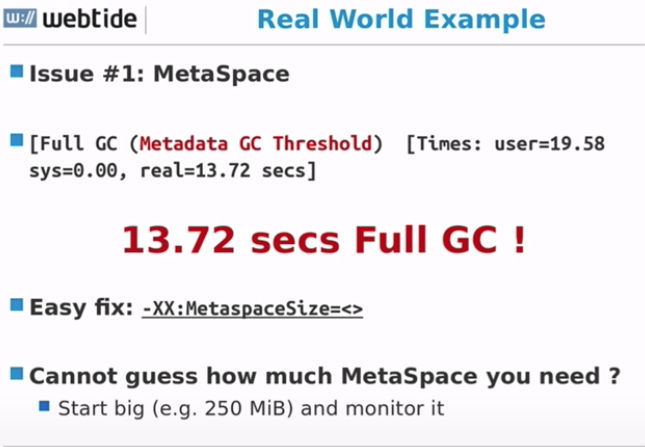
Real World Example
- Online Chess Game Application
- 20k requests/s - Jetty server
- 1 server, 64G RAM,2*16 cores
- Allocation rate: 0.5-1.2 G/s
- CMS to G1 Migration



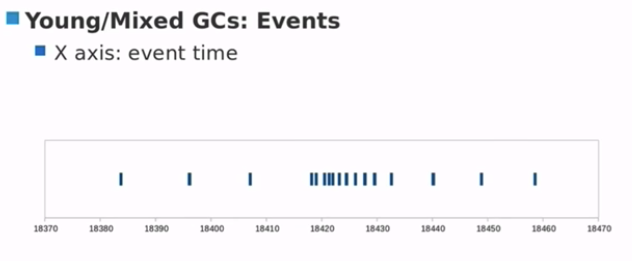
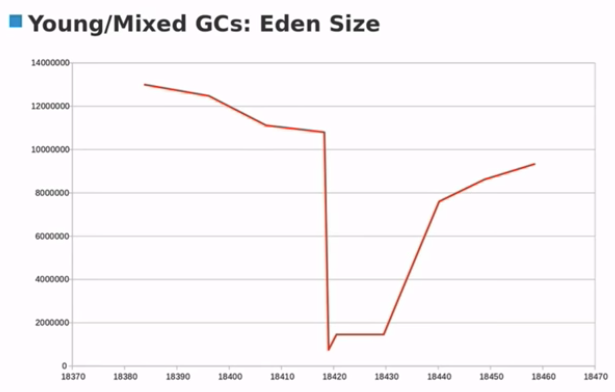
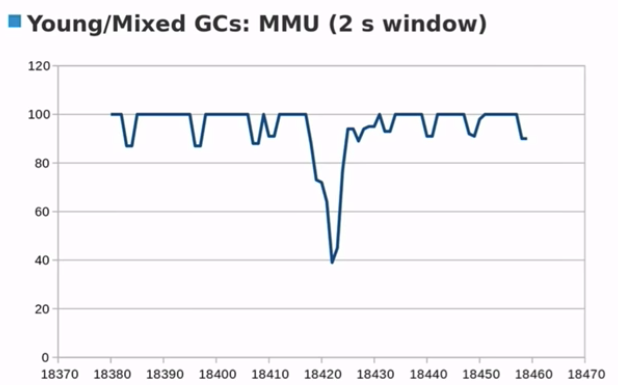
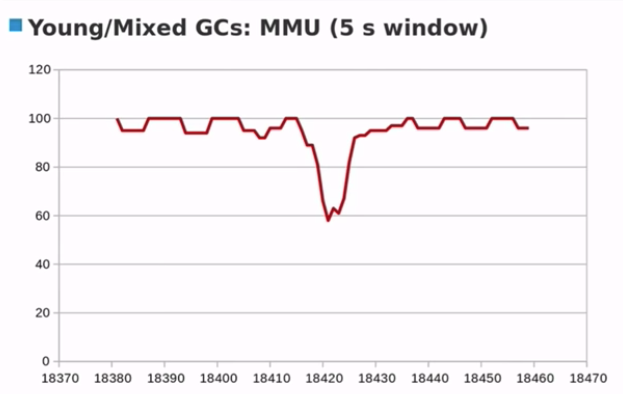
结论
- G1 是未来
- 比 CMS 更容易调整
- 仍然基于 STW 暂停
- 总是使用在最近的 JDK 中。
G1 的核心要素
G1 相比传统的 GC 收集器引入了一些新的要素,这些要素对实现高吞吐、内存碎片管理、控制收集时间等功能起到了关键作用。
Region
传统 GC 收集器将连续内存空间划分为新生代、老年代和永久代(JDK 8 去除了永久代,引入了元空间 Metaspace),通过这种划分,以保证各代的存储地址是连续的。
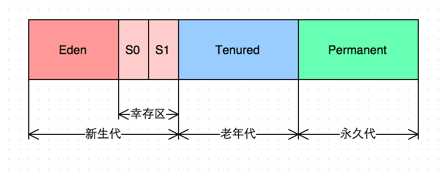
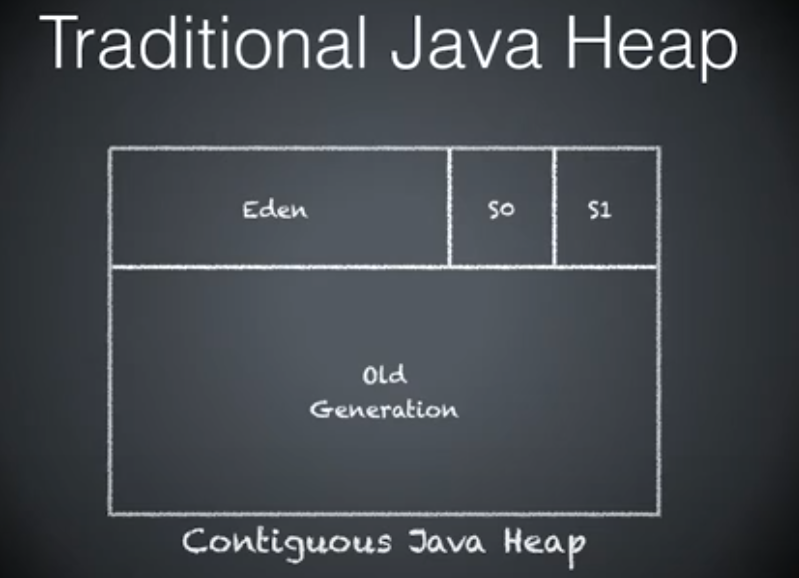
(传统 GC 内存布局)
对于 G1 来说,各代存储地址并没有设计成连续,每一代都使用了 N 个不连续的大小相同的 Region,每个 Region 占有一块连续的虚拟内存地址。
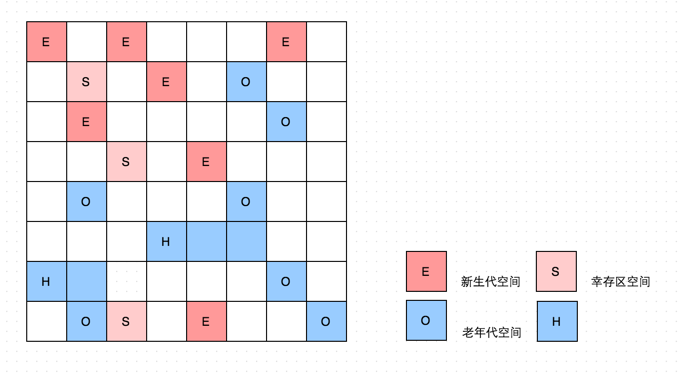

