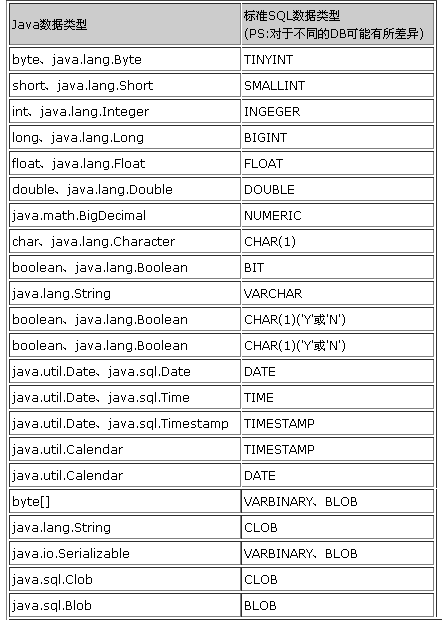
JDBC(Java DataBase Connectivity,Java 数据库连接),一组可以执行 SQL 语句的 Java API(Java 数据库的统一访问接口)
JDBC 完成 CRUD 操作
依赖:mysql:mysql-connector-java
- 在 java.sql 包下
步骤
// mysql-connector-java 6.0.x+ 版本的数据库驱动是 com.mysql.cj.jdbc.DriverClass.forName("com.mysql.jdbc.Driver"); // 从 Java 6(JDBC 4.0)开始,无需加载数据库驱动Connection conn = DriverManager.getConnection(String url, String user, String password); // 建立到指定数据库 URL 的连接// url = "jdbc:mysql://localhost:3306/mydb"`// jdbc:mysql://127.0.0.1:3306/mydb?useUnicode=true&characterEncoding=UTF-8&useSSL=false&autoReconnect=true&failOverReadOnly=false&allowMultiQueries=true&rewriteBatchedStatements=true&serverTimezone=GMT%2B8// 如果连接的数据库服务器在本机上,并且端口是 3306,则可以简写:url = "jdbc:mysql:///mydb"
- 加载数据库驱动,使用 DriverManager 获取连接对象
- 使用 Connection 创建 PreparedStatement 语句对象
- 设置 SQL 语句中的参数值,执行 SQL 语句
- 操作结果集
- 回收数据库资源,包括关闭 ResultSet、Statement 和 Connection 等资源
- 使用 PreparedStatement(预处理语句)比使用 Statement 的好处:
- 无须“拼接”SQL 语句,编程更简单
- 预编译 SQL 语句,性能更好(MySQL 不支持 PreparedStatement 的性能优化)
- 可以防止 SQL 注入,安全性更好
Configuration Properties for Connector/J(opens new window)常见参数:user、password、useSSL、characterEncoding、serverTimezone、autoReconnect、connectTimeout、allowMultiQueries(默认 false,是否允许使用 ‘;’ 在一个语句中分隔多个查询)、rewriteBatchedStatements(影响 executeBatch() 方法)、useCursorFetch、defaultFetchSize、tinyInt1isBit(默认 true)
常用 API
Connection 接口
Connection 接口:代表数据库连接对象(一个物理连接会话)
- 创建语句对象
Statement createStatement():创建一个 Statement 对象
PreparedStatement prepareStatement(String sql):创建一个 PreparedStatement 对象
PreparedStatement prepareStatement(String sql, int autoGeneratedKeys):创建一个 PreparedStatement 对象,并设置该对象是否能获取自动生成的主键(int 常量:Statement.RETURN_GENERATED_KEYS) 控制事务
void setAutoCommit(boolean autoCommit):false 为关闭自动提交,开启事务(MySQL 默认打开自动提交)
void commit():提交事务,并释放所持有的数据库锁
void rollback():回滚事务,并释放所持有的数据库锁(在 catch 块中回滚事务)Statement 接口
Statement 接口:用于执行静态 SQL 语句(将 SQL 语句发送到数据库)
- int 常量:RETURN_GENERATED_KEYS、NO_GENERATED_KEYS
