字符串
151 字符串反转
151. Reverse Words in a String
Given an input string, reverse the string word by word.Example 1: Input: “
the sky is blue“ Output: “blue is sky the“Example 2: Input: “ hello world! “ Output: “world! hello” Explanation: Your reversed string should not contain leading or trailing spaces.
Example 3:
Input: “a good example”
Output: “example good a”
Explanation: You need to reduce multiple spaces between two words to a single space in the reversed string.
Note:
- A word is defined as a sequence of non-space characters.
- Input string may contain leading or trailing spaces. However, your reversed string should not contain leading or trailing spaces.
- You need to reduce multiple spaces between two words to a single space in the reversed string.
Follow up:
For C programmers, try to solve it in-place in O(1) extra space.
class Solution(object):def reverseWords(self, s):""":type s: str:rtype: str"""slist = s.split()revertlist = slist[::-1]ret=""for tmp in revertlist:ret += tmp + " "return ret[:-1]
collections
这个模块实现了特定目标的容器,以提供Python标准内建容器 dict , list , set , 和 tuple 的替代选择。
namedtuple() |
创建命名元组子类的工厂函数 |
|---|---|
deque |
类似列表(list)的容器,实现了在两端快速添加(append)和弹出(pop) |
ChainMap |
类似字典(dict)的容器类,将多个映射集合到一个视图里面 |
Counter |
字典的子类,提供了可哈希对象的计数功能 |
OrderedDict |
字典的子类,保存了他们被添加的顺序 |
defaultdict |
字典的子类,提供了一个工厂函数,为字典查询提供一个默认值 |
UserDict |
封装了字典对象,简化了字典子类化 |
UserList |
封装了列表对象,简化了列表子类化 |
UserString |
封装了列表对象,简化了字符串子类化 |
Counter
class collections.Counter([iterable-or-mapping])
一个 Counter 是一个 dict 的子类,用于计数可哈希对象。它是一个集合,元素像字典键(key)一样存储,它们的计数存储为值。计数可以是任何整数值,包括0和负数。 Counter 类有点像其他语言中的 bags或multisets。
>>> from collections import Counter>>> c = Counter() # a new, empty counter>>> cCounter()>>> c = Counter('gallahad') # a new counter from an iterable>>> cCounter({'a': 3, 'l': 2, 'g': 1, 'h': 1, 'd': 1})>>> c = Counter({'red':4, 'blue': 2}) # a new counter from a mapping>>> cCounter({'red': 4, 'blue': 2})>>> c = Counter(cats=4, dogs=8) # a new counter from keywords args>>> cCounter({'dogs': 8, 'cats': 4})
347 前K个高频元素
347. 前 K 个高频元素
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。
你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的。
你可以按任意顺序返回答案。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/top-k-frequent-elements
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
方法一:Heap
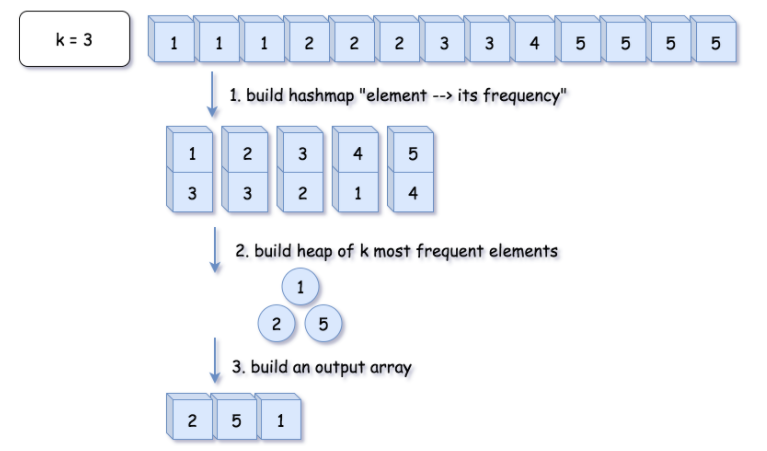
from collections import Counterclass Solution:def topKFrequent(self, nums: List[int], k: int) -> List[int]:# O(1) timeif k == len(nums):return nums# 1. build hash map : character and how often it appears# O(N) timecount = Counter(nums)# 2-3. build heap of top k frequent elements and# convert it into an output array# O(N log k) timereturn heapq.nlargest(k, count.keys(), key=count.get)
复杂度分析
时间复杂度:O(Nlog(k))。Counter 方法的复杂度是 O(N),建堆和输出的复杂度是 O(Nlog(k))。因此总复杂度为 O(N + N log(k)) =O(Nlog(k))。
空间复杂度:O(N)O(N),存储哈希表的开销。
注释
根据复杂度分析,方法对于小 k 的情况是很优的。但是如果 k 值很大,我们可以将算法改成删除频率最低的若干个元素。
方法二:Quickselect
Hoare’s selection algorithm
Quickselect is a textbook algorthm typically used to solve the problems “find kth something”: kth smallest, kth largest, kth most frequent, kth less frequent, etc. Like quicksort, quickselect was developed by Tony Hoare, and also known as Hoare’s selection algorithm.