(G1 GC 内存布局)
G1 GC Heap Regions
- Young Regions:这个区包含了 Eden 区和 Survivor 区里面的对象。
- Old Regions:这个区包含 Old generation 里面的对象。
- Humongous Regions:这个区包含了巨大对象。

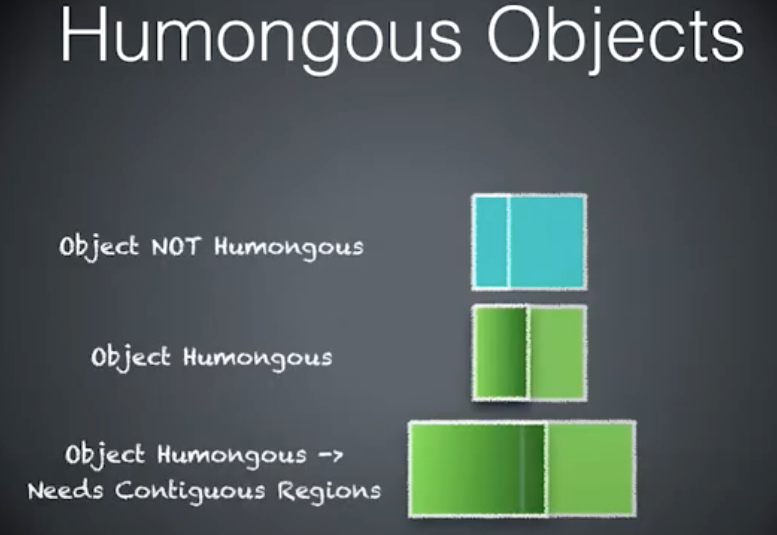
Humongous Objects

年轻代蓝,老年代绿。
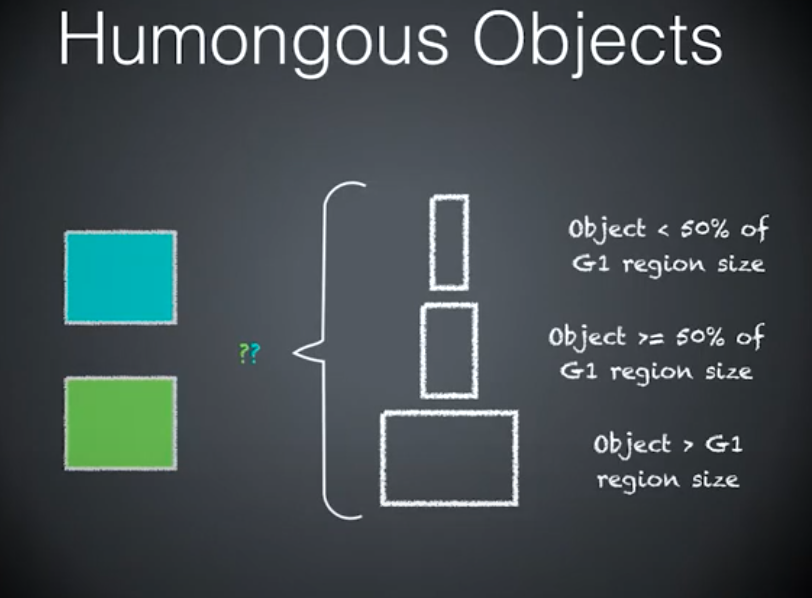
三种情况,如何分配内存。
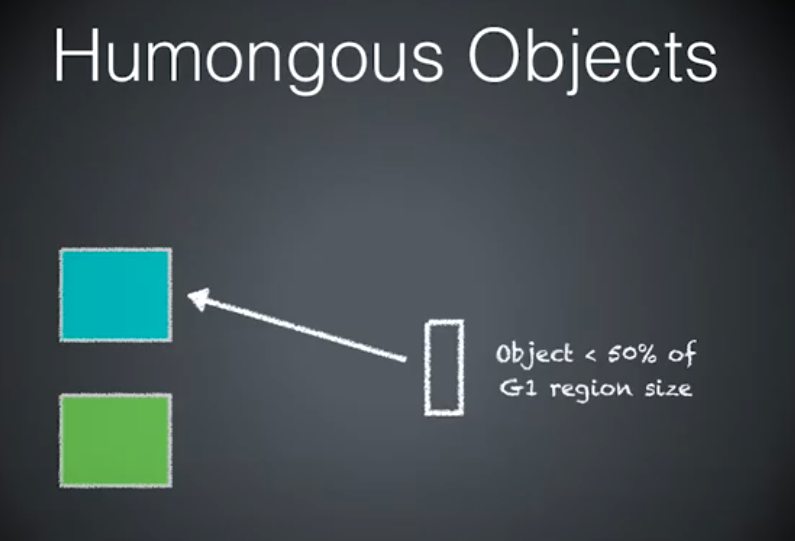
第一种情况的对象小于 Region 大小的一半,分配本地线程缓冲,对象进入 Eden 的普通对象。
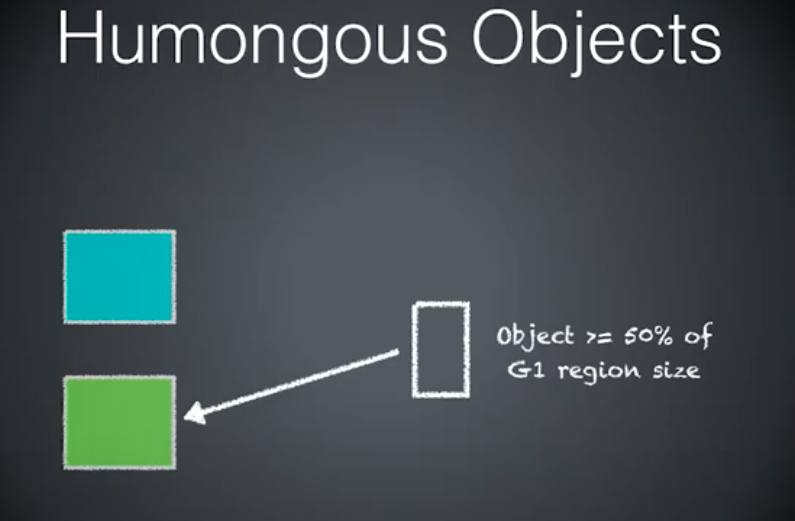
第二种情况的对象大于 Region 大小的一半(算 H-Object),对象分配到老年代。
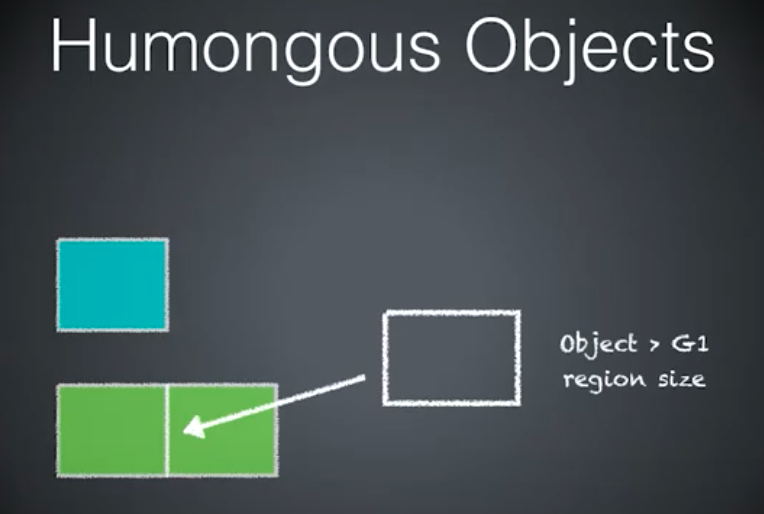
第二种情况的对象大于 Region 大小,一个 Region 不够用,需要分配老年代两块连续的 Region。

