前些天小伙伴给我出了一道题,是求两个单链表的首次相交点。要求是时间复杂度应严格满足m+n。
这道题类似于力扣的第160题
160. 相交链表
编写一个程序,找到两个单链表相交的起始节点。
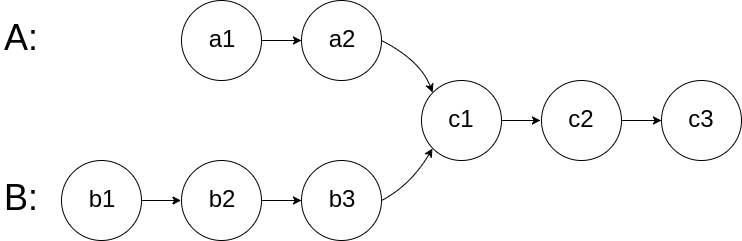
如下面的两个链表:
在节点 c1 开始相交。
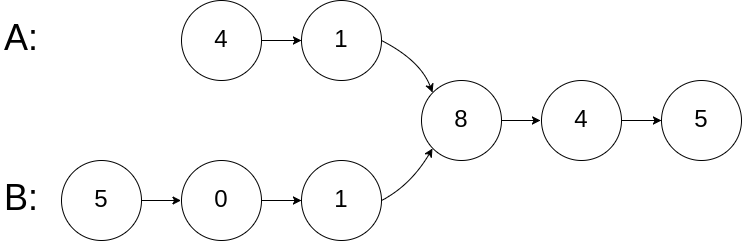
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
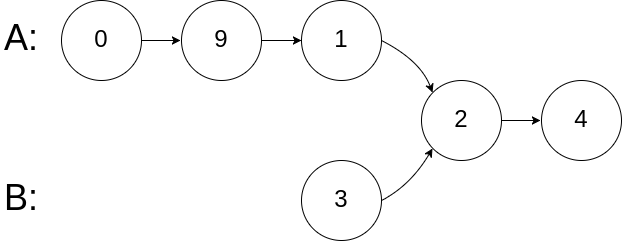
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
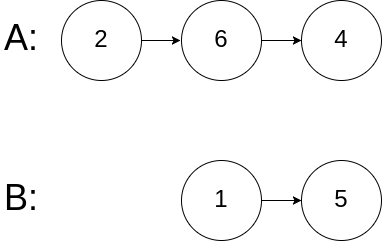
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。
注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/intersection-of-two-linked-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
这道题有很多解法,下面依次列出这些解法:
方法一:利用hashmap,这种方法的优点在于可以满足题目中所说严格满足m + n,缺点在于额外增加了空间。
struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}};ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {if(headA == NULL || headB == NULL)return NULL;set<ListNode*>store;while(headA != NULL){store.insert(headA);headA = headA->next;}while(headB != NULL){if(store.find(headB) != store.end())return headB;headB = headB->next;}return NULL;}
现在假设,如果已经明确告知了肯定会有相交点的话,那我们我们还可以通过修改链表来保证其时间严格满足m + n,同时还不额外增添空间
方法二:置NULL法。这种方法会破坏链表的本身,但却可以节省空间和时间。并且这种方法并不能解决力扣的第160题,因为这个方法可行的前提是链表一定要相交。
struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}};ListNode *getIntersectionNode2(ListNode *headA, ListNode *headB){if(headA == NULL || headB == NULL)return NULL;while(headA->next != NULL){ListNode* tmp = headA->next;headA->next = NULL;headA = tmp;}while(headB->next != NULL){headB = headB->next;}return headB;}
方法三:令A链表走向尾端的同时,指向B继续走,同时令B链表走向尾端的时候,指向A继续走,如果两者有相交的节点,即会存在相同的节点。
下面的做法,如果不存在相交的节点,那么最后的结果返回的是NULL
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/class Solution {public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {ListNode *pA = headA;ListNode *pB = headB;while(pA != pB){pA = pA ? pA->next : headB;pB = pB ? pB->next : headA;}return pA;}};

若有收获,就点个赞吧
0 人点赞
