EventLoop.h
添加和执行任务队列的任务。ExecuteTask会顺序执行functionlist中的函数。比如增、删、改等
class EventLoop{public:...//向任务队列添加任务void AddTask(Functor functor){{std::lock_guard <std::mutex> lock(mutex_);//std::cout << "push_back done" << std::endl;functorlist_.push_back(functor);}//std::cout << "WakeUp" << std::endl;WakeUp();//跨线程唤醒,worker线程唤醒IO线程}//执行任务队列的任务void ExecuteTask(){// std::lock_guard <std::mutex> lock(mutex_);// for(Functor &functor : functorlist_)// {// functor();//在加锁后执行任务,调用sendinloop,再调用close,执行添加任务,这样functorlist_就会修改// }// functorlist_.clear();std::vector<Functor> functorlist;{std::lock_guard <std::mutex> lock(mutex_);functorlist.swap(functorlist_);}for(Functor &functor : functorlist){functor();}functorlist.clear();}...private:private://任务列表std::vector<Functor> functorlist_;//epoll操作封装Poller poller_;//loop所在的线程idstd::thread::id tid_;//保护任务列表的互斥量std::mutex mutex_;}
Poller.h
这个项目是基于epoll的多线程网络服务器。所以让我们先了解一下epoll
epoll
epoll作为linux下高性能网络服务器的必备技术至关重要,nginx、redis、skynet和大部分游戏服务器都使用到这一多路复用技术。
网卡会把接收到的数据写入到内存中 —> 网卡向CPU发出一个中断信号,操作系统便能得知有新的数据到来,通过网卡中断程序去处理数据->将网络数据写入到socket的接收缓冲区里面->唤醒该socket对应的进程
以下是基本的网络编程代码,先常见socket对象,依次调用bind,listen,accept 最后调用recv接收数据。recv是个阻塞方法,当程序运行到recv时,它会一直等待,直到接收到数据才往下执行。
//创建socketint s = socket(AF_INET, SOCK_STREAM, 0);//绑定bind(s, ...)//监听listen(s, ...)//接受客户端连接int c = accept(s, ...)//接收客户端数据recv(c, ...);//将数据打印出来printf(...)
