特征提取/描述
特征
A 和 B 是平面,而且它们的图像中很多地方都存在。很难找到这些小图的准确位置。C 和 D 更简单。它们是建筑的边缘。你可以找到它们的近似位置,但是准确位置还是很难找到。这是因为:沿着边缘,所有的地方都一样。所以边缘是比平面更好的特征,但是还不够好。
如图所示,蓝色框中的区域是一个平面很难被找到和跟踪。无论你向哪个方向移动蓝色框,长的都一样。对于黑色框中的区域,它是一个边缘。如果你沿垂直方向移动,它会改变。但是如果沿水平方向移动就不会改变。而红色框中的角点,无论你向那个方向移动,得到的结果都不同,这说明它是唯一的。 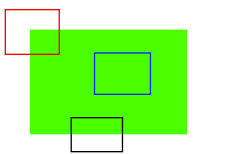
Harris角点检测
Harris 角点检测的结果是一个由角点分数构成的灰度图像。选取适当的阈值对结果图像进行二值化我们就检测到了图像中的角点。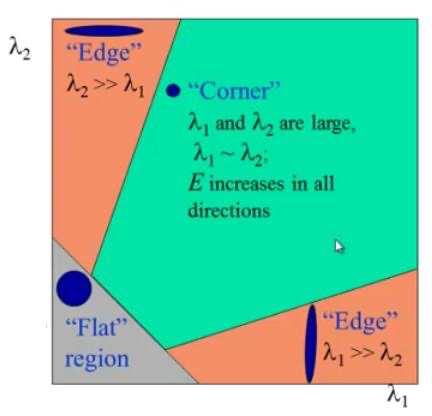
import cv2import numpy as npfilename = 'chessboard.jpg'img = cv2.imread(filename)gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)gray = np.float32(gray)# 输入图像必须是 float32,最后一个参数在 0.04 到 0.05 之间dst = cv2.cornerHarris(gray,2,3,0.04)#result is dilated for marking the corners, not importantdst = cv2.dilate(dst,None)# Threshold for an optimal value, it may vary depending on the image.img[dst>0.01*dst.max()]=[0,0,255]cv2.imshow('dst',img)if cv2.waitKey(0) & 0xff == 27:cv2.destroyAllWindows()

有时我们需要最大精度的角点检测。OpenCV 为我们提供了函数 cv2.cornerSubPix(), 它可以提供亚像素级别的角点检测。下面是一个例子。首先我们要找到 Harris 角点,然后将角点的重心传给这个函数进行修正。Harris 角点用红色像素标出,绿色像素是修正后的像素。在使用这个函数是我们要定义一个迭代停止条件。当迭代次数达到或者精度条件满足后迭代就会停止。我们同样需要定义进行角点搜索的邻域大小。
Shi-Tomasi角点检测 & 适合于跟踪的图像特征
cv2.goodFeaturesToTrack()这个函数可以帮我们使用 Shi-Tomasi 方法获取图像中 N 个最好的角点(也可以通过改变参数来使用 Harris 角点检测算法)。

SIFT(尺度不变特征变换)
在一副小图中使用一个小的窗口可以检测到一个角 点,但是如果图像被放大,再使用同样的窗口就检测不到角点了。
尺度空间极值检测
DoG 就是这组具有不同分辨率的图像金字塔中相邻的两层之间的差值。如下图所示: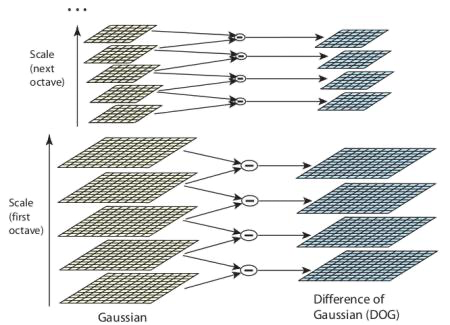
如果是局部最大值,它就可 能是一个关键点。基本上来说关键点是图像在相应尺度空间中的最好代表。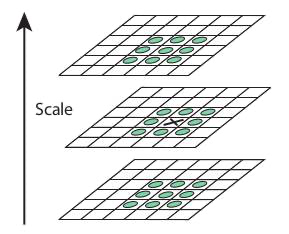
关键点(极值点)定位