参考资料
Lib/heapq.py
# -*- coding: latin-1 -*-"""Heap queue algorithm (a.k.a. priority queue).Heaps are arrays for which a[k] <= a[2*k+1] and a[k] <= a[2*k+2] forall k, counting elements from 0. For the sake of comparison,non-existing elements are considered to be infinite. The interestingproperty of a heap is that a[0] is always its smallest element.Usage:heap = [] # creates an empty heapheappush(heap, item) # pushes a new item on the heapitem = heappop(heap) # pops the smallest item from the heapitem = heap[0] # smallest item on the heap without popping itheapify(x) # transforms list into a heap, in-place, in linear timeitem = heapreplace(heap, item) # pops and returns smallest item, and adds# new item; the heap size is unchangedOur API differs from textbook heap algorithms as follows:- We use 0-based indexing. This makes the relationship between theindex for a node and the indexes for its children slightly lessobvious, but is more suitable since Python uses 0-based indexing.- Our heappop() method returns the smallest item, not the largest.These two make it possible to view the heap as a regular Python listwithout surprises: heap[0] is the smallest item, and heap.sort()maintains the heap invariant!"""# Original code by Kevin O'Connor, augmented by Tim Peters and Raymond Hettinger__about__ = """Heap queues[explanation by Fran�ois Pinard]Heaps are arrays for which a[k] <= a[2*k+1] and a[k] <= a[2*k+2] forall k, counting elements from 0. For the sake of comparison,non-existing elements are considered to be infinite. The interestingproperty of a heap is that a[0] is always its smallest element.The strange invariant above is meant to be an efficient memoryrepresentation for a tournament. The numbers below are `k', not a[k]:01 23 4 5 67 8 9 10 11 12 13 1415 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30In the tree above, each cell `k' is topping `2*k+1' and `2*k+2'. Ina usual binary tournament we see in sports, each cell is the winnerover the two cells it tops, and we can trace the winner down the treeto see all opponents s/he had. However, in many computer applicationsof such tournaments, we do not need to trace the history of a winner.To be more memory efficient, when a winner is promoted, we try toreplace it by something else at a lower level, and the rule becomesthat a cell and the two cells it tops contain three different items,but the top cell "wins" over the two topped cells.If this heap invariant is protected at all time, index 0 is clearlythe overall winner. The simplest algorithmic way to remove it andfind the "next" winner is to move some loser (let's say cell 30 in thediagram above) into the 0 position, and then percolate this new 0 downthe tree, exchanging values, until the invariant is re-established.This is clearly logarithmic on the total number of items in the tree.By iterating over all items, you get an O(n ln n) sort.A nice feature of this sort is that you can efficiently insert newitems while the sort is going on, provided that the inserted items arenot "better" than the last 0'th element you extracted. This isespecially useful in simulation contexts, where the tree holds allincoming events, and the "win" condition means the smallest scheduledtime. When an event schedule other events for execution, they arescheduled into the future, so they can easily go into the heap. So, aheap is a good structure for implementing schedulers (this is what Iused for my MIDI sequencer :-).Various structures for implementing schedulers have been extensivelystudied, and heaps are good for this, as they are reasonably speedy,the speed is almost constant, and the worst case is not much differentthan the average case. However, there are other representations whichare more efficient overall, yet the worst cases might be terrible.Heaps are also very useful in big disk sorts. You most probably allknow that a big sort implies producing "runs" (which are pre-sortedsequences, which size is usually related to the amount of CPU memory),followed by a merging passes for these runs, which merging is oftenvery cleverly organised[1]. It is very important that the initialsort produces the longest runs possible. Tournaments are a good wayto that. If, using all the memory