- 非巨大对象
- 巨大对象
- 巨大对象—>需要连续的 Region
Collection Set
(CSet)
GC要收集的Region集合。
young collection set包含所有的年轻代 Region。
mixed collection set 包含所有的年轻代 Region 以及一部分后续的老年代 Region,这些 Region 基于大多数垃圾优先的原则。
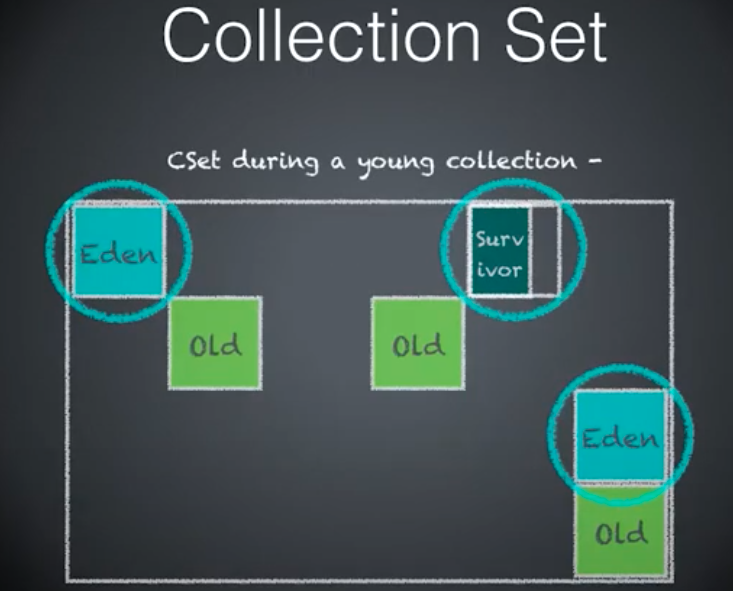
所有年轻代的 Region。
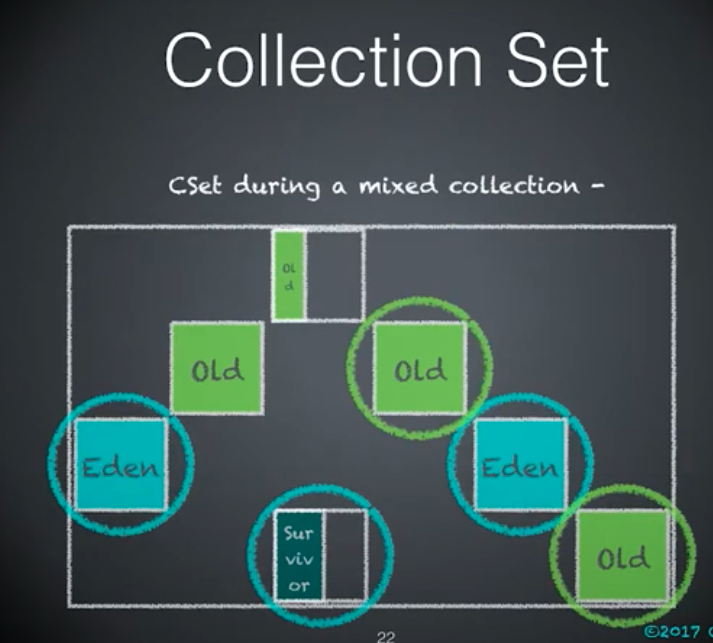
所有的年轻代 Region 以及少量的比较旧的老年代 Region。
Remembered Set

- 维护和追踪正指向 Region 的引用。
- 老年代到年轻代的引用
- 老年代到老年代的引用。
- RSet 基于对象或 Region 的受欢迎程度,有着变化的密度。(某个对象或 Region 被引用越多,RSet 的密度就会增加,可能是性能下降的原因。)
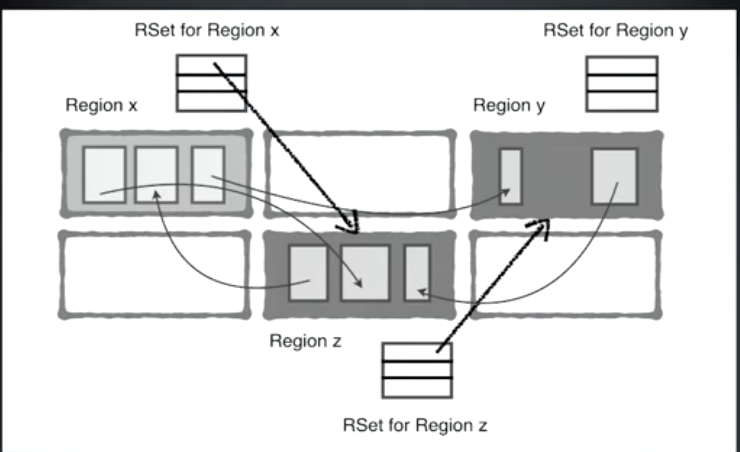
x 是 年轻代 Region,y,z 是 老年代 Region。
- z 有引用 x,所以 x 侧 RSet 存了 z 到 x 的引用。
- y 有引用z,所以 z 侧 RSet 存了 y 到 z 的引用。
G1 GC 阶段
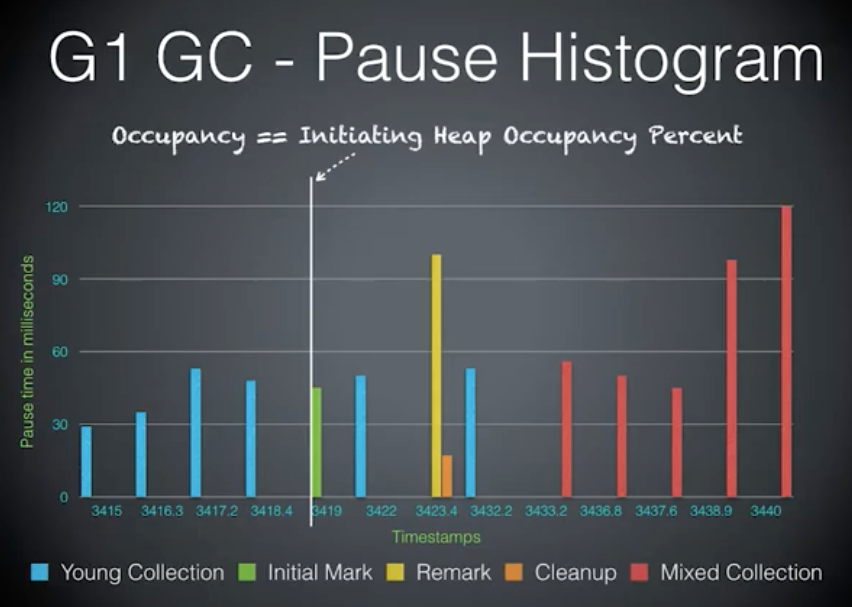
年轻代收集到达一定值后,会触发并发标记:
- `
`
- 并发标记,并不会影响应用线程,没有 stw
并发标记工作完成后,一个新的 年轻代出现,这是一个 stw pause。
并发标记期间有错过的,要重新标记一下,黄色的那部分。
标记之后,有个清理暂停,也是并发的,所以也是一个 stw pause。
然后就只有个一个年轻的集合。根据最有效的集合对旧 Region 进行排序,最不活跃或者最空闲的那些首先进行收集,活跃中的将在后边进行收集。这是我们拥有最后一个 young collection 的原因。
后边会看到 mix collection,5个 mix collection,这个期间在收集候选区域,有不同的阈值,
Young Collection