DoG 算法对边界非常敏感,所以我们必须要把边界去除。前面我们讲的 Harris 算法除了可以用于角点检测之外还可以用于检测边界。
为关键点(极值点)指定方向参数
现在我们要为每个关键点赋予一个反向参数,这样它才会具有旋转不变性。获取关键点(所在尺度空间)的邻域,然后计算这个区域的梯度级和方向。
关键点描述符
新的关键点描述符被创建了。选取与关键点周围一个 16x16 的邻域,把它分成 16 个 4x4 的小方块,为每个小方块创建一个具有 8 个 bin 的方向直方图。总共加起来有 128 个 bin。由此组成长为 128 的向量就构成了关键点描述符。除此之外还要进行几个测量以达到对光照变化,旋转等的稳定性。
关键点匹配
取第一个图的某个关键点,通过遍历找到第二幅图像中的距离最近的那个关键点。但有些情况下,第二个距离最近的关键点与第一个距离最近的关键点靠的太近。这可能是由于噪声等引起的。此时要计算最近距离与第二近距离的比值。如果比值大于 0.8 就忽略掉。这会去除 90% 的错误匹配,同时只去除 5% 的正确匹配。
函数 sift.detect() 可以在图像中找到关键点。如果你只想在图像中的一个 区域搜索的话,也可以创建一个掩模图像作为参数使用。
SURF(Speeded-Up Robust Features)
在SIFT中,Lowe 在构建尺度空间时使用 DoG 对 LoG 进行近似。SURF使用盒子滤波器(box_filter)对 LoG 进行近似。下图显示了这种近似: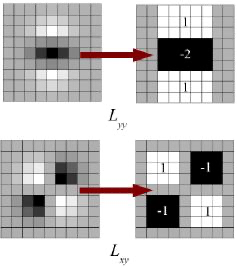
SURF 提供了成为 U-SURF 的功能,它具有更快的速度,同时保持了对 +/-15 度旋转的稳定性。
按照亮度的不同,可以将特征点分为两种,第一种为特征点迹其周围小邻域的亮度比背景区域要亮,Hessian矩阵的迹为正;另外一种为特征点迹其周围小邻域的亮度比背景区域要暗,Hessian 矩阵为负值。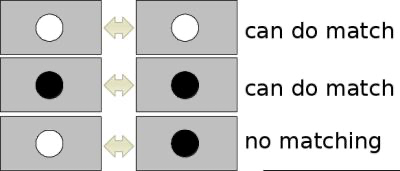
SURF 很像一个斑点检测器。它可以检测到蝴蝶翅膀上的白斑。

角点检测的FAST算法
FAST特征提取
- 在图像中选取一个像素点 p,来判断它是不是关键点。Ip等于像素点p的灰度值。
- 选择适当的阈值 t。
- 如下图所示在像素点 p 的周围选择16个像素点进行测试。
- 如果在这16个像素点中存在 n 个连续像素点的灰度值都高于 Ip+t,或者低于 Ip−t,那么像素点 p 就被认为是一个角点。如上图中的虚线所示,n 选取的值为12。

角点检测器
- 选择一组训练图片(最好是跟最后应用相关的图片)
- 使用FAST算法找出每幅图像的特征点
- 对每一个特征点,将其周围的16个像素存储构成一个向量。对所有图像都这样做构建一个特征向量P
- 每一个特征点的16像素点都属于下列三类中的一种。
- 根据这些像素点的分类,特征向量P也被分为3个子集:Pd, Ps, Pb
- 定义一个新的布尔变量Kp,如果p是角点就设置为Ture,如果不是就设置为False.
- 使用ID3算法(决策树分类器)查询每个子集,使用变量Kp查询关于真类的知识。它选择产生关于候选像素是否是角的最多信息的x,通过Kp的熵来测量。
- 这是递归地应用于所有的子集,直到它的熵为零。
- 将构建好的决策树运用于其它图像的快速的检测。
非极大值抑制
使用极大值抑制的方法可以解决检测到的特征点相连的问题
- 对所有检测到到特征点构建一个打分函数V。V就是像素点p与周围16个像素点差值的绝对值之和。
- 计算临近两个特征点的打分函数V。
- 忽略V值最低的特征点.
