在无向图中,DFS和BFS的关键点在于,需要维护一张表,用于记录该节点是否有过访问。
BFS
广度优先遍历的写法相对固定,我们不建议大家背代码、记模板。在深刻理解广度优先遍历的应用场景(找无权图的最短路径),借助「队列」实现的基础上,多做练习,写对代码就是自然而然的事情了。
在无权图中,由于广度优先遍历本身的特点,假设源点为 source,只有在遍历到 所有 距离源点 source 的距离为 d 的所有结点以后,才能遍历到所有 距离源点 source 的距离为 d + 1 的所有结点。也可以使用「两点之间、线段最短」这条经验来辅助理解如下结论:从源点 source 到目标结点 target 走直线走过的路径一定是最短的。
在图中,由于 图中存在环,和深度优先遍历一样,广度优先遍历也需要在遍历的时候记录已经遍历过的结点。特别注意:将结点添加到队列以后,一定要马上标记为「已经访问」,否则相同结点会重复入队,这一点在初学的时候很容易忽略。如果很难理解这样做的必要性,建议大家在代码中打印出队列中的元素进行调试:在图中,如果入队的时候不马上标记为「已访问」,相同的结点会重复入队,这是不对的。
另外一点还需要强调,广度优先遍历用于求解「无权图」的最短路径,因此一定要认清「无权图」这个前提条件。如果是带权图,就需要使用相应的专门的算法去解决它们。事实上,这些「专门」的算法的思想也都基于「广度优先遍历」的思想,我们为大家例举如下:
带权有向图、且所有权重都非负的单源最短路径问题:使用 Dijkstra 算法;
带权有向图的单源最短路径问题:Bellman-Ford 算法;
一个图的所有结点对的最短路径问题:Floy-Warshall 算法。
这里列出的以三位计算机科学家的名字命名的算法,大家可以在《算法导论》这本经典著作的第 24 章、第 25 章找到相关知识的介绍。值得说明的是:应用任何一种算法,都需要认清使用算法的前提,不满足前提直接套用算法是不可取的。深刻理解应用算法的前提,也是学习算法的重要方法。例如我们在学习「二分查找」算法、「滑动窗口」算法的时候,就可以问自己,这个问题为什么可以使用「二分查找」,为什么可以使用「滑动窗口」。我们知道一个问题可以使用「优先队列」解决,是什么样的需求促使我们想到使用「优先队列」,而不是「红黑树(平衡二叉搜索树)」,想清楚使用算法(数据结构)的前提更重要。
广度优先遍历可以用于「树」和「图」的问题的遍历;
广度优先遍历作用于「无权图」,得到的是「最短路径」。如果题目有让求「最小」、「最短」、「最少」,可以考虑这个问题是不是可以建立成一个「图形结构」或者「树形结构」,用「广度优先遍历」的思想求得「最小」、「最短」、「最少」的数值;
广度优先遍历作用于图论问题的时候,结点在加入队列以后标记为已经访问,否则会出现结点重复入队的情况。
二维平面上的搜索问题
完成「力扣」第 1091 题:二进制矩阵中的最短路径(中等);
友情提示:本节的例题是「四连通问题」,「力扣」第 1091 题是「八连通问题」,解题思路和代码编写非常类似。
完成「力扣」第 200 题:岛屿数量(中等):深度优先遍历、广度优先遍历、并查集;
完成「力扣」第 417 题:太平洋大西洋水流问题(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 130 题:被围绕的区域(中等):深度优先遍历、广度优先遍历、并查集;
完成「力扣」第 934 题:最短的桥(中等);
完成「力扣」第 529 题:扫雷游戏(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 1020 题:飞地的数量(中等):方法同第 130 题,深度优先遍历、广度优先遍历;
完成「力扣」第 1254 题:统计封闭岛屿的数目(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 1034 题:边框着色(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 733 题:图像渲染(简单):深度优先遍历、广度优先遍历;
完成「剑指 Offer 系列」第 13 题:机器人的运动范围(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 909 题:蛇梯棋(中等)广度优先遍历。
友情提示:题目问「最少移动次数」,如果这个问题是需要遍历的话,需要想到使用「广度优先遍历」。
抽象图论问题
在算法面试和笔试中,有一些问题问我们「最短」、「最少」、「最小」,可以尝试将它们转换为求解无权图的最短路径的问题求解。
对于这一类问题,最重要的一点在于分析出这一类问题的「图」结构,也就是对图形问题建模。依然是要注意到这些问题的背后是一个「无权图」的最短路径问题,因此可以使用「广度优先遍历」。
完成「力扣」第 22 题:括号生成(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 690 题:员工的重要性(中等);
完成「力扣」第 322 题:零钱兑换(中等):动态规划;
完成「力扣」第 365 题:水壶问题(中等);
完成「力扣」第 1306 题:跳跃游戏 III(中等)。
拓扑排序
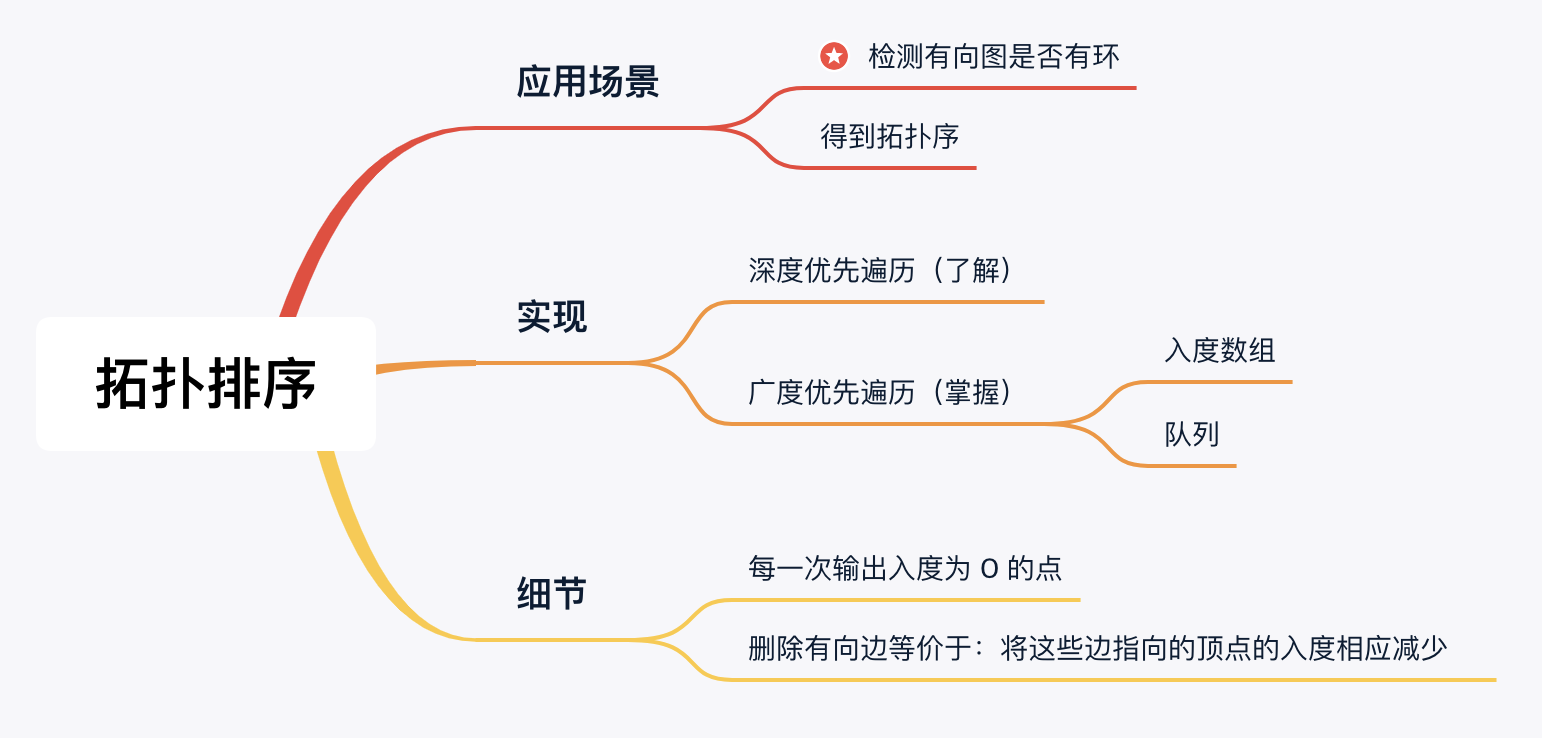
拓扑排序(Topological Sorting)是一种应用在「有向无环图(DAG,Directed Acyclic Graph)」上,给出结点输出先后顺序的算法。拓扑排序不是给出大小关系的排序,而是给出先后顺序的一种算法。这些结点的输出顺序需要保证:
每一个结点输出且仅输出一次;
在有向无环图中,如果存在一条从 u 到 v 的路径,那么在拓扑排序的结果中,u 必需保证在 v 的前面。
