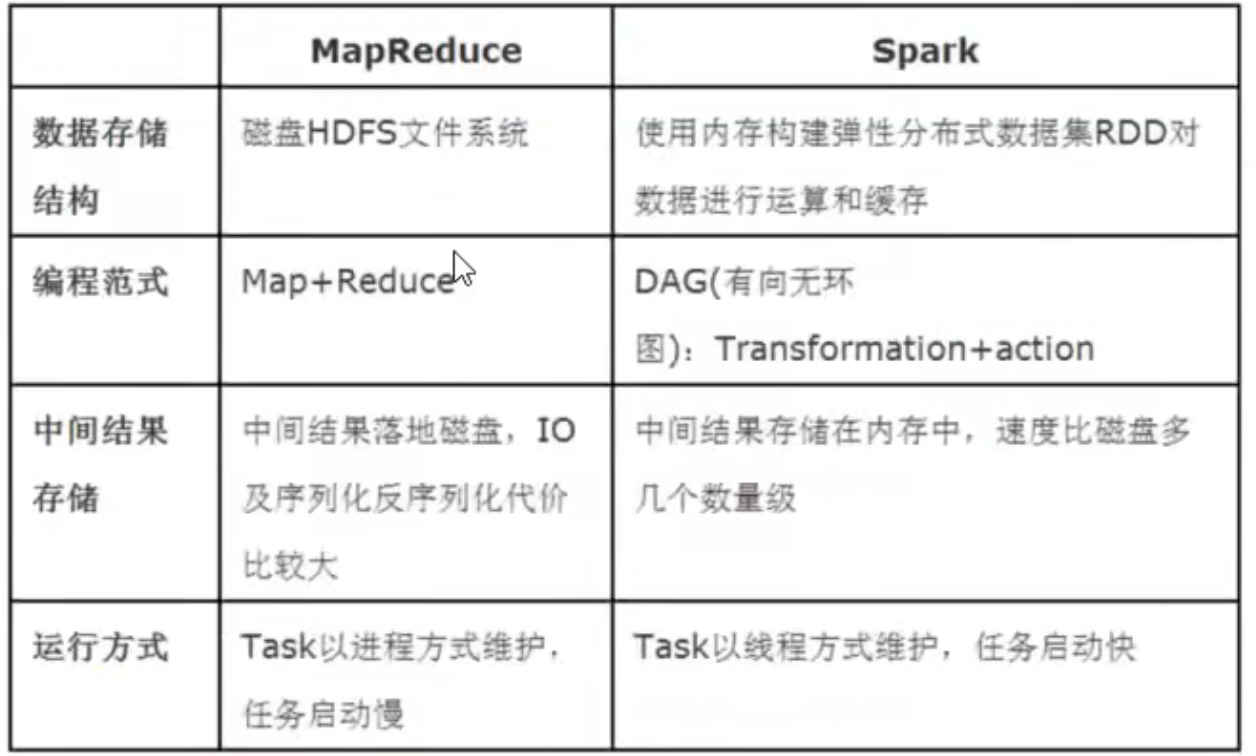
Hadoop和Spark的关系
Google 在 2003 年和 2004 年先后发表了 Google 文件系统 GFS 和 MapReduce 编程模型两篇文章,基于这两篇开源文档,06 年 Nutch 项目子项目之一的 Hadoop 实现了两个强有力的开源产品:HDFS 和 MapReduce。Hadoop 成为了典型的大数据批量处理架构,由HDFS 负责静态数据的存储,并通过 MapReduce将计算逻辑分配到各数据节点进行数据计算和价值发现。之后以HDFS 和 MapReduce为基础建立了很多项目,形成了 Hadoop 生态圈。
而 Spark则是UC Berkeley AMP lab (加州大学伯克利分校AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,专门用于大数据量下的迭代式计算。是为了跟 Hadoop 配合而开发出来的,不是为了取代 Hadoop,Spark运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁盘中,第二次 Mapredue 运算时在从磁盘中读取数据,所以其瓶颈在2次运算间的多余 IO 消耗。Spark则是将数据一直缓存在内存中,直到计算得到最后的结果,再将结果写入到磁盘,所以多次运算的情况下, Spark 是比较快的。
MapReduce和Spark的关系
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark与MapReduce处理数据对比,有两个不同点:
- Spark处理数据时,可将中间结果数据存储到内存中。