ORB(定向快且旋转短的BRIEF)
ORB 基本是 FAST 关键点检测和 BRIEF 关键点描述器的结合体,并通过很多修改增强了性能。首先它使用 FAST 找到关键点,然后再使用 Harris 角点检测对这些关键点进行排序找到其中的前 N 个点。它也使用金字塔从而产生尺度不变性特征。
import numpy as npimport cv2from matplotlib import pyplot as pltimg = cv2.imread('simple.jpg', 0)# Initiate STAR detectororb = cv2.ORB()# find the keypoints with ORBkp = orb.detect(img, None)# compute the descriptors with ORBkp, des = orb.compute(img, kp)# 只绘制关键点的位置,而不是大小和方向img2 = cv2.drawKeypoints(img, kp, color=(0, 255, 0), flags=0)plt.imshow(img2), plt.show()
特征匹配

Brute-Force 匹配
蛮力匹配器是很简单的。首先在第一幅图像中选取一个关键点然后依次与第二幅图像的每个关键点进行(描述符)距离测试,最后返回距离最近的关键点。
**
BFMatcher 对象具有两个方法:BFMatcher.match() 和 BFMatcher.knnMatch()。 第一个方法会返回最佳匹配。第二个方法为每个关键点返回 k 个最佳匹配(降序排列之后取前 k 个),其中 k 是由用户设定的。
ORB 蛮力匹配
匹配器对象
matches = bf.match(des1, des2) 返回值是一个 DMatch 对象列表。这个 DMatch 对象具有下列属性:
- DMatch.distance - 描述符之间的距离。越小越好。
- DMatch.trainIdx - 目标图像中描述符的索引。
- DMatch.imgIdx - 目标图像的索引。
- DMatch.queryIdx - 查询图像中描述符的索引。
SIFT 蛮力匹配和比值测试
FLANN 匹配
FLANN 是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors)的简称。它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集时它的效果要好于 BFMatcher。
**
使用特征匹配和单应性查找对象
我们在一张杂乱的图像中找到了一个对象(的某些部分)的位置。这些信息足以帮助我们在目标图像中准确找到(查询图像)对象。
为了达到这个目的我们可以使用 calib3d 模块中的 cv2.findHomography() 函数。如果将这两幅图像中的特征点集传给这个函数,它就会找到这个对象的透视图变换。然后我们就可以使用函数 cv2.perspectiveTransform() 找到这个对象了。至少要 4 个正确的点才能找到这种变换。
背景减除
背景减除(Background subtraction,BS)是一种使用静态相机生成前景掩码(即包含场景中移动物体像素的二值图像)的常用技术。顾名思义,BS计算前景掩码,执行当前帧和背景模型之间的减法,包含场景的静态部分,或者更一般地说,考虑到所观察场景的特征,所有可以被视为背景的部分。
后台建模包括两个主要步骤:
- 后台初始化;
- 后台更新。

BackgroundSubtractorMOG
这是一个以混合高斯模型为基础的前景/背景分割算法。它是 P.KadewTraKuPong 和 R.Bowden 在 2001 年提出的。它使用 K(K=3 或 5)个高斯分布混合对背景像素进行建模。使用这些颜色(在整个视频中)存在时间的长短作为混合的权重。背景的颜色一般持续的时间最长,而且更加静止。
**
BackgroundSubtractorMOG2
这个也是以高斯混合模型为基础的背景/前景分割算法。它是以 2004 年 和 2006 年 Z.Zivkovic 的两篇文章为基础的。这个算法的一个特点是它为每 一个像素选择一个合适数目的高斯分布。(上一个方法中我们使用是 K 高斯分 布)。这样就会对由于亮度等发生变化引起的场景变化产生更好的适应。