young collection 期间,survivor Region 被压缩,活动对象正移动到 Survivor 或者 old 取
Marking Initiation
标记初始化。

初始化堆的占用比
- 识别到候选的旧 Region 并启动并发标记周期的阈值
- 当老年代占比超过这个合适的阈值
- 占比是基于整个的堆大小,jdk 9 是自适应的,在这之前比如 jdk8,默认值是 45%,但他是可调的
XX:InitiatingHeapOccupancyPercent来设置。-XX:ConcGCThreads=n(并发垃圾收集器使用的线程数量,默认是-XX:ParallelGCThreads/4)
Concurrent Marking Stages

- 初始标记
- 根 Region 扫描
- 并发标记
- 重新标记
- 清理
递增压缩(又称 Mixed Collection)

Mixed Collection 期间,Eden 和 Survivor 在被压缩的同时,向新的 Region 移动,Old 被压缩的同时,在向新的 Region 移动。

G1调整注意事项
驯服(taming) Mixed GCs
年轻代收集接近 SLA,但混合收集太过频繁或者逼近 SAL,消耗变多。
这就是你要调整 Mixed Collection 的原因。
频率和延迟有两个原因:
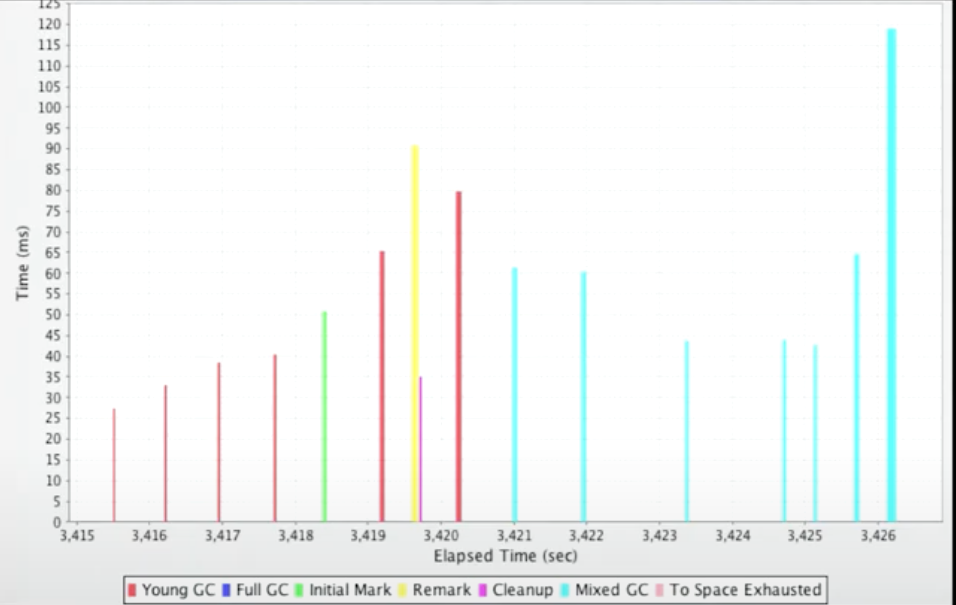
除了最后一个操作,其余操作都是小于 100ms。
【我们能做什么?】
如果你发现最近的 sla 是你唯一要关心的:
- 可以拆分昂贵的收集为更小的不昂贵的收集。
Adjusting Each Mixed Collection

在 Mixed CSet 里老年代 Region 包含的最小数量;
在 Mixed CSet 里老年代 Region 包含的最大数量;