拓扑排序的经典应用是:课程安排和任务安排。以课程安排为例:《机器学习》这门课程的学习需要《微积分》、《线性代数》和《概率论与数理统计》作为基础。它们之间的关系可以用如下 有向图 表示。
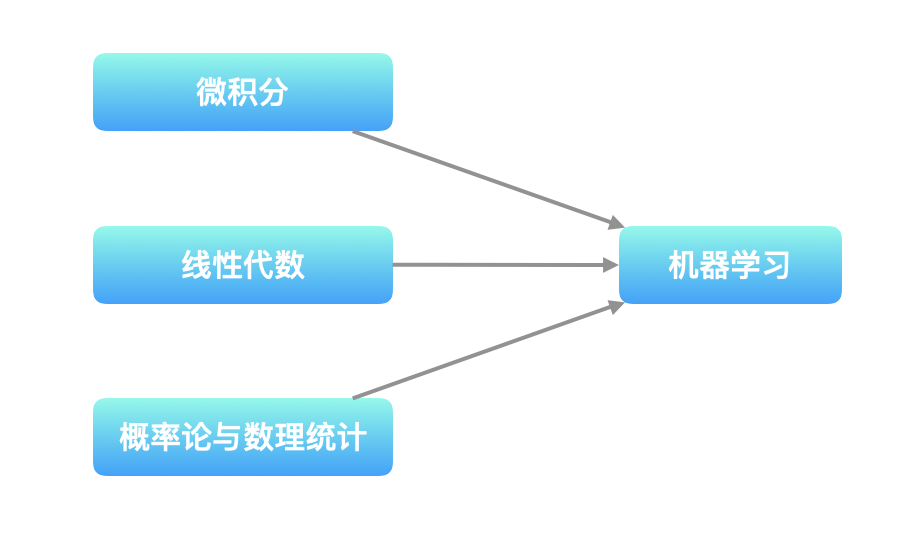
拓扑排序的结果不唯一,例如:[“微积分”, “线性代数”, “概率论与数理统计”, “机器学习”] 是一种拓扑排序的结果,[“概率论与数理统计”, “微积分”, “线性代数”, “机器学习”] 也是一种拓扑排序的结果。但一定保证「机器学习」安排在其它 33 门课程的后面。
只有在 有向无环图 中,才存在拓扑排序。这是因为:
「有向」是问题本身的要求,「有向」体现了完成一系列任务的先后顺序;
为什么要求「无环」呢?图中存在环,说明有循环依赖,这一点可以这样理解:在一个圆圈中,我们不能说谁就一定在谁的前面。
拓扑排序有两种实现:
深度优先遍历;
广度优先遍历。
我们在「深度优先遍历」专题中有介绍如何使用「深度优先遍历」得到拓扑排序,这种思路比较冷门,不要求深入学习。
事实上,拓扑排序的更经典的实现是「广度优先遍历」。广度优先遍历在思想层面上更简单,编码也相对容易。还有一个好处:我们一直向大家强调了只有「有向无环图」才存在拓扑排序:
用「深度优先遍历」得到拓扑序,须要在遍历的过程中检测有向图是否存在环;
而应用「广度优先遍历」,我们只需要在有向图中执行一次广度优先遍历,在结束以后,就能够得到这个有向图是不是存在环,在不存在环的时候,输出拓扑排序的结果。也就是说,广度优先遍历还可以帮助我们检测有向图是否存在环。
完成「力扣」第 207 题:课程表(中等);
完成「力扣」第 210 题:课程表 II(中等);
完成「力扣」第 301 题:最小高度树(中等);
完成「力扣」第 1245 题:树的直径(中等);
完成「力扣」第 802 题:找到最终的安全状态(中等);
完成「力扣」第 630 题:课程表 III(困难);
完成「力扣」第 1203 题:项目管理(困难)。
DFS
深度优先遍历 只要前面有可以走的路,就会一直向前走,直到无路可走才会回头;
「无路可走」有两种情况:① 遇到了墙;② 遇到了已经走过的路;
在「无路可走」的时候,沿着原路返回,直到回到了还有未走过的路的路口,尝试继续走没有走过的路径;
有一些路径没有走到,这是因为找到了出口,程序就停止了;
「深度优先遍历」也叫「深度优先搜索」,遍历是行为的描述,搜索是目的(用途);
遍历不是很深奥的事情,把 所有 可能的情况都看一遍,才能说「找到了目标元素」或者「没找到目标元素」。遍历也称为 穷举,穷举的思想在人类看来虽然很不起眼,但借助 计算机强大的计算能力,穷举可以帮助我们解决很多专业领域知识不能解决的问题。
「遍历」和「搜索」可以看作是两个的等价概念,通过遍历 所有 的可能的情况达到搜索的目的。遍历是手段,搜索是目的。因此「深度优先遍历」也叫「深度优先搜索」。
深度优先遍历有「回头」的过程,在树中由于不存在「环」(回路),对于每一个结点来说,每一个结点只会被递归处理一次。而「图」中由于存在「环」(回路),就需要 记录已经被递归处理的结点(通常使用布尔数组或者哈希表),以免结点被重复遍历到。
下面这些练习可能是大家在入门「树」这个专题的过程中做过的问题,以前我们在做这些问题的时候可以总结为:树的问题可以递归求解。现在我们可以用「深度优先遍历」的思想,特别是「后序遍历」的思想重新看待这些问题。
请大家通过这些问题体会 「如何设计递归函数的返回值」 帮助我们解决问题。并理解这些简单的问题其实都是「深度优先遍历」的思想中「后序遍历」思想的体现,真正程序在执行的时候,是通过「一层一层向上汇报」的方式,最终在根结点汇总整棵树遍历的结果。
完成「力扣」第 104 题:二叉树的最大深度(简单):设计递归函数的返回值;
完成「力扣」第 111 题:二叉树的最小深度(简单):设计递归函数的返回值;
完成「力扣」第 112 题:路径总和(简单):设计递归函数的返回值;
完成「力扣」第 226 题:翻转二叉树(简单):前中后序遍历、广度优先遍历均可,中序遍历有一个小小的坑;
完成「力扣」第 100 题:相同的树(简单):设计递归函数的返回值;
完成「力扣」第 101 题:对称二叉树(简单):设计递归函数的返回值;
完成「力扣」第 129 题:求根到叶子节点数字之和(中等):设计递归函数的返回值。
完成「力扣」第 236 题:二叉树的最近公共祖先(中等):使用后序遍历的典型问题。
请大家完成下面这些树中的问题,加深对前序遍历序列、中序遍历序列、后序遍历序列的理解。
完成「力扣」第 105 题:从前序与中序遍历序列构造二叉树(中等);
完成「力扣」第 106 题:从中序与后序遍历序列构造二叉树(中等);
完成「力扣」第 1008 题:前序遍历构造二叉搜索树(中等);
完成「力扣」第 1028 题:从先序遍历还原二叉树(困难)。
遍历可以用于搜索,思想是穷举,遍历是实现搜索的手段;
树的「前、中、后」序遍历都是深度优先遍历;
树的后序遍历很重要;
由于图中存在环(回路),图的深度优先遍历需要记录已经访问过的结点,以避免重复访问;
遍历是一种简单、朴素但是很重要的算法思想,很多树和图的问题就是在树和图上执行一次遍历,在遍历的过程中记录有用的信息,得到需要结果,区别在于为了解决不同的问题,在遍历的时候传递了不同的 与问题相关 的数据。

在深度优先遍历的过程中,需要将 当前遍历到的结点 的相邻结点 暂时保存 起来,以便在回退的时候可以继续访问它们。遍历到的结点的顺序呈现「后进先出」的特点,因此 深度优先遍历可以通过「栈」实现。
再者,深度优先遍历有明显的递归结构。我们知道支持递归实现的数据结构也是栈。因此实现深度优先遍历有以下两种方式:
编写递归方法;
编写栈,通过迭代的方式实现。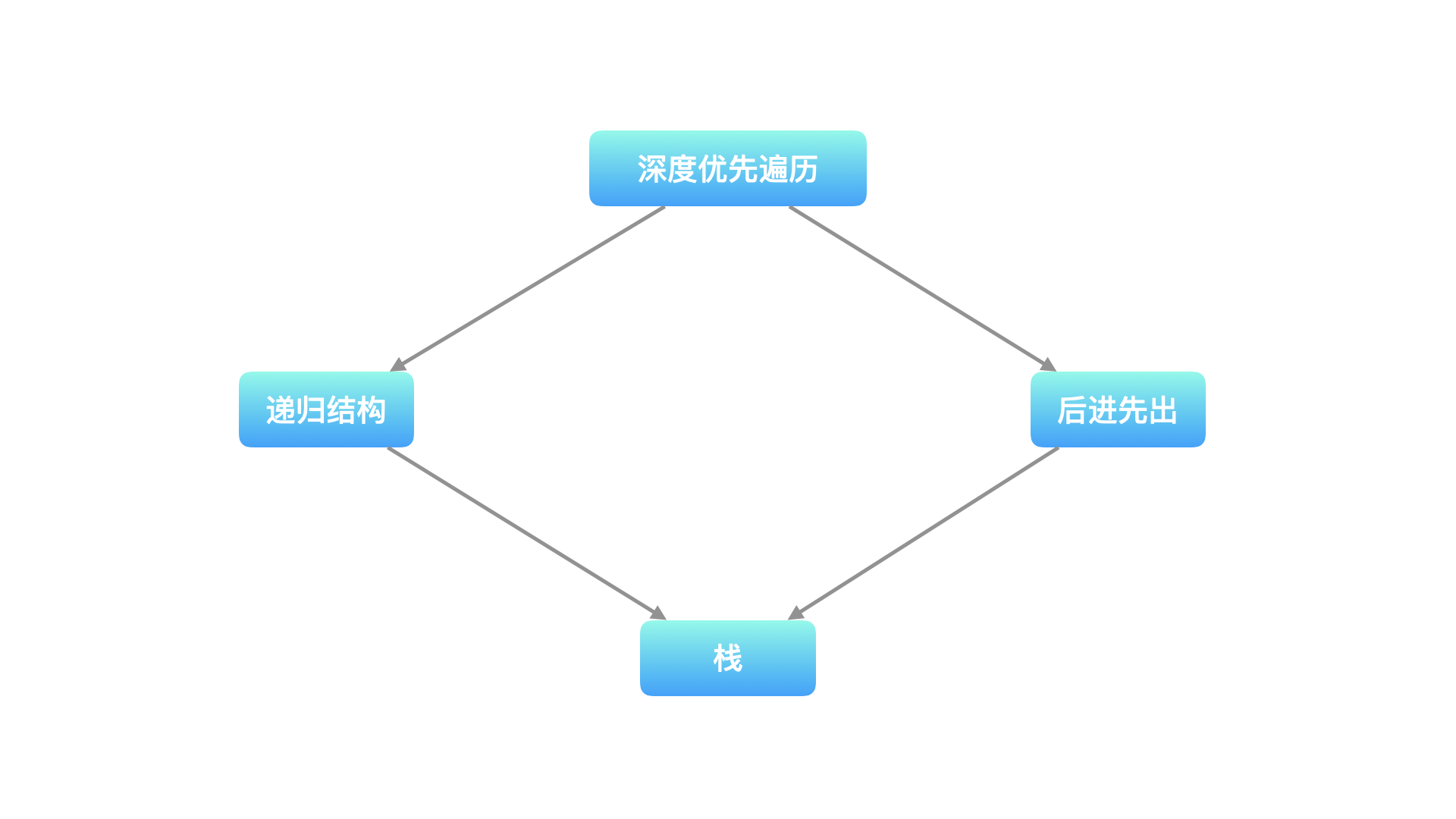
前序遍历栈模拟方式