**
BackgroundSubtractorGMG
此算法结合了静态背景图像估计和每个像素的贝叶斯分割。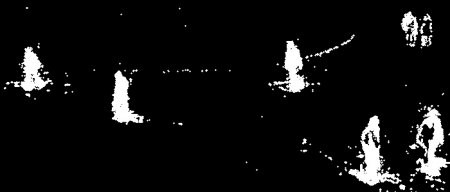
BackgroundSubtractorKNN
基于k近邻的背景/前景分割算法。如果前景像素的数量比较低将非常有效。
Meanshift
Meanshift(均值偏移) 算法的基本原理很简单。假设我们有一堆点(可以是像直方图反投影那样的像素分布)和一个小窗口(可能是一个圆圈),我们要完成的任务就是将这个窗口移动到最大灰度密度处(或者是点最多的地方)。如下图所示:
要在 OpenCV 中使用 Meanshift 算法首先要对目标对象进行设置,计算目标对象的直方图,这样在执行 Meanshift 算法时就可以将目标对象反向投影到每一帧中。另外我们还需要提供窗口的起始位置。在这里我们值计算 H(Hue)通道的直方图,同样为了避免低亮度造成的影响,我们使 用函数 cv2.inRange() 将低亮度的值忽略掉。
Camshift
上面的结果有一个问题。我们的窗口的大小是固定的,而汽车由远及近(在视觉上)是一个逐渐变大的过程,固定的窗口是不合适的。所以我们需要根据目标的大小和角度来对窗口的大小和角度进行修订。
**
光流
由于目标对象或者摄像机的移动造成的图像对象在连续两帧图像中的移动被称为光流。它是一个 2D 向量场,可以用来显示一个点从第一帧图像到第二帧图像之间的移动。
光流是基于以下假设的:
- 在连续的两帧图像之间(目标对象的)像素的灰度值不改变。
- 相邻的像素具有相同的运动。
Lucas-Kanade 光流
利用一个 3x3 邻域中的 9 个点具有相同运动的这一点。这样我们就可以找到这 9 个点的光流方程,用它们组成一个具有两个未知数 9 个等式的方程组,这是一个约束条件过多的方程组。**
稠密光流
计算稠密光流。结果是一个带有光流向量(u,v)的双通道数组。通过计算我们能得到光流的大小和方向。我们使用颜色对结果进行编码以便于更好的观察。方向对应于 H(Hue)通道,大小对应于 V(Value)通道。
相机标定(3D重构)
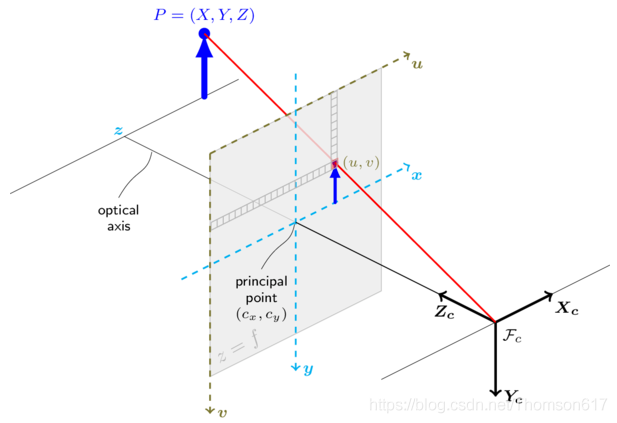

3D 点被称为对象点,2D 图像点被称为图像点
角点提取
为了找到棋盘的图案,我们要使用函数 cv2.findChessboardCorners()。
在找到这些角点之后我们可以使用函数 cv2.cornerSubPix() 增加准确度。我们使用函数 cv2.drawChessboardCorners() 绘制图案。
相机标定
单目标定
在得到这些对象点和图像点之后,开始做摄像机标定。我们要使用的函数是 cv2.calibrateCamera()。它会返回摄像机矩阵,畸变系数,旋转和平移向量等。
广角/鱼眼镜头标定
定义:设P为世界坐标系中三维坐标X中的一个点(存储在矩阵X中)摄像机坐标系中P的坐标向量为:Xc=RX+T。
使用的函数是 cv2.fisheye.calibrate()。它会返回摄像机矩阵,畸变系数,旋转和平移向量等。
双目标定
该函数估计两个摄像机之间的转换,形成一个立体对。如果你有一个相对位置和方向是固定的两个摄像头的立体相机,如果你分别(这可以用solvePnP)计算了一个对象的相对于第一个相机和第二个相机的姿态,(R1, T1)和(R2, T2),那么这些姿势肯定是相互关联的。这意味着,给定(R1, T1)计算(R2, T2)是可能的。你只需要知道第二个相机相对于第一个相机的位置和方向。
畸变校正
如今的低价单孔摄像机(照相机)会给图像带来很多畸变。畸变主要有两种:径向畸变和切向畸变。
畸变(distortion)是对直线投影(rectilinear projection)的一种偏移。简单来说直线投影是场景内的一条直线投影到图片上也保持为一条直线。畸变简单来说就是一条直线投影到图片上不能保持为一条直线了,这是一种光学畸变,可能由于摄像机镜头的原因。镜头畸变系数一般有径向畸变和切向畸变两种参数组成。
- 使用 cv2.undistort() 。只需使用这个函数和上边得到的 ROI 对结果进行裁剪。
