C++定义类的时候,是否可以使用自身来创建成员变量?
只能采用指针(包含智能指针)或引用的方式来创建。
class Node {char *cargo;Node left;Node right;};
如果采用这种方式的话,在编译期间就会出错,因为其会产生无限产生自身,从而这个object会变的无限大。可以改成如下形式
class Node {char *cargo;Node* left; // I'm not a Node; I'm just a pointer to a NodeNode* right; // Same here};
No, because the object would be infinitely large (because every
Nodehas as members two otherNodeobjects, which each have as members two otherNodeobjects, which each… well, you get the point).
拓展知识:
Java是可以的,比如下面的代码
public class A {private A a1;private A a2;A getA1(){return a1;}A getA2(){return a2;}void setA1(A a1){this.a1 = a1;}void setA2(A a2){this.a2 = a2;}}
- In Java an object variable is a reference to the object while in C++ an object variable is a value. This is why you can’t hold in C++ a direct member of yourself, as is, the size of the object would be infinite (A holding an actual value of A, holding an actual value of A, … recursively).
In Java when A holds an A, it just holds a reference to the other A (yes, you can still access recursively the referenced A, but it is not part of your size, you just hold a reference to it, it is stored elsewhere in memory. The addition to your size is just the size of a reference).
You can achieve similar semantics in C++ with reference variables or pointers, by adding&for a reference or*for a pointer:
A& a2 = a1; // a2 is a reference to A, assigned with a reference to a1// note that a1 above is assumed to be also of type A&A* a2 = a1; // a2 is a pointer to A, assigned with the address stored in a1// note that a1 above is assumed to be also of type A*
- Java Garbage Collector reclaims unused memory while in C++ the programmer needs to handle that, possibly with C++ tools such as smart pointers.
- Java Garbage Collector reclaims unused memory via Trace by Reachability, C++ smart pointers are based on scope lifetime. Additionally, C++
shared_ptris based on reference counting which has its advantages, but is subject to reference cycles possible leak of memory, which should be avoided with proper design of your code.
大体意思是说,java采用的是引用的方式,同时采用了垃圾回收机制,从而避免了内存的泄漏,对于C++来说,采用指针可以达到同样的引用效果,但是不要使用shared_ptr,因为shared_ptr拥有一个引用计数器,而这会导致最终的内存泄漏。所以可以采用unique_ptr 或是没有引用计数的weak_ptr
typeid, type_info使用
typeid
- typeid 运算符允许在运行时确定对象的类型
- type_id 返回一个 type_info 对象的引用
- 如果想通过基类的指针获得派生类的数据类型,基类必须带有虚函数
-
type_info
type_info 类描述编译器在程序中生成的类型信息。 此类的对象可以有效存储指向类型的名称的指针。 type_info 类还可存储适合比较两个类型是否相等或比较其排列顺序的编码值。 类型的编码规则和排列顺序是未指定的,并且可能因程序而异。
- 头文件:
typeinfo```cppinclude
using namespace std;
class Flyable { public: virtual void takeoff() = 0; virtual void land() = 0; };
class Bird : public Flyable { public: void foraging() {} virtual void takeoff() override {} virtual void land() override {} virtual ~Bird() {} };
class Plane : public Flyable { void carry() {} virtual void takeoff() override {} virtual void land() override {} virtual ~Plan() {} }
class type_info { public: const char* name() const; bool operator == (const type_info & rhs) const; bool operator == (const type_info & rhs) const; int before(const type_info & rhs) const; virtual ~type_info(); private:
};
void doSomething(Flyable obj) { obj->takeoff(); cout << typeid(obj).name() << endl; // 输出传入对象类型(”class Bird” or “class Plane”)
if(typeid(*obj) == typeid(Bird)) // 判断对象类型{Bird *bird = dynamic_cast<Bird *>(obj); // 对象转化bird->foraging();}obj->land();
}
int main() { Bird *b = new Bird(); doSomething(b); delete b; b = nullptr; return 0; }
