Streaming概述
在很多实时数据处理的场景中,都需要用到流式处理(Stream Process)框架,Spark也包含了两个完整的流式处理框架Spark Streaming和Structured Streaming(Spark 2.0出现)。
流式计算,对无边界的数据进行连续不断的处理、聚合和分析。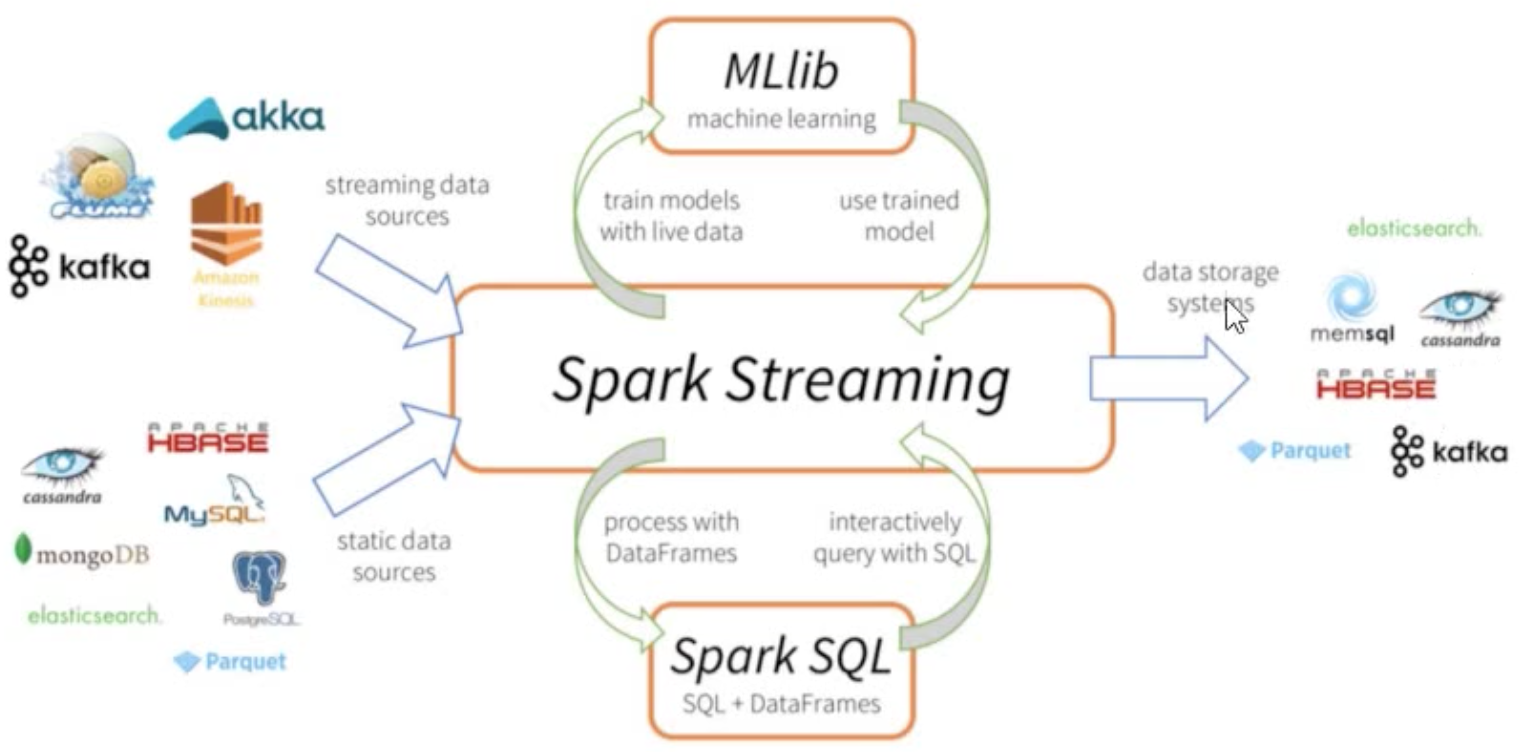
应用场景
- 电商实时大屏
- 商品推荐
- 工业大数据
- 集群监控
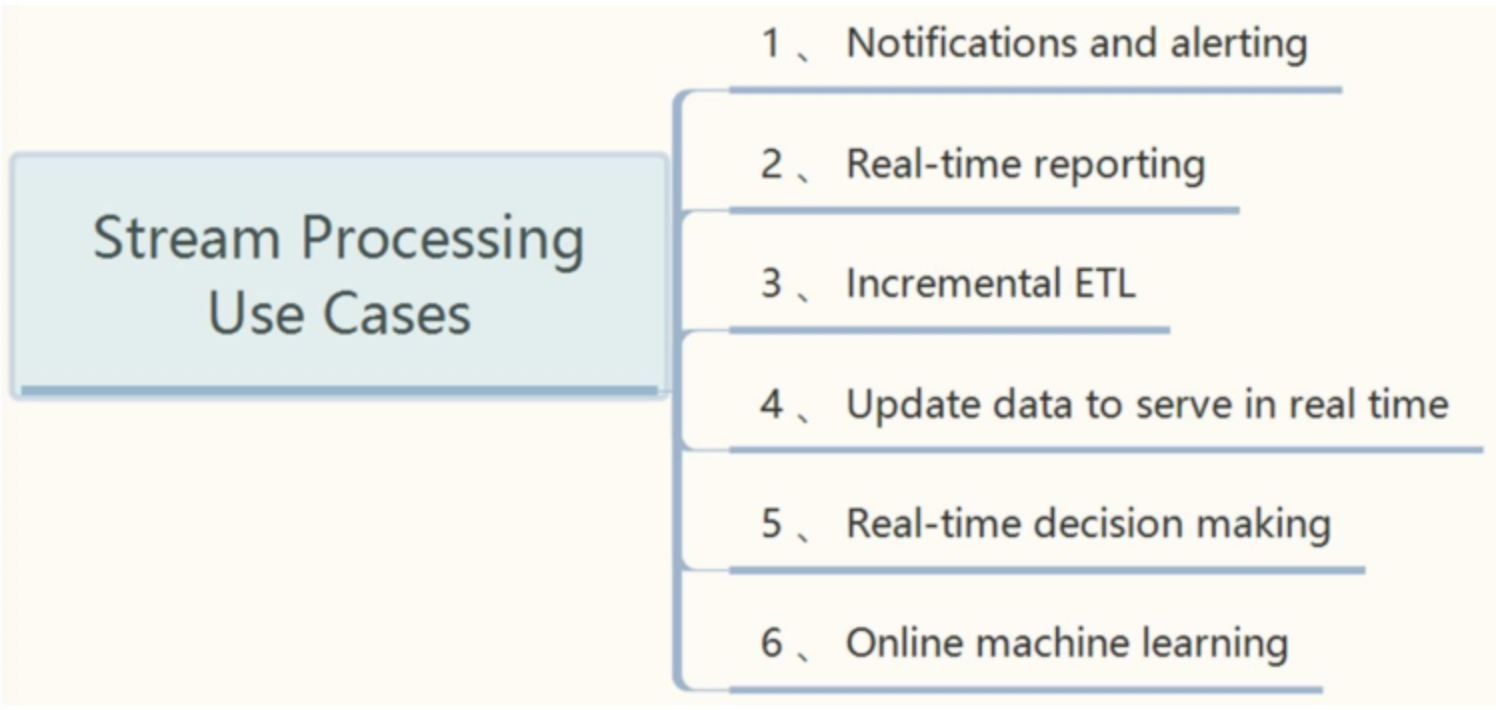
【实时增量ETL】:实时接收数据,进行ETL处理,最后保存至存储引擎,比如HBase、Elasticsearch中。
计算模式