- 使用 cv2.remap() 。首先我们要找到从畸变图像到非畸变图像的映射方程。再使用重映射方程。

反向投影误差
利用反向投影误差对我们找到的参数的准确性进行估计。得到的结果越接近 0 越好。有了内部参数,畸变参数和旋转变换矩阵,我们就可以使用
姿势估计
摄像机标定中,我们已经得到了摄像机矩阵,畸变系数等。有 了这些信息我们就可以估计图像中图案的姿势,比如目标对象是如何摆放,如何旋转等。对一个平面对象来说,我们可以假设 Z=0,这样问题就转化成摄像机在空间中是如何摆放(然后拍摄)的。所以,如果我们知道对象在空间中的姿势,我们就可以在图像中绘制一些 2D 的线条来产生 3D 的效果。
**
对极几何(Epipolar Geometry)
在使用针孔相机时,我们会丢失大量重要的信息,比如说图像的深度,或者说图像上的点和摄像机的距离,因为这是一个从 3D 到 2D 的转换。因此一个重要的问题就是如何使用这样的摄像机计算出深度信息?答案就是使用多个相机。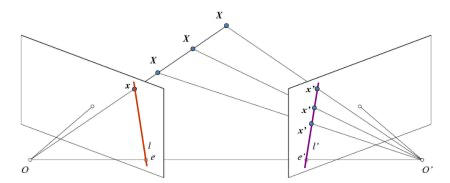
**
- 为了得到基础矩阵我们应该在两幅图像中找到尽量多的匹配点。可以使用 SIFT 描述符,FLANN 匹配器和比值检测。
- 现在得到了一个匹配点列表,就可以使用它来计算基础矩阵了。
- 找到极线。会得到一个包含很多线的数组。所以我们要定义一个新的函数将这些线绘制到图像中。
- 现在在两幅图像中计算并绘制极线。
- 图可以看出所有的极线都汇聚以图像外的一点,这个点就是极点。为了得到更好的结果,我们应该使用分辨率比较高的图像和 `
双目立体视觉
双目立体视觉(Binocular Stereo Vision)是机器视觉的一种重要形式,它是基于视差原理并利用成像设备从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的方法。
成像模型
小孔成像模型
小孔成像模型也称为针孔模型,是计算机视觉中最理想的一种也是最简单的一种成像模型,它近似为线性结构。摄像机成像模型的一个主要作用便是将真实空间中的点与拍摄平面图像上的点建立起联系。考虑到小孔成像模型的计算简便、便于分析等众多优点,其使用率比其它两种模型正交投影模型和拟透视投影模型都要高。
平行式与会聚式双目立体视觉系统模型
相机的摆放位置不同,系统模型的空间几何结构也不相同,相应的计算方式也会发生改变。依据相机的摆放方式,双目立体视觉系统模型主要分为两种:平行放置方式和会聚放置放式。
理想双目相机成像模型
空间点P离相机的距离(深度)z=f*b/d,可以发现如果要计算深度z,必须要知道:
- 相机焦距f,左右相机基线b。这些参数可以通过先验信息或者相机标定得到。
- 视差d。需要知道左相机的每个像素点(xl, yl)和右相机中对应点(xr, yr)的对应关系。这是双目视觉的核心问题。
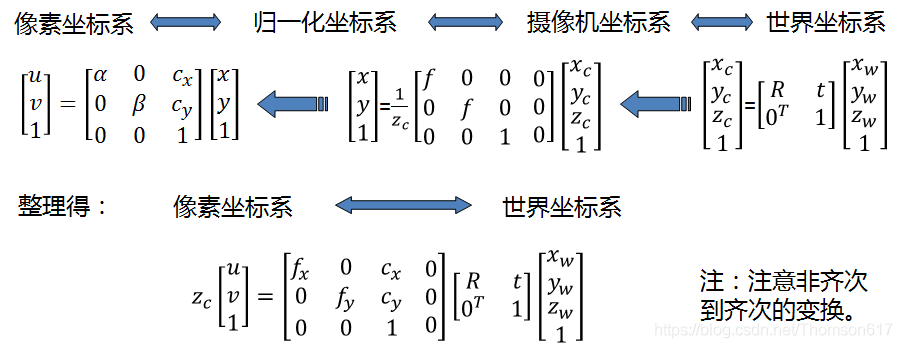
图像中的四大坐标系
- 世界坐标系就是物体在真实世界中的坐标,比如黑白棋盘格的世界坐标系原点定在第一个棋盘格的顶点,Xw,Yw,Zw互相垂直,Zw方向就是垂直于棋盘格面板的方向。可见世界坐标系是随着物体的大小和位置变化的,单位是长度单位。只要棋盘格的大小决定了,无论板子怎么动,棋盘格角点坐标一般就不再变动(因为是相对于世界坐标系原点的位置不变),且认为是Zw=0。
- 相机坐标系以光心为相机坐标系的原点,以平行于图像的x和y方向为Xc轴和Yc轴,Zc轴和光轴平行,Xc,Yc,Zc互相垂直,单位是长度单位。
- 图像物理坐标系以主光轴和图像平面交点为坐标原点,x和y方向如图所示,单位是长度单位。
- 图像像素坐标系以图像的顶点为坐标原点,u和v方向平行于x和y方向,单位是以像素计。
极线约束
要寻找两幅图像之间的对应关系,最直接的方法就是逐点匹配,如果加以一定的约束条件:极线约束(epipolar constraint),搜索的范围可以大大减小。极线约束对于求解图像对中像素点的对应关系非常重要。
图像矫正(立体校正)
图像矫正是通过分别对两张图片用单应(homography)矩阵变换(可以通过标定获得)得到的,目的就是把两个不同方向的图像平面(下图中灰色平面)重新投影到同一个平面且光轴互相平行(下图中黄色平面),这样就可以用前面理想情况下的模型了,两个相机的极线也变成水平的了。