<a name="M0Trm"></a>#### **子类析构时要调用父类的析构函数吗**析构函数调用的次序是先派生类的析构后基类的析构,也就是说在基类的的析构调用的时候,派生类的信息已经全部销毁了。定义一个对象时先调用基类的构造函数、然后调用派生类的构造函数;析构的时候恰好相反:先调用派生类的析构函数、然后调用基类的析构函数。<br />基类构造函数-->子类构造函数-->子类析构函数-->基类构造函数<a name="LnWHv"></a>#### delete和delete[]的区别delete只会调用一次析构函数,而delete[]会调用每一个成员的析构函数。当delete操作符用于数组时,它为每个数组元素调用析构函数,然后调用operator delete来释放内存。<br />delete与new配套,delete []与new []配套<br />对于内建简单数据类型,delete和delete[]功能是相同的。对于自定义的复杂数据类型,delete和delete[]不能互用。delete[]删除一个数组,delete删除一个指针。简单来说,用new分配的内存用delete删除;用new[]分配的内存用delete[]删除。delete[]会调用数组元素的析构函数。内部数据类型没有析构函数,所以问题不大。如果你在用delete时没用括号,delete就会认为指向的是单个对象,否则,它就会认为指向的是一个数组。<a name="vzJJK"></a>#### 结构和联合`结构` 和 `联合`都是由多个不同的数据类型成员组成, 但在任何同一时刻,联合中只存放了一个被选中的成员(所有成员共用一块地址空间), 而结构的所有成员都存在(不同成员的存放地址不同)。 <br />对于 `联合`的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于结构, 不同成员赋值是互不影响的。联合体和结构体都是由若干个数据类型不同的数据成员组成。使用时,联合体只有一个有效的成员;而结构体所有的成员都有效。<br />对联合体的不同成员赋值,将会对覆盖其他成员的值,而对于结构体的对不同成员赋值时,相互不影响。<br />联合体的大小为其内部所有变量的最大值,按照最大类型的倍数进行分配大小;结构体分配内存的大小遵循内存对齐原则。```cppstruct [structure name]{member definition;member definition;...member definition;};union [union name]{member definition;member definition;...member definition;};
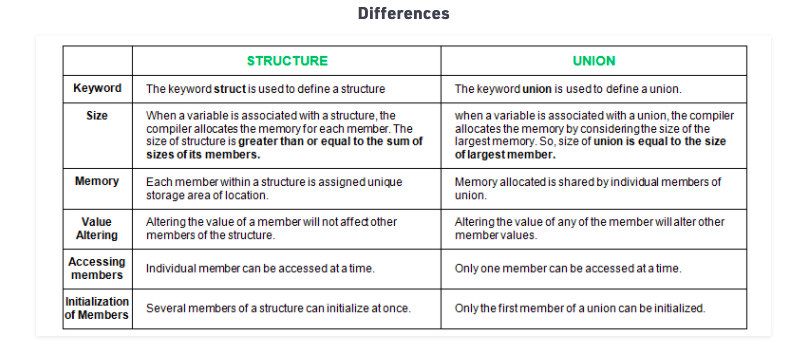
- Both are user-defined data types used to store data of different types as a single unit.
- Their members can be objects of any type, including other structures and unions or arrays. A member can also consist of a bit field.
- Both structures and unions support only assignment = and sizeof operators. The two structures or unions in the assignment must have the same members and member types.
- A structure or a union can be passed by value to functions and returned by value by functions. The argument must have the same type as the function parameter. A structure or union is passed by value just like a scalar variable as a corresponding parameter.
- ‘.’ operator is used for accessing members.
// C program to illustrate differences
// between structure and Union
#include <stdio.h>
#include <string.h>
// declaring structure
struct struct_example
{
int integer;
float decimal;
char name[20];
};
// declaraing union
union union_example
{
int integer;
float decimal;
char name[20];
};
void main()
{
// creating variable for structure
// and initializing values difference
// six
struct struct_example s={18,38,"geeksforgeeks"};
// creating variable for union
// and initializing values
union union_example u={18,38,"geeksforgeeks"};
printf("structure data:\n integer: %d\n"
"decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
printf("\nunion data:\n integeer: %d\n"
"decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
// difference two and three
printf("\nsizeof structure : %d\n", sizeof(s));
printf("sizeof union : %d\n", sizeof(u));
// difference five
printf("\n Accessing all members at a time:");
s.integer = 183;
s.decimal = 90;
strcpy(s.name, "geeksforgeeks");
printf("structure data:\n integer: %d\n "
"decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
u.integer = 183;
u.decimal = 90;
strcpy(u.name, "geeksforgeeks");
printf("\nunion data:\n integeer: %d\n "
"decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
printf("\n Accessing one member at time:");
printf("\nstructure data:");
s.integer = 240;
printf("\ninteger: %d", s.integer);
s.decimal = 120;
printf("\ndecimal: %f", s.decimal);
strcpy(s.name, "C programming");
printf("\nname: %s\n", s.name);
printf("\n union data:");
u.integer = 240;
printf("\ninteger: %d", u.integer);
u.decimal = 120;
printf("\ndecimal: %f", u.decimal);
strcpy(u.name, "C programming");
printf("\nname: %s\n", u.name);
//difference four
printf("\nAltering a member value:\n");
s.integer = 1218;
printf("structure data:\n integer: %d\n "
" decimal: %.2f\n name: %s\n",
s.integer, s.decimal, s.name);
u.integer = 1218;
printf("union data:\n integer: %d\n"
" decimal: %.2f\n name: %s\n",
u.integer, u.decimal, u.name);
}
//Output
structure data:
integer: 18
decimal: 38.00
name: geeksforgeeks
union data:
integeer: 18
decimal: 0.00
name: ?
