Computational Thinking
Decomposition: 把数据、过程或问题分解成更小的、易于管理的部分。
Pattern Recognition: 观察数据的模式、趋势和规律。
Abstraction: 识别模式形成背后的一般原理。
Algorithm Design: 为解决某一类问题撰写一系列详细步骤。
Choose Data Structure for Algorithms
Simple Version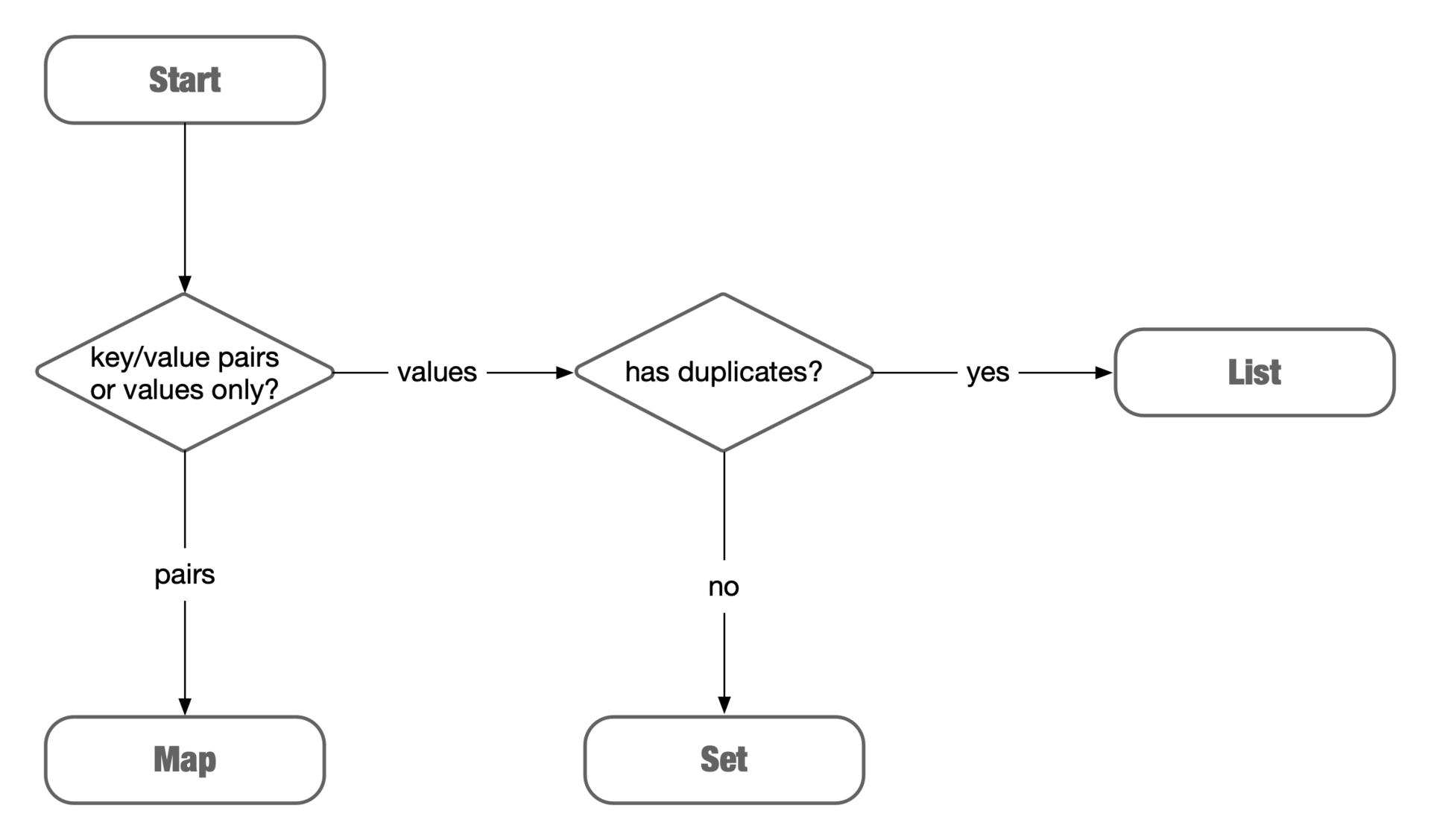
Complete Version

