时间复杂度为 O(n^2)的排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序(希尔排序比较特殊,它的性能略优于 O(n^2)但又比不上 O(nlog n),姑且把它归入本类)
时间复杂度为O(nlog n) 的排序算法
- 快速排序
- 归并排序
- 堆排序
- 时间复杂度为线性的排序算法
- 计数排序
- 桶排序
- 基数排序
即如果值相同的元素在排序后仍然保持着排序前的顺序,则这样的排序算法是稳定排序;如果值相同的元素在排序后打乱了排序前的顺序,则这样的排序算法是不稳定排序。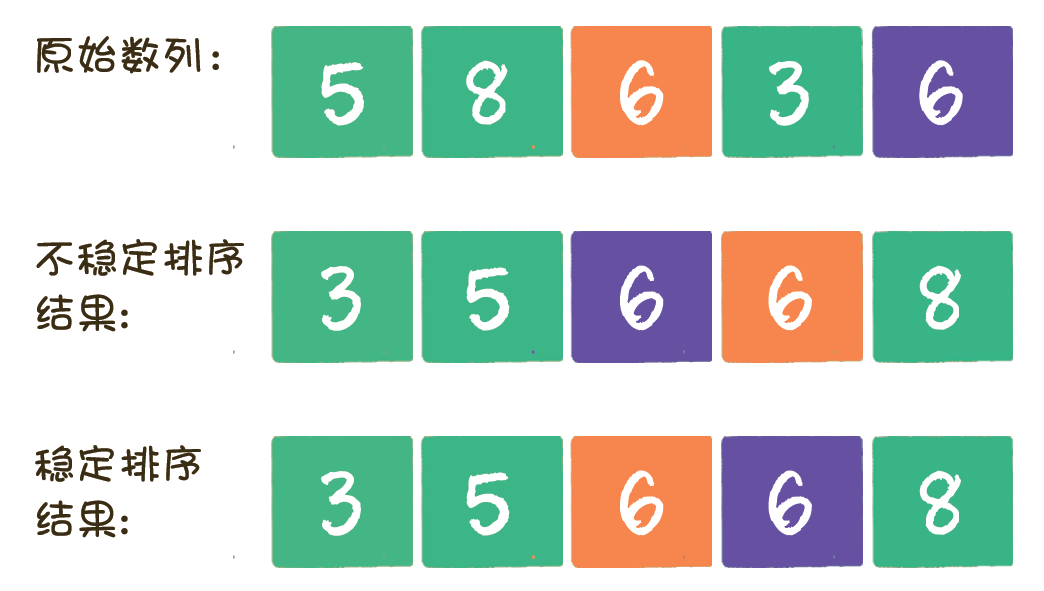
冒泡排序
void bubbleSort(int arr[], int n){for (int i = 0; i < n; i++){for(int j = 0; j < n - i - 1; j++){if(arr[j] > arr[j+1]){int t = arr[j];arr[j] = arr[j+1];arr[j + 1] = t;}}}}
选择排序
排序思路 i < j && arr[i] < arr[j]
void choiceSort(int arr[], int n)
{
for(int i = 0; i < n; i++)
{
int m = i;
for(int j = i + 1; j < n; j++)
{
if (arr[j] < m)
m = j;
}
if (i != m)
{
int t = arr[i];
arr[i] = arr[m];
arr[m] = t;
}
}
}
插入排序
void insertion_sort(int arr[], int len)
{
for(int i = 1; i < len; i++)
{
int key = arr[i];
int j;
for(j = i - 1; j > 0 && key < arr[j]; j--)
{
arr[j+1] = a[j];
a[j + 1] = key;
}
}
}
快速排序
快速排序算法由 C. A. R. Hoare 在 1960 年提出。它的时间复杂度也是 O(nlogn),但它在时间复杂度为 O(nlogn) 级的几种排序算法中,大多数情况下效率更高,所以快速排序的应用非常广泛。再加上快速排序所采用的分治思想非常实用,使得快速排序深受面试官的青睐,所以掌握快速排序的思想尤为重要。
快速排序算法的基本思想是:
从数组中取出一个数,称之为基数(pivot)
遍历数组,将比基数大的数字放到它的右边,比基数小的数字放到它的左边。遍历完成后,数组被分成了左右两个区域
将左右两个区域视为两个数组,重复前两个步骤,直到排序完成
事实上,快速排序的每一次遍历,都将基数摆到了最终位置上。第一轮遍历排好 1 个基数,第二轮遍历排好 2 个基数(每个区域一个基数,但如果某个区域为空,则此轮只能排好一个基数),第三轮遍历排好 4 个基数(同理,最差的情况下,只能排好一个基数),以此类推。总遍历次数为 logn~n 次,每轮遍历的时间复杂度为 O(n),所以很容易分析出快速排序的时间复杂度为 O(nlogn)O(nlogn) ~ O(n^2)平均时间复杂度为 O(nlogn)。
快速排序递归框架
public static void quickSort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
public static void quickSort(int[] arr, int start, int end) {
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 对左边区域快速排序
quickSort(arr, start, middle - 1);
// 对右边区域快速排序
quickSort(arr, middle + 1, end);
}
public static int partition(int[] arr, int start, int end) {
// TODO: 将 arr 从 start 到 end 分区,左边区域比基数小,右边区域比基数大,然后返回中间值的下标
}
partition 意为“划分”,我们期望 partition 函数做的事情是:将 arr 从 start 到 end 这一区间的值分成两个区域,左边区域的每个数都比基数小,右边区域的每个数都比基数大,然后返回中间值的下标。
只要有了这个函数,我们就能写出快速排序的递归函数框架。首先调用 partition 函数得到中间值的下标 middle,然后对左边区域执行快速排序,也就是递归调用 quickSort(arr, start, middle - 1),再对右边区域执行快速排序,也就是递归调用 quickSort(arr, middle + 1, end)。
现在还有一个问题,何时退出这个递归函数呢?