import java.util.ArrayDeque;import java.util.ArrayList;import java.util.Deque;import java.util.List;public class Solution {private enum Action {/*** 如果当前结点有孩子结点(左右孩子结点至少存在一个),执行 GO*/GO,/*** 添加到结果集(真正输出这个结点)*/ADDTORESULT}private class Command {private Action action;private TreeNode node;/*** 将动作类与结点类封装起来** @param action* @param node*/public Command(Action action, TreeNode node) {this.action = action;this.node = node;}}public List<Integer> preorderTraversal(TreeNode root) {List<Integer> res = new ArrayList<>();if (root == null) {return res;}Deque<Command> stack = new ArrayDeque<>();stack.addLast(new Command(Action.GO, root));while (!stack.isEmpty()) {Command command = stack.removeLast();if (command.action == Action.ADDTORESULT) {res.add(command.node.val);} else {// 特别注意:以下的顺序与递归执行的顺序反着来,即:倒过来写的结果// 前序遍历:根结点、左子树、右子树、// 添加到栈的顺序:右子树、左子树、根结点if (command.node.right != null) {stack.add(new Command(Action.GO, command.node.right));}if (command.node.left != null) {stack.add(new Command(Action.GO, command.node.left));}stack.add(new Command(Action.ADDTORESULT, command.node));}}return res;}}
中序遍历栈模拟
import java.util.ArrayDeque;import java.util.ArrayList;import java.util.Deque;import java.util.List;public class Solution {private enum Action {/*** 如果当前结点有孩子结点(左右孩子结点至少存在一个),执行 GO*/GO,/*** 添加到结果集(真正输出这个结点)*/ADDTORESULT}private class Command {private Action action;private TreeNode node;/*** 将动作类与结点类封装起来** @param action* @param node*/public Command(Action action, TreeNode node) {this.action = action;this.node = node;}}public List<Integer> inorderTraversal(TreeNode root) {List<Integer> res = new ArrayList<>();if (root == null) {return res;}Deque<Command> stack = new ArrayDeque<>();stack.addLast(new Command(Action.GO, root));while (!stack.isEmpty()) {Command command = stack.removeLast();if (command.action == Action.ADDTORESULT) {res.add(command.node.val);} else {// 特别注意:以下的顺序与递归执行的顺序反着来,即:倒过来写的结果// 中序遍历:左子树、根结点、右子树、// 添加到栈的顺序:右子树、根结点、左子树if (command.node.right != null) {stack.add(new Command(Action.GO, command.node.right));}stack.add(new Command(Action.ADDTORESULT, command.node));if (command.node.left != null) {stack.add(new Command(Action.GO, command.node.left));}}}return res;}}
后序遍历栈模拟
