前置环境
Java开发环境搭建
IDEA创建maven工程
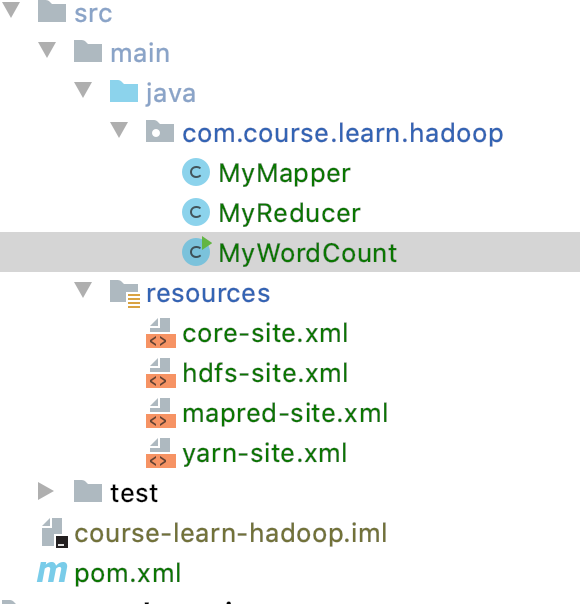
pom.xml依赖引入
注意hadoop版本对应
<!-- hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.2</version></dependency>
resources引入*site.xml
将/opt/bigdata/hadoop/ect/hadoop/下四个文件拷贝至项目
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
Java编码三个类
MyWordCount
public class MyWordCount {
public static void main(String[] args) throws Exception {
// 定义配置
Configuration conf = new Configuration(true);
// 定义JOB
Job job = Job.getInstance(conf);
job.setJarByClass(MyWordCount.class);
job.setJobName("myJob");
// 定义输入输出目录
Path inFile = new Path("/user/god/input");
TextInputFormat.addInputPath(job, inFile);
// /user/god/output必须不能存在,否则创建失败
Path outFile = new Path("/user/god/output");
if (outFile.getFileSystem(conf).exists(outFile)) {
outFile.getFileSystem(conf).delete(outFile, true);
}
TextOutputFormat.setOutputPath(job, outFile);
// 设置map阶段处理
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置reduce阶段处理
job.setReducerClass(MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
}
}
�MyMapper
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
�MyReducer
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
�构建打包上传
- mvn clean package -Dmaven.test.skip=true
- 将文件course-learn-hadoop.jar上传到主节点服务器
- 执行命令hadoop jar course-learn-hadoop.jar com.course.learn.hadoop.MyWordCount
- hdfs dfs -ls /user/god/output
hdfs dfs -cat /user/god/output/part-r-00000
作业提交方式
开发打包上传执行hadoop命令
开发 -> jar -> 上传到集群中任意一个节点 -> hadoop jar xxx.jar ooxx in out
嵌入linux/Windows集群方式