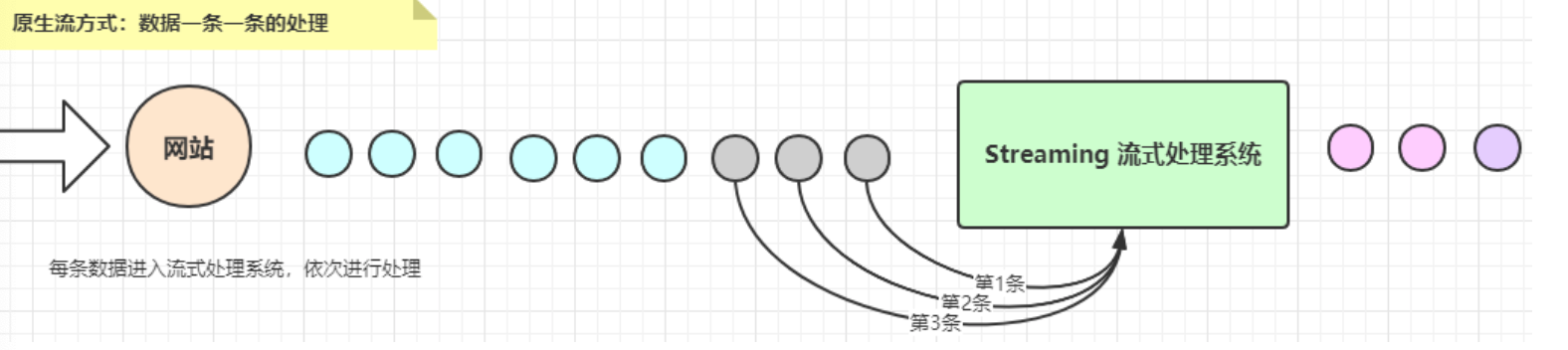
原生流计算模式
- 一条一条数据处理分析,实时性很高
- 比如Storm框架、Flink框架,以及StructedStreaming也支持
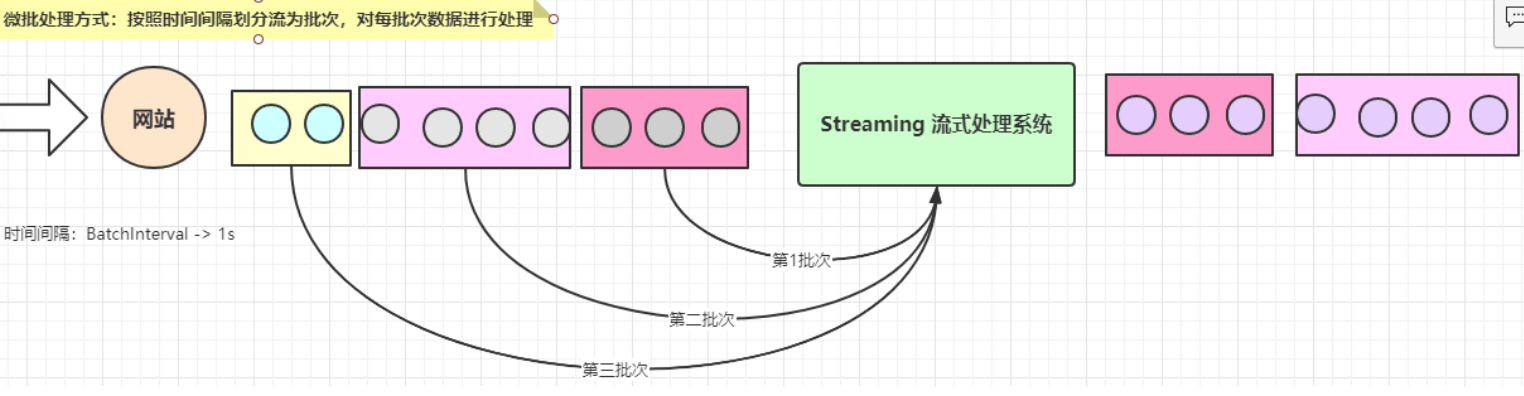
微批处理计算模式
- 按照时间间隔划分流,将批次数据进行处理分析
- 比如SparkStreaming和StructedStreaming
计算思想
SparkStreaming是一个基于SparkCore之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。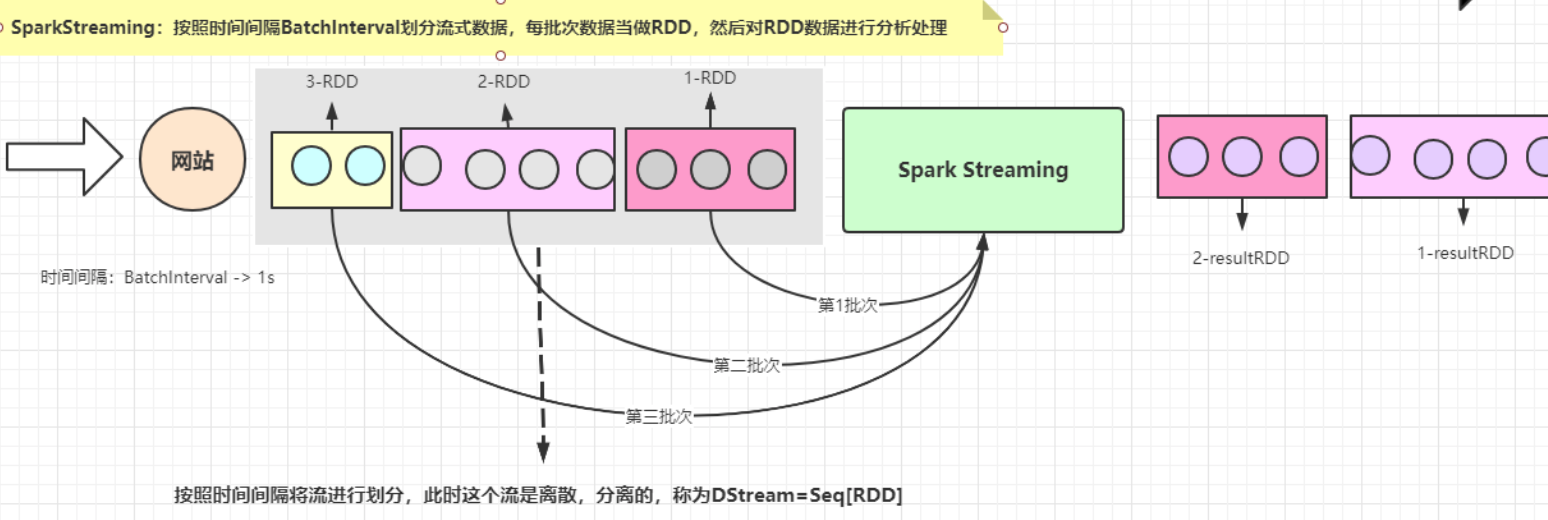