退出递归的边界条件
很容易想到,当某个区域只剩下一个数字的时候,自然不需要排序了,此时退出递归函数。实际上还有一种情况,就是某个区域只剩下 0 个数字时,也需要退出递归函数。当 middle 等于 start 或者 end 时,就会出现某个区域剩余数字为 0。
所以我们可以通过这种方式退出递归函数:
//
public static void quickSort(int[] arr, int start, int end) {
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 当左边区域中至少有 2 个数字时,对左边区域快速排序
if (start != middle && start != middle - 1) quickSort(arr, start, middle - 1);
// 当右边区域中至少有 2 个数字时,对右边区域快速排序
if (middle != end && middle != end - 1) quickSort(arr, middle + 1, end);
}
在递归之前,先判断此区域剩余数字是否为 0 个或者 1 个,当数字至少为 2 个时,才执行这个区域的快速排序。因为我们知道 middle >= start && middle <= end 必然成立,所以判断剩余区域的数字为 0 个或者 1 个也就是指 start 或 end 与 middle 相等或相差 1。
我们来分析一下这四个判断条件:
当 start == middle 时,相当于 quickSort(arr, start, middle - 1) 中的 start == end + 1
当 start == middle - 1 时,相当于 quickSort(arr, start, middle - 1) 中的 start == end
当 middle == end 时,相当于 quickSort(arr, middle + 1, end) 中的 start == end + 1
当 middle == end -1 时,相当于 quickSort(arr, middle + 1, end) 中的 start == end
综上,我们可以将此边界条件统一移到 quickSort 函数之前:
public static void quickSort(int[] arr, int start, int end) {
// 如果区域内的数字少于 2 个,退出递归
if (start == end || start == end + 1) return;
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 对左边区域快速排序
quickSort(arr, start, middle - 1);
// 对右边区域快速排序
quickSort(arr, middle + 1, end);
}
更进一步,由上文所说的 middle >= start && middle <= end 可以推出,除了start == end || start == end + 1这两个条件之外,其他的情况下 start 都小于 end。所以我们可以将这个判断条件再次简写为:
/
public static void quickSort(int[] arr, int start, int end) {
// 如果区域内的数字少于 2 个,退出递归
if (start >= end) return;
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 对左边区域快速排序
quickSort(arr, start, middle - 1);
// 对右边区域快速排序
quickSort(arr, middle + 1, end);
}
这样我们就写出了最简洁版的边界条件,我们需要知道,这里的 start >= end 实际上只有两种情况:
start == end: 表明区域内只有一个数字
start == end + 1: 表明区域内一个数字也没有
不会存在 start 比 end 大 2 或者大 3 之类的。
分区算法实现
快速排序中最重要的便是分区算法,也就是 partition 函数。大多数人都能说出快速排序的整体思路,但实现起来却很难一次写对。主要问题就在于分区时存在的各种边界条件,需要读者亲自动手实践才能加深体会。
上文已经说到,partition 函数需要做的事情就是将 arr 从 start 到 end 分区,左边区域比基数小,右边区域比基数大,然后返回中间值的下标。那么首先我们要做的事情就是选择一个基数,基数我们一般称之为 pivot,意为“轴”。整个数组就像围绕这个轴进行旋转,小于轴的数字旋转到左边,大于轴的数字旋转到右边。(所谓的双轴快排就是一次选取两个基数,将数组分为三个区域进行旋转,关于双轴快排的内容我们将在后续章节讲解。)
基数的选择
基数的选择没有固定标准,随意选择区间内任何一个数字做基数都可以。通常来讲有三种选择方式:
选择第一个元素作为基数
选择最后一个元素作为基数
选择区间内一个随机元素作为基数
选择的基数不同,算法的实现也不同。实际上第三种选择方式的平均时间复杂度是最优的,待会分析时间复杂度时我们会详细说明。
本文通过第一种方式来讲解快速排序:
// 将 arr 从 start 到 end 分区,左边区域比基数小,右边区域比基数大,然后返回中间值的下标
public static int partition(int[] arr, int start, int end) {
// 取第一个数为基数
int pivot = arr[start];
// 从第二个数开始分区
int left = start + 1;
// 右边界
int right = end;
// TODO
}
最简单的分区算法
分区的方式也有很多种,最简单的思路是:从 left 开始,遇到比基数大的数,就交换到数组最后,并将 right 减一,直到 left 和 right 相遇,此时数组就被分成了左右两个区域。再将基数和中间的数交换,返回中间值的下标即可。
按照这个思路,我们敲出了如下代码:
public static void quickSort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
public static void quickSort(int[] arr, int start, int end) {
// 如果区域内的数字少于 2 个,退出递归
if (start >= end) return;
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 对左边区域快速排序
quickSort(arr, start, middle - 1);
// 对右边区域快速排序
quickSort(arr, middle + 1, end);
}
// 将 arr 从 start 到 end 分区,左边区域比基数小,右边区域比基数大,然后返回中间值的下标
public static int partition(int[] arr, int start, int end) {
// 取第一个数为基数
int pivot = arr[start];
// 从第二个数开始分区
int left = start + 1;
// 右边界
int right = end;
// left、right 相遇时退出循环
while (left < right) {
// 找到第一个大于基数的位置
while (left < right && arr[left] <= pivot) left++;
// 交换这两个数,使得左边分区都小于或等于基数,右边分区大于或等于基数