Horizontal stereo:第一和第二相机的视图相对移动,主要沿着x轴(可能有小的垂直移动)。在校正后的图像中,左右摄像头对应的极线是水平的,y坐标相同。
Vertical stereo:第一和第二摄像机视图主要在垂直方向上相对移动(可能也在水平方向上移动了一点)。经过校正的图像中的极线是垂直的,并且具有相同的x坐标。
立体匹配
立体匹配是根据对所选特征的计算,建立特征间的对应关系,将同一个空间点在不同图像中的映像点对应起来,并由此得到相应的视差图像,立体匹配是双目视觉中最重要也是最困难的问题。当空间三维场景被投影为二维图像时,同一景物在不同视点下的图像会有很大不同,而且场景中的诸多因素,如光照条件、景物几何形状和物理特性、噪声干扰和畸变以及摄像机特性等,都被综合成单一的图像灰度值。
OpenCV中提供了三种立体匹配算法的实现:BM、SGBM、GC。
- BM(Block Matching,块匹配):速度最快,但效果最差
- SGBM(Semi-Global Block Matching,半全局块匹配):匹配效果好,速度比BM稍慢
- GC(Graph Cuts,图割):匹配效果最佳,但速度最慢,不适合实时业务,只能在 opencv2.x 中找到实现
双目测距
距离公式:Z = f * T / D 
机器学习
K 近邻(k-Nearest Neighbour )
kNN 可以说是最简单的监督学习分类器了。想法也很简单,就是找出测试数据在特征空间中的最近邻居。
测试数据有 3 个邻居,它们都是蓝色,所以它被分为蓝色家族。结果很明显,如下图所示:
kNN 对手写数字 OCR
手写数字的 OCR
创建一个可以对手写数字进行识别的程序,为了达到这个目的我们需要训练数据和测试数据。
英文字母的 OCR
支持向量机(SVM)
线性数据分割
如下图所示,其中含有两类数据,红的和蓝的。如果是使用 kNN,对于一 个测试数据我们要测量它到每一个样本的距离,从而根据最近邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训练样本。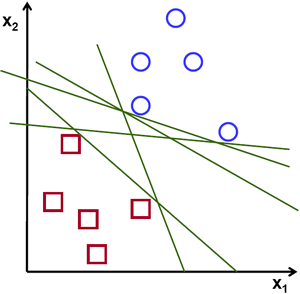
从上图中我们看到有很多条直线可以将数据分为蓝红两组,那一条直线是最好的呢?直觉上讲这条直线应该是与两组数据的距离越远越好。为什么呢? 因为测试数据可能有噪音影响(真实数据 + 噪声)。这些数据不应该影响分类的准确性。所以这条距离远的直线抗噪声能力也就最强。所以 SVM 要做就是找到一条直线,并使这条直线到(训练样本)各组数据的最短距离最大。
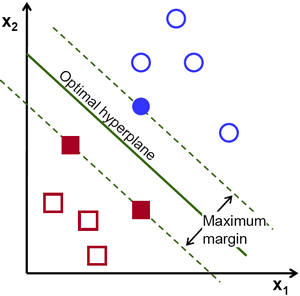
使用 SVM 进行手写数据 OCR
在计算 HOG 前我们使用图片的二阶矩对其进行抗扭斜(deskew)处理。 所以我们首先要定义一个函数 deskew(),它可以对一个图像进行抗扭斜处理。下面就是 deskew() 函数:
def deskew(img):m = cv2.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11'] / m['mu02']M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])img = cv2.warpAffine(img, M, (SZ, SZ), flags=affine_flags)return img<a name="k2uIQ"></a>## **K 值聚类**<a name="WBaS4"></a>### T-shirt 大小问题话说有一个公司要生产一批新的 T 恤。很明显它们要生产不同大小的 T 恤来满足不同顾客的需求。所以这个公司收集了很多人的身高和体重信息,并把 这些数据绘制在图上,如下所示:<br />**<br />肯定不能把每个大小的 T 恤都生产出来,所以它们把所有的人分为三组: 小,中,大,这三组要覆盖所有的人。我们可以使用 K 值聚类的方法将所有人分为 3 组,这个算法可以找到一个最好的分法,并能覆盖所有人。如果不能覆盖全部人的话,公司就只能把这些人分为更多的组,可能是 4 个或 5 个甚至更多。如下图:<br />**<a name="EYXDU"></a>### 工作原理1. 