C++类内引入typedef
class MyClass{public:typedef long INDEX;};
上面的语句是放在了public段中,是可以在类外部使用,例如:MyClass::INDEX usercode
如果放在private段中,则只能在类内部使用。
引入仅能在类内部起作用的类型别名的初衷在于:通过限制该类型别名的作用域来防止冲突。比如同样表示长度,可能有的类中只需char即可,有的类中要用int,而有的类可能连long都嫌小。那么,一概起个别名叫”size”,不同的类中又不同的定义。
“类型别名”和变量、函数一样具有作用域。
C++11 added alias declarations, which are generalization of typedef, allowing templates:
template <size_t N>using Vector = Matrix<N, 1>;//The type Vector<3> is equivalent to Matrix<3, 1>.
对于typedef来一个现实的例子,std::alloc 的二层级配置
#ifdef __USE_MALLOC...typedef __malloc_alloc_template<0> malloc_alloc;typedef malloc_alloc alloc;#else...typedef __default_alloc_template<__NODE_ALLOCATOR_THERADS, 0> alloc;#endif
整型5取反后的结果是-6
负数是按位取反再加一
C++三大特性
C++的三大特性是 封装 , 继承 和 多态 .
封装可以隐藏实现细节,使得代码模块化,继承可以扩展已存在的模块,它们目的都是为了:代码重用。
封装的好处:
- 将变化隔离
- 便于使用
- 提高重用性
- 提高安全性
封装的原则:
- 将不需要对外提供的内容都隐藏起来
- 把属性都隐藏,提供公共方法对其访问
多态 是指相同的操作和函数在不同的对象上会有不同的行为和得到不同的结果,不同的对象,收到同一个消息,会得到不同的结果,这种现象叫做多态。
多态是为了实现另一个目的:接口重用。例如:打羽毛球,打篮球,打保龄球,这里的“打”就是多态。 多态性可以简单概括为“一个接口,多种实现”,是通过虚函数实现的。基类提供一个虚接口,其派生类重写这个接口,这样就构成了多态,简单说,就是某一类事物多种存在形态。
多态的体现:
- 父类的引用指向了自己子类对象
- 父类的引用也可以接收自己的子类对象
多态的前提:
- 必须是类与类之间有关系。要么继承,要么实现
- 存在覆盖
多态的好处:
- 多态的出现大大的提高程序的扩展性
多态的弊端:
- 提高了扩展性,但是只能使用父类的引用访问父类中的成员
多态
多态就是不同继承类的对象,对同一消息做出不同的响应,基类的指针指向或绑定到派生类的对象,使得基类指针呈现不同的表现方式。在基类的函数前加上 virtual 关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
实现方法
多态是通过虚函数实现的,虚函数的地址保存在虚函数表中,虚函数表的地址保存在含有虚函数的类的实例对象的内存空间中。
实现过程
在类中用 virtual 关键字声明的函数叫做虚函数;
存在虚函数的类都有一个虚函数表,当创建一个该类的对象时,该对象有一个指向虚函数表的虚表指针(虚函数表和类对应的,虚表指针是和对象对应);
当基类指针指向派生类对象,基类指针调用虚函数时,基类指针指向派生类的虚表指针,由于该虚表指针指向派生类虚函数表,通过遍历虚表,寻找相应的虚函数。
#include <iostream>using namespace std;class Base{public:virtual void fun() { cout << "Base::fun()" << endl; }virtual void fun1() { cout << "Base::fun1()" << endl; }virtual void fun2() { cout << "Base::fun2()" << endl; }};class Derive : public Base{public:void fun() { cout << "Derive::fun()" << endl; }virtual void D_fun1() { cout << "Derive::D_fun1()" << endl; }virtual void D_fun2() { cout << "Derive::D_fun2()" << endl; }};int main(){Base *p = new Derive();p->fun(); // Derive::fun() 调用派生类中的虚函数return 0;}
识别函数或指针
void ((fp1)(int))[10]: fp1是一个指针,指向一个函数,这个函数的参数为int型,函数的返回值是一个指针,这个指针指向一个数组,这个数组有10个元素,每个元素是一个void型指针。
float((fp2)(int,int,int))(int): fp2是一个指针,指向一个函数,这个函数的参数为3个int型,函数的返回值是一个指针,这个指针指向一个函数,这个函数的参数为int型,函数的返回值是float型。
int((fp3)())10:fp3是一个指针,指向一个函数,这个函数的参数为空,函数的返回值是一个指针,这个指针指向一个数组,这个数组有10个元素,每个元素是一个指针,指向一个函数,这个函数的参数为空,函数的返回值是int型
多态类中的虚函数表
虚拟函数表是在编译期就建立了,各个虚函数这时被组织成了一个虚拟函数的入口地址的数组。而对象的隐藏函数—虚拟函数表指针是在运行期,也就是构造函数被调用时进行初始化的,这时实现多态的关键。
虚函数表是在编译期创建完成,this指针是在运行期创建。
A vtable isn’t a C++ concept so if they are used and when they are created if they are used will depend on the implementation. (虚函数表并非是c++的concept,它什么时候被创建取决于如何实现它)
Typically, vtables are structures created at compile time (because they can be determined at compile time). When objects of a particular type are created at runtime they will have a vptr which will be initialized to point at a static vtable at construction time.(通常,虚函数列表是在编译器被创建出的一个结构体)
**
基类的析构函数不是虚函数,会带来的问题?