if (left != right) {
exchange(arr, left, right);
right--;
}
}
// 如果 left 和 right 相等,单独比较 arr[right] 和 pivot
if (left == right && arr[right] > pivot) right--;
// 将基数和中间数交换
if (right != start) exchange(arr, start, right);
// 返回中间值的下标
return right;
}
private static void exchange(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
因为我们选择了数组的第一个元素作为基数,并且分完区后,会执行将基数和中间值交换的操作,这就意味着交换后的中间值会被分到左边区域。所以我们需要保证中间值的下标是分区完成后,最后一个比基数小的值,这里我们用 right 来记录这个值。
这段代码有一个细节。首先,在交换 left 和 right 之前,我们判断了 left != right,这是因为如果剩余的数组都比基数小,则 left 会加到 right 才停止,这时不应该发生交换。因为 right 已经指向了最后一个比基数小的值。
但这里的拦截可能会拦截到一种错误情况,如果剩余的数组只有最后一个数比基数大,left 仍然加到 right 停止了,但我们并没有发生交换。所以我们在退出循环后,单独比较了 arr[right] 和 pivot。
实际上,这行单独比较的代码非常巧妙,一共处理了三种情况:
一是刚才提到的剩余数组中只有最后一个数比基数大的情况
二是 left 和 right 区间内只有一个值,则初始状态下, left == right,所以 while (left < right) 根本不会进入,所以此时我们单独比较这个值和基数的大小关系
三是剩余数组中每个数都比基数大,此时 right 会持续减小,直到和 left 相等退出循环,此时 left 所在位置的值还没有和 pivot 进行比较,所以我们单独比较 left 所在位置的值和基数的大小关系
双指针分区算法
除了上述的分区算法外,还有一种双指针的分区算法更为常用:从 left 开始,遇到比基数大的数,记录其下标;再从 right 往前遍历,找到第一个比基数小的数,记录其下标;然后交换这两个数。继续遍历,直到 left 和 right 相遇。然后就和刚才的算法一样了,交换基数和中间值,并返回中间值的下标。
代码如下:
public static void quickSort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
public static void quickSort(int[] arr, int start, int end) {
// 如果区域内的数字少于 2 个,退出递归
if (start >= end) return;
// 将数组分区,并获得中间值的下标
int middle = partition(arr, start, end);
// 对左边区域快速排序
quickSort(arr, start, middle - 1);
// 对右边区域快速排序
quickSort(arr, middle + 1, end);
}
// 将 arr 从 start 到 end 分区,左边区域比基数小,右边区域比基数大,然后返回中间值的下标
public static int partition(int[] arr, int start, int end) {
// 取第一个数为基数
int pivot = arr[start];
// 从第二个数开始分区
int left = start + 1;
// 右边界
int right = end;
while (left < right) {
// 找到第一个大于基数的位置
while (left < right && arr[left] <= pivot) left++;
// 找到第一个小于基数的位置
while (left < right && arr[right] >= pivot) right--;
// 交换这两个数,使得左边分区都小于或等于基数,右边分区大于或等于基数
if (left < right) {
exchange(arr, left, right);
left++;
right--;
}
}
// 如果 left 和 right 相等,单独比较 arr[right] 和 pivot
if (left == right && arr[right] > pivot) right--;
// 将基数和轴交换
exchange(arr, start, right);
return right;
}
private static void exchange(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
同样地,我们需要在退出循环后,单独比较 left 和 right 的值。
从代码实现中可以分析出,快速排序是一种不稳定的排序算法,在分区过程中,相同数字的相对顺序可能会被修改。
时间复杂度 & 空间复杂度
快速排序的时间复杂度上文已经提到过,平均时间复杂度为 O(nlogn)O(nlogn),最坏的时间复杂度为 O(n^2)O(n
2
),空间复杂度与递归的层数有关,每层递归会生成一些临时变量,所以空间复杂度为 O(logn)O(logn) ~ O(n)O(n),平均空间复杂度为 O(logn)O(logn)。
回到前文提到的那个问题,为什么说随机选择剩余数组中的一个元素作为基数的方案平均复杂度是最优的呢?要理清这个问题,我们先来看一下什么情况下快速排序算法的时间复杂度最高,一共有两种情况。
理想中的快速排序在第 k 轮遍历中,可以排好 2^{k-1}
个基数。但从图中我们发现,当数组原本为正序或逆序时,我们将第一个数作为基数的话,每轮分区后,都有一个区域是空的,也就是说数组中剩下的数字都被分到了同一个区域!这就导致了每一轮遍历只能排好一个基数。所以总的比较次数为 (n - 1) + (n - 2) + (n - 3) + … + 1 次,由等差数列求和公式可以计算出总的比较次数为 n(n - 1)/2 次,此时快速排序的时间复杂度达到了 O(n^2) 级。
有的读者可能会疑惑,既然数组已经有序了,为什么还要再对其排序呢?这个操作看起来毫无意义。但事实可能让你大吃一惊,因为在实际工作中,这种重复排序的需求非常常见。
设想一个场景,前端程序员从第三方平台提供的接口中获取一列数据,并且产品部门要求前端必须保证这一列数据在展示给用户时是有序的。在测试环境下,前端程序员发现从第三方平台获取到的数据总是有序的,但为了保险起见,他还是不得不对收到的数据再次进行排序。因为第三方平台提供的数据是不可控的,他不能选择相信后台,否则万一哪天后台提供的数据变成了无序的,给用户展示数据时就会出现问题。于是这里就发生了重复排序,此时如果直接使用快速排序就可能出现排序速度很慢,拖慢程序性能的问题。
如何解决这样的问题呢?其实思路也很简单,只要我们每轮选择的基数不是剩余数组中最大或最小的值就可以了。具体方案有很多种,其中较常用的有三种。
快速排序的优化思路
第一种就是我们在前文中提到的,每轮选择基数时,从剩余的数组中随机选择一个数字作为基数。这样每轮都选到最大或最小值的概率就会变得很低了。所以我们才说用这种方式选择基数,其平均时间复杂度是最优的
第二种解决方案是在排序之前,先用洗牌算法将数组的原有顺序打乱,以防止原数组正序或逆序。
Java 已经将洗牌算法封装到了集合类中,即 Collections.shuffle() 函数。洗牌算法由 Ronald A.Fisher 和 Frank Yates 于 1938 年发明,思路是每次从未处理的数据中随机取出一个数字,然后把该数字放在数组中所有未处理数据的尾部。 Collections.shuffle() 函数源码如下:
private static final int SHUFFLE_THRESHOLD = 5;
public static void shuffle(List<?> list, Random rnd) {
int size = list.size();
if (size < SHUFFLE_THRESHOLD || list instanceof RandomAccess) {
for (int i=size; i>1; i--)
swap(list, i-1, rnd.nextInt(i));
} else {
Object arr[] = list.toArray();
// Shuffle array
for (int i=size; i>1; i--)
swap(arr, i-1, rnd.nextInt(i));
// Dump array back into list
// instead of using a raw type here, it's possible to capture
// the wildcard but it will require a call to a supplementary
// private method
ListIterator it = list.listIterator();
for (int i=0; i<arr.length; i++) {
it.next();
it.set(arr[i]);
}
}
}
public static void swap(List<?> list, int i, int j) {
// instead of using a raw type here, it's possible to capture
// the wildcard but it will require a call to a supplementary
// private method
final List l = list;
l.set(i, l.set(j, l.get(i)));
}
private static void swap(Object[] arr, int i, int j) {
Object tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
从源码中可以看出,对于数据量较小的列表(少于 5 个值),shuffle 函数直接通过列表的 set 方法进行洗牌,否则先将 list 转换为 array,再进行洗牌,以提高交换效率,洗牌完成后再将 array 转成 list 返回。
还有一种解决方案,既然数组重复排序的情况如此常见,那么我们可以在快速排序之前先对数组做个判断,如果已经有序则直接返回,如果是逆序则直接倒序即可。在 Java 内部封装的 Arrays.sort() 的源码中就采用了此解决方案。
关于 Arrays.sort() 函数的更多细节,我们将在后续章节讲解。
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
int partion(int arr[], int low, int high)
{
int i = low;
int pivot = arr[high];
for (int j = low; j <= high - 1; j++)
{
if (arr[j] < pivot)
{
swap(&arr[i], &arr[j]);
i++;
}
}
swap(&arr[i], &arr[high]);
return i;
}
void quickSort(int arr[], int low, int high)
{
if (low < high)
{
int pivot = partion(arr, low, high);
quickSort(arr, low, pivot - 1);
quickSort(arr, pivot + 1, high);
}
}
归并排序
约翰·冯·诺伊曼在 1945 年提出了归并排序。在讲解归并排序之前,我们先一起思考一个问题:如何将两个有序的列表合并成一个有序的列表?
将两个有序的列表合并成一个有序的列表
这太简单了,笔者首先想到的思路就是,将两个列表拼接成一个列表,然后之前学的冒泡、选择、插入、希尔、堆、快排都可以派上用场了。
觉得太暴力了一点?那我们换个思路。
既然列表已经有序了,通过前几章的学习,我们已经知道,插入排序的过程中,被插入的数组也是有序的。这就好办了,我们将其中一个列表中的元素逐个插入另一个列表中即可。
但是按照这个思路,我们只需要一个列表有序就行了,另一个列表不管是不是有序的,都会被逐个取出来,插入第一个列表中。那么,在两个列表都已经有序的情况下,还可以有更优的合并方案吗?
深入思考之后,我们发现,在第二个列表向第一个列表逐个插入的过程中,由于第二个列表已经有序,所以后续插入的元素一定不会在前面插入的元素之前。在逐个插入的过程中,每次插入时,只需要从上次插入的位置开始,继续向后寻找插入位置即可。这样一来,我们最多只需要将两个有序数组遍历一次就可以完成合并。
思路很接近了,如何实现它呢?我们发现,在向数组中不断插入新数字时,原数组需要不断腾出位置,这是一个比较复杂的过程,而且这个过程必然导致增加一轮遍历。
但好在我们有一个替代方案:只要开辟一个长度等同于两个数组长度之和的新数组,并使用两个指针来遍历原有的两个数组,不断将较小的数字添加到新数组中,并移动对应的指针即可。
根据这个思路,我们可以写出合并两个有序列表的代码:
// 将两个有序数组合并为一个有序数组
private static int[] merge(int[] arr1, int[] arr2) {
int[] result = new int[arr1.length + arr2.length];
int index1 = 0, index2 = 0;
while (index1 < arr1.length && index2 < arr2.length) {
if (arr1[index1] <= arr2[index2]) {
result[index1 + index2] = arr1[index1];
index1++;
} else {
result[index1 + index2] = arr2[index2];
index2++;
}
}
// 将剩余数字补到结果数组之后
while (index1 < arr1.length) {
result[index1 + index2] = arr1[index1];
index1++;
}
while (index2 < arr2.length) {
result[index1 + index2] = arr2[index2];
index2++;
}
return result;
}
这份代码的实现思路和我们分析的一模一样:首先开辟了一个新数组 result,长度等同于 arr1 和 arr2 的长度之和,然后使用 index1 记录 arr1 数组的下标,index2 记录 arr2 数组的下标。再将两个数组中较小的值不断添加到 result 中。其中,result 的当前下标等同于 index1 和 index2 之和。
如果你对 ++ 运算符用得熟练的话:
result[index1 + index2] = arr1[index1];
index1++;
间写为
result[index1 + index2] = arr1[index1++];
这样代码看起来会更简洁一些。
合并有序数组的问题解决了,但我们排序时用的都是无序数组,那么上哪里去找这两个有序的数组呢?