sizeof structure: 28
sizeof union: 20
Accessing all members at a time: structure data:
integer: 183
decimal: 90.00
name: geeksforgeeks
union data:
integeer: 1801807207
decimal: 277322871721159510000000000.00
name: geeksforgeeks
Accessing one member at a time:
structure data:
integer: 240
decimal: 120.000000
name: C programming
union data:
integer: 240
decimal: 120.000000
name: C programming
Altering a member value:
structure data:
integer: 1218
decimal: 120.00
name: C programming
union data:
integer: 1218
decimal: 0.00
name: ?
structure is better because as memory is shared in union ambiguity is more.
编译器可以指定结构体的对其方式,对于结构体中的静态成员,是被放置在静态区而不占用结构体的内存。
long long, char, int, char[2] 占用的字节各为8,1,4,2
long long占用8个字节,因此结构体的内存占用大小应该等于8的整数倍
char[2]虽然占用2个字节,但它的存取粒度是1字节,其存储的起始地址只需要整除1,即任意起始都可以
C++不允许嵌套定义
C++中不允许对函数做嵌套定义,即在一个函数中不能定义另一个函数
return 语句
1、 return语句不可返回栈内存的 指针或是 引用,因为所占的栈内存在函数体结束时被自动销毁。
2、要搞清楚返回的究竟是 值 , 指针 还是 引用
3、如果函数返回值是一个对象,要考虑return语句的效率。比方说 return String(s1 + s2);的效率要优于String temp(s1 + s2); return temp; 这是因为编译器直接把临时对象创建并初始化在外部存储单元中,省去了拷贝和析构的步骤,提高了效率
空类的大小不是零
为了确保两个不同对象的地址不同,必须如此。也正因为如此,new返回的指针总是指向不同的单个对象。
class Empty { };
void f()
{
Empty a, b;
if (&a == &b) cout << "impossible: report error to compiler supplier";
Empty* p1 = new Empty;
Empty* p2 = new Empty;
if (p1 == p2) cout << "impossible: report error to compiler supplier";
}
C++中有一条有趣的规则——空基类并不需要另外一个字节来表示:
struct X : Empty {
int a;
// ...
};
void f(X* p)
{
void* p1 = p;
void* p2 = &p->a;
if (p1 == p2) cout << "nice: good optimizer";
}
如果上述代码中p1和p2相等,那么说明编译器作了优化。这样的优化是安全的,而且非常有用。它允许程序员用空类来表示非常简单的概念,而不需为此付出额外的(空间)代价。一些现代编译器提供了这种“虚基类优化”功能。
C++多继承所可能引发的“diamond problem
在多继承和 hierarchical inheritance我们不能够创建 hybrid inheritance
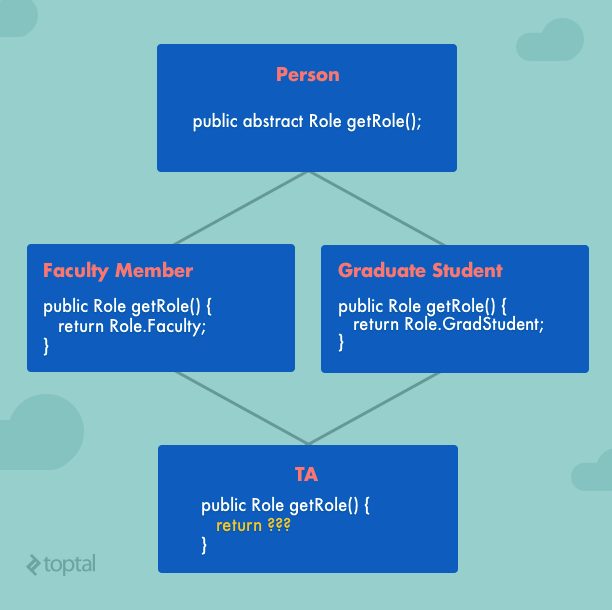
比方说上图中,Faculty Member和Graduate Student都是继承自Person这个类,而Teaching Assistant即是Faculty又是Graduate,因此在面对方法getRole的时候,便不知道应该使用哪一个了,解决方法是在TA中重写getRole,然后这样一来,它便隐藏了TA事实上的角色,即TA及时faculty member又是grad student。
It means that we cannot create hybrid inheritance using multiple and hierarchical inheritance. Let’s consider a simple example. A university has people who are affiliated with it. Some are students, some are faculty members, some are administrators, and so on. So a simple inheritance scheme might have different types of people in different roles, all of whom inherit from one common “Person” class. The Person class could define an abstract