阻塞是进程调度的关键一环,指的是进程在等待某事件(如接收到网络数据)发生之前的等待状态,
recv、select和epoll都是阻塞方法。阻塞并不占用CPU资源,因为CPU会把阻塞的进程放入到等待队列当中,该进程便由工作状态变为等待状态,当socket接收到数据后,CPU再将该socket等待队列上的进程重新放回到工作队列当中,将进程的状态变为工作状态
由于每一个socket都对应着一个端口号,而网络数据包中包含了ip和端口的信息,内核便可以通过端口号找到对应的socket。把socket当成一个单独的进程
从上面的代码中可以看出recv只能监控单个socket,epoll的要义是监控多个socket
在没有epoll之前,采用的是低效的调用select,并通过遍历一个sockets列表来发现拥有数据的socket
int s = socket(AF_INET, SOCK_STREAM, 0);bind(s, ...)listen(s, ...)int fds[] = 存放需要监听的socketwhile(1){int n = select(..., fds, ...)for(int i=0; i < fds.count; i++){if(FD_ISSET(fds[i], ...)){//fds[i]的数据处理}}}
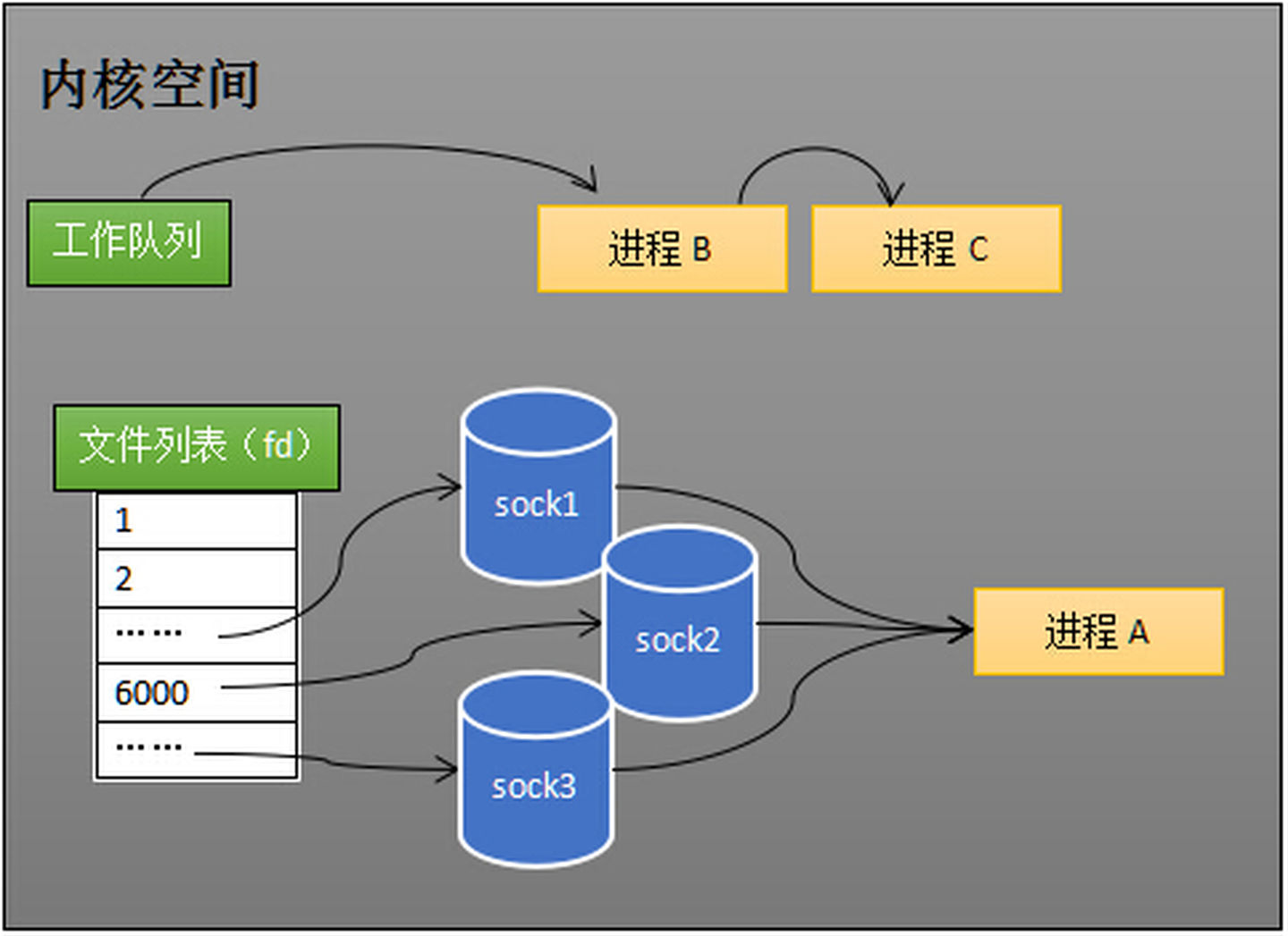