available to hold a tournament, youreplace and percolate items that happen to fit the current run, you'llproduce runs which are twice the size of the memory for random input,and much better for input fuzzily ordered.Moreover, if you output the 0'th item on disk and get an input whichmay not fit in the current tournament (because the value "wins" overthe last output value), it cannot fit in the heap, so the size of theheap decreases. The freed memory could be cleverly reused immediatelyfor progressively building a second heap, which grows at exactly thesame rate the first heap is melting. When the first heap completelyvanishes, you switch heaps and start a new run. Clever and quiteeffective!In a word, heaps are useful memory structures to know. I use them ina few applications, and I think it is good to keep a `heap' modulearound. :-)--------------------[1] The disk balancing algorithms which are current, nowadays, aremore annoying than clever, and this is a consequence of the seekingcapabilities of the disks. On devices which cannot seek, like bigtape drives, the story was quite different, and one had to be veryclever to ensure (far in advance) that each tape movement will be themost effective possible (that is, will best participate at"progressing" the merge). Some tapes were even able to readbackwards, and this was also used to avoid the rewinding time.Believe me, real good tape sorts were quite spectacular to watch!From all times, sorting has always been a Great Art! :-)"""__all__ = ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge','nlargest', 'nsmallest', 'heappushpop']from itertools import islice, count, imap, izip, tee, chainfrom operator import itemgetterdef cmp_lt(x, y):# Use __lt__ if available; otherwise, try __le__.# In Py3.x, only __lt__ will be called.return (x < y) if hasattr(x, '__lt__') else (not y <= x)def heappush(heap, item):"""Push item onto heap, maintaining the heap invariant."""heap.append(item)_siftdown(heap, 0, len(heap)-1)def heappop(heap):"""Pop the smallest item off the heap, maintaining the heap invariant."""lastelt = heap.pop() # raises appropriate IndexError if heap is emptyif heap:returnitem = heap[0]heap[0] = lastelt_siftup(heap, 0)else:returnitem = lasteltreturn returnitemdef heapreplace(heap, item):"""Pop and return the current smallest value, and add the new item.This is more efficient than heappop() followed by heappush(), and can bemore appropriate when using a fixed-size heap. Note that the valuereturned may be larger than item! That constrains reasonable uses ofthis routine unless written as part of a conditional replacement:if item > heap[0]:item = heapreplace(heap, item)"""returnitem = heap[0] # raises appropriate IndexError if heap is emptyheap[0] = item_siftup(heap, 0)return returnitemdef heappushpop(heap, item):"""Fast version of a heappush followed by a heappop."""if heap and cmp_lt(heap[0], item):item, heap[0] = heap[0], item_siftup(heap, 0)return itemdef heapify(x):"""Transform list into a heap, in-place, in O(len(x)) time."""n = len(x)# Transform bottom-up. The largest index there's any point to looking at# is the largest with a child index in-range, so must have 2*i + 1 < n,# or i < (n-1)/2. If n is even = 2*j, this is (2*j-1)/2 = j-1/2 so# j-1 is the largest, which is n//2 - 1. If n is odd = 2*j+1, this is# (2*j+1-1)/2 = j so j-1 is the largest, and that's again n//2-1.for i in reversed(xrange(n//2)):_siftup(x, i)def _heappushpop_max(heap, item):"""Maxheap version of a heappush followed by a heappop."""if heap and cmp_lt(item, heap[0]):item, heap[0] = heap[0], item_siftup_max(heap, 0)return itemdef _heapify_max(x):"""Transform list into a maxheap, in-place, in O(len(x)) time."""n = len(x)for i in reversed(range(n//2)):_siftup_max(x, i)def nlargest(n, iterable):"""Find the n largest elements in a dataset.Equivalent to: sorted(iterable, reverse=True)[:n]"""if n < 0:return []it = iter(iterable)result = list(islice(it, n))if not result:return resultheapify(result)_heappushpop = heappushpopfor elem in it:_heappushpop(result, elem)result.sort(reverse=True)return resultdef nsmallest(n, iterable):"""Find the n smallest elements in a dataset.Equivalent to: sorted(iterable)[:n]"""if n < 0:return []it = iter(iterable)result = list(islice(it, n))if not result:return result_heapify_max(result)_heappushpop = _heappushpop_maxfor elem in it:_heappushpop(result, elem)result.sort()return result# 'heap' is a heap at all indices >= startpos, except possibly for pos. pos# is the index of a leaf with a possibly out-of-order value. Restore the# heap invariant.def _siftdown(heap, startpos, pos):newitem = heap[pos]# Follow the path to the root, moving parents down until finding a place# newitem fits.while pos > startpos:parentpos = (pos - 1) >> 1parent = heap[parentpos]if cmp_lt(newitem, parent):heap[pos] = parentpos = parentposcontinuebreakheap[pos] = newitem# The child indices of heap index pos are already heaps, and we want to make# a heap at index pos too. We do this by bubbling the smaller child of# pos up (and so on with that child's children, etc) until hitting a leaf,# then using _siftdown to move the oddball originally at index pos into place.## We *could* break out of the loop as soon as we find a pos where newitem <=# both its children, but turns out that's not a good idea, and despite that# many books write the algorithm that way. During a heap pop, the last array# element is sifted in, and that tends to be large, so that comparing it# against values starting from the root usually doesn't pay (= usually doesn't# get us out of the loop early). See Knuth, Volume 3, where this is# explained and quantified in an exercise.## Cutting the # of comparisons is important, since these routines have no# way to extract "the priority" from an array element, so that intelligence# is likely to be hiding in custom __cmp__ methods, or in array elements# storing (priority, record) tuples. Comparisons are thus potentially# expensive.## On random arrays of length 1000, making this change cut the number of# comparisons made by heapify() a little, and those made by exhaustive# heappop() a lot, in accord with theory. Here are typical results from 3# runs (3 just to demonstrate how small the variance is):## Compares needed by heapify Compares needed by 1000 heappops# -------------------------- --------------------------------# 1837 cut to 1663 14996 cut to 8680# 1855 cut to 1659 14966 cut to 8678# 1847 cut to 1660 15024 cut to 8703## Building the heap by using heappush() 1000 times instead required# 2198, 2148, and 2219 compares: heapify() is more efficient, when# you can use it.## The total compares needed by list.sort() on the same lists were 8627,# 8627, and 8632 (this should be compared to the sum of heapify() and# heappop() compares): list.sort() is (unsurprisingly!) more efficient# for sorting.def _siftup(heap, pos):endpos = len(heap)startpos = posnewitem = heap[pos]# Bubble up the smaller child until hitting a leaf.childpos = 2*pos + 1 # leftmost child positionwhile childpos < endpos:# Set childpos to index of smaller child.rightpos = childpos + 1if rightpos < endpos and not cmp_lt(heap[childpos], heap[rightpos]):childpos = rightpos# Move the smaller child up.heap[pos] = heap[childpos]pos = childposchildpos = 2*pos + 1# The leaf at pos is empty now. Put newitem there, and bubble it up# to its final resting place (by sifting its parents down).heap[pos] = newitem_siftdown(heap, startpos, pos)def _siftdown_max(heap, startpos, pos):'Maxheap variant of _siftdown'newitem = heap[pos]# Follow the path to the root, moving parents down until finding a place# newitem fits.while pos > startpos:parentpos = (pos - 1) >> 1parent = heap[parentpos]if cmp_lt(parent, newitem):heap[pos] = parentpos = parentposcontinuebreakheap[pos] = newitemdef _siftup_max(heap, pos):'Maxheap variant of _siftup'endpos = len(heap)startpos = posnewitem = heap[pos]# Bubble up the larger child until hitting a leaf.childpos = 2*pos + 1 # leftmost child positionwhile childpos < endpos:# Set childpos to index of larger child.rightpos = childpos + 1if rightpos < endpos and not cmp_lt(heap[rightpos], heap[childpos]):childpos = rightpos# Move the larger child up.heap[pos] = heap[childpos]pos = childposchildpos = 2*pos + 1# The leaf at pos is empty now. Put newitem there, and bubble it up# to its final resting place (by sifting its parents down).heap[pos] = newitem_siftdown_max(heap, startpos, pos)# If available, use C implementationtry:from _heapq import *except ImportError:passdef merge(*iterables):'''Merge multiple sorted inputs into a single sorted output.Similar to sorted(itertools.chain(*iterables)) but returns a generator,does not pull the data into memory all at once, and assumes that each ofthe input streams is already sorted (smallest to largest).