getRole()method which would then be overridden by its subclasses to return the correct role type. But now what happens if we want to model the role of a Teaching Assistant (TA)? Typically, a TA is both a grad student and a faculty member. This yields the classic diamond problem of multiple inheritance and the resulting ambiguity regarding the TA’sgetRole()method: WhichgetRole()implementation should the TA inherit? That of the Faculty Member or that of the Grad Student? The simple answer might be to have the TA class override thegetRole()method and return newly-defined role called “TA”. But that answer is also imperfect as it would hide the fact that a TA is, in fact, both a faculty member and a grad student.
typedef typename
typedef typename _Mybase::value_type value_type;
typedef typename本身并不是一个整体,typename是用来修饰后面的名字的.对于上面的例子,typname告诉编译器value_type是类型,而不是_Mybase的静态成员。
typename here is letting the compiler know that
value_typeis a type and not a static member of_MyBase. the::is the scope of the type. It is kind of like “is in” sovalue_type“is in”_MyBase. or can also be thought of as contains.
禁止对象产生于堆中
禁止对象产生于堆中,可以从三个方面去考虑:
- 直接实例化对象
- 对象被实例化为继承类中的基类成分
- 对象被嵌于其他对象当中
具体实施的思路就是:堆内存的申请总是通过new来实施的,那么只要保证不调用new即可,那么可以重载operator new,并将其作为private,那么便会有如下的代码
class UPNumber {
private:
static void *operator new();
static void operator delete(void *ptr);
...
}
UPNumber n1; //Right
static UPNumber n2; //Right
UPNumber *ptr = new UPNumber; //Wrong
C++和Java的区别
- C++的析构函数会在对象被销毁时自动的调用。Java则拥有垃圾自动回收器。Java 所有的对象都是用 new 操作符建立在内存堆栈上,类似于 C++ 中的 new 操作符,但是当要释放该申请的内存空间时,Java 自动进行内存回收操作,C++ 需要程序员自己释放内存空间,并且 Java 中的内存回收是以线程的方式在后台运行的,利用空闲时间。
- C++支持运算符重载,多继承,指针,结构体,模版,联合。Java则没有。C++可以通过指针来直接访问内存。
- Java拥有内建的线程类可以用来创建新的线程,C++没有内建的线程类
- C++提供类goto可以用来跳跃到任何打label的地方,Java没有
- C++采用编译器,将源代码转换称为机器语言,因此,其运行的程序依赖平台。Java则是将源代码转换称为JVM bytecode,因此是可以跨平台的。
- 数据类型和类:Java 是完全面向对象的语言,所有函数和变量部必须是类的一部分。除了基本数据类型之外,其余的都作为类对象,包括数组。对象将数据和方法结合起来,把它们封装在类中,这样每个对象都可实现自己的特点和行为。而 C++ 允许将函数和变量定义为全局的。
- Java 运行在虚拟机上,和开发平台无关,C++ 直接编译成可执行文件,是否跨平台在于用到的编译器的特性是否有多平台的支持。
- C++ 可以直接编译成可执行文件,运行效率比 Java 高。
- Java 主要用来开发 Web 应用。
- C++ 主要用在嵌入式开发、网络、并发编程的方面。
Python vs C++
语言自身:Python 为脚本语言,解释执行,不需要经过编译;C++ 是一种需要编译后才能运行的语言,在特定的机器上编译后运行。
运行效率:C++ 运行效率高,安全稳定。原因:Python 代码和 C++ 最终都会变成 CPU 指令来跑,但一般情况下,比如反转和合并两个字符串,Python 最终转换出来的 CPU 指令会比 C++ 多很多。首先,Python 中涉及的内容比 C++ 多,经过了更多层,Python 中甚至连数字都是 object ;其次,Python 是解释执行的,和物理机 CPU 之间多了解释器这层,而 C++ 是编译执行的,直接就是机器码,编译的时候编译器又可以进行一些优化。
开发效率:Python 开发效率高。原因:Python 一两句代码就能实现的功能,C++ 往往需要更多的代码才能实现。
书写格式和语法不同:Python 的语法格式不同于其 C++ 定义声明才能使用,而且极其灵活,完全面向更上层的开发者。
std::size_t
size_t是unsigned integer,其作为sizeof操作符的返回类型。
64-bit systems when the index exceeds UINT_MAX or if it relies on 32-bit modular arithmetic.