- 执行语句
int executeUpdate(String sql):执行 DML 语句时返回受影响的行数;执行 DDL 语句时返回 0
int executeUpdate(String sql, int autoGeneratedKeys):执行给定的 DML 语句,并设置此 Statement 生成的自动生成键是否能用于获取
ResultSet executeQuery(String sql):执行 DQL 语句,并返回查询结果对应的 ResultSet 对象 - 批量更新
void addBatch(String sql):将给定的 SQL 命令添加到此 Statement 对象的当前命令列表中
int[] executeBatch()、long[] executeLargeBatch():将一批命令(DDL、DML 语句)提交给数据库来执行,如果全部命令执行成功,则返回影响行数组成的数组
void clearBatch():清空此 Statement 对象的当前 SQL 命令列表 获取自动生成主键
ResultSet getGeneratedKeys():获取由于执行此 Statement 对象而创建的所有自动生成的主键PreparedStatement 接口
PreparedStatement 接口,Statement 的子接口,用于执行带占位符(?)参数的 SQL 语句
- 给参数设值即添加到批处理
viod setXxx(int parameterIndex, Xxx value):根据索引(从 1 开始)将 SQL 语句中指定位置的参数设置为 value 值,如果不清楚预编译 SQL 语句中各参数的类型,可以使用 setObject() 方法来传入参数
void setBlob(int parameterIndex, InputStream inputStream):将指定参数设置为输入流对象
void addBatch():将一组参数添加到此 PreparedStatement 对象的批处理命令中(调用前需先为参数设置) 执行语句
int executeUpdate():执行 DML 语句或 DDL 语句(无须接收 SQL 字符串)
ResultSet executeQuery():执行 DQL 语句(无须接收 SQL 字符串)ResultSet 接口:结果集对象
boolean next():将光标从当前行移动到下一行(光标的初始位置是第一行之前)
Xxx getXxx(int columnIndex):获取当前行中的指定列索引(从 1 开始)的数据
Xxx getXxx(String columnName):获取当前行中的指定列名的数据Xxx 表示 Java 中与当前列的数据类型对应的数据类型,也可以用 getObject() 获取任意类型的值,或 getString() 方法获取除 Blob 之外的任意类型列的值
ResultsetRows 接口:结果集行对象
ResultsetRowsStatic 静态结果集,默认的查询方式,普通查询(一次获取全部):Represents an in-memory result set
- ResultsetRowsCursor 游标结果集,服务器端基于游标查询(一次多行):Model for result set data backed by a cursor. (需要设置连接参数 useCursorFetch=true,设置 Statement 每次读取的数据数量,如 fetchSize=”100”)
ResultsetRowsStreaming 动态结果集,流式查询(一次一行):Provides streaming of Resultset rows. Each next row is consumed from the input stream only on {@link #next()} call. Consumed rows are not cached thus we only stream result sets when they are forward-only, read-only, and the fetch size has been set to Integer.MIN_VALUE (rows are read one by one). (需要设置 Statement 参数:resultSetType=”FORWARD_ONLY”、fetchSize=”-2147483648”)
接口 Blob