- -XX:G1OldCSetRegionThresholdPercent=10
设置混合垃圾回收期间要回收的最大旧区域数。默认值是 Java 堆的 10%。Java HotSpot VM build 23 中没有此设置。
-XX:G1MixedGCCountTarget=8
- 设置标记周期完成后,对存活数据上限为 G1MixedGCLIveThresholdPercent 的旧区域执行混合垃圾回收的目标次数。默认值是 8 次混合垃圾回收。混合回收的目标是要控制在此目标次数以内。Java HotSpot VM build 23 中没有此设置。
【我们能做什么?】
如果你的GC开销比较大,GC频繁,耗时高,但你还有堆空间可以共享?
- 从你的 CSet 中移出最贵的 Region
【从 Mixed Collection 中消除昂贵的老年代 Region】
两种方式:频率和延迟。
- -XX:G1MixedGCLiveThresholdPercent=65
为混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%。这是一个实验性的标志。有关示例,请参见“如何解锁实验性虚拟机标志”。此设置取代了 -XX:G1OldCSetRegionLiveThresholdPercent 设置。Java HotSpot VM build 23 中没有此设置。 - -XX:G1HeapWastePercent=10
设置您愿意浪费的堆百分比。如果可回收百分比小于堆废物百分比,Java HotSpot VM 不会启动混合垃圾回收周期。默认值是 10%。Java HotSpot VM build 23 中没有此设置。
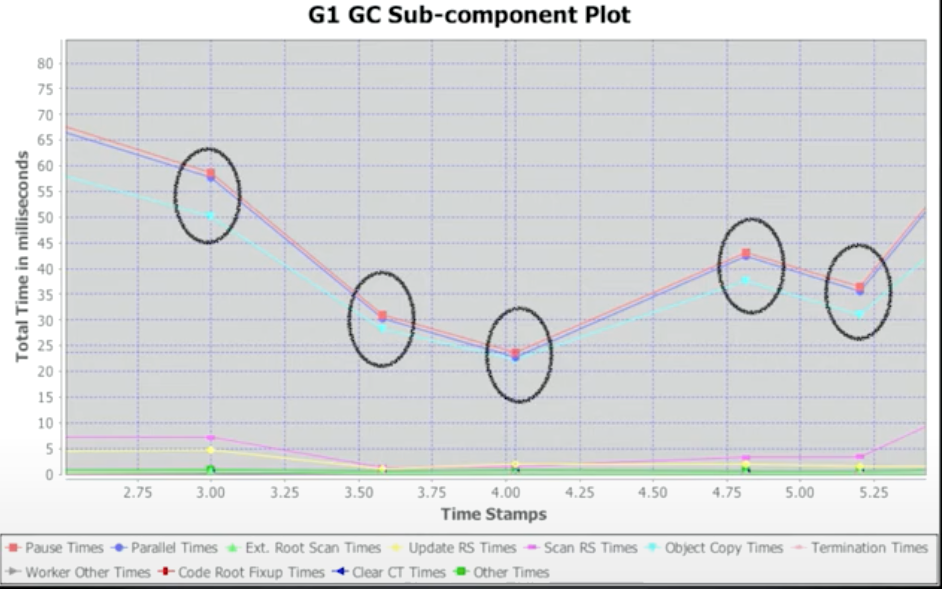
Components of a G1 GC Pause
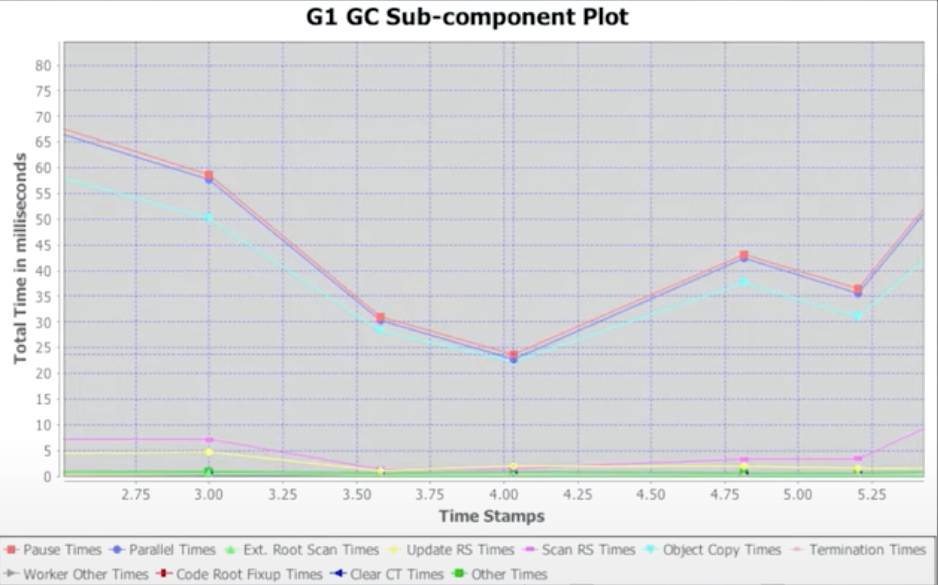
Major Contributor
大多数暂停时间花费在复制活跃对象上。所以对象复制时间是主要的贡献者。
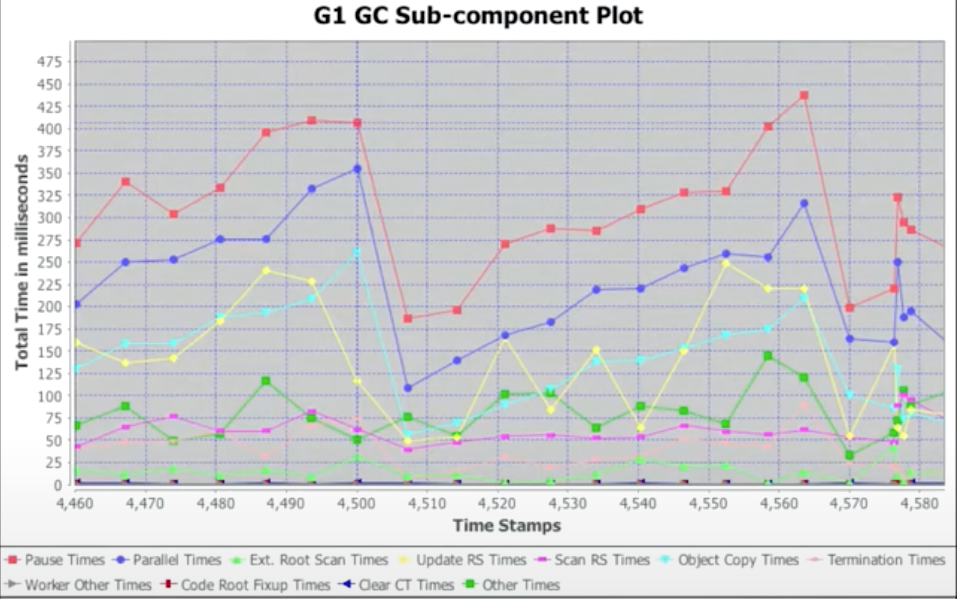
黄色线是 RSet
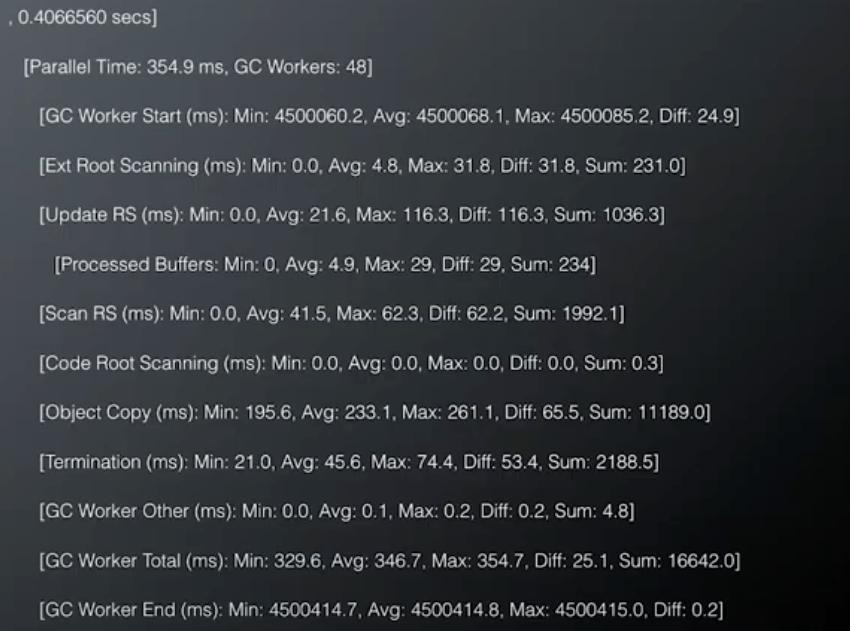
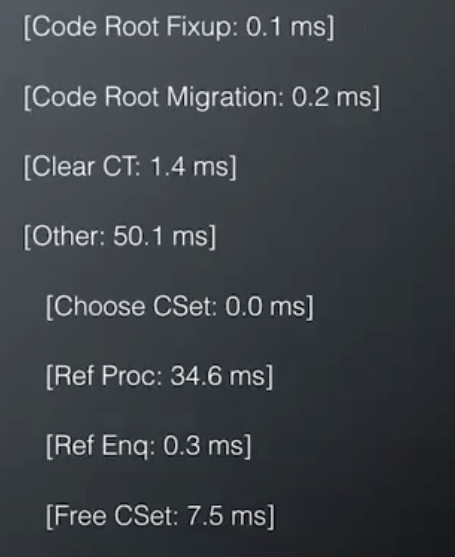
GC log:
Humongous Objects Requirements
理想情况下,巨大对象数量很少并且寿命很短。
一些长寿命的巨大对象可能造成从巨大对象区域到老年代空间的晋级失败。
我们观察到了什么
H-Object:
- 分配量超过了老年代
- 不能移动(除非死了,把他们回收,但不能移动。如果活着,移动成本高)
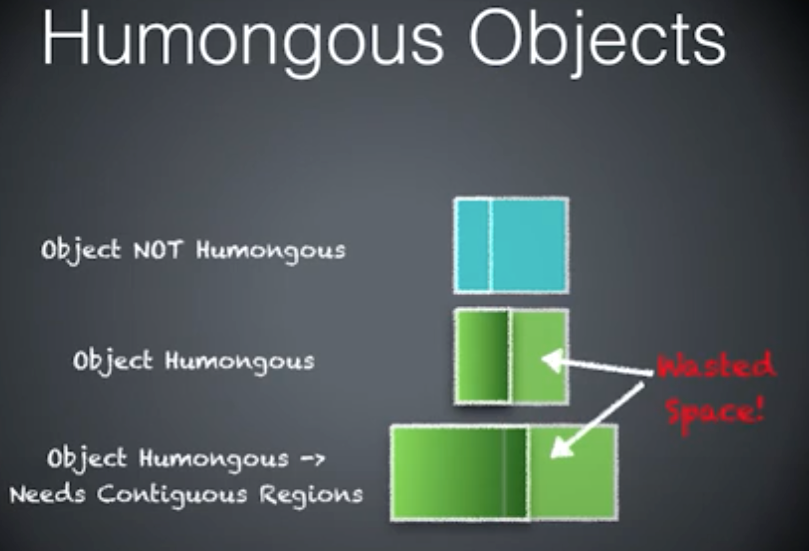
Wasted Space:
- 每一个巨大对象都需要有一个或连续的 Region 来容纳,剩下的空间就被浪费掉了。
所以 H-Object 会造成以下问题:
- Wasted Space(空间浪费,这可能导致碎片化)
- Evacuation failures (疏散失败,由于没有足够的空间来划分 Region)
Fragmentation In The G1 Collector
G1 Heap Waste Percentage
- G1 GC 被设计成用来吸收某些内存碎片的。(有足够的堆空间,不想收集昂贵的区域,所以可以吸收一些碎片)
- 默认 Java Heap 5%(你不想接触这些东西,就按照默认的来)
G1 Mixed GC(Region) Liveness Threshold