(在这里进程A是worker进程,多个socket共用这个worker进程,这个便是多路复用)
这种方法需要两次遍历,第一次遍历fds列表,发现拥有数据的socket,然后唤起进程,第二次遍历通过FD_ISSET判断具体哪个socket接到数据,然后做出处理。
这种方法的缺点在于
- 每次调用select都需要将进程加入到所有监视socket的等待队列,每次唤醒都需要从每个队列中移除。这里涉及了两次遍历,而且每次都要将整个fds列表传递给内核,有一定的开销。正是因为遍历操作开销大,出于效率的考量,才会规定select的最大监视数量,默认只能监视1024个socket。
- 进程被唤醒后,程序并不知道哪些socket收到数据,还需要遍历一次。
select将等待队列和进程等待合二为一,而epoll则是将其拆开,epoll_ctl维护等待队列,epoll_wait阻塞进程。
epoll将功能分离的另外一个好处在于,我们可以对每一个功能进行单独的优化。
在select的方法中,我们需要需要在第二次遍历中找到收到数据的socket来交给被唤起的进程,在epoll中我们可以增加一个列表rdlist,专门用来 引用 拥有数据的socket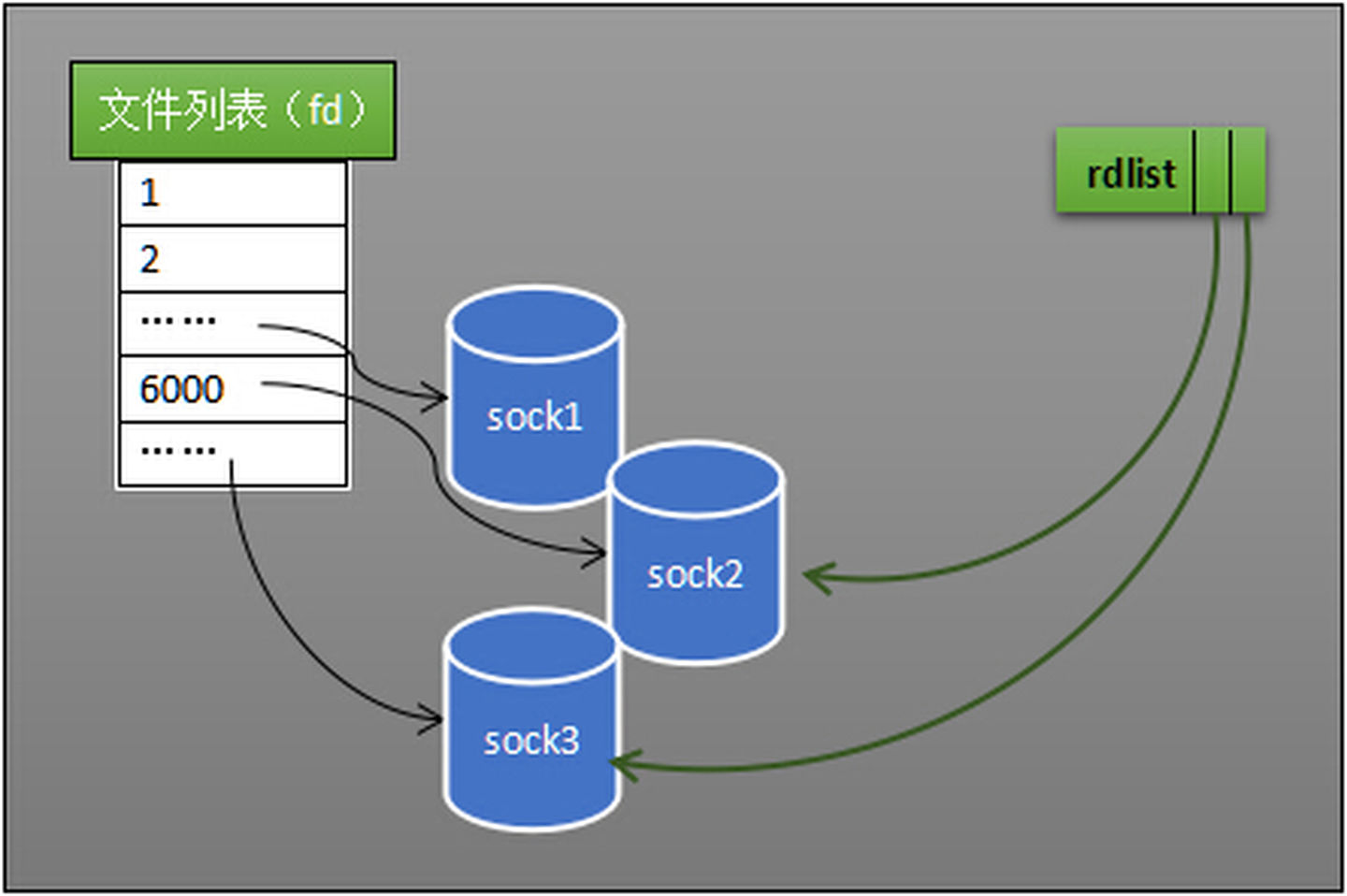
PS:epoll只有在持有很多连接,并且每个连接都不是特别活跃的时候效率才高,其他的情况不见得比select好。毕竟epoll的数据结构更加的复杂