import java.util.ArrayDeque;import java.util.ArrayList;import java.util.Deque;import java.util.List;public class Solution {private enum Action {/*** 如果当前结点有孩子结点(左右孩子结点至少存在一个),执行 GO*/GO,/*** 添加到结果集(真正输出这个结点)*/ADDTORESULT}private class Command {private Action action;private TreeNode node;/*** 将动作类与结点类封装起来** @param action* @param node*/public Command(Action action, TreeNode node) {this.action = action;this.node = node;}}public List<Integer> postorderTraversal(TreeNode root) {List<Integer> res = new ArrayList<>();if (root == null) {return res;}Deque<Command> stack = new ArrayDeque<>();stack.addLast(new Command(Action.GO, root));while (!stack.isEmpty()) {Command command = stack.removeLast();if (command.action == Action.ADDTORESULT) {res.add(command.node.val);} else {assert command.action == Action.GO;// 特别注意:以下的顺序与递归执行的顺序反着来,即:倒过来写的结果// 后序遍历:左子树、右子树、根结点// 添加到栈的顺序:根结点、右子树、左子树stack.addLast(new Command(Action.ADDTORESULT, command.node));if (command.node.right != null) {stack.addLast(new Command(Action.GO, command.node.right));}if (command.node.left != null) {stack.addLast(new Command(Action.GO, command.node.left));}}}return res;}}
深度优先遍历通过「栈」实现;
深度优先遍历符合「后进先出」规律,可以借助「栈」实现;
深度优先遍历有明显的「递归」结构,递归也是借助「栈」实现的;
因此深度优先遍历一般通过「递归」实现,底层借助了「栈」这个数据结构作为支持;
栈虽然结构(数组或者链表)和规则定义简单(后进先出),但是它在算法的世界里发挥了巨大的作用;
比较递归与非递归实现:我们用一张表格来比较「递归」和「栈」实现「深度优先遍历」的优缺点。
回溯法
https://www.yuque.com/renshengxiaoquexing/gmh4be/wtt95i
回溯算法是一种通过不断 尝试 ,搜索一个问题的一个解或者 所有解 的方法。在求解的过程中,如果继续求解不能得到题目要求的结果,就需要 回退 到上一步尝试新的求解路径。回溯算法的核心思想是:在一棵 隐式的树(看不见的树) 上进行一次深度优先遍历。
剪枝法
剪枝的想法是很自然的。回溯算法本质上是遍历算法,如果 在遍历的过程中,可以分析得到这样一条分支一定不存在需要的结果,就可以跳过这个分支。
发现剪枝条件依然是通过举例的例子,画图分析,即:通过具体例子抽象出一般的剪枝规则。通常可以选取一些较典型的例子,以便抽象出一般规律。
二维平面的搜索问题
完成「力扣」第 130 题:被围绕的区域(中等);深度优先遍历、广度优先遍历、并查集。
完成「力扣」第 200 题:岛屿数量(中等):深度优先遍历、广度优先遍历、并查集;
完成「力扣」第 417 题:太平洋大西洋水流问题(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 1020 题:飞地的数量(中等):方法同第 130 题,深度优先遍历、广度优先遍历;
完成「力扣」第 1254 题:统计封闭岛屿的数目(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 1034 题:边框着色(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 133 题:克隆图(中等):借助哈希表,使用深度优先遍历、广度优先遍历;
完成「剑指 Offer」第 13 题:机器人的运动范围(中等):深度优先遍历、广度优先遍历;
完成「力扣」第 529 题:扫雷问题(中等):深度优先遍历、广度优先遍历;
动态规划和深度优先遍历思想相结合
在动态规划问题里,有一类问题叫做「树形动态规划 DP」问题。这一类问题通常的解决的思路是:通过对树结构执行一次深度优先遍历,采用 后序遍历 的方式,一层一层向上传递信息,并且利用「无后效性」的思想(固定住一些状态,或者对当前维度进行升维)解决问题。即这一类问题通常采用「后序遍历」 + 「动态规划(无后效性)」的思路解决。
完成「力扣」第 124 题:二叉树中的最大路径和(困难);
完成「力扣」第 298 题:二叉树最长连续序列(中等);
完成「力扣」第 549 题:二叉树中最长的连续序列(中等);
完成「力扣」第 687 题:最长同值路径(中等);
完成「力扣」第 865 题:具有所有最深节点的最小子树(中等);
完成「力扣」第 1372 题:二叉树中的最长交错路径(中等)。
下面的问题可以使用「二分答案 + DFS 或者 BFS」的思想解决。
完成「力扣」第 1102 题:得分最高的路径(中等);
完成「力扣」第 1631 题:最小体力消耗路径(中等);
完成「力扣」第 778 题:水位上升的泳池中游泳(困难);
完成「力扣」第 403 题:青蛙过河(困难)。
例题
完成「力扣」第 40 题:组合总和 II(中等);
完成「力扣」第 78 题:子集(中等);
完成「力扣」第 90 题:子集 II(中等)。
完成「力扣」第 1593 题:拆分字符串使唯一子字符串的数目最大(中等);
完成「力扣」第 1079 题:活字印刷(中等)。
力扣133 克隆图
133. 克隆图
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node { public int val; public List