答案是 —— 自己拆分,我们可以把数组不断地拆成两份,直到只剩下一个数字时,这一个数字组成的数组我们就可以认为它是有序的。
然后通过上述合并有序列表的思路,将 1 个数字组成的有序数组合并成一个包含 2 个数字的有序数组,再将 2 个数字组成的有序数组合并成包含 4 个数字的有序数组…直到整个数组排序完成,这就是归并排序(Merge Sort)的思想。
将数组拆分成有序数组
拆分过程使用了二分的思想,这是一个递归的过程,归并排序使用的递归框架如下:
public static void mergeSort(int[] arr) {
if (arr.length == 0) return;
int[] result = mergeSort(arr, 0, arr.length - 1);
// 将结果拷贝到 arr 数组中
for (int i = 0; i < result.length; i++) {
arr[i] = result[i];
}
}
// 对 arr 的 [start, end] 区间归并排序
private static int[] mergeSort(int[] arr, int start, int end) {
// 只剩下一个数字,停止拆分,返回单个数字组成的数组
if (start == end) return new int[]{arr[start]};
int middle = (start + end) / 2;
// 拆分左边区域
int[] left = mergeSort(arr, start, middle);
// 拆分右边区域
int[] right = mergeSort(arr, middle + 1, end);
// 合并左右区域
return merge(left, right);
}
其中, mergeSort(int[] arr) 函数是对外暴露的公共方法,内部调用了私有的mergeSort(int[] arr, int start, int end) 函数,这个函数用于对 arr 的 [start, end] 区间进行归并排序。
可以看到,我们在这个函数中,将原有数组不断地二分,直到只剩下最后一个数字。此时嵌套的递归开始返回,一层层地调用merge(int[] arr1, int[] arr2)函数,也就是我们刚才写的将两个有序数组合并为一个有序数组的函数。
这就是最经典的归并排序,只需要一个二分拆数组的递归函数和一个合并两个有序列表的函数即可。
但这份代码还有一个缺点,那就是在递归过程中,开辟了很多临时空间,接下来我们就来看下它的优化过程。
归并排序的优化:减少临时空间的开辟
为了减少在递归过程中不断开辟空间的问题,我们可以在归并排序之前,先开辟出一个临时空间,在递归过程中统一使用此空间进行归并即可。
代码如下:
public static void mergeSort(int[] arr) {
if (arr.length == 0) return;
int[] result = new int[arr.length];
mergeSort(arr, 0, arr.length - 1, result);
}
// 对 arr 的 [start, end] 区间归并排序
private static void mergeSort(int[] arr, int start, int end, int[] result) {
// 只剩下一个数字,停止拆分
if (start == end) return;
int middle = (start + end) / 2;
// 拆分左边区域,并将归并排序的结果保存到 result 的 [start, middle] 区间
mergeSort(arr, start, middle, result);
// 拆分右边区域,并将归并排序的结果保存到 result 的 [middle + 1, end] 区间
mergeSort(arr, middle + 1, end, result);
// 合并左右区域到 result 的 [start, end] 区间
merge(arr, start, end, result);
}
// 将 result 的 [start, middle] 和 [middle + 1, end] 区间合并
private static void merge(int[] arr, int start, int end, int[] result) {
int middle = (start + end) / 2;
// 数组 1 的首尾位置
int start1 = start;
int end1 = middle;
// 数组 2 的首尾位置
int start2 = middle + 1;
int end2 = end;
// 用来遍历数组的指针
int index1 = start1;
int index2 = start2;
// 结果数组的指针
int resultIndex = start1;
while (index1 <= end1 && index2 <= end2) {
if (arr[index1] <= arr[index2]) {
result[resultIndex++] = arr[index1++];
} else {
result[resultIndex++] = arr[index2++];
}
}
// 将剩余数字补到结果数组之后
while (index1 <= end1) {
result[resultIndex++] = arr[index1++];
}
while (index2 <= end2) {
result[resultIndex++] = arr[index2++];
}
// 将 result 操作区间的数字拷贝到 arr 数组中,以便下次比较
for (int i = start; i <= end; i++) {
arr[i] = result[i];
}
}
在这份代码中,我们统一使用 result 数组作为递归过程中的临时数组,所以merge 函数接收的参数不再是两个数组,而是 result 数组中需要合并的两个数组的首尾下标。根据首尾下标可以分别计算出两个有序数组的首尾下标 start1、end1、start2、end2,之后的过程就和之前合并两个有序数组的代码类似了。
这份代码还可以再精简一下,我们可以去掉一些不会改变的临时变量。比如 start1 始终等于 start,end2 始终等于 end,end1 始终等于 middle。并且分析可知,resultIndex 的值始终等于 start 加上 index1 和 index2 移动的距离。即:
/
resultIndex = start + (index1 - start1) + (index2 - start2)
将 start1 == start 代入,化简得:
resultIndex = index1 + index2 - start2
最终得到的归并排序的代码为
public static void mergeSort(int[] arr) {
if (arr.length == 0) return;
int[] result = new int[arr.length];
mergeSort(arr, 0, arr.length - 1, result);
}
// 对 arr 的 [start, end] 区间归并排序
private static void mergeSort(int[] arr, int start, int end, int[] result) {
// 只剩下一个数字,停止拆分
if (start == end) return;
int middle = (start + end) / 2;
// 拆分左边区域,并将归并排序的结果保存到 result 的 [start, middle] 区间
mergeSort(arr, start, middle, result);
// 拆分右边区域,并将归并排序的结果保存到 result 的 [middle + 1, end] 区间
mergeSort(arr, middle + 1, end, result);
// 合并左右区域到 result 的 [start, end] 区间
merge(arr, start, end, result);
}
// 将 result 的 [start, middle] 和 [middle + 1, end] 区间合并
private static void merge(int[] arr, int start, int end, int[] result) {
int end1 = (start + end) / 2;
int start2 = end1 + 1;
// 用来遍历数组的指针
int index1 = start;
int index2 = start2;
while (index1 <= end1 && index2 <= end) {
if (arr[index1] <= arr[index2]) {
result[index1 + index2 - start2] = arr[index1++];
} else {
result[index1 + index2 - start2] = arr[index2++];
}
}
// 将剩余数字补到结果数组之后
while (index1 <= end1) {
result[index1 + index2 - start2] = arr[index1++];
}
while (index2 <= end) {
result[index1 + index2 - start2] = arr[index2++];
}
// 将 result 操作区间的数字拷贝到 arr 数组中,以便下次比较
while (start <= end) {
arr[start] = result[start++];
}
}
原地归并排序?