InputStream getBinaryStream():以流的形式获取此 Blob 实例指定的 BLOB 值
DAO 设计
DAO(Data Access Object):一个数据访问接口,夹在业务逻辑与数据库资源中间
分包规范:
domain:存放实体类 / 模型对象, Xxx
dao:存放 DAO 接口,IXxxDAO,对实体类对象的 CRUD 的封装
dao.impl:存放 DAO 实现类,XxxDAOImpl
util:存放工具类,JdbcUtils,包括:在初始化时加载配置文件创建 DataSource 对象、获取连接对象、释放资源
test:存放 DAO 测试类,XxxDAOTest事务处理
隐式提交事务:正常退出或者运行 DDL、DCL 语句
- 隐式自动回滚:Connection 遇到一个未处理的 SQLException 异常,系统非正常退出(但如果程序捕获了该异常,则需要在异常处理块中显式地回滚事务)
操作事务的模板:
try {connection.setAutoCommit(false); // 取消事务自动提交// DML 操作1// DML 操作2// ...connection.commit(); // 提交事务} catch(Exception e) {// 处理异常connection.rollback(); // 回滚事务} finally {// 释放资源}
Java 事务
Java 事务的类型有三种:JDBC 事务、JTA(Java Transaction API)事务、容器事务
- JDBC 的一切行为包括事务是基于一个 Connection 的,在 JDBC 中通过 Connection 对象进行事务管理。一个 JDBC 事务不能跨越多个数据库。
- Java 事务 API(Java Transaction API,简称 JTA)是一个 Java EE 应用程序接口,在 Java 环境中,允许完成跨越多个 XA 资源的分布式事务。
- 常见的 JTA 实现有以下几种:
- J2EE 容器所提供的 JTA 实现(如 JBoss、WebLogic 等)
- 独立的 JTA 实现:如 Atomikos、Bitronix 等
- JTA 对 DataSource、Connection 和 Resource 都是有要求的,只有符合 XA 规范,并且实现了 XA 规范的相关接口(javax.sql.XADataSource、javax.sql.XAConnection 和 javax.sql.XAResource)的类才能参与到 JTA 事务中来。
- MySQL 的 JDBC 驱动不支持批量处理,在默认情况下会无视 executeBatch() 语句,把期望批量执行的一组 SQL 语句拆散,一条一条地发给 MySQL
- 但在新的 JDBC 驱动(5.1.13 以上版本)中,可以通过在 URL 连接中设置参数来优化:rewriteBatchedStatements=true(默认为 false)
- 为了让批量操作可以正确地处理错误,必须把批量执行的操作视为单个事务
- 步骤:
- void addBatch():将给定的 SQL 命令添加到此 Statement 对象的当前命令列表中,或者设置 SQL 语句中指定位置的参数值后添加到此 PreparedStatement 对象的当前命令列表中,注意:不能添加 select 查询语句
- int[] executeBatch():执行批处理
- void clearBatch():清除缓存
代码片段
// 保存当前的自动的提交模式boolean autoCommit = conn.getAutoGommit();// 关闭自动提交conn.setAutoCommit(false);Statement stmt = conn.createStatement();// 使用 Statement 同时收集多条 SQL语句stmt.addBatch(sqll);stmt.addBatch(sql2);stmt.addBatch(sql3);// 同时提交所有的 SQL 语句stmt.executeBatch();// 清空收集的 SQL 命令列表stmt.clearBatch();// 提交修改conn.commit();// 恢复原有的自动提交模式conn.setAutocommit(autoCommit);
大数据类型处理
将 Blob 类型数据插入数据库需要调用 PreparedStatement 对象将指定参数设置为输入流对象的方法
从 ResultSet 里取出 Blob 数据