neighbors; } 测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
输入:adjList = [[2,4],[1,3],[2,4],[1,3]] 输出:[[2,4],[1,3],[2,4],[1,3]] 解释: 图中有 4 个节点。 节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 节点 4 的值是 4,它有两个邻居:节点 1 和 3 。 示例 2:
输入:adjList = [[]] 输出:[[]] 解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。 示例 3:
输入:adjList = [] 输出:[] 解释:这个图是空的,它不含任何节点。 示例 4:
输入:adjList = [[2],[1]] 输出:[[2],[1]]
提示:
节点数不超过 100 。 每个节点值 Node.val 都是唯一的,1 <= Node.val <= 100。 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。 图是连通图,你可以从给定节点访问到所有节点。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/clone-graph 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
方法一:深度优先搜索
思路
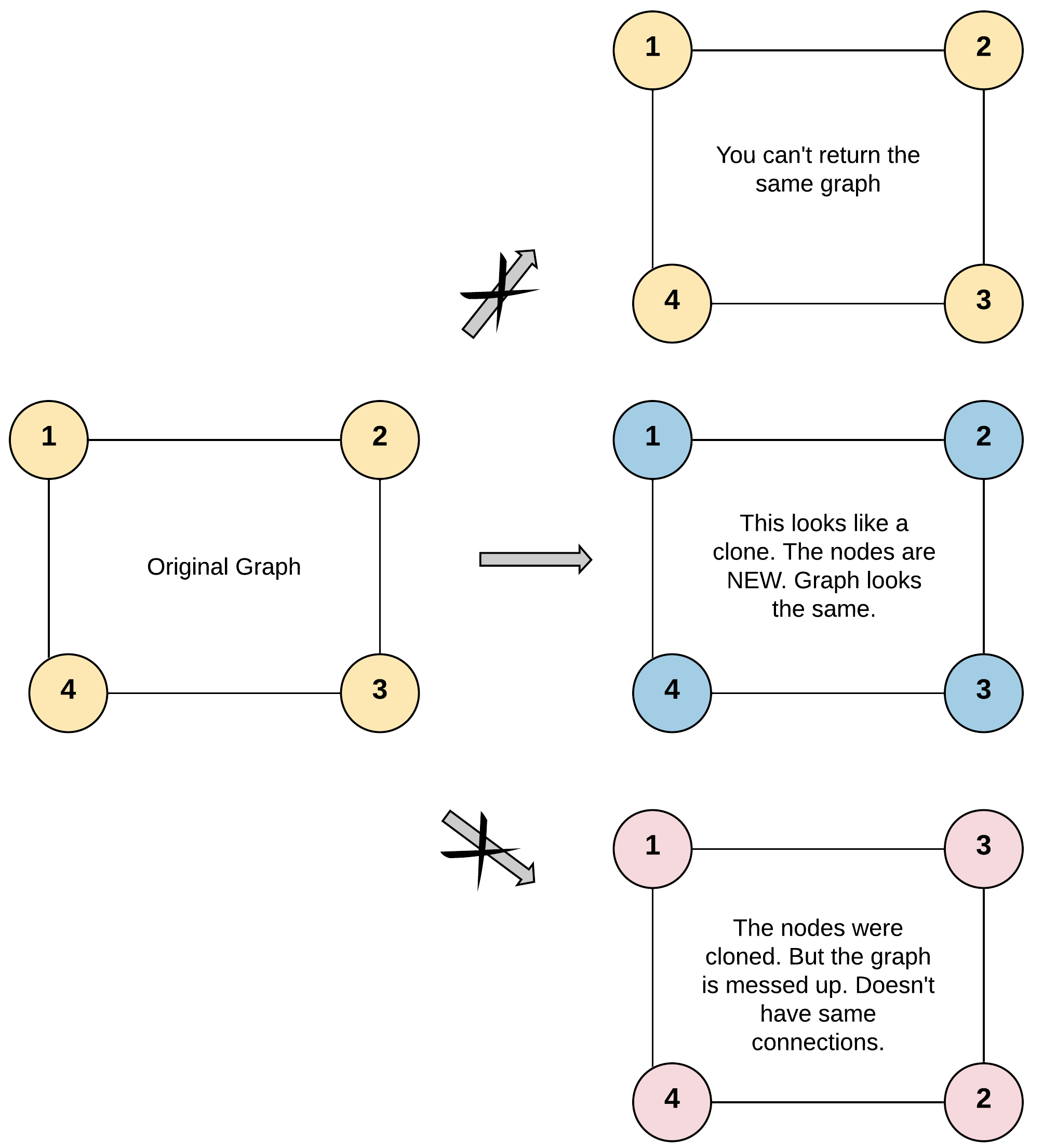
对于本题而言,我们需要明确图的深拷贝是在做什么,对于一张图而言,它的深拷贝即构建一张与原图结构,值均一样的图,但是其中的节点不再是原来图节点的引用。因此,为了深拷贝出整张图,我们需要知道整张图的结构以及对应节点的值。
由于题目只给了我们一个节点的引用,因此为了知道整张图的结构以及对应节点的值,我们需要从给定的节点出发,进行「图的遍历」,并在遍历的过程中完成图的深拷贝。
为了避免在深拷贝时陷入死循环,我们需要理解图的结构。对于一张无向图,任何给定的无向边都可以表示为两个有向边,即如果节点 A 和节点 B 之间存在无向边,则表示该图具有从节点 A 到节点 B 的有向边和从节点 B 到节点 A 的有向边。
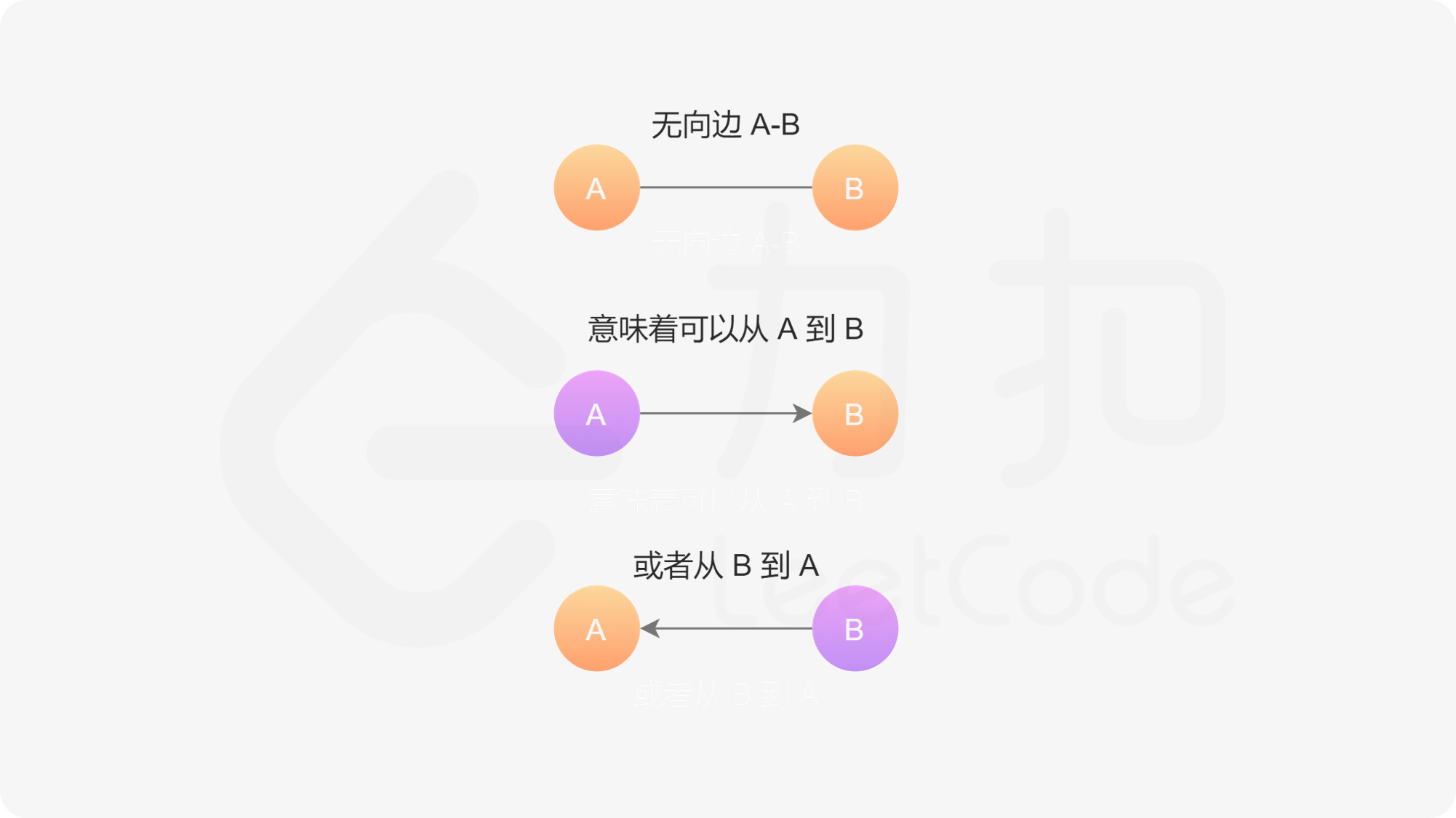
为了防止多次遍历同一个节点,陷入死循环,我们需要用一种数据结构记录已经被克隆过的节点。
算法
使用一个哈希表存储所有已被访问和克隆的节点。哈希表中的 key 是原始图中的节点,value 是克隆图中的对应节点。
从给定节点开始遍历图。如果某个节点已经被访问过,则返回其克隆图中的对应节点。
如下图,我们给定无向边边 A - B,表示 A 能连接到 B,且 B 能连接到 A。如果不对访问过的节点做标记,则会陷入死循环中。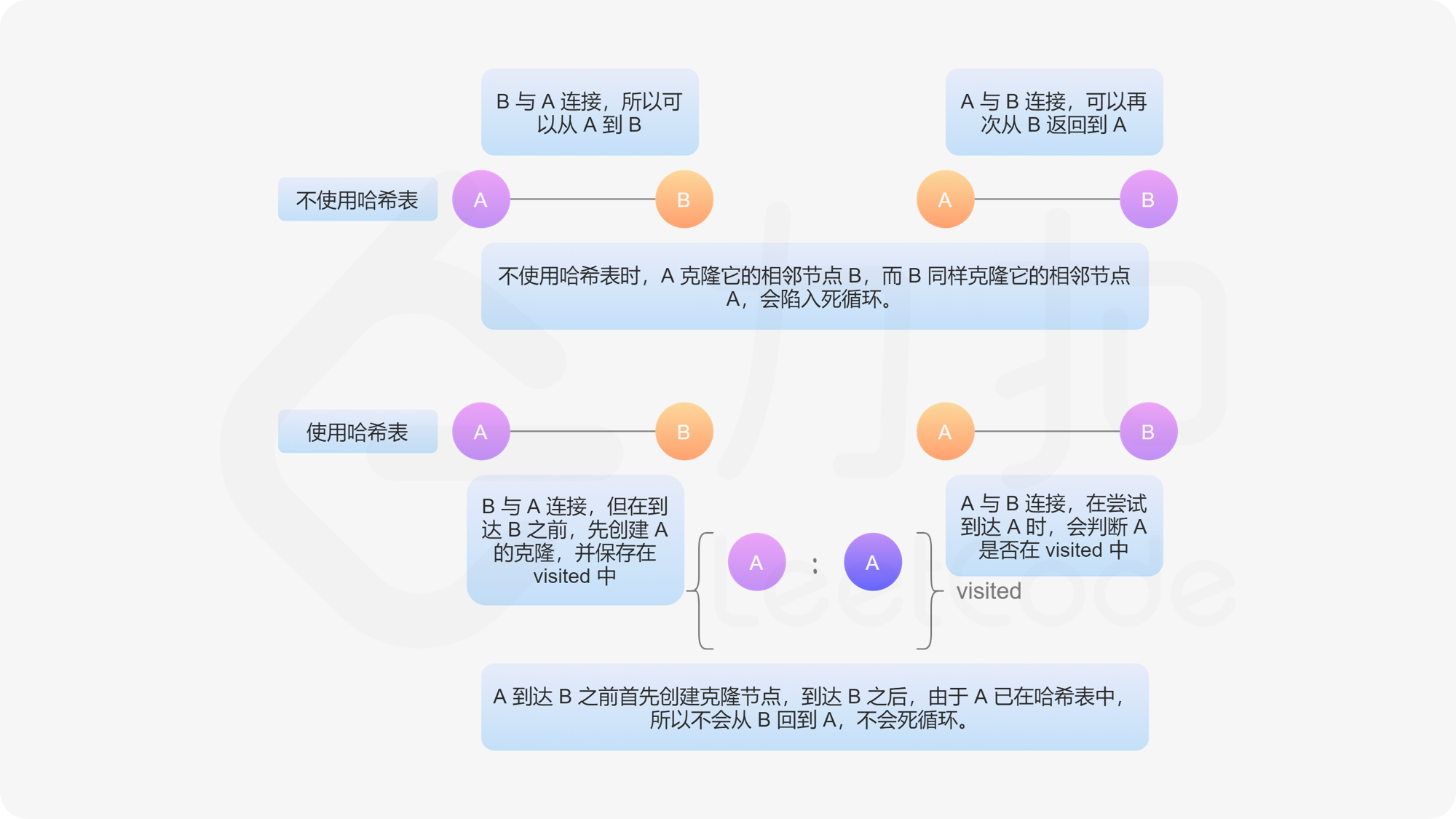
如果当前访问的节点不在哈希表中,则创建它的克隆节点并存储在哈希表中。注意:在进入递归之前,必须先创建克隆节点并保存在哈希表中。如果不保证这种顺序,可能会在递归中再次遇到同一个节点,再次遍历该节点时,陷入死循环。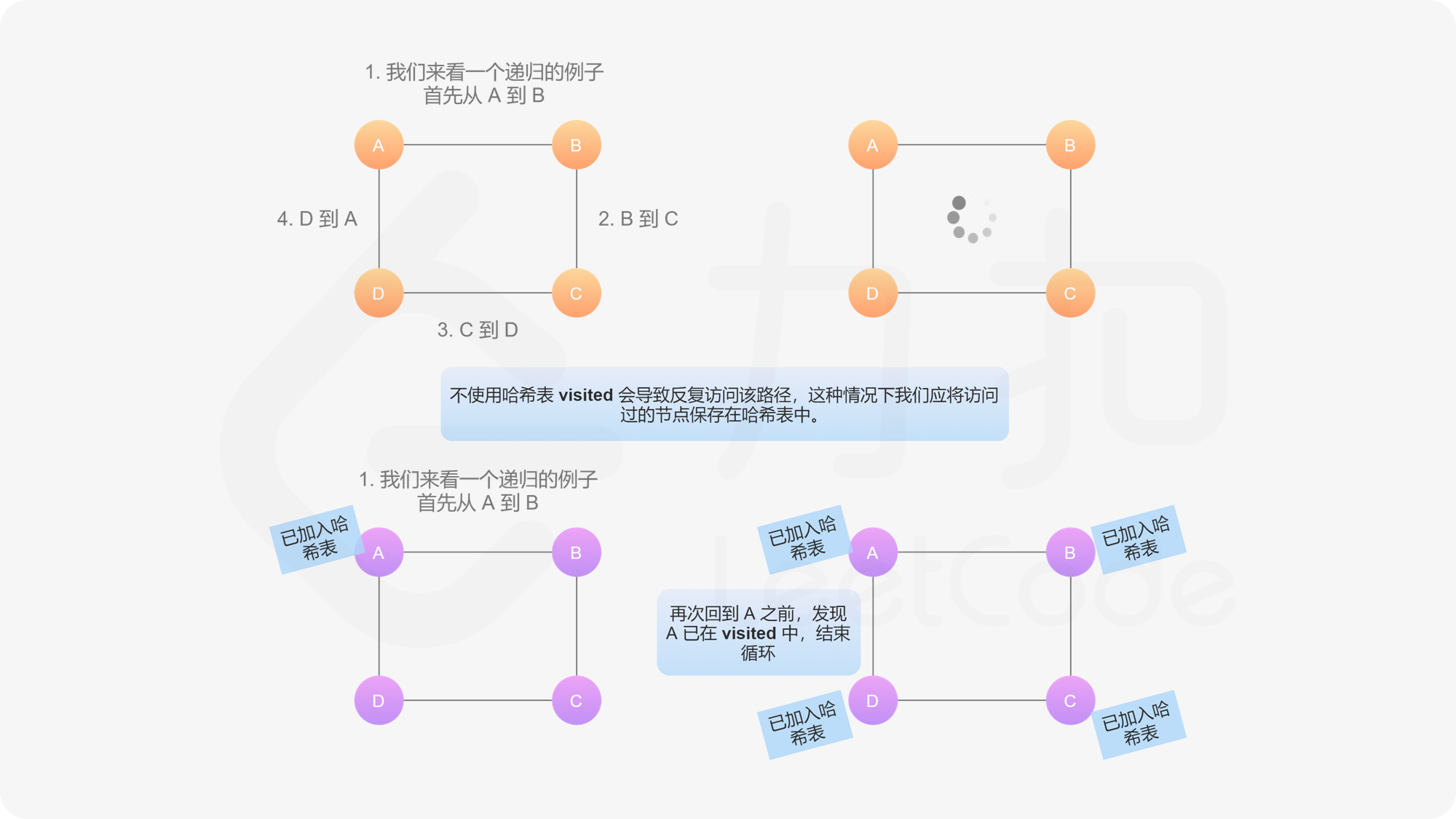
递归调用每个节点的邻接点。每个节点递归调用的次数等于邻接点的数量,每一次调用返回其对应邻接点的克隆节点,最终返回这些克隆邻接点的列表,将其放入对应克隆节点的邻接表中。这样就可以克隆给定的节点和其邻接点。
class Solution {public:unordered_map<Node*, Node*> visited;Node* cloneGraph(Node* node) {if (node == nullptr) {return node;}// 如果该节点已经被访问过了,则直接从哈希表中取出对应的克隆节点返回if (visited.find(node) != visited.end()) {return visited[node];}// 克隆节点,注意到为了深拷贝我们不会克隆它的邻居的列表Node* cloneNode = new Node(node->val);// 哈希表存储visited[node] = cloneNode;// 遍历该节点的邻居并更新克隆节点的邻居列表for (auto& neighbor: node->neighbors) {cloneNode->neighbors.emplace_back(cloneGraph(neighbor));}return cloneNode;}};作者:LeetCode-Solution链接:https://leetcode-cn.com/problems/clone-graph/solution/ke-long-tu-by-leetcode-solution/来源:力扣(LeetCode)著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析
时间复杂度:O(N),其中 NN 表示节点数量。深度优先搜索遍历图的过程中每个节点只会被访问一次。
空间复杂度:O(N)。存储克隆节点和原节点的哈希表需要 O(N) 的空间,递归调用栈需要 O(H)的空间,其中 H是图的深度,经过放缩可以得到 O(H)=O(N),因此总体空间复杂度为 O(N)。
方法二:广度优先遍历
思路
同样,我们也可以用广度优先搜索来进行「图的遍历」。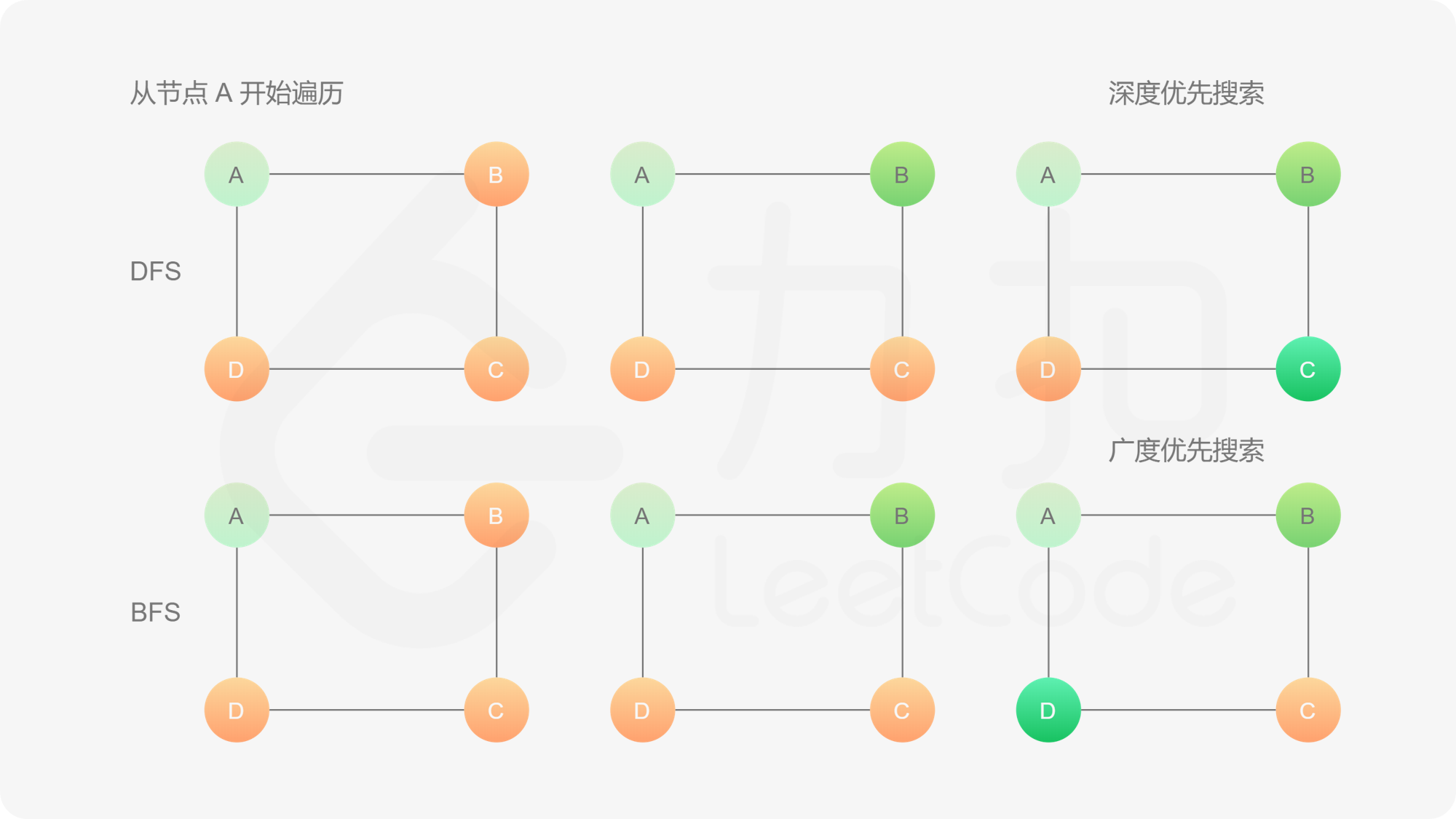
方法一与方法二的区别仅在于搜索的方式。深度优先搜索以深度优先,广度优先搜索以广度优先。这两种方法都需要借助哈希表记录被克隆过的节点来避免陷入死循环。