对于Spark Streaming来说,将流式数据按照时间间隔BatchInterval划分为很多部分,每一部分Batch(批次),针对每批次数据Batch当做RDD进行快速分析和处理。
它的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒、分等时间间隔将数据流进行批量的划分。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等。
DStream = Seq[RDD]
工作原理
- ssc.start()启动receiver接收器,实时接收数据源数据
- 按照时间间隔BlockInterval划分流式数据Block
- 存储Block至Executors内存中,设置副本数
- receiver想StreamingContext发送Block报告
- 达到BatchInterval时间间隔生成批次,将数据当做RDD交给SparkContext处理
整个Streaming运行过程中,涉及到两个时间间隔:
- 批次时间间隔:BatchInterval
Block时间间隔:BlockInterval
接收器划分流式数据的时间间隔,可以调整大小,官方建议最小值不能小于50ms
默认值为200ms,属性:spark.streaming.blockInterval,调整设置BatchInterval: 1s = 1000ms = 5 * BlockInterval
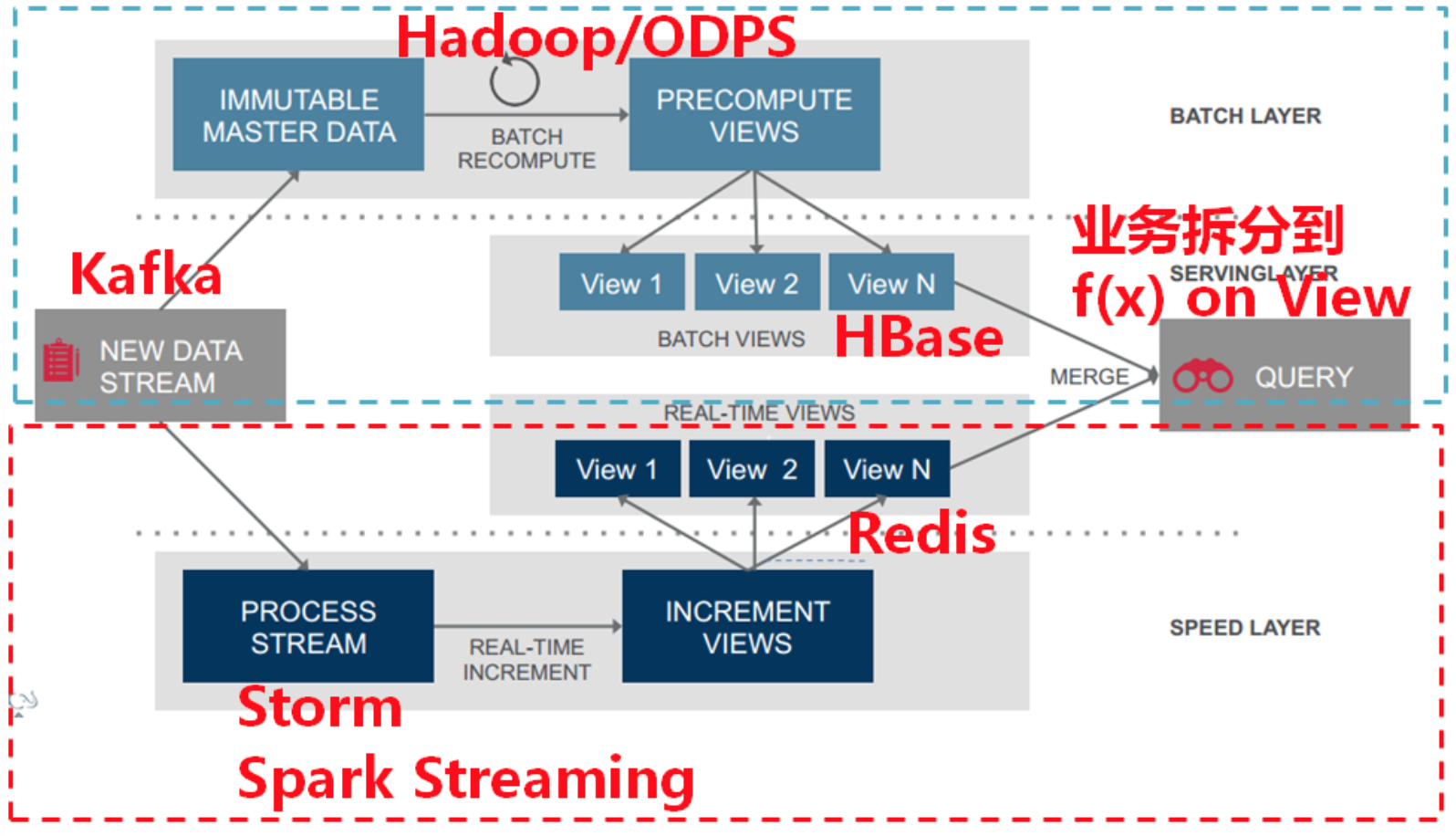
Lambda架构
Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架。
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。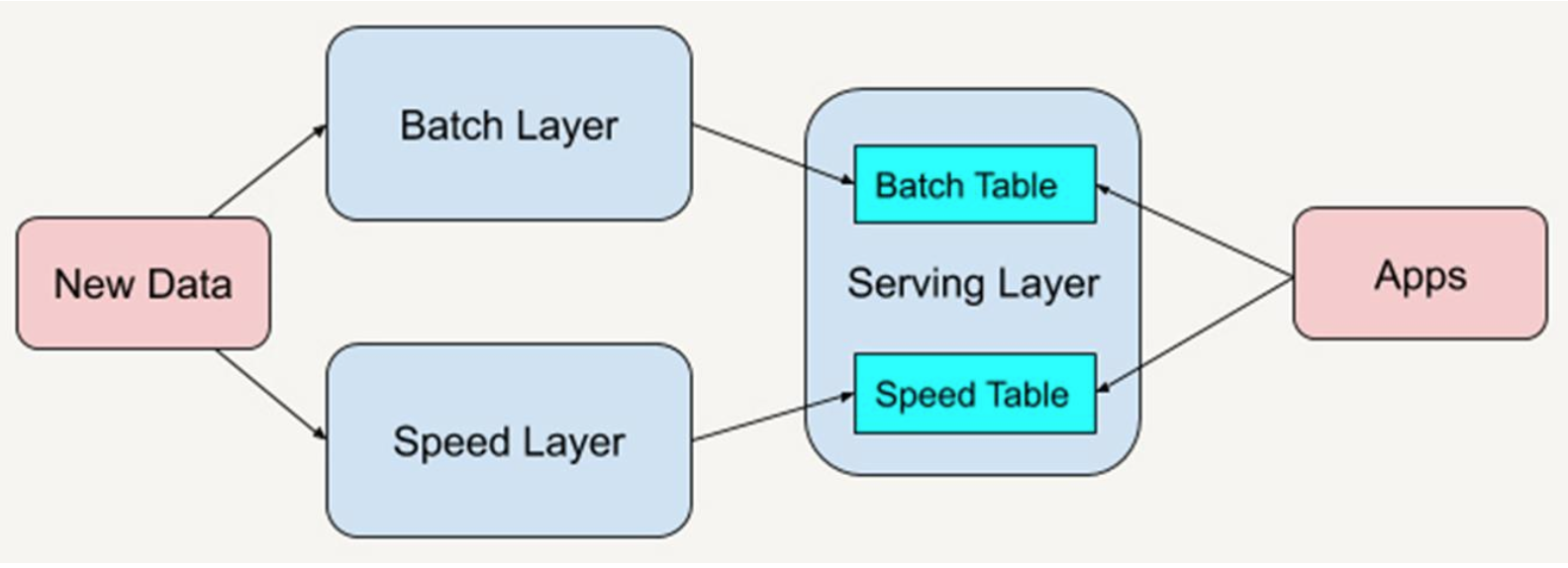
Lamdab架构分为三层:Batch Layer:批处理层,离线分析
- Speed Layer:速度层,实时分析
- Serving Layer:服务层,存储批处理层和速度层分析结果数据
DStream
SparkStreaming模块将流式数据封装的数据结构:DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