派生类的析构函数用不上,会造成资源的泄漏。
内存的分配方式有几种
- 从静态存储区分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static类型。
- 从栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。
之所以会有堆空间的原因在于:直到运行时才知道一个对象需要多少内存空间;不知道对象的生存期到底有多长。
全局变量和局部变量的区别
生命周期不同
全局变量随主程序创建而创建,随主程序销毁而销毁;
局部变量在局部函数内部,甚至局部循环体等内部存在,退出就不存在; 内存中分配在全局数据
使用方式不同
通过声明后全局变量程序的各个部分都可以用到;局部变量只能在局部使用;分配在栈区
操作系统和编译器通过内存分配的位置来知道
全局变量分配在全局数据段并且在程序开始运行的时候被加载。局部变量则分配在堆栈里面 。
Heap和Stack的区别
从空间分配的角度:
堆:堆空间是由程序员进行手动的分配和释放,若程序员没有释放内存,则程序结束之后,由操作系统进行内存的回收。申请效率低,容易产生内存碎片。
栈:栈空间是由操作系统自动的分配和释放,存放的是函数的参数值,局部变量等值。其操作方式类似于数据结构中的栈。申请效率高,但是无法自己控制。
从缓存方式的角度:
栈使用的是一级缓存,被调用时处于存储空间当中,使用完后立即被释放
堆存放在二级混存当中,声明周期由虚拟机的垃圾回收算法来决定(并不是一旦称为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
从申请后系统的响应:对于分配的栈空间,其大小是固定且空间连续(向低地址进行扩展),当程序申请的栈空间大于栈的剩余空间时,程序会产生溢出(向高地址进行扩展),堆空间,是由一系列不连续的空间所组成的,这些不连续的空间是通过链表而连接到一起的。
从数据结构的角度:
堆:堆可以被看成是一棵树
栈:一种后进先出的数据结构。
Stack空间有限,Heap是很大的自由存储区 C中的malloc函数分配的内存空间即在堆上,C++中对应的是new操作符。
程序在编译期对变量和函数分配内存都在栈上进行,且程序运行过程中函数调用时参数的传递也在栈上进行。
写一个不抛出异常的swap函数
- 当std::swap对你的类型效率不高时,提供一个swap成员函数,并确定这个函数不抛出异常
- 如果你提供一个member swap,也该提供一个non-member swap用来调用前者。对于classes(而非templates),也请特化std::swap
- 调用swap时应针对std::swap使用using声明式,然后调用swap并且不带任何”命名空间资格修饰”
- 为”用户定义类型”进行std::templates全特化是好的,但千万不要尝试在std内加入某些对std而言全新的东西
1LL
LL代表long long, 1LL 是为了在计算时,把int类型的变量转化为long long,然后再赋值给long long类型的变量。
unsigned char
unsigned char 是8bit,范围在0-255
charis the most basic data type in C. It stores a single character and requires a single byte of memory in almost all compilers.Now character datatype can be divided into 2 types:
- signed char
- unsigned char
**unsigned char**is a character datatype where the variable consumes all the 8 bits of the memory and there is no sign bit (which is there in signed char). So it means that the range of unsigned char data type ranges from 0 to 255.