现在的归并排序看起来仍”美中不足”,那就是仍然需要开辟额外的空间,能不能实现不开辟额外空间的归并排序呢?好像是可以做到的。在一些文章中,将这样的归并排序称之为 In-Place Merge Sort,直译为原地归并排序。
代码实现思路主要有两种:
public static void mergeSort(int[] arr) {
if (arr.length == 0) return;
mergeSort(arr, 0, arr.length - 1);
}
// 对 arr 的 [start, end] 区间归并排序
private static void mergeSort(int[] arr, int start, int end) {
// 只剩下一个数字,停止拆分
if (start == end) return;
int middle = (start + end) / 2;
// 拆分左边区域
mergeSort(arr, start, middle);
// 拆分右边区域
mergeSort(arr, middle + 1, end);
// 合并左右区域
merge(arr, start, end);
}
// 将 arr 的 [start, middle] 和 [middle + 1, end] 区间合并
private static void merge(int[] arr, int start, int end) {
int end1 = (start + end) / 2;
int start2 = end1 + 1;
// 用来遍历数组的指针
int index1 = start;
int index2 = start2;
while (index1 <= end1 && index2 <= end) {
if (arr[index1] <= arr[index2]) {
index1++;
} else {
// 右边区域的这个数字比左边区域的数字小,于是它站了起来
int value = arr[index2];
int index = index2;
// 前面的数字不断地后移
while (index > index1) {
arr[index] = arr[index - 1];
index--;
}
// 这个数字坐到 index1 所在的位置上
arr[index] = value;
// 更新所有下标,使其前进一格
index1++;
index2++;
end1++;
}
}
}
/
这段代码在合并 arr 的 [start, middle] 区间和 [middle + 1, end] 区间时,将两个区间较小的数字移动到 index1 的位置,并且将左边区域不断后移,目的是给新插入的数字腾出位置。最后更新两个区间的下标,继续合并更新后的区间。
第二种实现思路:
public static void mergeSort(int[] arr) {
if (arr.length == 0) return;
mergeSort(arr, 0, arr.length - 1);
}
// 对 arr 的 [start, end] 区间归并排序
private static void mergeSort(int[] arr, int start, int end) {
// 只剩下一个数字,停止拆分
if (start == end) return;
int middle = (start + end) / 2;
// 拆分左边区域
mergeSort(arr, start, middle);
// 拆分右边区域
mergeSort(arr, middle + 1, end);
// 合并左右区域
merge(arr, start, end);
}
// 将 arr 的 [start, middle] 和 [middle + 1, end] 区间合并
private static void merge(int[] arr, int start, int end) {
int end1 = (start + end) / 2;
int start2 = end1 + 1;
// 用来遍历数组的指针
int index1 = start;
while (index1 <= end1 && start2 <= end) {
if (arr[index1] > arr[start2]) {
// 将 index1 和 start2 下标的数字交换
exchange(arr, index1, start2);
if (start2 != end) {
// 调整交换到 start2 上的这个数字的位置,使右边区域继续保持有序
int value = arr[start2];
int index = start2;
// 右边区域比 arr[start2] 小的数字不断前移
while (index < end && arr[index + 1] < value) {
arr[index] = arr[index + 1];
index++;
}
// 交换到右边区域的这个数字找到了自己合适的位置,坐下
arr[index] = value;
}
}
index1++;
}
}
private static void exchange(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/
这段代码在合并区间时,同样是将两个区间中较小的数字移到 index1 的位置,不过采用的是两个区间的首个数字直接交换的思路,交换完成后,将交换到右边区间的数字不断后移,以使得右边区间继续保持有序。
这两种思路看起来都很美好,但这真的实现了原地归并排序吗?