Interactive Visualization
List
Hash Table
Heap
Tree
Graph
一、数据结构
数据存储于内存时,决定了数据顺序和位置关系的便是“数据结构”。
把新得到的电话号码,记在电话簿上:
- 按从上往下的顺序,快,但查找不方便
- 按姓名拼音的顺序,慢,但查找方便
- 按姓名拼音首字母,分表记录(从上倒下 vs. 姓名拼音) | 结构 | 访问 | 添加 | 删除 | | —- | —- | —- | —- | | 链表 | O(n) | O(1) | O(1) | | 数组 | O(1) | O(n) | O(n) | | 堆 | O(1) | O(logn) | O(logn) |
1.1 链表
链表的数据呈线性排列。在链表中,数据的添加和删除都较为方便,就是访问比较耗费时间。

Blue、Yellow、Red 这 3 个字符串作为数据被存储于链表中。每个数据都有 1 个 “指针”,它指向下一个数据的内存地址。

在链表中,数据一般都是分散存储于内存中的,无须存储在连续空间内。

如果想要访问 数据,只能从第 1 个数据开始,顺着指针的指向一一往下访问(这便是顺序访问)。
思考
- 添加数据
- 删除数据
1.1.1 循环链表
我们也可以在链表尾部使用指针,并且让它指向链表头部的数据,将链表变成环形。这便是“循环链表”,也叫“环形链表”。循环链表没有头和尾的概念。想要保存数量固定的最新数据时通常会使用这种链表。

1.1.1 双向链表
我们可以把指针设定为两个,并且让它们分别指向前后数据,这就是“双向链表”。使用这种链表,不仅可以从前往后,还可以从后往前遍历数据,十分方便。
但是,双向链表存在两个缺点:一是指针数的增加会导致存储空间需求增加;二是添加和删除数据时需要改变更多指针的指向。

1.2 数组
数组也是数据呈线性排列的一种数据结构。与链表不同,在数组中,访问数据十分简单,而添加和删除数据比较耗工夫。

a 是数组的名字,后面“[ ]”中的数字表示该数据是数组中的第几个数据(这个数字叫作“数组下标”,下标从 0 开始计数)。比如,Red 就是数组 a 的第 2 个数据。

数据按顺序存储在内存的连续空间内。
思考
- 添加数据
- 删除数据
1.3 栈
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数据。栈就像是一摞书,拿到新书时我们会把它放在书堆的最上面,取书时也只能从最上面的新书开始取。

 往栈中添加数据的操作叫作“入栈”(push)。从栈中取出数据的操作叫作“出栈”(pop)
往栈中添加数据的操作叫作“入栈”(push)。从栈中取出数据的操作叫作“出栈”(pop)
栈这种最后添加的数据最先被取出,即“后进先出”的结构,我们称为Last In First Out,简称LIFO。
1.4 队列
队列中的数据也呈线性排列。虽然与栈有些相似,但队列中添加和删除数据的操作分别是在两端进行的。就和“队列”这个名字一样,把它想象成排成一队的人更容易理解。在队列中,处理总是从第一名开始往后进行,而新来的人只能排在队尾。

