1. 回环检测的意义
回环检测loop back detection:前端所造成的累计误差,单纯的后端优化无法构建全局一致的轨迹和地图,所以需要回环检测,构建时间相隔更加久远的约束,获得更好的建图效果。
2. 回环检测的方法
- 朴素方法:
- 任意两幅两两配对(计算量太大)
- 随机配对,检测效率低下
- 基于里程计(odometry based)的几何关系
相机运动到之前位置的附近。但如果误差过大也就无从检测到附近这一说,有点悖论的感觉
- 基于外观的(appearance based)几何关系
与前端后端的估计都无关,仅根图像之间的相似性确定回环关系。使得回环检测称为SLAM中独立的模块,能在不同场景下工作,是主流做法
- 基于传感器
比如利用GPS。
2.1 图像之间的相似性
基于外观的方法就是计算图像之间的相似性。
不用L1范数的原因:像素灰度不稳定,受光照和相继曝光的影响;像素位移也会使得L1范数差异值很大
现在提出相似关系的相关概念:
- 感知偏差(perceptual aliasing),对应FP
- 感知变异(perceptual variability),对应FN
在SLAM中,往往要求高的准确率,对召回率则相对宽容一点。因为一旦回环检测出错,则会导致整个优化出现问题。而较低的召回率顶多使得部分回环没有检测到,可以会多一些累计误差的影响,但这都能通过一两次回环就完全消除了。
3. 词袋模型(Bag-of-Words,BoW)
用图像中有哪几种特征来描述一幅图像。特征就是单词,没有顺序,可能甚至没有数量,强调的是集合。
有了词袋模型,一个图片的特征可以描述为一个向量[1,2,0],单词1有1个,单词2有2个,单词3没有。
然后就可以根据这个向量进行相似性计算。
3.1 k-means
我们知道字典由很多单词组成,那么提取出来的特征如何变为单词,所以字典生成问题类似于一个聚类(clustering)问题。
k-means算法基本流程:
- 随机选取k个中心店;(分为k个类)
- 对每一个样本,计算它与每个中心点之间的距离,取最小的作为它的归类,如此迭代n次
- 每次迭代过程中,利用均值等方法更新各个聚类的中心点(质心)
- 如果每个中心点都变化很小,则算法收敛
缺点:
- k值的选取不把握(分类的个数,中心点不好掌握,初始值)
- 对于不是凸的数据集比较难收敛
- 最终结果和初始点的选择有关,容易陷入局部最优
- 对噪音和异常点比较的敏感
3.2 字典结构
不管k-meas的优缺点,我们现在已经有聚类好的字典了,那么怎么从某个特征点查找字典的相应单词呢?
如果字典是一个列表,那么查找的复杂度是O(n),太慢了,我们可以使用树结构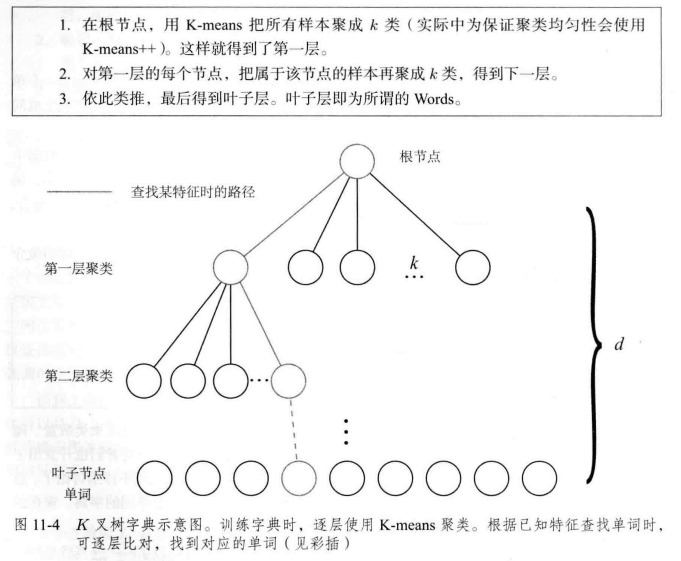
以这种方式实现对数级别复杂度的查找。
4. 实践
- 创建字典,通常用更大的数据集训练而成。
- opencv读图
- 计算orb
- dbow3根据orb生成字典
- 相似度计算
TF-IDF(Term Frequency-Inverse Document Frequency),是文本检索中常用的一种加权方式,也用于BoW模型中。TF的思想是,某单词在一副图像中经常出现,它的区分度就高。IDF的思想是,某单词在字典中出现的频率越低,分类图像时区分度越高。假设一张图中所有特征数量为n,某叶子节点wi,一张图片该单词的数量为ni,则:
TF:
IDF:
那么一个单词的权重就是:
5. DBoW3是什么
是一个开源的C++库,用于给图像特征排序,并将图像转化为视觉词袋表示。它采用层级树状结构。DBoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的图像检索和对比非常快。

若有收获,就点个赞吧
0 人点赞