分析代码可以看出,这样实现的归并本质上是插入排序!前文已经说到,在插入排序中,腾出位置是一个比较复杂的过程,而且这个过程必然导致增加一轮遍历。在这两份代码中,每一次合并数组时,都使用了两层循环,目的就是不断腾挪位置以插入新数字,可以看出这里合并的效率是非常低的。这两种排序算法的时间复杂度都达到了 O(n^2)级,不能称之为归并排序。它们只是借用了归并排序的递归框架而已。
也就是说,所谓的原地归并排序事实上并不存在,许多算法书籍中都没有收录这种算法。它打着归并排序的幌子,卖的是插入排序的思想,实际排序效率比归并排序低得多。
时间复杂度 & 空间复杂度
归并排序的复杂度比较容易分析,拆分数组的过程中,会将数组拆分 logn 次,每层执行的比较次数都约等于 n 次,所以时间复杂度是 O(nlogn)O(nlogn)。
空间复杂度是 O(n)O(n),主要占用空间的就是我们在排序前创建的长度为 n 的 result 数组。
分析归并的过程可知,归并排序是一种稳定的排序算法。其中,对算法稳定性非常重要的一行代码是:
if (arr[index1] <= arr[index2]) {
result[index1 + index2 - start2] = arr[index1++];
}
在这里我们通过arr[index1] <= arr[index2]来合并两个有序数组,保证了原数组中,相同的元素相对顺序不会变化,如果这里的比较条件写成了arr[index1] < arr[index2],则归并排序将变得不稳定。
总结起来,归并排序分成两步,一是拆分数组,二是合并数组,它是分治思想的典型应用。分治的意思是“分而治之”,分的时候体现了二分的思想,“一尺之棰,日取其半,logn 世竭”,治是一个滚雪球的过程,将 1 个数字组成的有序数组合并成一个包含 2 个数字的有序数组,再将 2 个数字组成的有序数组合并成包含 4 个数字的有序数组…如《活着》一书中的经典名句:“小鸡长大了就变成了鹅;鹅长大了,就变成了羊;羊再长大了,就变成了牛…”
由于性能较好,且排序稳定,归并排序应用非常广泛,Arrays.sort() 源码中的 TimSort就是归并排序的优化版。

堆排序
数组、链表都是一维的数据结构,相对来说比较容易理解,而堆是二维的数据结构,对抽象思维的要求更高,所以许多程序员“闻堆色变”。但堆又是数据结构进阶必经的一步,我们不妨静下心来,将其梳理清楚。
堆:符合以下两个条件之一的完全二叉树:
根节点的值 ≥ 子节点的值,这样的堆被称之为最大堆,或大顶堆;
根节点的值 ≤ 子节点的值,这样的堆被称之为最小堆,或小顶堆。

为了有一个轻松的开场,我们先来看一个程序员的段子放松一下:
你有哪些用计算机技能解决生活问题的经历?
我认识一个大牛,他不喜欢洗袜子,又不喜欢袜子的臭味。于是他买了很多样式一样的袜子,把这些袜子放在地上,根据臭的程度,摆一个二叉堆。每天早上,他 pop 两只最“香”的袜子,穿上;晚上回到家,把袜子脱下来,push 到堆里。某一天,top 的袜子超过他的耐臭能力,全扔掉,买新的。
如果我们将袜子 “臭的程度” 量化,这位大牛每天做的事情就是构建一个大顶堆,然后将堆顶的袜子取出来。再调整剩下的袜子,构建出一个新的大顶堆,再次取出堆顶的袜子。这个过程使用的就是堆排序的思想,它是由 J. W. J. Williams 在1964年发明的。
堆排序过程如下:
用数列构建出一个大顶堆,取出堆顶的数字;
调整剩余的数字,构建出新的大顶堆,再次取出堆顶的数字;
循环往复,完成整个排序。
整体的思路就是这么简单,我们需要解决的问题有两个:
如何用数列构建出一个大顶堆;
取出堆顶的数字后,如何将剩余的数字调整成新的大顶堆。
构建大顶堆 & 调整堆
构建大顶堆有两种方式:
方案一:从 0 开始,将每个数字依次插入堆中,一边插入,一边调整堆的结构,使其满足大顶堆的要求;
方案二:将整个数列的初始状态视作一棵完全二叉树,自底向上调整树的结构,使其满足大顶堆的要求。
在介绍堆排序具体实现之前,我们先要了解完全二叉树的几个性质。将根节点的下标视为 0,则完全二叉树有如下性质:
对于完全二叉树中的第 i 个数,它的左子节点下标:left = 2i + 1
对于完全二叉树中的第 i 个数,它的右子节点下标:right = left + 1
对于有 n 个元素的完全二叉树(n >2),它的最后一个非叶子结点的下标:n/2 - 1
public static void heapSort(int[] arr) {
// 构建初始大顶堆
buildMaxHeap(arr);
for (int i = arr.length - 1; i > 0; i--) {
// 将最大值放到数组最后
exchange(arr, 0, i);
// 调整剩余数组,使其满足大顶堆
maxHeapify(arr, 0, i);
}
}
// 构建初始大顶堆
public static void buildMaxHeap(int[] arr) {
// 从最后一个非叶子结点开始调整大顶堆,最后一个非叶子结点的下标就是 arr.length / 2-1
for (int i = arr.length / 2 - 1; i >= 0; i--) {
maxHeapify(arr, i, arr.length);
}
}
// 调整大顶堆,第三个参数表示剩余未排序的数字的数量,也就是剩余堆的大小
private static void maxHeapify(int[] arr, int i, int heapSize) {
// 左子结点下标
int l = 2 * i + 1;
// 右子结点下标
int r = l + 1;
// 记录根结点、左子树结点、右子树结点三者中的最大值下标
int largest = i;
// 与左子树结点比较
if (l < heapSize && arr[l] > arr[largest]) {
largest = l;
}
// 与右子树结点比较
if (r < heapSize && arr[r] > arr[largest]) {
largest = r;
}
if (largest != i) {
// 将最大值交换为根结点
exchange(arr, i, largest);
// 再次调整交换数字后的大顶堆
maxHeapify(arr, largest, heapSize);
}
}
// 交换元素
