分析流程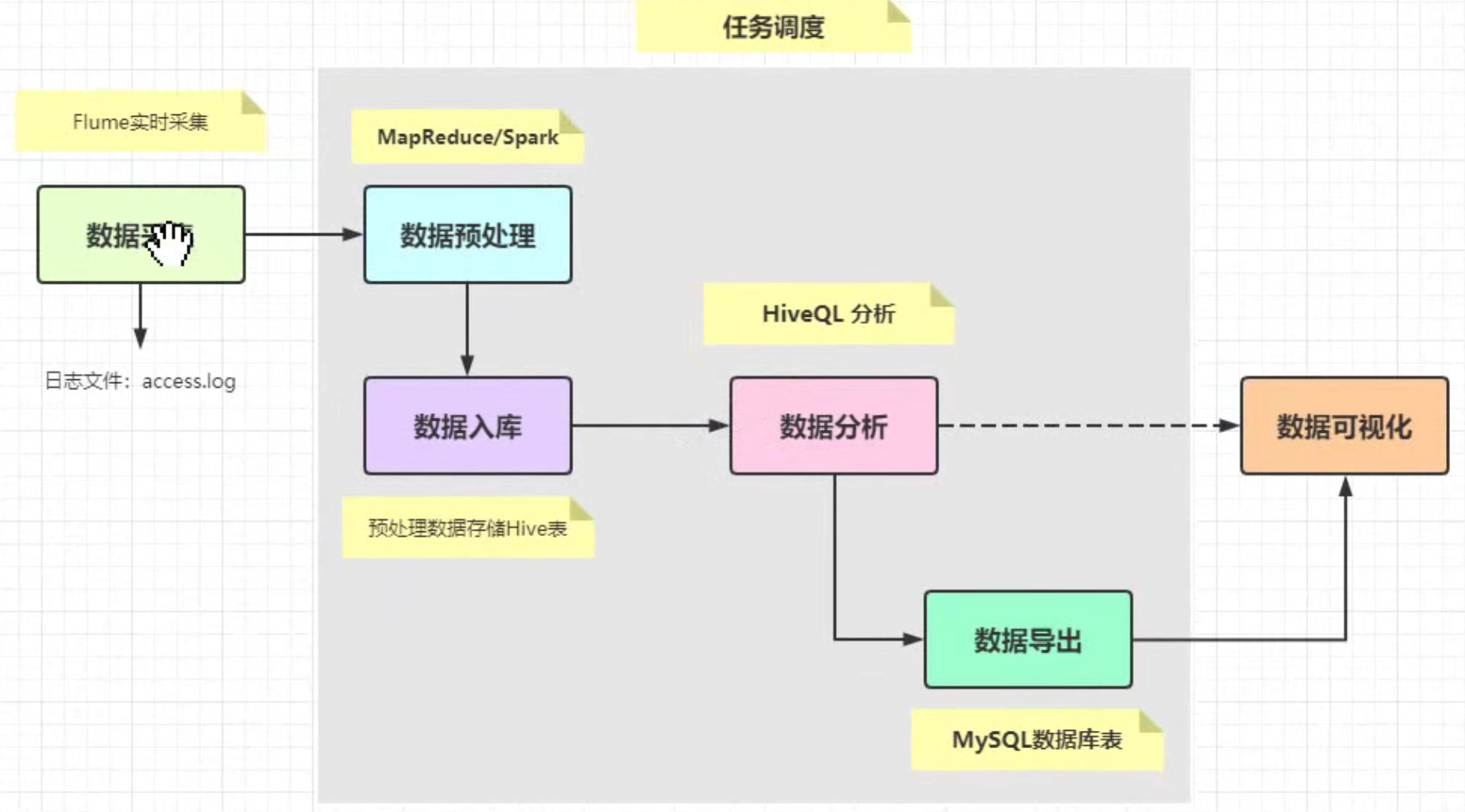
项目概述
项目规划
- 需求:实现【报表统计】功能,进行可视化
- 数据调研:分析数据格式,字段含义
- 环境搭建:大数据环境、开发环境
- 项目初始化:工具类编写、标准定义
环境搭建
大数据环境
| 基础软件 | java1.8.0_311 scala-2.13.8 mysql-5.7.31 |
|---|---|
| 大数据软件 | hadoop-3.2.2 hive-3.1.2 spark-3.1.2-bin-hadoop3.2 oozie hue |
所需启动服务环境:
- HDFS:start-dfs.sh
- YARN:start-yarn.sh
- MRHistory:mr-jobhistory-daemon.sh start historyserver
- Spark History:start-history-server.sh
- Oozie:oozied.sh start
- Hue:hue.daemon.sh start
- HiveMetaStore:hive —service metastore
- Spark JDBC/ODBC Server:start-thriftserver.sh —master local[2]
Beeline:beeline -u jdbc:hive2://master01:10000 -n root -p 123456
应用开发环境
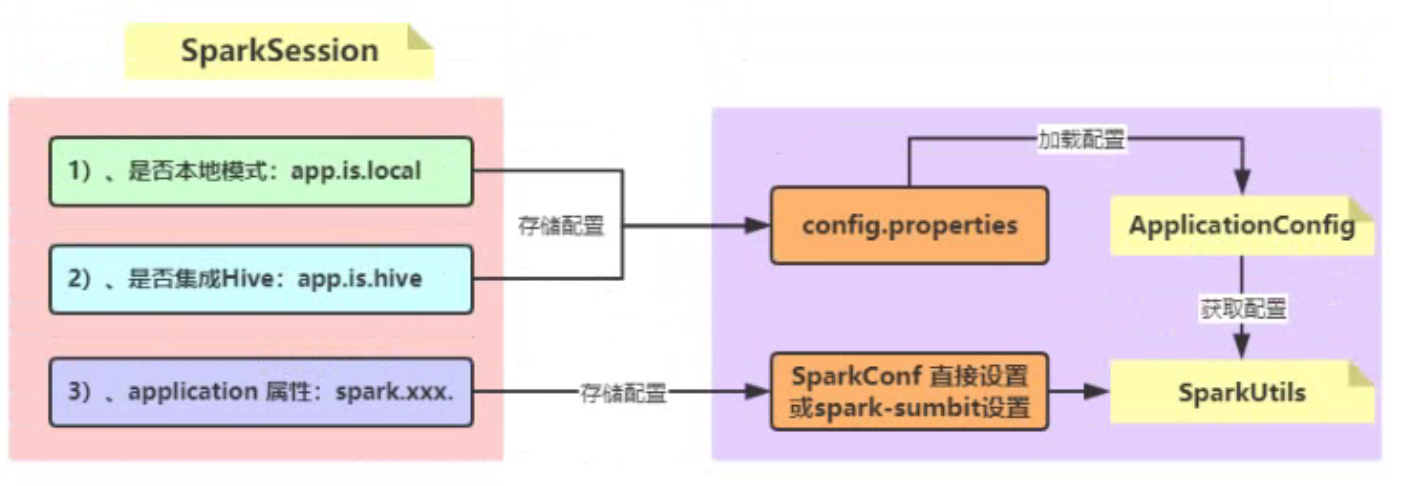
构建SparkSession实例对象,数据加载、运行模式、集成Hive
-
项目初始化
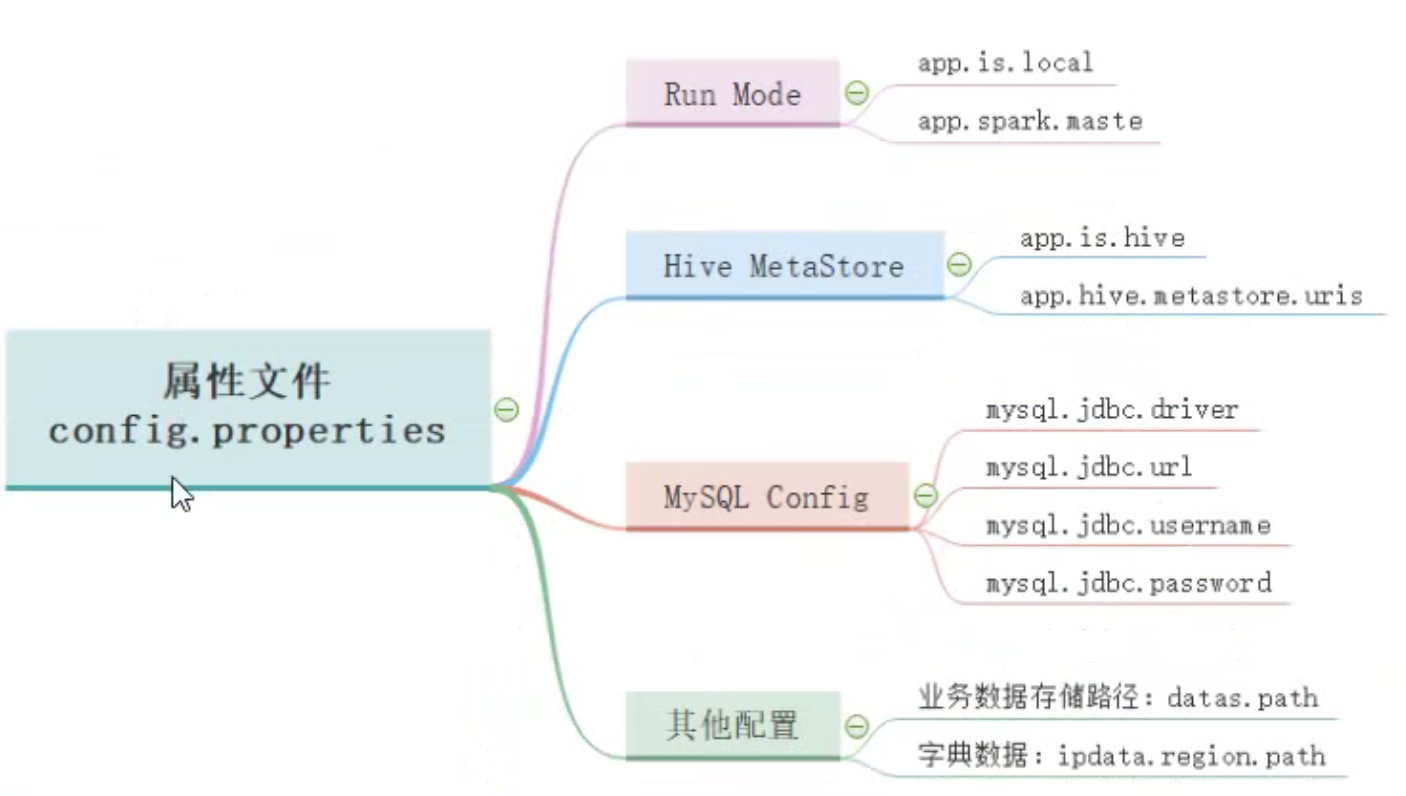
加载属性文件
- SparkSession工具类
-
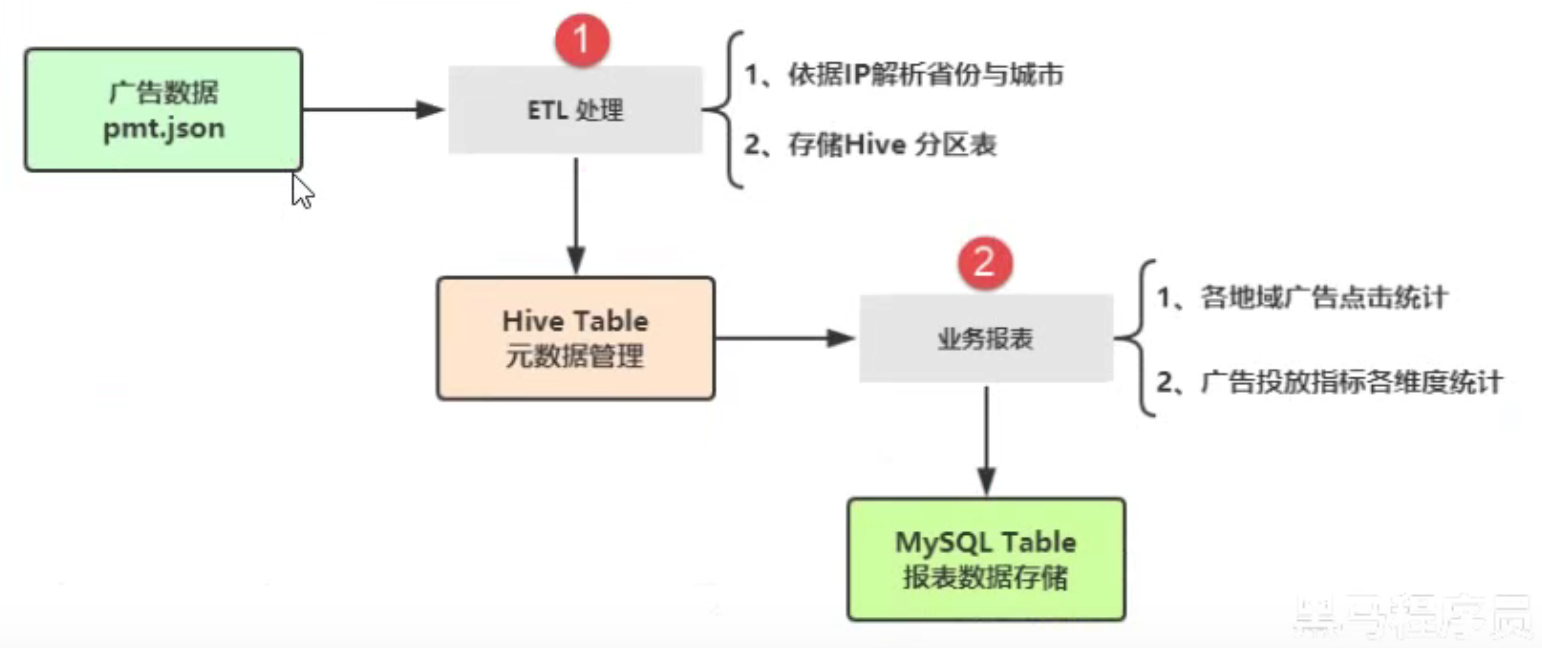
数据ETL
- IP工具类
- Hive表创建(必须在Hive中创建,否则有问题)