关键词override
当对虚函数进行重写时,override可以判断是否正确的对虚函数进行重写(无意的重写和虚函数签名不匹配),比方说,是否在重写虚函数时引用了正确的参数等。override保证在派生类中声明的重载函数,与基类的虚函数有相同的签名。
不正确的覆盖虚函数的写法
// A CPP program without override keyword. Here// programmer makes a mistake and it is not caught.#include <iostream>using namespace std;class Base {public:// user wants to override this in// the derived classvirtual void func() {cout << "I am in base" << endl;}};class derived : public Base {public:// did a silly mistake by putting// an argument "int a"void func(int a) {cout << "I am in derived class" << endl;}};// Driver codeint main(){Base b;derived d;cout << "Compiled successfully" << endl;return 0;}
正确的覆盖虚函数写法
// A CPP program that uses override keyword so
// that any difference in function signature is
// caught during compilation.
#include <iostream>
using namespace std;
class Base {
public:
// user wants to override this in
// the derived class
virtual void func()
{
cout << "I am in base" << endl;
}
};
class derived : public Base {
public:
// did a silly mistake by putting
// an argument "int a"
void func(int a) override
{
cout << "I am in derived class" << endl;
}
};
int main()
{
Base b;
derived d;
cout << "Compiled successfully" << endl;
return 0;
}
关键字final
如果不希望类中的某些方法在被继承的时候被重写,则可以使用关键字final。同样的,如果final用在类上,则表明该类不想被继承。
阻止虚函数被继承
#include <iostream>
using namespace std;
class Base
{
public:
virtual void myfun() final
{
cout << "myfun() in Base";
}
};
class Derived : public Base
{
void myfun()
{
cout << "myfun() in Derived\n";
}
};
int main()
{
Derived d;
Base &b = d;
b.myfun();
return 0;
}
//Output
prog.cpp:14:10: error: virtual function ‘virtual void Derived::myfun()’
void myfun()
^
prog.cpp:7:18: error: overriding final function ‘virtual void Base::myfun()’
virtual void myfun() final
阻止类被继承
#include <iostream>
class Base final
{
};
class Derived : public Base
{
};
int main()
{
Derived d;
return 0;
}
//Output
error: cannot derive from ‘final’ base ‘Base’ in derived type ‘Derived’
class Derived : public Base
关键字auto
C++11中auto只是一个占位符,函数的返回类型是写在后面,这叫做trailing return type
auto func(T parameters) -> type
配合上关键字decltype,可以进行类型推导
template <typename U, typename V>
auto add(U a, V b) -> decltype(a + b);
这样可以通过a+b的型别推断出add函数的返回类型。
decltype关键字用于检查实体的声明类型或表达式的类型及值分类。
decltype (expression)
// 尾置返回允许我们在参数列表之后声明返回类型
template <typename It>
auto fcn(It beg, It end) -> decltype(*beg)
{
// 处理序列
return *beg; // 返回序列中一个元素的引用
}
// 为了使用模板参数成员,必须用 typename
template <typename It>
auto fcn2(It beg, It end) -> typename remove_reference<decltype(*beg)>::type
{
// 处理序列
return *beg; // 返回序列中一个元素的拷贝
}
C++14则允许在函数定义的时候,使用真正的auto,这个auto就会进行型别的推断
auto func(T parameters) {
return something;
}
//相当于 auto value = something;
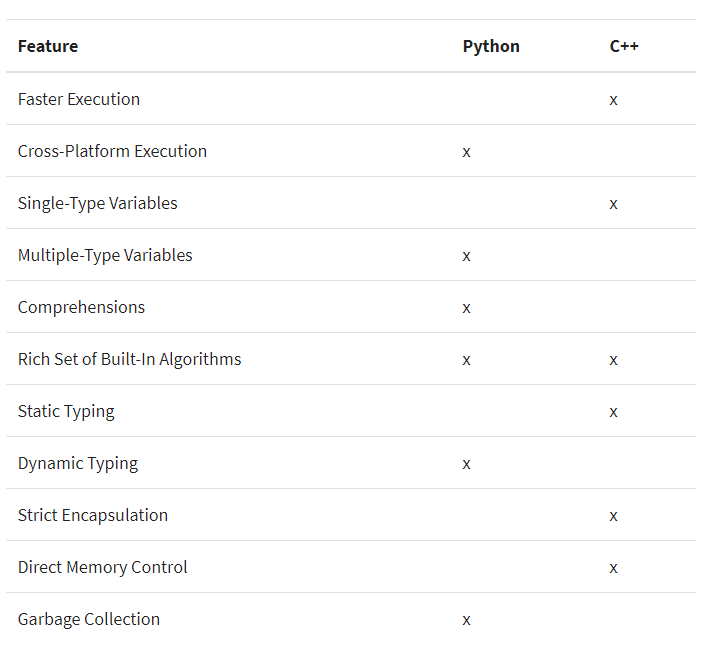
C++ 和 Python (https://realpython.com/python-vs-cpp/)
Compilation vs Virtual Machine
Unlike Python, C++ has variables that are assigned to a memory location, and you must indicate how much memory that variable will use:
C++被编译成直接在硬件上运行。而Python是运行在Python的虚拟机中。这意味着,如果想要在taget上运行python的程序,那么taget上必须要有python的虚拟机,而c++所针对taget所编译的版本,是可以直接运行在target之上的。所以如果你的程序跑在自己的环境中,比如saas平台,service是跑在自己的cloud当中。对于这种情况,则可以通过python实现逻辑,而需要对强调性能的部分,则可以通过C++进行实现,然后暴露接口给Python。同样的开发思路也在QT中,对与数据的处理采用QT C++进行实现,然后通过qface IDL创建接口,将数据通过接口暴露给QML
int an_int;
float a_big_array_of_floats[REALLY_BIG_NUMBER];
Syntax Differences