private static void exchange(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
堆排序的第一步就是构建大顶堆,对应代码中的 buildMaxHeap 函数。我们将数组视作一颗完全二叉树,从它的最后一个非叶子结点开始,调整此结点和其左右子树,使这三个数字构成一个大顶堆。
调整过程由 maxHeapify 函数处理, maxHeapify 函数记录了最大值的下标,根结点和其左右子树结点在经过比较之后,将最大值交换到根结点位置。这样,这三个数字就构成了一个大顶堆。
需要注意的是,如果根结点和左右子树结点任何一个数字发生了交换,则还需要保证调整后的子树仍然是大顶堆,这是一个递归的过程。
这里比较难理解,打个比方:构建大顶堆的过程就是一堆数字比赛谁更大。比赛过程分为初赛、复赛、决赛。但不是所有人都会参加初赛,只有叶子结点和第一批非叶子结点会进行三人组初赛。选出三者最大的一个,站到三人组的根结点位置,然后继续参加后面的复赛。
而有的人生来就在上层,比如李小胖,因为他是数列的第一个数字,所以它一出生就是二叉树的根结点,躺在那里坐等一场决赛。
当王大强和张壮壮,经历了重重比拼来到了李小胖的左右子树结点位置。他们三个人开始决赛。王大强和张壮壮是靠实打实的实力打上来的,他们已经确认过自己是小组最强。而李小胖之前一直躺在这里等决赛。如果李小胖赢了他们两个,说明李小胖是所有小组里最强的,毋庸置疑,他可以继续坐在冠军宝座。
但李小胖如果输给了其中任何一个人,比如输给了王大强。王大强会和张壮壮对决,选出本次构建大顶堆的冠军。但李小胖能够坐享其成获得第三名吗?生活中或许会有这样的黑幕,但程序不会欺骗我们。李小胖跌落神坛之后,就要从王大强的打拼路线回去,继续向下比较,找到自己真正实力所在的真实位置。这就是 maxHeapify 中会继续递归调用 maxHeapify 的原因。
当构建出大顶堆之后,就要把冠军挪到数列最后,深藏功与名。来到冠军宝座的新人又要和李小胖一样,开始向下比较,找到自己的真实位置,使得剩下的 n - 1 个数字构建成新的大顶堆。这就是 heapSort 方法的 for 循环中,调用 maxHeapify 的原因。
变量 heapSize 用来记录还剩下多少个数字没有排序完成,每当交换了一个堆顶的数字,heapSize 就会减 1。在 maxHeapify 方法中,使用 heapSize 来限制剩下的选手,不要和已经躺在数组最后,当过冠军的人比较,免得被暴揍。
这就是堆排序的思想。学习时我们采用的是最简单的代码实现,在熟练掌握了之后我们就可以加一些小技巧以获得更高的效率。我们知道计算机采用二进制来存储数据,数字左移一位表示乘以 2,右移一位表示除以 2。所以堆排序代码中的arr.length / 2 - 1 可以修改为 (arr.length >> 1) - 1,左子结点下标2 * i + 1可以修改为(i << 1) + 1。需要注意的是,位运算符的优先级比加减运算的优先级低,所以必须给位运算过程加上括号。
在有的文章中,作者将堆的根节点下标视为 1,这样做的好处是使得第 i 个结点的左子结点下标为 2i,右子结点下标为 2i + 1,看似更方便,但笔者认为这种写法看起来不够正统,毕竟程序员都是从 0 开始计数,故本文未采取这种实现,但两种实现思路的核心思想都是一致的。
时间复杂度 & 空间复杂度
堆排序分为两个阶段:初始化建堆(buildMaxHeap)和重建堆(maxHeapify,直译为大顶堆化)。所以时间复杂度要从这两个方面分析。
根据数学运算可以推导出初始化建堆的时间复杂度为 O(n)O(n),重建堆的时间复杂度为 O(nlogn)O(nlogn),故堆排序总的时间复杂度为 O(nlogn)O(nlogn)。推导过程较为复杂,故不再给出证明过程。
堆排序的空间复杂度为 O(1)O(1),只需要常数级的临时变量。
堆排序是一个优秀的排序算法,但是在实际应用中,快速排序的性能一般会优于堆排序,我们将在下一节介绍快速排序的思想。
sort
sort是泛型的,可以用于任何合理的容器组合、元素类型和比较算法
struct Record {
string name;
// ...
};
struct name_compare { // compare Records using "name" as the key
bool operator()(const Record& a, const Record& b) const
{ return a.name<b.name; }
};
void f(vector<Record>& vs)
{
sort(vs.begin(), vs.end(), name_compare());
// ...
}
sort具备类型安全性,对于标准类型,也不必写compare()函数。同时因为它更好的利用了c++的内联语法语义。
STL Sort 源码分析
STL sort算法的实现,数据量大时采用Quick Sort, 分段递归排序,一旦分段后的数据量小于某个门槛,为避免Quick Sort的递归调用带来过大的额外负荷(overhead),就改用insertion sort,如果递归层次过深,还会改用Heap Sort。
Insertion Sort
STL不开放的函数,其函数名都是加上双下划线,表示内部使用。
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
if (first == last)
return;
for(RandomAccessIterator i = first + 1; i != last; ++i)
__linear_insert(first, i, value_type(first));
}
template <class RandomAccessIterator, class T>
inline void __linear_insert(RandomAccessIterator first,
RandomAccessIterator last,
T*) {
T value = *last;
if(value < *first) {
copy_backward(first, last, last + 1);
*first = value;
}
else
__unguarded_linear_insert(last, value);
}

若有收获,就点个赞吧
0 人点赞