算法
使用一个哈希表 visited 存储所有已被访问和克隆的节点。哈希表中的 key 是原始图中的节点,value 是克隆图中的对应节点。
将题目给定的节点添加到队列。克隆该节点并存储到哈希表中。
每次从队列首部取出一个节点,遍历该节点的所有邻接点。如果某个邻接点已被访问,则该邻接点一定在 visited 中,那么从 visited 获得该邻接点,否则创建一个新的节点存储在 visited 中,并将邻接点添加到队列。将克隆的邻接点添加到克隆图对应节点的邻接表中。重复上述操作直到队列为空,则整个图遍历结束。
class Solution {
public:
Node* cloneGraph(Node* node) {
if (node == nullptr) {
return node;
}
unordered_map<Node*, Node*> visited;
// 将题目给定的节点添加到队列
queue<Node*> Q;
Q.push(node);
// 克隆第一个节点并存储到哈希表中
visited[node] = new Node(node->val);
// 广度优先搜索
while (!Q.empty()) {
// 取出队列的头节点
auto n = Q.front();
Q.pop();
// 遍历该节点的邻居
for (auto& neighbor: n->neighbors) {
if (visited.find(neighbor) == visited.end()) {
// 如果没有被访问过,就克隆并存储在哈希表中
visited[neighbor] = new Node(neighbor->val);
// 将邻居节点加入队列中
Q.push(neighbor);
}
// 更新当前节点的邻居列表
visited[n]->neighbors.emplace_back(visited[neighbor]);
}
}
return visited[node];
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/clone-graph/solution/ke-long-tu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
复杂度分析
时间复杂度:O(N),其中 NN 表示节点数量。广度优先搜索遍历图的过程中每个节点只 会被访问一次。
空间复杂度:O(N)。哈希表使用 O(N)的空间。广度优先搜索中的队列在最坏情况下会达到 O(N)的空间复杂度,因此总体空间复杂度为 O(N)。
力扣102 二叉树的层序遍历
102. 二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3/ \
9 20
/ \15 7
返回其层序遍历结果:
[
[3],
[9,20],
[15,7]
]
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
采用两个队列来一层层的按照从左到右的将节点插入序列中。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>>ret;
if(root == nullptr)
return ret;
queue<TreeNode*>level1;
queue<TreeNode*>level2;
level1.push(root);
while(!level1.empty() || !level2.empty())
{
vector<int>tmp;
while(!level1.empty())
{
TreeNode *tmpNode = level1.front();
level1.pop();
tmp.emplace_back(tmpNode->val);
if(tmpNode->left != nullptr)
level2.push(tmpNode->left);
if(tmpNode->right != nullptr)
level2.push(tmpNode->right);
}
ret.emplace_back(tmp);
if(level2.empty())
break;
tmp.clear();
while(!level2.empty())
{
TreeNode *tmpNode = level2.front();
level2.pop();
tmp.emplace_back(tmpNode->val);
if(tmpNode->left != nullptr)
level1.push(tmpNode->left);
if(tmpNode->right != nullptr)
level1.push(tmpNode->right);
}
ret.emplace_back(tmp);
}
return ret;
}
};
力扣417 太平洋大西洋水流问题
417. 太平洋大西洋水流问题
给定一个 m x n 的非负整数矩阵来表示一片大陆上各个单元格的高度。“太平洋”处于大陆的左边界和上边界,而“大西洋”处于大陆的右边界和下边界。
规定水流只能按照上、下、左、右四个方向流动,且只能从高到低或者在同等高度上流动。
请找出那些水流既可以流动到“太平洋”,又能流动到“大西洋”的陆地单元的坐标。
提示:
输出坐标的顺序不重要
m 和 n 都小于150
示例:
给定下面的 5x5 矩阵:
太平洋 ~ ~ ~ ~ ~
~ 1 2 2 3 (5) * ~ 3 2 3 (4) (4) * ~ 2 4 (5) 3 1 * ~ (6) (7) 1 4 5 * ~ (5) 1 1 2 4 * * * * * * 大西洋返回:
[[0, 4], [1, 3], [1, 4], [2, 2], [3, 0], [3, 1], [4, 0]] (上图中带括号的单元).