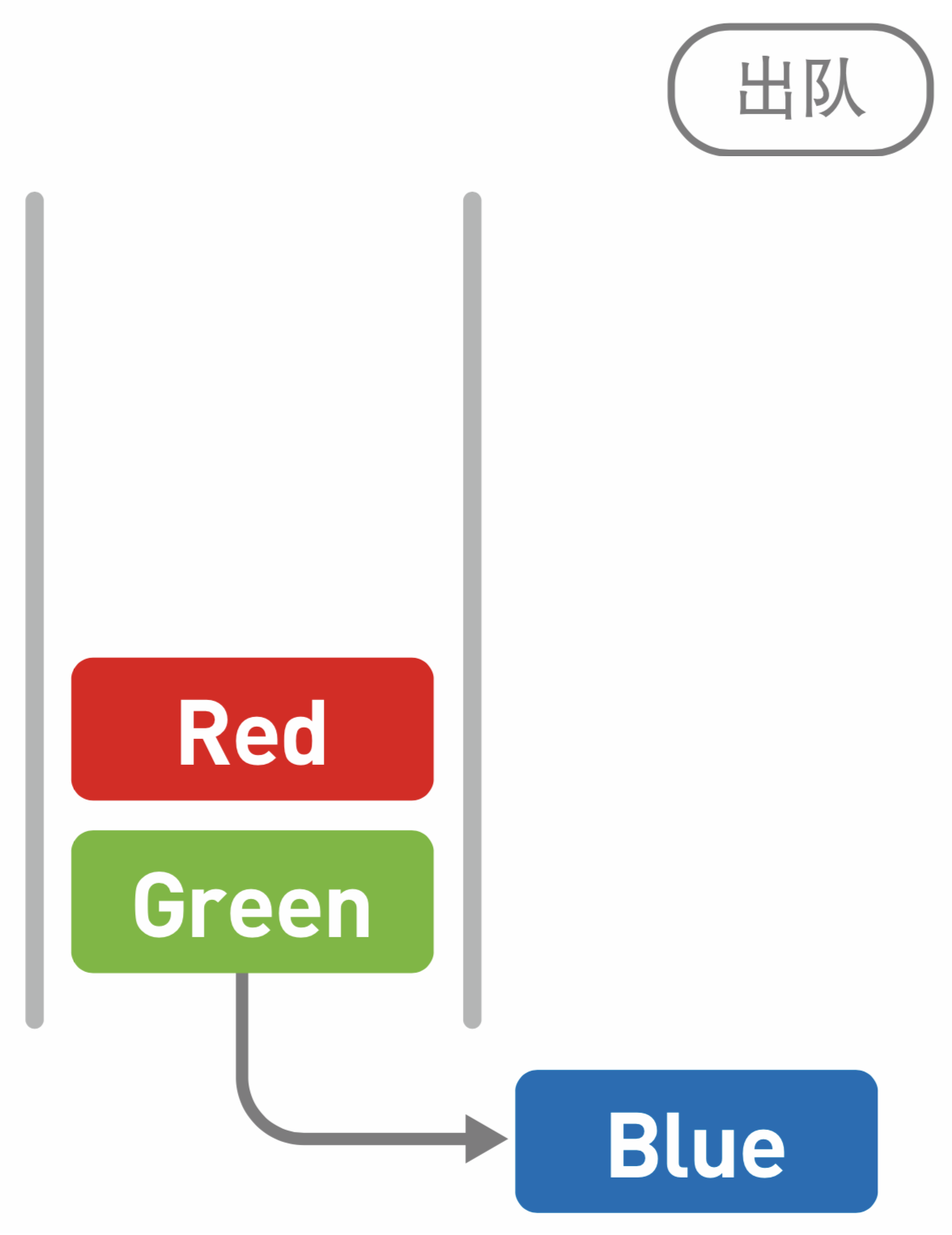 往队列中添加数据的操作叫作“入队”。从队列中删除数据的操作叫作“出队”。
往队列中添加数据的操作叫作“入队”。从队列中删除数据的操作叫作“出队”。
队列这种最先进去的数据最先被取来,即“先进先出”的结构,我们称为 First In First Out,简称 FIFO。
1.5 哈希表
哈希表使用“哈希函数”,可以使数据的查询效率得到显著提升。