In Python, all objects are created in memory, and you apply labels to them. The labels themselves don’t have types, and they can be put on any type of object:
>>> my_flexible_name = 1
>>> my_flexible_name
1
>>> my_flexible_name = 'This is a string'
>>> my_flexible_name
'This is a string'
>>> my_flexible_name = [3, 'more info', 3.26]
>>> my_flexible_name
[3, 'more info', 3.26]
>>> my_flexible_name = print
>>> my_flexible_name
<built-in function print>
any and all can cover much of the same ground where C++ developers would look to std::find or std::find_if.
Static vs Dynamic Typing
C++ 是static typing, 对变量有明确的类型,即可以让开发人员提前知晓变量的类型,同时也有利于编译器进行优化。
C++ is statically typed, which means that each variable you use in your code must have a specific data type like
int,char,float, and so forth. You can only assign values of the correct type to a variable, unless you jump through some hoops. This has some advantages for both the developer and the compiler. The developer gains the advantage of knowing what the type of a particular variable is ahead of time, and therefore which operations are allowed. The compiler can use the type information to optimize the code, making it smaller, faster, or both. This advance knowledge comes at a cost, however. The parameters passed into a function must match the type expected by the function, which can reduce the flexibility and potential usefulness of the code.
Python是Dynamic Typing,对于类型的检查是放在了程序运行期间。
Dynamic typing is frequently referred to as duck typing.
def read_ten(file_like_object):
for line_number in range(10):
x = file_like_object.readline()
print(f"{line_number} = {x.strip()}")
with open("types.py") as f:
read_ten(f)
Python doesn’t have templates like C++, but it generally doesn’t need them. In Python, everything is a subclass of a single base type. This is what allows you to create duck typing functions like the ones above. The templating system in C++ allows you to create functions or algorithms that operate on multiple different types. This is quite powerful and can save you significant time and effort. However, it can also be a source of confusion and frustration, as compiler errors in templates can leave you baffled.
采用内存管理机制的python的弊端在于,无法确保程序对于同一事件的处理都是采用相同的时间,这对于实时性要求较高或是对于时许有严格要求的程序来说,无疑是增加了程序的不确定性。因此,对于这类程序来说,就必须采用C++来进行实现。对于我的导航应用程序,对于数据时许的处理,需要采用c++进行实现,这样才可以确保传递给QML的数据是正确的数据。
When you’re comparing Python vs C++, as when you’re comparing any two tools, each advantage comes with a trade-off. Python doesn’t require explicit memory management, but occasionally it will spend a longer amount of time than expected on garbage collection. The inverse is true for C++: your program will have consistent response times, but you’ll need to expend more effort in managing memory. In many programs the occasional garbage collection hit is unimportant. If you’re writing a script that only runs for 10 seconds, then you’re unlikely to notice the difference. Some situations, however, require consistent response times. Real-time systems are a great example, where responding to a piece of hardware in a fixed amount of time can be essential to the proper operation of your system. Systems with hard real-time requirements are some of the systems for which Python is a poor language choice. Having a tightly controlled system where you’re certain of the timing is a good use of C++. These are the types of issues to consider when you’re deciding on the language for a project.