随机选取两个重心点,C1 和 C2(有时可以选取数据中的两个点 作为起始重心)。1. 计算每个点到这两个重心点的距离,如果距离 C1 比较近就标记 为 0,如果距离 C2 比较近就标记为 1。(如果有更多的重心点,可以标记为 “2”,“3”等)1. 重新计算所有蓝色点的重心,和所有红色点的重心,并以这两个点更新重心点的位置。1. 重复步骤 2,更新所有的点标记。1.<a name="IO7pp"></a>### 仅有一个特征的数据假设我们有一组数据,每个数据只有一个特征(1 维)。例如前面的 T 恤 问题,我们只使用人们的身高来决定 T 恤的大小。<br /><a name="wpnZP"></a>### 含有多个特征的数据在前面的 T 恤例子中我们只考虑了身高,现在我们也把体重考虑进去,也就是两个特征。在前一节我们的数据是一个单列向量。每一个特征被排列成一列,每一行对应一个测试样本。<br />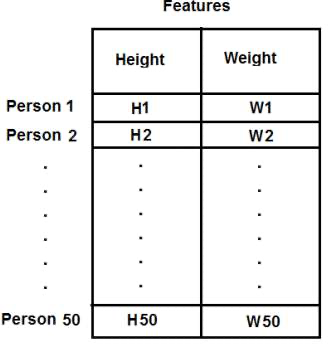<a name="dmeYU"></a>### 颜色量化颜色量化就是减少图片中颜色数目的一个过程。为什么要减少图片中的颜色呢?减少内存消耗!有些设备的资源有限,只能显示很少的颜色。在这种情况下就需要进行颜色量化。我们使用 K 值聚类的方法来进行颜色量化。<br /><a name="tTdod"></a># 摄影学<a name="ZYgYT"></a>## 去噪噪声有一个性质。我们认为噪声是平均值为一的随机变量。考虑一个带噪声的像素点,p = p0 + n,其中 p0 为像素的真实值,n 为这个像素的噪声。我 们可以从不同图片中选取大量的相同像素(N)然后计算平均值。理想情况下 我们会得到 p = p0。因为噪声的平均值为 0。OpenCV 提供了这种技术的四个变本:1. `cv2.fastNlMeansDenoising()` 适用对象为灰度图。1. `cv2.fastNlMeansDenoisingColored()` 适用对象为彩色图。1. `cv2.fastNlMeansDenoisingMulti()` 适用于短时间的图像序列(灰度图像)1. `cv2.fastNlMeansDenoisingColoredMulti()` 适用于短时间的图像序列(彩色图像)```pythonimport cv2from matplotlib import pyplot as pltimg = cv2.imread('die.png')dst = cv2.fastNlMeansDenoisingColored(img,None,10,10,7,21)plt.subplot(121),plt.imshow(img)plt.subplot(122),plt.imshow(dst)plt.show()
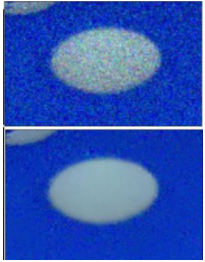
cv2.fastNlMeansDenoisingMulti() 计算消耗了相当可观的时间。第一张图是原始图像,第二个是带噪音个图 像,第三个是去噪音之后的图像。
修补
使用坏点周围的像素取代坏点,这样它看起来和周围像素就比较像了。如下图所示:
创建一个与输入图像大小相等的掩模图像,将待修复区域的像素设置为255(其它地方为0)。
import cv2img = cv2.imread('messi_2.jpg')mask = cv2.imread('mask2.png',0)dst = cv2.inpaint(img,mask,3,cv2.INPAINT_TELEA) cv2.imshow('dst',dst)cv2.waitKey(0)cv2.destroyAllWindows()

对象检测/追踪
分类器
开始时,算法需要大量的正样本图像(面部图 像)和负样本图像(不含面部的图像)来训练分类器。我们需要从其中提取特征。下图中的 Haar 特征会被使用。它们就像我们的卷积核。每一个特征是一个值,这个值等于黑色矩形中的像素值之后减去白色矩形中的像素值之和。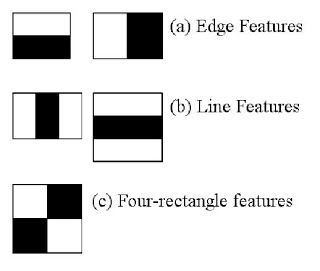
如果把这两个窗口放到脸颊的话,就一点都不相关。那么我们怎样从超过 160000+ 个特征中选出最好的特征呢?