使用哈希函数(Hash)计算 Joe 的键,也就是字符串“Joe”的哈希值,得到的结果为 4928。将得到的哈希值除以数组的长度 5,求得其余数。这样的求余运算叫作“mod 运算”。此处 mod 运算的结果为 3 。因此,将Joe的数据存进数组的3号箱。
 在哈希表中,我们可以利用哈希函数快速访问到数组中的目标数据。如果发生哈希冲突,就使用链表进行存储。这种方法被称为“链地址法”。这样一来,不管数据量为多少,我们都能够灵活应对。
在哈希表中,我们可以利用哈希函数快速访问到数组中的目标数据。如果发生哈希冲突,就使用链表进行存储。这种方法被称为“链地址法”。这样一来,不管数据量为多少,我们都能够灵活应对。
除了链地址法以外,还有几种解决冲突的方法。其中,应用较为广泛的是“开放地址法”。这种方法是指当冲突发生时,立刻计算出一个候补地址(数组上的位置)并将数据存进去。如果仍然有冲突,便继续计算下一个候补地址,直到有空地址为止。可以通过多次使用哈希函数或“线性探测法”等方法计算候补地址。
如果数组的空间太小,使用哈希表的时候就容易发生冲突,线性查找的使用频率也会更高;反过来,如果数组的空间太大,就会出现很多空箱子,造成内存的浪费。因此,给数组设定合适的空间非常重要。
1.6 堆
 堆是一种图的树形结构,被用于实现“优先队列”(priority queues)。优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。
堆是一种图的树形结构,被用于实现“优先队列”(priority queues)。优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。
1.7 二叉查找树
 二叉查找树(又叫作二叉搜索树或二叉排序树)是一种数据结构,采用了图的树形结构。数据存储于二叉查找树的各个结点中。
二叉查找树(又叫作二叉搜索树或二叉排序树)是一种数据结构,采用了图的树形结构。数据存储于二叉查找树的各个结点中。
有很多以二叉查找树为基础扩展的数据结构,比如“平衡二叉查找树”。这种数据结构可以修正形状不均衡的树,让其始终保持均衡形态,以提高查找效率。
另外,虽然我们介绍的二叉查找树中一个结点最多有两个子结点,但我们可以把子结点数扩展为 m(m 为预先设定好的常数)。像这种子结点数可以自由设定,并且形状均衡的树便是 B 树。
二、数组的查找
2.1 线性查找
 线性查找是一种在数组中查找数据的算法。与二分查找不同,即便数据没有按顺序存储,也可以应用线性查找。线性查找的操作很简单,只要在数组中从头开始依次往下查找即可。虽然存储的数据类型没有限制。
线性查找是一种在数组中查找数据的算法。与二分查找不同,即便数据没有按顺序存储,也可以应用线性查找。线性查找的操作很简单,只要在数组中从头开始依次往下查找即可。虽然存储的数据类型没有限制。
2.2 二分查找
 和线性查找不同,它只能查找已经排好序的数据。二分查找通过比较数组中间的数据与目标数据的大小,可以得知目标数据是在数组的左边还是右边。因此,比较一次就可以把查找范围缩小一半。重复执行该操作就可以找到目标数据,或得出目标数据不存在的结论。
和线性查找不同,它只能查找已经排好序的数据。二分查找通过比较数组中间的数据与目标数据的大小,可以得知目标数据是在数组的左边还是右边。因此,比较一次就可以把查找范围缩小一半。重复执行该操作就可以找到目标数据,或得出目标数据不存在的结论。
注:二分查找必须建立在数据已经排好序的基础上才能使用,因此添加数据时必须加到合适的位置,这就需要额外耗费维护数组的时间。而使用线性查找时,数组中的数据可以是无序的,因此添加数据时也无须顾虑位置,直接把它加在末尾即可,不需要耗费时间。
三、图的搜索
计算机科学或离散数学中说的“图”是下面这样的:
图可以表现社会中的各种关系,使用起来非常方便:
将车站作为顶点,将相邻两站用边连接,就能用图来表现地铁的路线了。
给边加上一个值。这个值叫作边的“权重”或者“权”,加了权的图被称为“加权图”。
如果图中的路线只能单向行驶时,就可以给边加上箭头,而这样的图就叫作“有向图”。有向图的边也可以加上权重。
3.1 广度优先
广度优先搜索是一种对图进行搜索的算法。假设我们一开始位于某个顶点(即起点),此时并不知道图的整体结构,而我们的目的是从起点开始顺着边搜索,直到到达指定顶点(即终点)。在此过程中每走到一个顶点,就会判断一次它是否为终点。广度优先搜索会优先从离起点近的顶点开始搜索。

搜索顺序为:A、B、C、D、E、F、H…
3.2 深度优先
深度优先搜索和广度优先搜索一样,都是对图进行搜索的算法,目的也都是从起点开始搜索直到到达指定顶点(终点)。深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。

搜索顺序为:A、B、E、K、F、C、H
深度优先搜索的特征为沿着一条路径不断往下,进行深度搜索。虽然广度优先搜索和深度优先搜索在搜索顺序上有很大的差异,但是在操作步骤上却只有一点不同,那就是选择哪一个候补顶点作为下一个顶点的基准不同:
- 广度优先搜索选择的是最早成为候补的顶点,因为顶点离起点越近就越早成为候补,所以会从离起点近的地方开始按顺序搜索
- 而深度优先搜索选择的则是最新成为候补的顶点,所以会一路往下,沿着新发现的路径不断深入搜索。

若有收获,就点个赞吧
0 人点赞