在进行条件比较,比方说判断循环条件的比较当中,就很自然的会使用std::size_t本身。它可以承载任何object的最大的size(包含array)
但是如果只是想单纯的计数的话,那么使用机器自带的int或是unsigned int即可。
std::size_t is the unsigned integer type of the result of the sizeof operator as well as the sizeof… operator and the alignof operator A good rule of thumb is for anything that you need to compare in the loop condition against something that is naturally a
std::size_titself.std::size_tis the type of anysizeofexpression and as is guaranteed to be able to express the maximum size of any object (including any array) in C++. By extension it is also guaranteed to be big enough for any array index so it is a natural type for a loop by index over an array. If you are just counting up to a number then it may be more natural to use either the type of the variable that holds that number or anintorunsigned int(if large enough) as these should be a natural size for the machine.
struct attribute ((packed))
C/C++在创建结构体的时候,由于进行来内存对其操作,其所占用的内存大小往往比实际变量占用的要大一些。
当不想字节对其的时候,即可以加上attribute((packed))关键字,它可以让所定义的结构体按照紧凑排列的方式来占用内存。
#include <iostream>
struct test1 {
char ch;
int val;
};
struct __attribute__((__packed__)) test2 {
char ch;
int val;
};
int main()
{
cout << sizeof(test1) << endl;
cout << sizeof(test2) << endl;
}
//Result:
8
5
test1的结构体采用来4字节对其,因此char也占用来4字节的内存。
attribute((packed))在动态的更改结构体的大小,并通过内存来直接访问内部变量的时候非常的好用,比如redis的sds类型。
但是这样做会影响性能的下降
Yes, it will affect the performance of the program. Adding the padding means the compiler can use integer load instructions to read things from memory. Without the padding, the compiler must load things separately and do bit shifting to get the entire value. (Even if it’s x86 and this is done by the hardware, it still has to be done).
Most hardware handles most unaligned loads without a penalty. The exception to the rule is when the access straddles some kind of boundary: cache line, page, etc. Mentioning instructions is misleading. In particular, if the working set does not fit into the cache (not an unusual situation), the benefit of fewer DRAM transactions for a “compressed” array will probably outweigh the extra cache accesses. Doubly so for structures written to disk.
所以redis用在x86的服务器上没有什么问题,但是用在arm的设备中,就有可能存在问题。而嵌入式设备多是arm处理器。
“most”? Maybe if “most machines are x86” your statement has some chance of being true, but last I checked most machines are embedded systems, cell phones, etc.. On most hardware, unaligned access means the compiler must generate code that performs the loads/stores byte-by-byte, possibly with bitshifting and bitwise or to assemble values, to work with larger types. This is a huge penalty.
两个井号 ## 的含义
#define DEFINE_STAT(stat) \
struct FThreadSafeStaticStat<FStat_##Stat> StatPtr_##Stat
是用于连接用的预处理运算符
##is the preprocessor operator for concatenation.
DEFINE_STAT(foo)
//上面的式在会在编译前被转换成为如下的式子
struct FThreadSafeStaticStat<FStat_foo> StatPtr_foo
再看如下的例子
#include <stdio.h>
#define decode(s,t,u,m,p,e,d) m ## s ## u ## t
#define begin decode(a,n,i,m,a,t,e)
int begin()
{
printf("Stumped?\n");
}
//Output
Stumped?
在这个例子当中,并没有看到main函数,但是通过的编译,并且运行正常,那么preprocessor是如何处理这段程序的呢?