当应用程序启动时,系统主动建立足够的数据库连接,并将这些连接组成一个连接池
- 每次应用程序请求数据库连接时,无须重新打开连接,而是从连接池中取出已有的连接使用,使用完后不再关闭数据库连接,而是直接将连接归还给连接池
- 连接数 = ((处理器核心数 * 2) + 有效磁盘数)(opens new window)
- Connection Pool
- javax.sql.DataSource 接口,表示 JDBC 的数据库连接池
常用 DataSource 的实现:DBCP、C3P0、Druid、Hikari
// 使用连接池获取 Connection 对象Connection conn = dataSource.getConnection();// 释放数据库连接conn.close();
获取 DataSource 对象
DBCP 连接池
需要的 jar 包:org.apache.commons:commons-dbcp2
Tomcat 内置的数据库连接池也是 DBCP
// 通过连接池工厂创建连接池对象// 配置文件中的 key 名要对应 BasicDataSourceFactory 类中字符串常量DataSource ds = BasicDataSourceFactory.createDataSource(Properties properties);
Druid 连接池(opens new window)
需要的 jar 包:com.alibaba:druid、commons-logging:commons-logging
- Druid 的分页支持:PagerUtils
- 配置属性列表(opens new window)
- Druid Spring Boot Starter(opens new window)
driverClassName=com.mysql.jdbc.Driverurl=jdbc:mysql://localhost:3306/jdbcdemo?useSSL=false&allowMultiQueries=true&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghaiusername=rootpassword=admin# 最大连接数maxActive=10
// 通过连接池工厂创建连接池对象// 配置文件中的 key 名要对应 DruidDataSourceFactory 类中字符串常量DataSource ds = DruidDataSourceFactory.createDataSource(Properties properties);
Client SDK 的 API 形式
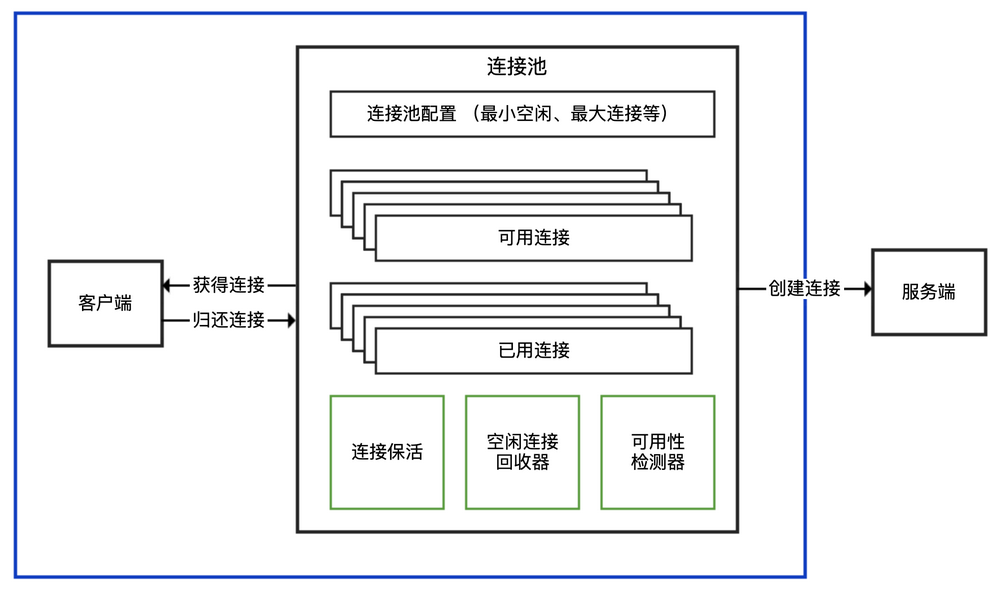
涉及 TCP 连接的客户端 SDK,对外提供 API 的三种方式:
- 内部带有连接池的 API:对外提供一个 XXXClient 类,通过这个类可以直接进行服务端请求;这个类内部维护了连接池,SDK 使用者无需考虑连接的获取和归还问题。一般而言,XXXClient 是线程安全的。(几乎所有的数据库连接池,都是这一类)
- 连接池和连接分离的 API:有一个 XXXPool 类负责连接池实现,先从其获得连接 XXXConnection,然后用获得的连接进行服务端请求,完成后使用者需要归还连接。通常,XXXPool 是线程安全的,可以并发获取和归还连接,而 XXXConnection 是非线程安全的。(Jeds)
- 非连接池的 API: 基于单一连接,每次使用都需要创建和断开连接,性能一般,且通常不是线程安全的,需要使用者自己封装连接池。
重构的思想
- 把相同的结构提取出去,把不同内容的使用参数表示
- JDBC 操作模板:JdbcTemplate
- 把处理结果集的具体行为交给每一个 DAO 的实现类
- 结果集处理器接口:IResultSetHandler
- 结果集处理器实现类:
- BeanHanlder:把结果集中的第一条记录封装成一个 JavaBean 对象
- BeanListHandler:把结果集中的每一条记录都封装成一个 JavaBean 对象,再把多个 JavaBean 对象存储到 List 集合中
- 此时要保证:表中的列名和 JavaBean 中的属性名相同,表中的列类型和 JavaBean 中属性的类型对应
- 通过内省机制获取属性名(列名)、属性值
- 使用注解或 XML 文件处理表名和类名、属性名和列名不同的情况(映射)

若有收获,就点个赞吧
0 人点赞