创建数据库【itcast_ads】和表【pmt_ads_info】 - 日期工具类
- 数据ETL
第一步、加载json数据
第二步、解析IP地址为省份和城市
第三步、数据保存至Hive
分布式缓存
spark.sparkContext.addFile(AppConfig.IP_DATA_REGION_PATH)
new DbSearcher(new DbConfig(), SparkFiles.get(“ip2region.db”))业务报表分析
参考文档:/Users/qinlei/Documents/Notebook/Spark/报表数据离线实战
应用执行调度
应用打包
在集群环境运行开发Spark Application,首先要打成jar,直接使用Maven插件即可。
mvn package
- 服务器:mkdir -p /root/submit-ads-app
scp pmt.json、ip2region.db、应用程序bubble-learn-ads-1.0-SNAPSHOT.jar - 服务器:mkdir -p /root/submit-ads-app/jars
将应用程序相关jar上传至此
- HDFS服务器:hdfs dfs -mkdir -p /spark/dataset/
hdfs dfs -put /root/submit-ads-app/pmt.json /spark/dataset/
hdfs dfs -put /root/submit-ads-app/ip2region.db /spark/dataset/
hdfs dfs -put /root/submit-ads-app/bubble-learn-ads-1.0-SNAPSHOT.jar /spark/apps - 上传spark目录下的jar
cd /opt/bigdata/spark/jars/
hdfs dfs -put * /spark/apps/jars
集群提交运行