Mixed GC 活跃度阈值
- G1 GC 的 老 Region 也被设计成吸收某些碎片的。
- G1 Region 默认值是 85% 活跃度
- 置换掉以使昂贵的区域不在集合中
调整G1垃圾收集器的混合收集的工作量,即在一次混合垃圾收集中尽量多处理一些分区,可以从另外一方面提高混合垃圾收集的频率。在一次混合收集中可以回收多少分区,取决于三个因素:(1)有多少个分区被认定为垃圾分区,-XX:G1MixedGCLiveThresholdPercent=n这个参数表示如果一个分区中的存活对象比例超过n,就不会被挑选为垃圾分区,因此可以通过这个参数控制每次混合收集的分区个数,这个参数的值越大,某个分区越容易被当做是垃圾分区【来自:https://zhuanlan.zhihu.com/p/54048685】
Humongous Objects
- Wasted space
- External fragmentation
分配巨大对象的要求是连续的 Region。那么 Heap 有空闲的 Region,但它没有连续的 Region。这时候碎片化就比较严重,如果没有相应地调整 Heap 大小,就会导致 Evacuation failures(疏散失败)。
Promotion/Evacuation Failures In The G1 Collector
晋升失败/疏散失败/空间耗尽。术语不同,但含义相同。
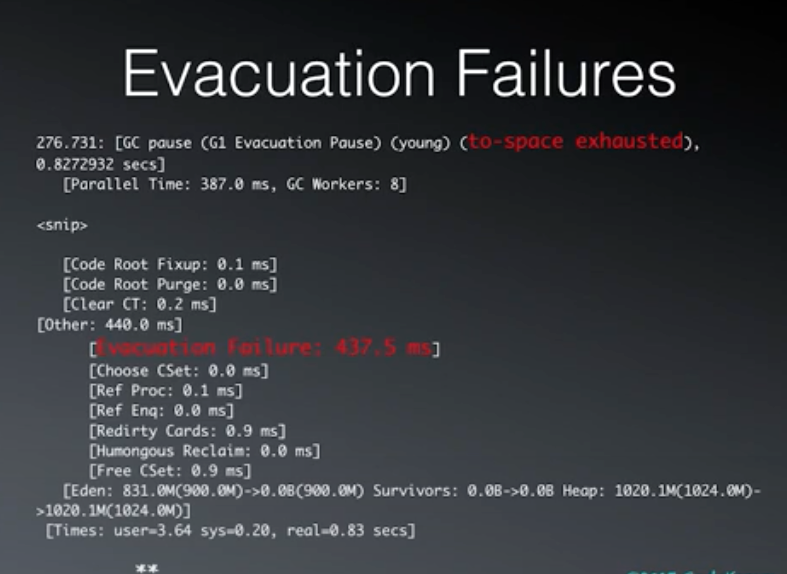
标红的表示,空间耗尽。
疏散失败花费 437.5ms。
Evacuation Failures
- 当没有更多可用的 Region 可用于幸存者或永久对象时,G1 GC 会遇到疏散失败
- 一个疏散失败是昂贵的,通常的模式是,如果你看到几个疏散失败;full GC 可能很快就会出现
避免 Evacuation Failures
一个经过大量调整的 JVM 命令行可能会限制 G1 GC 的人体工程学和适应性
- 开始调整你的 Heap 大小并设置一个合理的暂停时间目标把。
你的实时数据集+长时间活跃的瞬态数据可能对于老年代来说太大了。
- 检查你的 LDS(Live Data Set,实时数据集)以及其他内容,并增加 Heap 以适应老年代。
初始化的 Heap 占用阈值如果太高,可能会出现新的问题。【IHOP(-XX:InitiatingHeapOccupancyPercent=45)】
- 检查 IHOP 以及确保它能容纳 LDS。
- IHOP 阈值太高 —> 标记延迟 —> 进一步压缩延迟—>疏散失败(IHOP threshold too high -> Delayed marking —> Delayed incremental compaction —> Evacuation Failures)
标记周期可能花费很长时间才能完成:
- 增加并发标记线程
- 减少 IHOP(更早的开始标记周期)
老年代有足够的空间,但Survivor 空间不足:
增加 G1ReservePercent(如果 Survivor 空间会触发 Evacuation Failures 的话,增加该值,可以让该空间容纳更多的幸存者)
-XX:G1ReservePercent=10
设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险。默认值是 10%。增加或减少百分比时,请确保对总的 Java 堆调整相同的量。Java HotSpot VM build 23 中没有此设置。
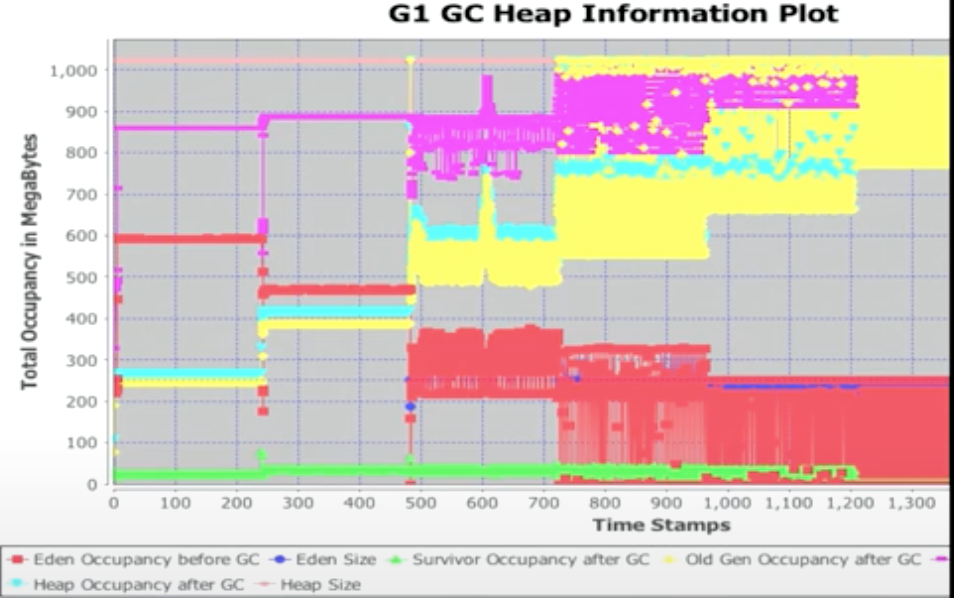