epoll的具体用法: 当进程调用epoll_create方法时,内核会创建一个eventpoll对象(也就是下面程序中的epfd所代表的对象),epoll_ctl将需要监视的socket添加到epfd中,调用epoll_wait等待数据。
int s = socket(AF_INET, SOCK_STREAM, 0);bind(s, ...)listen(s, ...)int epfd = epoll_create(...);epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中while(1){int n = epoll_wait(...)for(接收到数据的socket){//处理}}
过epoll_ctl添加sock1、sock2和sock3的监视,内核会将eventpoll添加到这三个socket的等待队列中。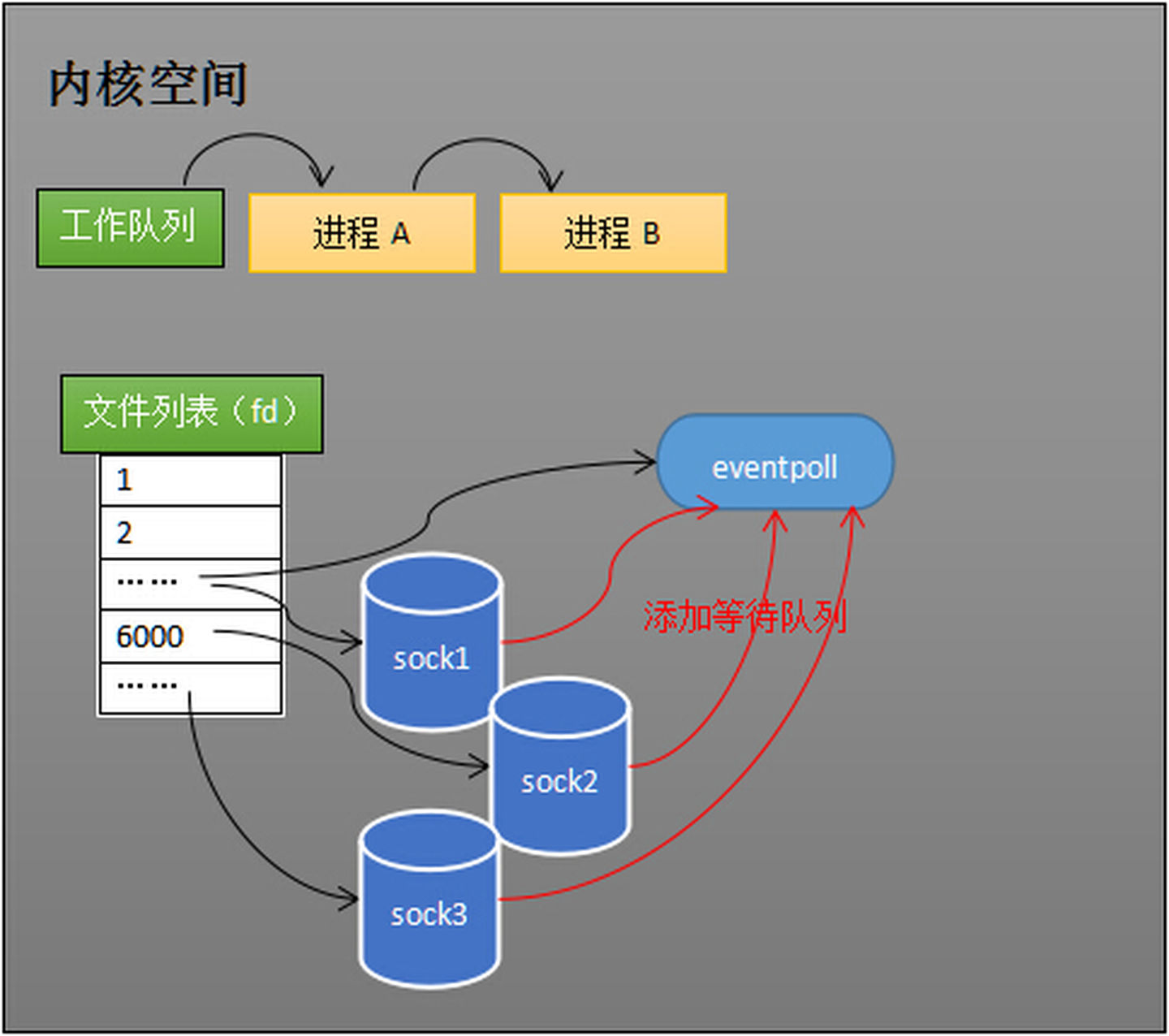
当socket收到数据后,中断程序会操作eventpoll对象,给eventpoll的“就绪列表”添加socket引用,而不是直接操作进程。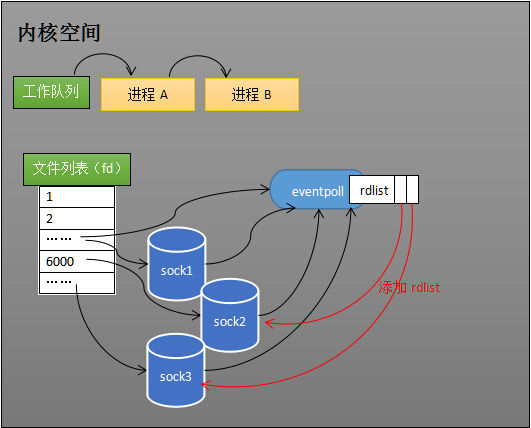
eventpoll对象相当于是socket和进程之间的中介,socket的数据接收并不直接影响进程,而是通过改变eventpoll的就绪列表来改变进程状态。当程序执行到epoll_wait时,如果rdlist已经引用了socket,那么epoll_wait直接返回,如果rdlist为空,阻塞进程。