https://spark.apache.org/docs/2.4.5/submitting-applications.html
本地提交模式
# 本地运行模式 ETL应用运行(ads_elt)提交应用命令EXTERNAL_JARS=/home/submit-ads-app/jarsspark-submit --master local[2] \--conf "spark.sql.shuffle.partitions=2" \--class com.bubble.ads.etl.PmtEtlRunner \--jars ${EXTERNAL_JARS}/ip2region-1.7.2.jar,${EXTERNAL_JARS}/config-1.4.1.jar \hdfs://master01:8020/spark/apps/bubble-learn-ads-1.0-SNAPSHOT.jar#报表Report应用运行(ads_report)提交应用命令EXTERNAL_JARS=/home/submit-ads-app/jarsspark-submit --master local[2] \--conf "spark.sql.shuffle.partitions=2" \--class com.bubble.ads.report.PmtReportRunner \--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.27.jar,${EXTERNAL_JARS}/config-1.4.1.jar,${EXTERNAL_JARS}/protobuf-java-3.7.1.jar \hdfs://master01:8020/spark/apps/bubble-learn-ads-1.0-SNAPSHOT.jar
集群提交模式
#客户端模式
EXTERNAL_JARS=/home/submit-ads-app/jars
spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf spark.sql.shuffle.partitions=2 \
--class com.bubble.ads.report.PmtReportRunner \
--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.27.jar,${EXTERNAL_JARS}/config-1.4.1.jar,${EXTERNAL_JARS}/protobuf-java-3.7.1.jar \
hdfs://master01:8020/spark/apps/bubble-learn-ads-1.0-SNAPSHOT.jar
# 集群模式
EXTERNAL_JARS=/home/submit-ads-app/jars
spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf spark.sql.shuffle.partitions=2 \
--class com.bubble.ads.report.PmtReportRunner \
--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.27.jar,${EXTERNAL_JARS}/config-1.4.1.jar,${EXTERNAL_JARS}/protobuf-java-3.7.1.jar \
hdfs://master01:8020/spark/apps/bubble-learn-ads-1.0-SNAPSHOT.jar
由于从HDFS上加载数据,封装到DataFrame中,默认的分区数目等于block 数目,所以每个Task 处理数据最大量为128MB,无需设置并行度,但是要是从HBase表或者Elasticsearch索引加载数据, 需要考虑分区数目(并行度spark.default.parallelism)。
前端大屏展示
TODO

若有收获,就点个赞吧
0 人点赞