友元函数和友元类
使用场景
普通函数定义为友元函数,使普通函数能够访问类的私有成员。
#include <iostream>
using namespace std;
class A
{
friend ostream &operator<<(ostream &_cout, const A &tmp); // 声明为类的友元函数
public:
A(int tmp) : var(tmp)
{
}
private:
int var;
};
ostream &operator<<(ostream &_cout, const A &tmp)
{
_cout << tmp.var;
return _cout;
}
int main()
{
A ex(4);
cout << ex << endl; // 4
return 0;
}
友元类:类之间共享数据
include <iostream>
using namespace std;
class A
{
friend class B;
public:
A() : var(10){}
A(int tmp) : var(tmp) {}
void fun()
{
cout << "fun():" << var << endl;
}
private:
int var;
};
class B
{
public:
B() {}
void fun()
{
cout << "fun():" << ex.var << endl; // 访问类 A 中的私有成员
}
private:
A ex;
};
int main()
{
B ex;
ex.fun(); // fun():10
return 0;
}
友元函数的危害性:
- 能访问私有成员
- 破坏封装性
- 友元关系不可传递或者说友元关系不可以被继承
- 友元关系的单向性(A是B的友元,那么B可以不是A的友元)
- 友元声明的形式及数量不受限制
Following are some important points about friend functions and classes: 1) Friends should be used only for limited purpose. too many functions or external classes are declared as friends of a class with protected or private data, it lessens the value of encapsulation of separate classes in object-oriented programming. 2) Friendship is not mutual. If class A is a friend of B, then B doesn’t become a friend of A automatically. 3) Friendship is not inherited (See this for more details) 4) The concept of friends is not there in Java.
友元类
A friend class can access private and protected members of other class in which it is declared as friend. It is sometimes useful to allow a particular class to access private members of other class. For example a LinkedList class may be allowed to access private members of Node.
class Node {
private:
int key;
Node* next;
/* Other members of Node Class */
// Now class LinkedList can
// access private members of Node
friend class LinkedList;
};
#include <iostream>
class A {
private:
int a;
public:
A() { a = 0; }
friend class B; // Friend Class
};
class B {
private:
int b;
public:
void showA(A& x)
{
// Since B is friend of A, it can access
// private members of A
std::cout << "A::a=" << x.a;
}
};
int main()
{
A a;
B b;
b.showA(a);
return 0;
}
//output
A::a=0
友元函数
友元函数可以是一个全局的函数,也可以是一个类的成员函数。
class Node {
private:
int key;
Node* next;
/* Other members of Node Class */
friend int LinkedList::search();
// Only search() of linkedList
// can access internal members
};
#include <iostream>
class B;
class A {
public:
void showB(B&);
};
class B {
private:
int b;
public:
B() { b = 0; }
friend void A::showB(B& x); // Friend function
};
void A::showB(B& x)
{
// Since showB() is friend of B, it can
// access private members of B
std::cout << "B::b = " << x.b;
}
int main()
{
A a;
B x;
a.showB(x);
return 0;
}
//Output
B::b = 0
#include <iostream>
class A {
int a;
public:
A() { a = 0; }
// global friend function
friend void showA(A&);
};
void showA(A& x)
{
// Since showA() is a friend, it can access
// private members of A
std::cout << "A::a=" << x.a;
}
int main()
{
A a;
showA(a);
return 0;
}
//Output
A::a = 0
下面的这个例子说明的是,友元关系是不能被继承的
#include <iostream>
using namespace std;
class A
{
protected:
int x;
public:
A() { x = 0;}
friend void show();
};
class B: public A
{
public:
B() : y (0) {}
private:
int y;
};
void show()
{
B b;
cout << "The default value of A::x = " << b.x;
// Can't access private member declared in class 'B'
cout << "The default value of B::y = " << b.y;
}
int main()
{
show();
getchar();
return 0;
}
如何定义一个只能在堆上生成对象的类
方法:将析构函数设置为私有
原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
如何定义一个只能在栈上生成对象的类
方法:将 new 和 delete 重载为私有
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。

若有收获,就点个赞吧
0 人点赞