假设计算机中正在运行进程A和进程B,在某时刻进程A运行到了epoll_wait语句。如下图所示,内核会将进程A放入eventpoll的等待队列中,阻塞进程。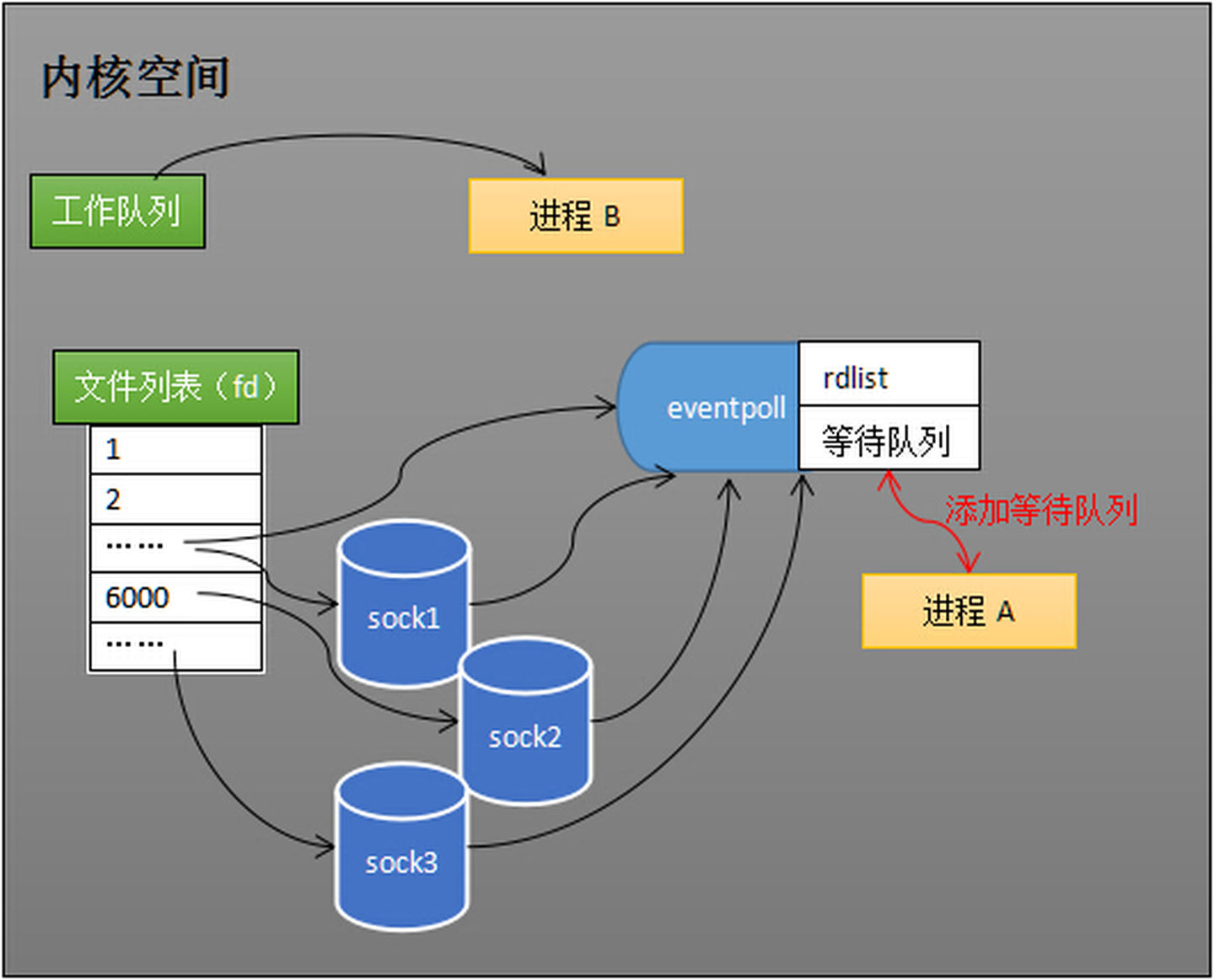
当socket接收到数据,中断程序一方面修改rdlist,另一方面唤醒eventpoll等待队列中的进程,进程A再次进入运行状态(如下图)。也因为rdlist的存在,进程A可以知道哪些socket发生了变化。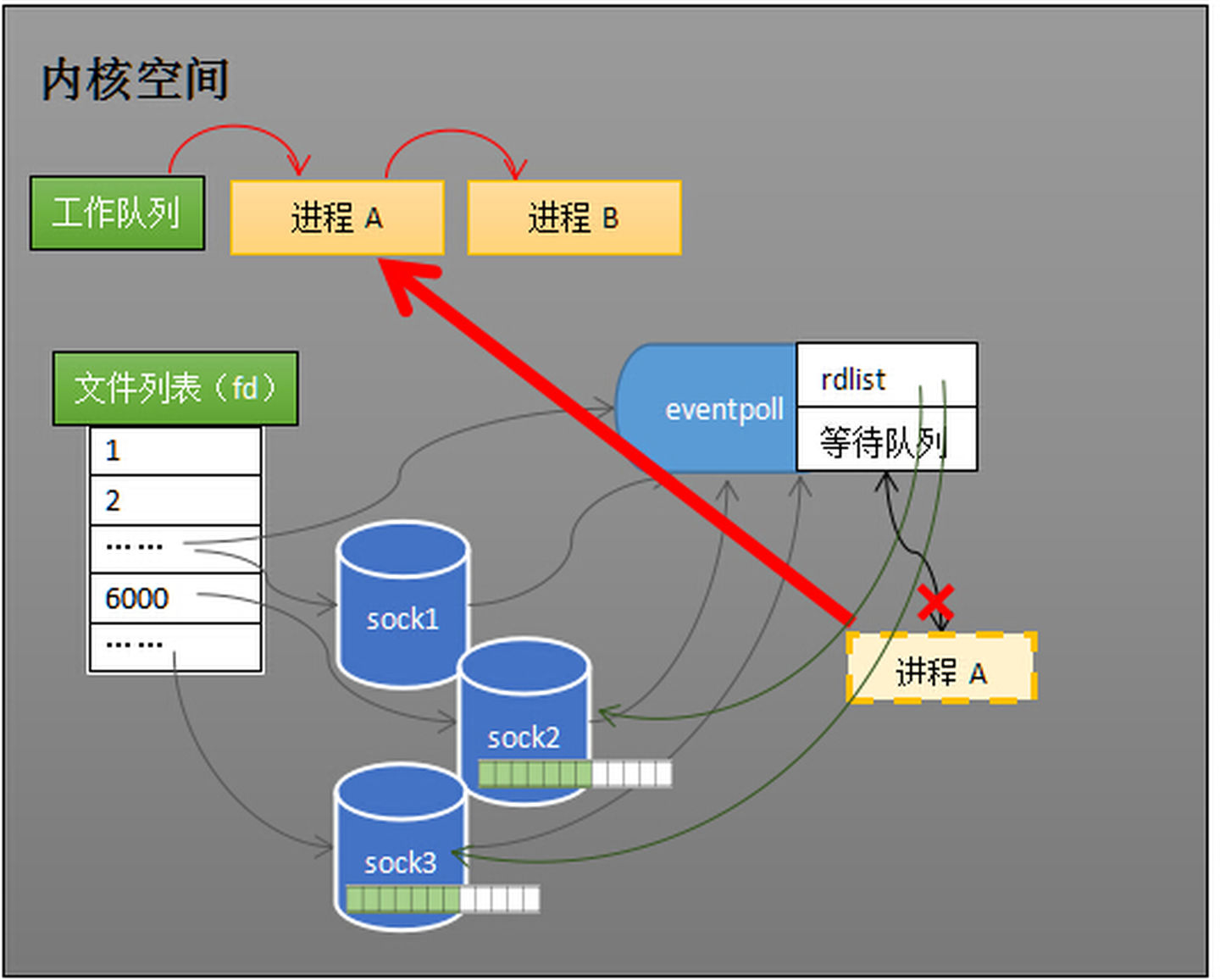
epoll在select和poll(poll和select基本一样,有少量改进)的基础引入了eventpoll作为中间层,使用了先进的数据结构,是一种高效的多路复用技术。
假设Redis对外提供6379端口,那么6379端口会用于监听,当服务端accept一个客户端的连接时,服务端内部会重建一个新的socket来代表该客户端,所以服务端端socket总数是N+1,即一个用于监听+N个匹对客户端端socket。可以想想看,每次accept后不是有个新的fd生成么,这个fd就代表了新的socket
补充
nginx所依赖的epoll出现于linux-2.5.44,发布于2002年。在那之前的服务器开发有如下几种模型:
- 多进程模型:apache的标准模式,每一个新来的请求都会开一个子进程来处理,处理后子进程销毁,对资源占用很高,动则几MB到几十MB的内存消耗。linux当时也郁闷于多进程模式的内存消耗,搞出了COW模式的子进程,使得与父进程共享而未修改的内存不再需要申请新的空间。但总的来说,一个新的进程对资源的消耗远大于一个线程。
- 多线程模型:apache在后期也开始支持的模式,对每个新的请求只开一个线程来处理。因为有大量的资源是隶属于进程并被各个线程共享,所以资源消耗上有了一定的提升,但几百KB到几个MB还是要的。
- select()模型:利用select()系统调用实现异步服务器,一个循环通过调用select()获知哪些连接有新的事件发生并进行处理。select()模型对资源的利用率比多线程模式还好。但有个缺陷,即内核里select()的实现是需要循环扫描所有socket的。这就导致当连接数很大时,单单扫描一圈也是非常耗时的。
于是epoll出现了,主要解决的是扫描大量socket太慢的问题。引入了红黑树存储所有要监控的socket。这使得服务器在处理million级别并发连接时,每个连接的资源消耗可以控制在几十KB的级别。极端优化的甚至可以把每个连接的内存消耗降低到10KB以下
Reference
https://zhuanlan.zhihu.com/p/63179839
https://zhuanlan.zhihu.com/p/64138532
https://zhuanlan.zhihu.com/p/64746509
https://www.zhihu.com/question/394259343/answer/1225870088

若有收获,就点个赞吧
0 人点赞