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/pacific-atlantic-water-flow
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
维护两张列表,一张列表存储的是能够流到太平洋的水流,另外一张列表存储的是能够流到大西洋的水流,比较两张列表,重合的部分便是既可以流到太平洋的水流又是可以流到大西洋的水流。
在具体实现中,可以维护两个队列通过BFS分别搜寻到可以流到太平洋的水流和可以流到大西洋的水流,两个列表的初始值分别是和太平洋以及大西洋相邻的边界。
class Solution:
def pacificAtlantic(self, matrix: List[List[int]]) -> List[List[int]]:
# Check if input is empty
if not matrix or not matrix[0]:
return []
num_rows, num_cols = len(matrix), len(matrix[0])
# Setup each queue with cells adjacent to their respective ocean
pacific_queue = deque()
atlantic_queue = deque()
for i in range(num_rows):
pacific_queue.append((i, 0))
atlantic_queue.append((i, num_cols - 1))
for i in range(num_cols):
pacific_queue.append((0, i))
atlantic_queue.append((num_rows - 1, i))
def bfs(queue):
reachable = set()
while queue:
(row, col) = queue.popleft()
# This cell is reachable, so mark it
reachable.add((row, col))
for (x, y) in [(1, 0), (0, 1), (-1, 0), (0, -1)]: # Check all 4 directions
new_row, new_col = row + x, col + y
# Check if the new cell is within bounds
if new_row < 0 or new_row >= num_rows or new_col < 0 or new_col >= num_cols:
continue
# Check that the new cell hasn't already been visited
if (new_row, new_col) in reachable:
continue
# Check that the new cell has a higher or equal height,
# So that water can flow from the new cell to the old cell
if matrix[new_row][new_col] < matrix[row][col]:
continue
# If we've gotten this far, that means the new cell is reachable
queue.append((new_row, new_col))
return reachable
# Perform a BFS for each ocean to find all cells accessible by each ocean
pacific_reachable = bfs(pacific_queue)
atlantic_reachable = bfs(atlantic_queue)
# Find all cells that can reach both oceans, and convert to list
return list(pacific_reachable.intersection(atlantic_reachable))
力扣130 被围绕的区域
130. 被围绕的区域
给定一个二维的矩阵,包含 ‘X’ 和 ‘O’(字母 O)。
找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
示例:
X X X X X O O X X X O X X O X X 运行你的函数后,矩阵变为:
X X X X X X X X X X X X X O X X 解释:
被围绕的区间不会存在于边界上,换句话说,任何边界上的 ‘O’ 都不会被填充为 ‘X’。 任何不在边界上,或不与边界上的 ‘O’ 相连的 ‘O’ 最终都会被填充为 ‘X’。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/surrounded-regions 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
BFS和DFS应该找到应该从哪点开始进行BFS和DFS,比如这道题,其判断条件就是值为O
class Solution {
public:
int n, m;
void dfs(vector<vector<char>>& board, int x, int y) {
if (x < 0 || x >= n || y < 0 || y >= m || board[x][y] != 'O') {
return;
}
board[x][y] = 'A';
dfs(board, x + 1, y);
dfs(board, x - 1, y);
dfs(board, x, y + 1);
dfs(board, x, y - 1);
}
void solve(vector<vector<char>>& board) {
n = board.size();
if (n == 0) {
return;
}
m = board[0].size();
for (int i = 0; i < n; i++) {
dfs(board, i, 0);
dfs(board, i, m - 1);
}
for (int i = 1; i < m - 1; i++) {
dfs(board, 0, i);
dfs(board, n - 1, i);
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (board[i][j] == 'A') {
board[i][j] = 'O';
} else if (board[i][j] == 'O') {
board[i][j] = 'X';
}
}
}
}
};
力扣279 完全平方数
279. 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, …)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9
提示:
1 <= n <= 104
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/perfect-squares
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解决递归中堆栈溢出的问题的一个思路就是使用动态规划(DP)技术,该技术建立在重用中间解的结果来计算终解的思想之上。
class Solution {
public:
int numSquares(int n) {
if(n == 0)
return 0;
vector<int>square(n+1, INT_MAX);
square[0] = 0;
for(int i = 1; i <= n; i++)
{
for(int j = 1; j * j <= i; j++)
{
square[i] = min(square[i], square[i - j*j] + 1);
}
}
return square[n];
}
};
力扣1136 平行课程
1136. 平行课程
已知有 N 门课程,它们以 1 到 N 进行编号。
给你一份课程关系表 relations[i] = [X, Y],用以表示课程 X 和课程 Y 之间的先修关系:课程 X 必须在课程 Y 之前修完。
假设在一个学期里,你可以学习任何数量的课程,但前提是你已经学习了将要学习的这些课程的所有先修课程。
请你返回学完全部课程所需的最少学期数。
如果没有办法做到学完全部这些课程的话,就返回 -1。
示例 1:
输入:N = 3, relations = [[1,3],[2,3]]
输出:2
解释:
在第一个学期学习课程 1 和 2,在第二个学期学习课程 3。
示例 2:
输入:N = 3, relations = [[1,2],[2,3],[3,1]]
输出:-1
解释:
没有课程可以学习,因为它们相互依赖。
提示:
1 <= N <= 5000
1 <= relations.length <= 5000
relations[i][0] != relations[i][1]
输入中没有重复的关系
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/parallel-courses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
这题其实是典型的有优先级限制的调度问题,我们可以使用拓扑排序来解决这样的问题。
我们知道只有当一门课程没有前置课程的时候,才能上这门课。我们可以把这门课程需要上的前置课程的数量表示为入度。比如上图中 0 的入度为 0,没有前置课程需要上,而 3 的入度为 2,有 1 和 2 需要上。所以我们可以每一次遍历把所有入度为 0 的课程上完,并且把他们的后置课程的入度减 1,重复这个过程直到没有课程可以上。
算法
初始化所有课程的入度 preClassCount和直接后置课程 nextClasses。
初始化 term 记录一共遍历了几次,一次代表一个学期。
找出所有入度为 0 的课程,记录为已学习 learn。
将所有这学期已学习的课程的直接后置课程的入度减 1。
重复第三步直到所有课程已经学完,或者这个学期不能学习任何课程。
在进入正式实现之前,先让我们通过示例图查看算法的运行过程。
class Solution {
public:
int minimumSemesters(int N, vector<vector<int>>& relations) {
int in[N] = {0};
vector<vector<int>> edges(N);
for (auto relation : relations) {
int x = relation[0] - 1;
int y = relation[1] - 1;
edges[x].push_back(y);
edges[y].push_back(x);
++in[y];
}
auto cur_semester = new vector<int>;
for (int i = 0; i != N; ++i)
if (in[i] == 0)
cur_semester -> push_back(i);
int term = 0;
while (!cur_semester -> empty()) {
auto next_semester = new vector<int>;
for (int cur_class : *cur_semester)
for (int next_class : edges[cur_class]) {
if (0 == --in[next_class])
next_semester -> push_back(next_class);
}
delete cur_semester;
cur_semester = next_semester;
++term;
}
for (int n : in)
if (n > 0)
return -1;
return term;
}
};
力扣269 火星词典
269. 火星词典
现有一种使用英语字母的火星语言,这门语言的字母顺序与英语顺序不同。
给你一个字符串列表 words ,作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 。
请你根据该词典还原出此语言中已知的字母顺序,并 按字母递增顺序 排列。若不存在合法字母顺序,返回 “” 。若存在多种可能的合法字母顺序,返回其中 任意一种 顺序即可。
字符串 s 字典顺序小于 字符串 t 有两种情况:
在第一个不同字母处,如果 s 中的字母在这门外星语言的字母顺序中位于 t 中字母之前,那么 s 的字典顺序小于 t 。
如果前面 min(s.length, t.length) 字母都相同,那么 s.length < t.length 时,s 的字典顺序也小于 t 。
示例 1:
输入:words = [“wrt”,”wrf”,”er”,”ett”,”rftt”]
输出:”wertf”
示例 2:
输入:words = [“z”,”x”]
输出:”zx”
示例 3:
输入:words = [“z”,”x”,”z”]
输出:””
解释:不存在合法字母顺序,因此返回 “” 。
提示:
1 <= words.length <= 100
1 <= words[i].length <= 100
words[i] 仅由小写英文字母组成
通过次数4,651提交次数13,854