>>> list(merge([1,3,5,7], [0,2,4,8], [5,10,15,20], [], [25]))[0, 1, 2, 3, 4, 5, 5, 7, 8, 10, 15, 20, 25]'''_heappop, _heapreplace, _StopIteration = heappop, heapreplace, StopIteration_len = lenh = []h_append = h.appendfor itnum, it in enumerate(map(iter, iterables)):try:next = it.nexth_append([next(), itnum, next])except _StopIteration:passheapify(h)while _len(h) > 1:try:while 1:v, itnum, next = s = h[0]yield vs[0] = next() # raises StopIteration when exhausted_heapreplace(h, s) # restore heap conditionexcept _StopIteration:_heappop(h) # remove empty iteratorif h:# fast case when only a single iterator remainsv, itnum, next = h[0]yield vfor v in next.__self__:yield v# Extend the implementations of nsmallest and nlargest to use a key= argument_nsmallest = nsmallestdef nsmallest(n, iterable, key=None):"""Find the n smallest elements in a dataset.Equivalent to: sorted(iterable, key=key)[:n]"""# Short-cut for n==1 is to use min() when len(iterable)>0if n == 1:it = iter(iterable)head = list(islice(it, 1))if not head:return []if key is None:return [min(chain(head, it))]return [min(chain(head, it), key=key)]# When n>=size, it's faster to use sorted()try:size = len(iterable)except (TypeError, AttributeError):passelse:if n >= size:return sorted(iterable, key=key)[:n]# When key is none, use simpler decorationif key is None:it = izip(iterable, count()) # decorateresult = _nsmallest(n, it)return map(itemgetter(0), result) # undecorate# General case, slowest methodin1, in2 = tee(iterable)it = izip(imap(key, in1), count(), in2) # decorateresult = _nsmallest(n, it)return map(itemgetter(2), result) # undecorate_nlargest = nlargestdef nlargest(n, iterable, key=None):"""Find the n largest elements in a dataset.Equivalent to: sorted(iterable, key=key, reverse=True)[:n]"""# Short-cut for n==1 is to use max() when len(iterable)>0if n == 1:it = iter(iterable)head = list(islice(it, 1))if not head:return []if key is None:return [max(chain(head, it))]return [max(chain(head, it), key=key)]# When n>=size, it's faster to use sorted()try:size = len(iterable)except (TypeError, AttributeError):passelse:if n >= size:return sorted(iterable, key=key, reverse=True)[:n]# When key is none, use simpler decorationif key is None:it = izip(iterable, count(0,-1)) # decorateresult = _nlargest(n, it)return map(itemgetter(0), result) # undecorate# General case, slowest methodin1, in2 = tee(iterable)it = izip(imap(key, in1), count(0,-1), in2) # decorateresult = _nlargest(n, it)return map(itemgetter(2), result) # undecorateif __name__ == "__main__":+−# Simple sanity testheap = []data = [1, 3, 5, 7, 9, 2, 4, 6, 8, 0]for item in data:heappush(heap, item)sort = []while heap:sort.append(heappop(heap))print sortimport doctestdoctest.testmod()
530 检测大写字母
520. 检测大写字母
给定一个单词,你需要判断单词的大写使用是否正确。
我们定义,在以下情况时,单词的大写用法是正确的:
全部字母都是大写,比如”USA”。
单词中所有字母都不是大写,比如”leetcode”。
如果单词不只含有一个字母,只有首字母大写, 比如 “Google”。
否则,我们定义这个单词没有正确使用大写字母。
示例 1:
输入: “USA”
输出: True
示例 2:
输入: “FlaG”
输出: False
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/detect-capital
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
对于这道题,我一开始使用的是C++的方法,非常的费脑子,算是按照过程式的思维去考虑到所有可能的情况,并总结规律,最后通过两个bool的flag来维系状态
class Solution {
public:
bool detectCapitalUse(string word) {
if(word.size() == 1)
return true;
int first = word[0];
bool no_capitals = false;
if(first >= 'a' && first <= 'z')
no_capitals = true;
int second = word[1];
bool always_capitals = false;
if(second >= 'A' && second <= 'Z')
{
if(no_capitals)
return false;
always_capitals = true;
}
if(second >= 'a' && second <= 'z')
no_capitals = true;
for(int i = 2; i < word.size(); i++)
{
if(word[i] >= 'A' && word[i] <= 'Z')
{
if(no_capitals)
return false;
}
if(word[i] >= 'a' && word[i] <= 'z')
{
if(always_capitals)
return false;
}
}
return true;
}
};
下面这种方法是我在评论区中所看到的,采用python,非常的简洁
def detectCapitalUse(self, word):
return word.isupper() or word.islower() or word.istitle()

若有收获,就点个赞吧
0 人点赞