- Spark Job调度以DAG方式,并且每个任务Task以线程(Thread)方式执行,并不像MapReduce以进程(Process)方式执行。
Spark概述
官网:https://spark.apache.org/
中文官网:https://spark.apachecn.org/#/
Spark是一种采用Scala语言编写的快速、通用、可扩展的大数据分析引擎。
Spark特点
- 运行速度快,因为基于内存计算。
- Spark支持Java、Scala、Python、R和SQL语言。
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时支持在Kubernetes(Spark2.3开始)上。
Spark计算框架
伯克利大学将 Spark 的整个生态系统成为伯克利数据分析栈(BDAS),在核心框架 Spark 的基础上:主要提供五个范畴的计算框架:
Spark Core:Spark的基本功能
- Spark SQL:提供了类 SQL 的查询,返回Spark-DataFrame 的数据结构(类似 Hive)
- Spark Streaming:流式计算,主要用于处理线上实时时序数据(类似 storm)
- MLlib:提供机器学习的各种模型和调优
- GraphX:提供基于图的算法,如 PageRank
- Structured Streaming:使用结构化方式处理流式数据(Spark SQL + Spark Streaming)

Spark优点
- 提供 Cache 机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的 IO 开销
- 提供了一套支持 DAG 图的分布式并行计算的编程框架,减少多次计算之间中间结果写到 HDFS 的开销
使用多线程池模型减少 Task 启动开稍,shuffle 过程中避免不必要的 sort 操作并减少磁盘 IO 操作(Hadoop 的 Map 和 reduce 之间的 shuffle 需要 sort)
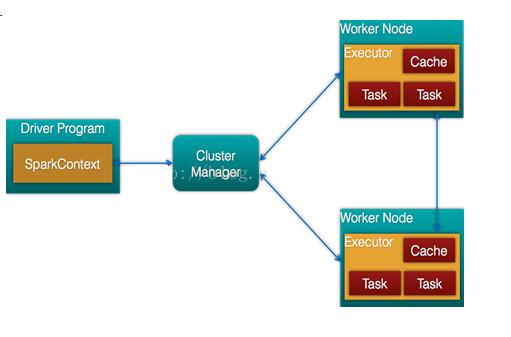
Spark架构
Master节点
Master 节点上常驻 Master 守护进程和 Driver 进程, Master 负责将串行任务变成可并行执行的任务集Tasks, 同时还负责出错问题处理等。
Master 负载管理全部的 Worker 节点。Worker节点
Worker 节点上常驻 Worker 守护进程,而 Worker 节点负责执行任务。
Driver
创建 SparkContext,负责执行用户写的Application(用户自定义)的main函数进程
Executor
每个 Worker上存在一个或多个 Executor 进程,该对象拥有一个线程池,每个线程负责一个 Task 任务的执行。根据 Executor上 cpu-core 的数量,其每个时间可以并行多个跟 core 一样数量的Task
相关术语
应用程序(Application):基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor
- 驱动(Driver):运行Application的main()函数并且创建SparkContext
- 执行单元(Executor):Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors
- 集群管理程序(Cluster Manager):在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统)
操作(Operation):作用于RDD的各种操作分为Transformation和Action
运行原理
启动 Spark 运行程序主要有两种方式:
一种是使用 spark-submit 将脚本文件提交
- 一种是打开 Spark 跟某种特定语言的解释器(spark-shell【scala】、pyspark、sparkR)
执行流程: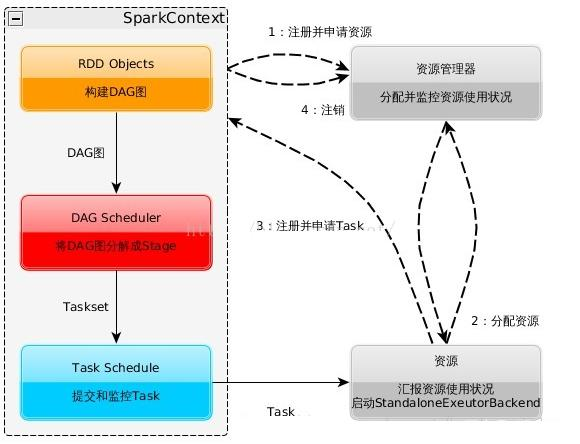


若有收获,就点个赞吧
0 人点赞