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/alien-dictionary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路分析:
首先需要明确题目的意思,这道题给出了一个按照「自定义字典序」排序的单词列表,让我们还原出「自定义的字典序」(题目中说的火星词典);
字典序:是指按照单词出现在字典的顺序进行排序的方法。先按照第一个字母以 a、b、c……z 的顺序排列,如果第一个字母一样,那么比较第二个、第三个乃至后面的字母。如果比到最后两个单词不一样长,比如 sigh 和 sight),把短者排在前;
分析示例 1:[“wrt”, “wrf”, “er”, “ett”, “rftt”],
比较 “wrt” 与 “wrf,按数位依次比较,前 22 个字符相等,t 与 f 不等,说明 t 的字典序在 f 的前面,我们记为 t -> f;
比较 “wrf” 与 “er”,按数位依次比较,w 与 e 不等,说明 w 的字典序在 e 的前面,我们记为 w -> e;
比较 “er” 与 “ett”,按数位依次比较,前 11 个字符相等,r 与 t 不等,说明 r 的字典序在 t 的前面,我们记为 r -> t;
比较 “ett” 与 “rftt”,按数位依次比较,e 与 r 不等,说明 e 的字典序在 r 的前面,我们记为 e -> r;
把它们连在一起,可以画出如下图结构:
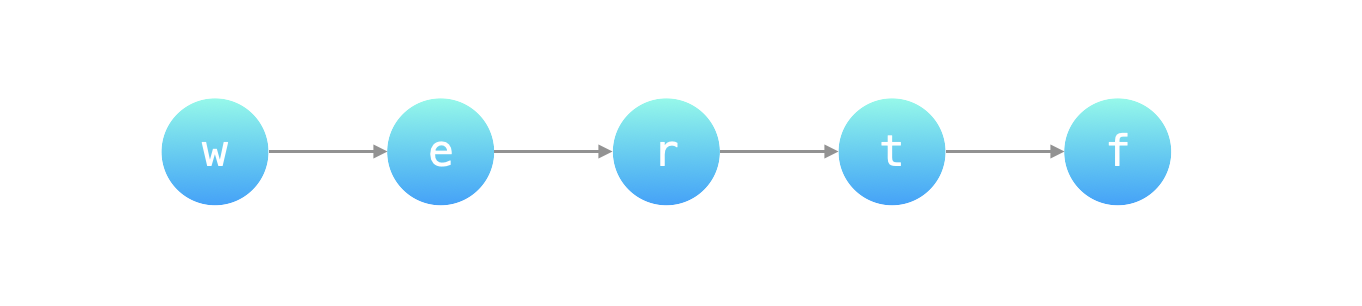
因此输出就是 “wertf”。
通过示例 1 的分析,可以归纳出求解这个问题的步骤:
步骤 1:通过输入的字符串数组 words ,构建字符的图结构(建图);
步骤 2:可以对步骤 1 得到的图结构执行一次「拓扑排序」(广度优先遍历),如果图是 有向无环图,拓扑排序的结果就是「自定义字典序」。
在实际编码的时候,有很多细节和一些特殊的测试用例需要考虑,我们例举如下(大家不一定需要了解下面说到的细节,可以先自己尝试编码,在遇到问题的时候尝试调试,这样是更有效的):
建图,建立邻接表,即「顶点」和它的 所有 「后继」结点的对应关系,题目中说:「你可以默认输入的全部都是小写字母」,因此可以使用数组或者哈希表,这里推荐使用哈希表,理由是 ① 哈希表有去重、判重的功能;② 有遍历所有在输入字符串数组中出现的字符的需求,遍历哈希表中的所有键,是相对方便的;
针对特殊测试用例,[“abc”, “ab”],按照字典序的定义,长度较短的字符串在前,应该为 [“ab”, “abc”],在建图的时候需要考虑到这种特殊的情况;
建图的时候,需要找到找到位置相邻的一对单词,从左至右依次比较,直到找到不一样的字符,得到有向图的一条边,后面就不可以再比较下去(回顾上述字典序的定义);
题目中说:「你可以默认输入的全部都是小写字母」,因此在拓扑排序中使用的入度数组的长度可以只设置为 2626。注意:在输入的字符串数组中,2626 个字符不一定都会出现,不会出现的字符在入度数组里的入度也为 00,在编码的时候需要考虑到这种情况;
构建图的时候,有向边的可以被重复添加,因为哈希表可以去重,但是被指向顶点的入度不可以重复增加,为此需要做特殊判断;
拓扑排序以后,需要判断:所有的顶点都输出了,才是说明通过输入字符串数组构建的图结构是有向无环图,此时才输出拓扑排序的结果。
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.Map;
import java.util.Queue;
import java.util.Set;
public class Solution {
public String alienOrder(String[] words) {
int len = words.length;
if (len == 0) {
return "";
}
// 第 1 步:构建图与统计入度数组
Map<Character, Set<Character>> adj = new HashMap<>(26);
for (String word : words) {
for (char c : word.toCharArray()) {
// 如果 c 还未在哈希表的 key 中出现,创建 key,并且初始化它的后继结点列表
adj.putIfAbsent(c, new HashSet<>());
}
}
int[] inDegree = new int[26];
// 相邻两个单词比较,得出字典序
for (int i = 0; i < len - 1; i++) {
char[] charArray1 = words[i].toCharArray();
char[] charArray2 = words[i + 1].toCharArray();
int minLen = Math.min(charArray1.length, charArray2.length);
for (int j = 0; j < minLen; j++) {
if (charArray1[j] != charArray2[j]) {
// 有向边的可以被重复添加,因为哈希表可以去重,但是被指向顶点的入度不可以重复增加,为此需要做特殊判断
if (!adj.get(charArray1[j]).contains(charArray2[j])) {
adj.get(charArray1[j]).add(charArray2[j]);
inDegree[charArray2[j] - 'a']++;
}
// 这个 break 很重要,后面的字符不可以继续比对下去
break;
}
// 针对特殊测试用例,["abc", "ab"],不存在这样的字典序排序结果
if (j == minLen - 1 && words[i].length() > words[i + 1].length()) {
return "";
}
}
}
// 第 2 步:基于 adj 和入度数组进行广度优先遍历,下面这一串代码是典型的拓扑排序的代码
Queue<Character> queue = new LinkedList<>();
for (char c : adj.keySet()) {
if (inDegree[c - 'a'] == 0) {
queue.offer(c);
}
}
StringBuilder stringBuilder = new StringBuilder();
while (!queue.isEmpty()) {
Character top = queue.poll();
stringBuilder.append(top);
Set<Character> successors = adj.get(top);
for (Character successor : successors) {
inDegree[successor - 'a']--;
if (inDegree[successor - 'a'] == 0) {
queue.offer(successor);
}
}
}
// 最后不要忘了,所有的顶点都输出了,才是有向无环图
// 可以遍历入度数组,如果存在一个顶点的入度大于 0,说明存在环,输出 ""
// 等价的方式是看输出的字符串长度是否等于 adj 的键值对总数
if (stringBuilder.length() == adj.size()) {
return stringBuilder.toString();
}
return "";
}
}
复杂度分析:
本题的复杂度分析较难给出形式化的结论,我们知道拓扑排序,其实就是在问题所对应的图形结构上执行一次广度优先遍历,广度优先遍历的时间复杂度取决于图形结构的顶点数和边数。
时间复杂度:
当前这个问题,构建图之前需要遍历字符串数组的每一个字符串,然后构建图的时候,需要枚举所有输入字符串数组「相邻的」两个字符串的字符(出了第一个字符串和最后一个字符串以外,每隔字符串被遍历了两次),可以粗略地认为所有字符串都被遍历了两次。因此时间复杂度主要由以下关系决定:
输入字符串数组的所有字符的总数(包含了重复字符);
输入字符串数组所包含的不重复字符数,根据题目意思,这个值不超过 2626;
输入字符串数组所构建的图形结构的 有向边 的总数,根据题目意思, 这个值不超过 25!25!。
空间复杂度:题目中用到的空间来自「邻接表 adj」(较难给出形式化的表达式) 和入度数组 inDegree(长度为 2626)。
力扣129 求根节点到叶节点数字之和
129. 求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
示例 1:
输入:root = [1,2,3]
输出:25
解释:
从根到叶子节点路径 1->2 代表数字 12
从根到叶子节点路径 1->3 代表数字 13
因此,数字总和 = 12 + 13 = 25
示例 2:
输入:root = [4,9,0,5,1]
输出:1026
解释:
从根到叶子节点路径 4->9->5 代表数字 495
从根到叶子节点路径 4->9->1 代表数字 491
从根到叶子节点路径 4->0 代表数字 40
因此,数字总和 = 495 + 491 + 40 = 1026
提示:
树中节点的数目在范围 [1, 1000] 内
0 <= Node.val <= 9
树的深度不超过 10
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/sum-root-to-leaf-numbers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这道题需要注意的是当判断到节点是null的时候,需要返回的是0,而不是presum,因为当节点为null的时候,意味着这个节点所在的分支是不存在的。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int dfs(TreeNode* node, int preSum)
{
if(node == nullptr)
return 0;
preSum = node->val + preSum * 10;
if(node->left == nullptr && node->right == nullptr)
{
return preSum;
}
else
{
return dfs(node->left, preSum) + dfs(node->right, preSum);
}
}
int sumNumbers(TreeNode* root) {
return dfs(root, 0);
}
};
力扣323 无向图中连通分量的数目
323. 无向图中连通分量的数目
给定编号从 0 到 n-1 的 n 个节点和一个无向边列表(每条边都是一对节点),请编写一个函数来计算无向图中连通分量的数目。
示例 1:
输入: n = 5 和 edges = [[0, 1], [1, 2], [3, 4]]
0 3 | | 1 --- 2 4输出: 2
示例 2:
输入: n = 5 和 edges = [[0, 1], [1, 2], [2, 3], [3, 4]]
0 4 | | 1 --- 2 --- 3输出: 1
注意:
你可以假设在 edges 中不会出现重复的边。而且由于所以的边都是无向边,[0, 1] 与 [1, 0] 相同,所以它们不会同时在 edges 中出现。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/number-of-connected-components-in-an-undirected-graph
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
采用并查集进行解决。(Python的并查集)
class UnionFind
{
public:
vector<int> parent;
vector<int> size;
int n;
int part;
UnionFind(int n)
{
this->n = n;
part = n;
parent.resize(n);
for(int x = 0; x < n; x++)
parent[x] = x;
size.resize(n, 1);
}
int Find(int x)
{
if (parent[x] == x)
return x;
return Find(parent[x]);
}
bool Union(int x, int y)
{
int root_x = Find(x);
int root_y = Find(y);
if (root_x == root_y)
return false;
if (size[root_x] > size[root_y])
swap(root_x, root_y);
parent[root_x] = root_y;
size[root_y] += size[root_x];
part -= 1;
return true;
}
bool in_the_same_part(int x, int y)
{
return Find(x) == Find(y);
}
int get_the_part_size(int x)
{
int root_x = Find(x);
return size[root_x];
}
};
class Solution
{
public:
int countComponents(int n, vector<vector<int>>& edges)
{
UnionFind UF(n);
for (auto & v: edges)
{
int x = v[0], y = v[1];
UF.Union(x, y);
}
return UF.part;
}
};

若有收获,就点个赞吧
0 人点赞