训练
使用弱分类器的增强级联包括两个主要阶段:训练和检测阶段。
最常用到的三种空间特征分别为HOG特征、LBP特征及Haar特征:
- Haar描述的是图像在局部范围内像素值明暗变换信息;
- LBP描述的是图像在局部范围内对应的纹理信息;
- HOG描述的则是图像在局部范围内对应的形状边缘梯度信息。
HOG
概念与思想:方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来描述图像局部特征的描述子。
特点:与其它特征相比,HOG的优势在于能更好的描述形状,在行人识别方面有很好的效果。
LBP
概念与思想:局部二值模式(Local Binary Pattern,LBP)是一种计算机视觉和图像处理中用来描述图像局部特征的描述子。
特点:与其它特征相比,LBP的优势在于能更好地描述纹理,在人脸识别方面有很好的效果,比 Haar 快很多倍(提取的准确率会低)因此适合用在移动设备上。
Haar
概念与思想:Haar 特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。
特点:与其它特征相比,Haar 的优势在于能更好地描述灰度变化情况,用于检测正面的人脸(正脸由于鼻子等凸起的存在,使得脸上的光影变化十分明显)。
训练数据
为了训练弱分类器的增强级联,我们需要一组正样本(包含您要检测的实际对象)和一组负图像(包含您不想检测的所有内容)。负样本集必须手动准备,而正样本集是使用opencv_createsamples应用程序创建的。
负样本
负样本取自任意图像,其中不包含要检测的对象。这些负图像(从中生成样本)应在特殊的负图像文件中列出,该文件每行包含一个图像路径(可以是绝对路径,也可以是相对路径)。注意,负样本和样本图像也称为背景样本或背景图像,在本文档中可以互换使用。
正样本
正样本由opencv_createsamples应用程序创建。增强过程使用它们来定义在尝试找到感兴趣的对象时模型应实际寻找的内容。
可视化分类器
有时,可视化受过训练的级联,查看其选择的功能以及其阶段的复杂性可能会很有用。为此,OpenCV提供了一个opencv_visualisation应用程序。
HAAR / LBP人脸模型的示例在Angelina Jolie的给定窗口上运行,该窗口具有与级联分类器文件相同的预处理-> 24x24像素图像,灰度转换和直方图均衡化:
追踪
在视频后续帧中定位一个物体,称为追踪。
稠密光流:此类算法用来评估一个视频帧中的每个像素的运动向量
稀疏光流:此类算法,像Kanade-Lucas-Tomashi(KLT)特征追踪,追踪一张图片中几个特征点的位置
Kalman Filtering:一个非常出名的信号处理算法基于先前的运动信息用来预测运动目标的位置。早期用于导弹的导航
MeanShift和Camshift:这些算法是用来定位密度函数的最大值,也用于追踪
单一目标追踪:此类追踪器中,第一帧中的用矩形标识目标的位置。然后在接下来的帧中用追踪算法。日常生活中,此类追踪器用于与目标检测混合使用。
多目标追踪查找算法:如果我们有一个非常快的目标检测器,在每一帧中检测多个目标,然后运行一个追踪查找算法,来识别当前帧中某个矩形对应下一帧中的某个矩形。
运动物体的识别方法很多,主要就是要提取相关物体的特征,主要分为:
- 各种色彩空间直方图,利用色彩空间的直方图分布作为目标跟踪的特征的一个显著性特点是可以减少物体远近距离对跟踪的影响,因为其颜色分布大致相同。
- 轮廓特征,提取目标的轮廓特征不但可以加快算法的速度,还可以在目标有小部分影响的情况下同样有效果。
- 纹理特征,如果被跟踪目标是有纹理的,根据其纹理特征来跟踪,效果会有所改善。
运动物体的跟踪涉及到的算法也比较多,其主要分类为:
- 质心跟踪算法(Centroid):这种跟踪方式用于跟踪有界目标如飞机,目标完全包含在摄像机的视场范围内,对于这种跟踪方式可选用一些预处理算法:如白热(正对比度)增强、黑热(负对比度)增强,和基于直方图的统计(双极性)增强。
- 多目标跟踪算法(MTT):多目标跟踪用于有界目标如飞机、地面汽车等。它们完全在跟踪窗口内。在复杂环境里的小目标跟踪MMT能给出一个较好的性能。
- 相关跟踪算法(Correlation):相关可用来跟踪多种类型的目标,当跟踪目标无边界且动态不是很强时这种方式非常有效。典型应用于:目标在近距离的范围,且目标扩展到摄像机视场范围外,如一艘船。
- 边缘跟踪算法(Edge):当跟踪目标有一个或多个确定的边缘而同时却又具有不确定的边缘,这时边缘跟踪是最有效的算法。典型地火箭发射,它有确定好的前边缘,但尾边缘由于喷气而不定。
- 相位相关跟踪算法(Phase Correlation):相位相关算法是非常通用的算法,既可以用来跟踪无界目标也可以用来跟踪有界目标。在复杂环境下(如地面的汽车)能给出一个好的效果。
- 场景锁定算法(SceneLock):该算法专门用于复杂场景的跟踪。适合于空对地和地对地场景。这个算法跟踪场景中的多个目标,然后依据每个点的运动,从而估计整个场景全局运动,场景中的目标和定位是自动选择的。当存在跟踪点移动到摄像机视场外时,新的跟踪点能自动被标识。瞄准点初始化到场景中的某个点,跟踪启动,同时定位瞄准线。在这种模式下,能连续跟踪和报告场景里的目标的位置。
- 组合(Combined)跟踪算法:顾名思义这种跟踪方式是两种具有互补特性的跟踪算法的组合:相关类算法 +质心类算法。它适合于目标尺寸、表面、特征改变很大的场景(如小船在波涛汹涌的大海里行驶)。
OpenCV追踪器
- BOOSTING
- MIL
- KCF
- TLD
- MEDIANFLOW
- GOTURN
- MULTI
- MOSSE
- CSRT.
- 如果需要更高的准确率,并且可以容忍延迟的话,使用CSRT
- 如果需要更快的FPS,并且可以容许稍低一点的准确率的话,使用KCF
- 如果纯粹的需要速度的话,用MOSSE。

若有收获,就点个赞吧
0 人点赞