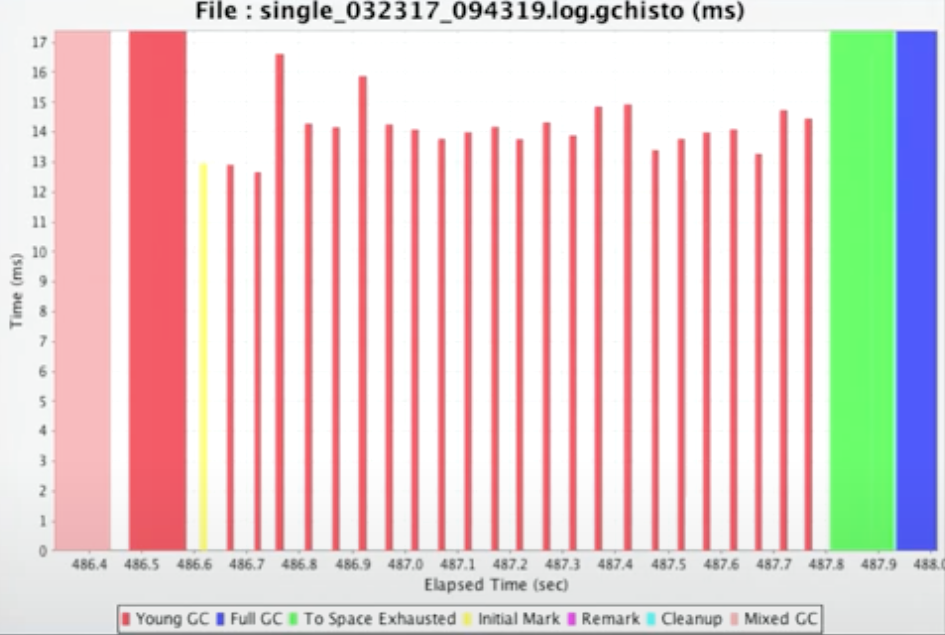

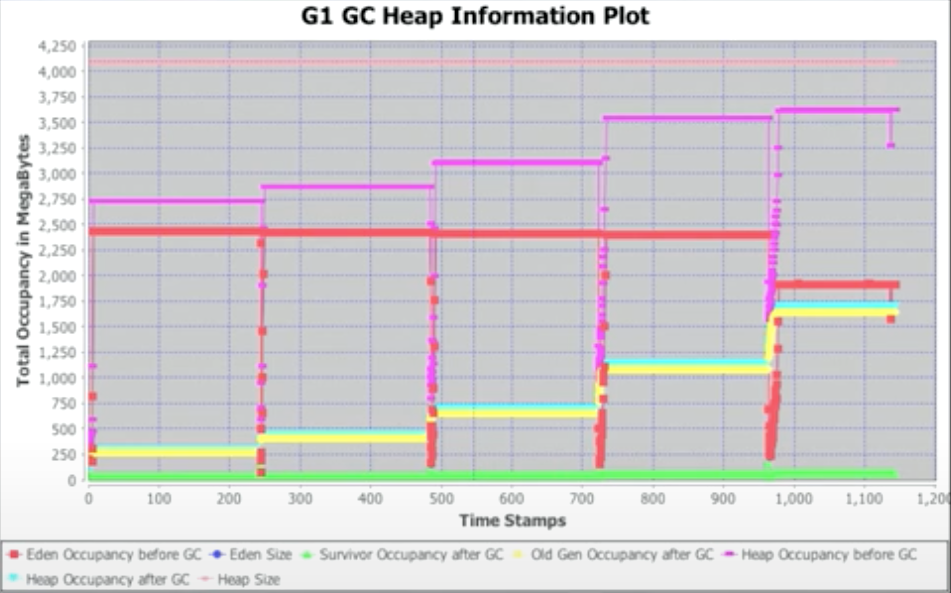
Allocation and Promotion Rates
分配和升级
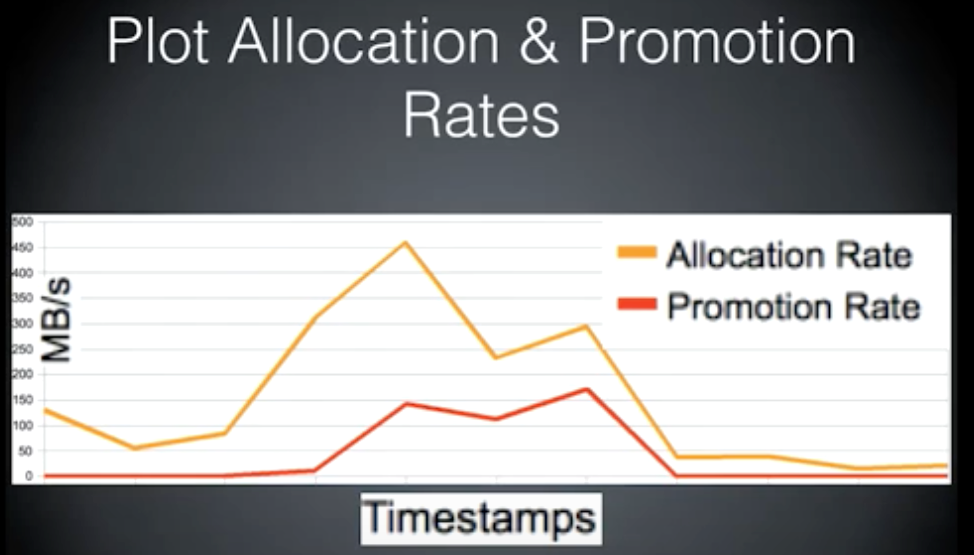
E 代表新生代空间内存,S 代表新生代中幸存区空间内存,O 代表老年代。
H 代表这个 Region 存储的是巨大对象(Humongous object,H-obj),即大小大于等于 Region 一半的对象。H-obj 有以下特点:
- H-obj 直接分配到 O 区,防止了反复拷贝移动。
- H-obj 在 Global Concurrent Marking 阶段的 cleanup 和 full GC 阶段回收。
- 在分配 H-obj 之前先检查是否超过
-XX:InitiatingHeapOccupancyPercent(设置触发标记周期的 Java 堆占用率阈值。默认占用率是整个 Java 堆的 45%)和 the marking threshold,如果超过的话,就启动 GCM,目的是提早回收,防止 evacuation failures 和 full GC。
为了减少连续 H-objs 分配对 GC 的影响,需要把大对象变为普通的对象,建议增大 Region size。
一个 Region 的大小可以通过 -XX:G1HeapRegionSize 设定,取值范围从 1M 到 32M,是 2 的指数。如果不设定,G1 会根据 Heap 大小自动决定。
// share/vm/gc_implementation/g1/heapRegion.cpp// Minimum region size; we won't go lower than that.// We might want to decrease this in the future, to deal with small// heaps a bit more efficiently.#define MIN_REGION_SIZE ( 1024 * 1024 )// Maximum region size; we don't go higher than that. There's a good// reason for having an upper bound. We don't want regions to get too// large, otherwise cleanup's effectiveness would decrease as there// will be fewer opportunities to find totally empty regions after// marking.#define MAX_REGION_SIZE ( 32 * 1024 * 1024 )// The automatic region size calculation will try to have around this// many regions in the heap (based on the min heap size).#define TARGET_REGION_NUMBER 2048void HeapRegion::setup_heap_region_size(size_t initial_heap_size, size_t max_heap_size) {uintx region_size = G1HeapRegionSize;if (FLAG_IS_DEFAULT(G1HeapRegionSize)) {size_t average_heap_size = (initial_heap_size + max_heap_size) / 2;region_size = MAX2(average_heap_size / TARGET_REGION_NUMBER,(uintx) MIN_REGION_SIZE);}int region_size_log = log2_long((jlong) region_size);// Recalculate the region size to make sure it's a power of// 2. This means that region_size is the largest power of 2 that's// <= what we've calculated so far.region_size = ((uintx)1 << region_size_log);// Now make sure that we don't go over or under our limits.if (region_size < MIN_REGION_SIZE) {region_size = MIN_REGION_SIZE;} else if (region_size > MAX_REGION_SIZE) {region_size = MAX_REGION_SIZE;}}
SATB
SATB 的全称是 Snapshot-At-The-Beginning,由字面理解,是 GC 开始时活着的对象的一个快照。
通过 Root Tracing 得到,作用是维持并发 GC 的正确性。
如何维持并发 GC 的正确性?
- 根据三色标记算法,对象存在三种状态:
- 白:对象没有被标记到,标记阶段结束后,会被当做垃圾回收掉。
- 灰:对象被标记了,但是它的 field 还没有被标记或标记完。
- 黑:对象被标记了,且它的所有 field 也被标记完了。
由于并发阶段的存在,Mutator(Mutator:特指java的应用线程) 和 Garbage Collector 线程同时对对象进行修改,就会出现白对象漏标的情况,这种情况发生的前提是:
- Mutator 赋予一个黑对象到该白对象的引用
- Mutator 删除了所有从灰对象到该白对象的直接或者间接引用。
对于第一个条件,在并发标记阶段,如果该白对象是new出来的,并没有被灰对象持有,那么它会不会被漏标呢?Region中有两个top-at-mark-start(TAMS)指针,分别为prevTAMS和nextTAMS。在TAMS以上的对象是新分配的,这是一种隐式的标记。对于在GC时已经存在的白对象,如果它是活着的,它必然会被另一个对象引用,即条件二中的灰对象。如果灰对象到白对象的直接引用或者间接引用被替换了,或者删除了,白对象就会被漏标,从而导致被回收掉,这是非常严重的错误,所以SATB破坏了第二个条件。也就是说,一个对象的引用被替换时,可以通过write barrier 将旧引用记录下来。
// share/vm/gc_implementation/g1/g1SATBCardTableModRefBS.hpp// This notes that we don't need to access any BarrierSet data// structures, so this can be called from a static context.template <class T> static void write_ref_field_pre_static(T* field, oop newVal) {T heap_oop = oopDesc::load_heap_oop(field);if (!oopDesc::is_null(heap_oop)) {enqueue(oopDesc::decode_heap_oop(heap_oop));}}// share/vm/gc_implementation/g1/g1SATBCardTableModRefBS.cppvoid G1SATBCardTableModRefBS::enqueue(oop pre_val) {// Nulls should have been already filtered.assert(pre_val->is_oop(true), "Error");if (!JavaThread::satb_mark_queue_set().is_active()) return;Thread* thr = Thread::current();if (thr->is_Java_thread()) {JavaThread* jt = (JavaThread*)thr;jt->satb_mark_queue().enqueue(pre_val);} else {MutexLockerEx x(Shared_SATB_Q_lock, Mutex::_no_safepoint_check_flag);JavaThread::satb_mark_queue_set().shared_satb_queue()->enqueue(pre_val);}}
SATB也是有副作用的,如果被替换的白对象就是要被收集的垃圾,这次的标记会让它躲过GC,这就是float garbage。因为SATB的做法精度比较低,所以造成的 float garbage 也会比较多。
G1 logging
命令行选项最佳实践
基本命令行
为了启用G1收集器,使用:-XX:+UseG1GC
这个是启动在已下载的JDK演示和示例里的Java2Demo程序的示例命令行:
java -Xmx50m -Xms50m -XX:UserG1GC -XX:MaxGCPauseMillis=200 -jar c:\javademos\demo\jfc\Java2D\Java2demo.jar
关键命令行开关
-XX:+UseG1GC - 告诉Java虚拟机使用G1垃圾收集器
-XX:MaxGCPauseMillis=200 - 为最大GC暂停时间设置一个指标。这是一个软目标,Java虚拟机将尽最大努力实现它。因此,暂停时间目标有时候可能不会达到。默认值是200毫秒。
-XX:InitiatingHeapOccupancyPercent=45 - 触发并发垃圾收集周期的整个堆的百分比时机。
什么时候用 G1
- 大的 Heap
- 大于等于 6G
- 应用需要更低的延迟
什么时候不该用 G1
- G1 需要更多的计算资源和内存来运行。
- Heap 不够大
- 低于 6G
- 应用不需要更少的暂停
参考
https://www.oracle.com/cn/technical-resources/articles/java/g1gc.html
https://www.slideshare.net/leonjchen/java-gc-javadeveloperdaytw
G1 Java垃圾回收 rset card table
https://blog.csdn.net/waltonhuang/article/details/105542041

若有收获,就点个赞吧
0 人点赞