设置mapreduce.framework.name = yarn
System.setProperty(“HADOOP_USER_NAME”, “root”);
conf.set(“mapreduce.app-submission.cross-platform”,”true”)
job.setJar(“Target目录下jar路径”);local单机方式(自测)
设置mapreduce.framework.name = local
windows系统必配:conf.set(“mapreduce.app-submission.cross-platform”,”true”);
- 部署hadoop-3.2.2并且配置HADOOP_HOME环境变量
将部署的hadoop/bin目录下的hadoop.dll复制到c:/windows/system32/下
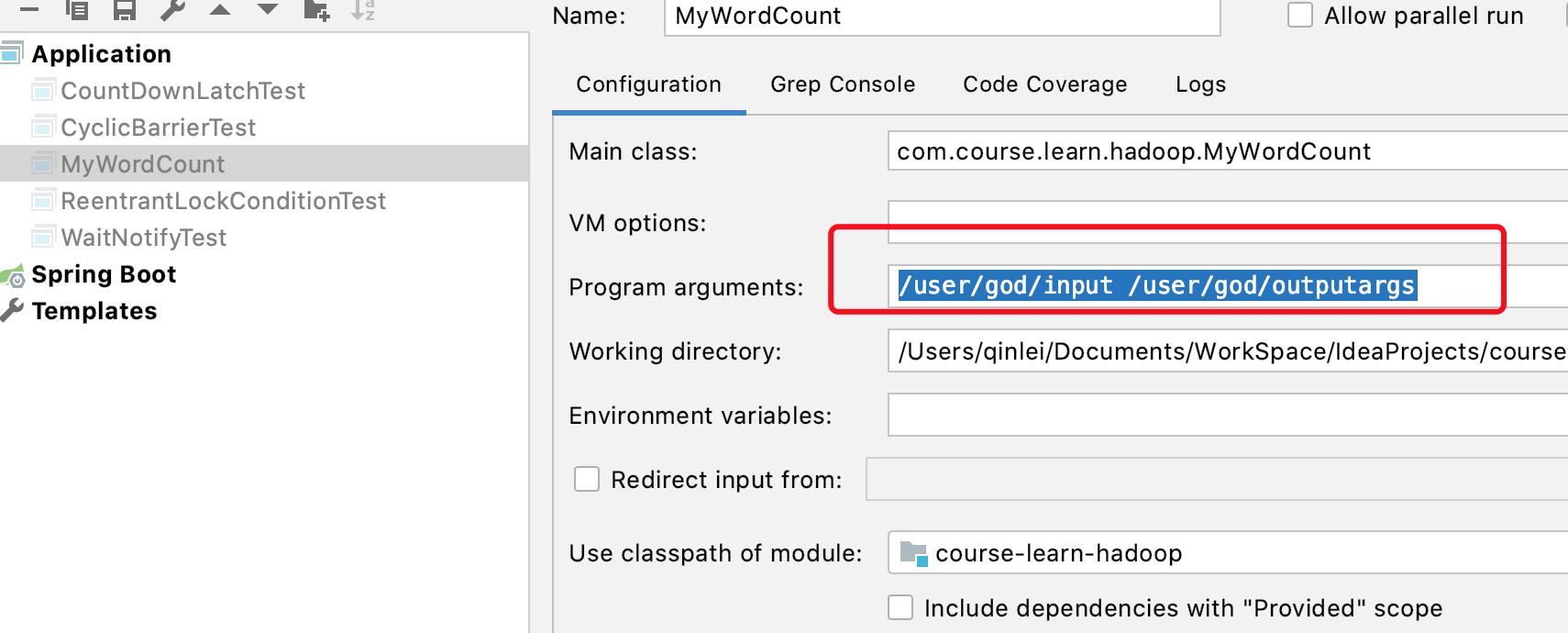
参数个性化配置
public class MyWordCount { public static void main(String[] args) throws Exception { System.setProperty("HADOOP_USER_NAME", "god"); // 定义配置 Configuration conf = new Configuration(true); // 个性化参数 GenericOptionsParser parser = new GenericOptionsParser(conf, args); String[] params = parser.getRemainingArgs(); // 定义JOB Job job = Job.getInstance(conf); job.setJarByClass(MyWordCount.class); job.setJobName("myJob"); job.setJar( "/Users/qinlei/Documents/WorkSpace/IdeaProjects/course/course-learn/course-learn-hadoop/target/course-learn-hadoop.jar"); // 定义输入输出目录 Path inFile = new Path(params[0]); TextInputFormat.addInputPath(job, inFile); // /user/god/output必须不能存在,否则创建失败 Path outFile = new Path(params[1]); if (outFile.getFileSystem(conf).exists(outFile)) { outFile.getFileSystem(conf).delete(outFile, true); } TextOutputFormat.setOutputPath(job, outFile); // 设置map阶段处理 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置reduce阶段处理 job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete job.waitForCompletion(true); } }�设置动态参数,可设置-D mapreduce.job.reduce=2

若有收获,就点个赞吧
0 人点赞