首先begin被替换成为decode(a,n,i,m,a,t,e)
接下来decode(a,n,i,m,a,t,e)被替换成为m ## a ## i ## n
m ## a ## i ## n被替换成为了main
所以begin实际上是变成了main,整个程序中便拥有了main函数
成员初始化列表
优点:
- 更高效:少了一次调用默认构造函数的过程。
- 有些场合必须要用初始化列表:
- 常量成员,因为常量只能初始化不能赋值,所以必须放在初始化列表里面
- 引用类型,引用必须在定义的时候初始化,并且不能重新赋值,所以也要写在初始化列表里面
- 没有默认构造函数的类类型,因为使用初始化列表可以不必调用默认构造函数来初始化
如何避免拷贝
如果将拷贝构造函数和赋值构造函数声明为private,但是对于类的成员函数和友元函数来说依然可以调用,达不到完全禁止类的对象被拷贝的目的,而且程序会出错,因为未对函数进行定义。
解决方法:
- 定义一个基类,将拷贝构造函数和赋值构造函数声明为私有private
- 派生类以private的方式继承基类。 ```cpp class Uncopyable { public: Uncopyable() {} ~Uncopyable() {}
private: Uncopyable(const Uncopyable &); // 拷贝构造函数 Uncopyable &operator=(const Uncopyable &); // 赋值构造函数 }; class A : private Uncopyable // 注意继承方式 { };
能够保证,在派生类 A 的成员函数和友元函数中无法进行拷贝操作,因为无法调用基类 Uncopyable 的拷贝构造函数或赋值构造函数。同样,在类的外部也无法进行拷贝操作。
<a name="1D0mB"></a>
#### 如何减少构造函数开销
在构造函数中使用类的初始化列表,会减少调用默认的构造函数产生的开销
```cpp
class A
{
private:
int val;
public:
A()
{
cout << "A()" << endl;
}
A(int tmp)
{
val = tmp;
cout << "A(int " << val << ")" << endl;
}
};
class Test1
{
private:
A ex;
public:
Test1() : ex(1) // 成员列表初始化方式
{
}
};
多继承可能出现的状况和解决方法
多重继承容易出现的问题:命名冲突和数据冗余问题。
#include <iostream>
using namespace std;
// 间接基类
class Base1
{
public:
int var1;
};
// 直接基类
class Base2 : public Base1
{
public:
int var2;
};
// 直接基类
class Base3 : public Base1
{
public:
int var3;
};
// 派生类
class Derive : public Base2, public Base3
{
public:
void set_var1(int tmp) { var1 = tmp; } // error: reference to 'var1' is ambiguous. 命名冲突
void set_var2(int tmp) { var2 = tmp; }
void set_var3(int tmp) { var3 = tmp; }
void set_var4(int tmp) { var4 = tmp; }
private:
int var4;
};
int main()
{
Derive d;
return 0;
}
从多个基类中继承了相同的构造函数(即形参数列表完全相同),则程序也将会产生错误。
解决方法一:声明出现冲突的成员变量来源于哪个类
// 直接基类
class Base2 : public Base1
{
public:
int var2;
};
// 直接基类
class Base3 : public Base1
{
public:
int var3;
};
// 派生类
class Derive : public Base2, public Base3
{
public:
void set_var1(int tmp) { Base2::var1 = tmp; } // 这里声明成员变量来源于类 Base2,当然也可以声明来源于类 Base3
void set_var2(int tmp) { var2 = tmp; }
void set_var3(int tmp) { var3 = tmp; }
void set_var4(int tmp) { var4 = tmp; }
private:
int var4;
};
int main()
{
Derive d;
return 0;
}
解决方法二:虚继承
使用虚继承的目的:保证存在命名冲突的成员变量在派生类中只保留一份,即使间接基类中的成员在派生类中只保留一份。在菱形继承关系中,间接基类称为虚基类,直接基类和间接基类之间的继承关系称为虚继承。
实现方式:在继承方式前面加上 virtual 关键字。
#include <iostream>
using namespace std;
// 间接基类,即虚基类
class Base1
{
public:
int var1;
};
// 直接基类
class Base2 : virtual public Base1 // 虚继承
{
public:
int var2;
};
// 直接基类
class Base3 : virtual public Base1 // 虚继承
{
public:
int var3;
};
// 派生类
class Derive : public Base2, public Base3
{
public:
void set_var1(int tmp) { var1 = tmp; }
void set_var2(int tmp) { var2 = tmp; }
void set_var3(int tmp) { var3 = tmp; }
void set_var4(int tmp) { var4 = tmp; }
private:
int var4;
};
int main()
{
Derive d;
return 0;
}

若有收获,就点个赞吧
0 人点赞