DStream内部是由一系列连续的RDD组成的,每个RDD都包含了特定时间间隔内的一批数据,如下图所示:
DStream Operations
DStream类似RDD,里面包含很多函数,进行数据处理和输出操作,主要分为两大类:
- DStream#Transformations:将一个DStream转换为另一个DStream
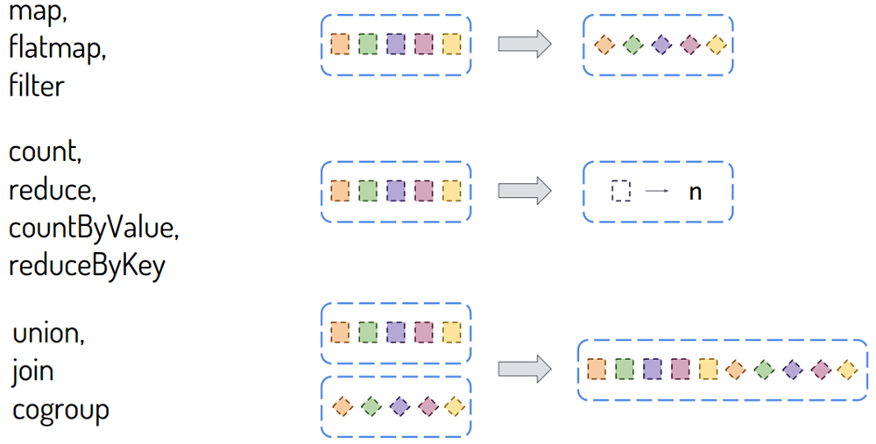
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#transformations-on-dstreams - DStream#Output Operations:将DStream中每批次RDD处理结果resultRDD输出
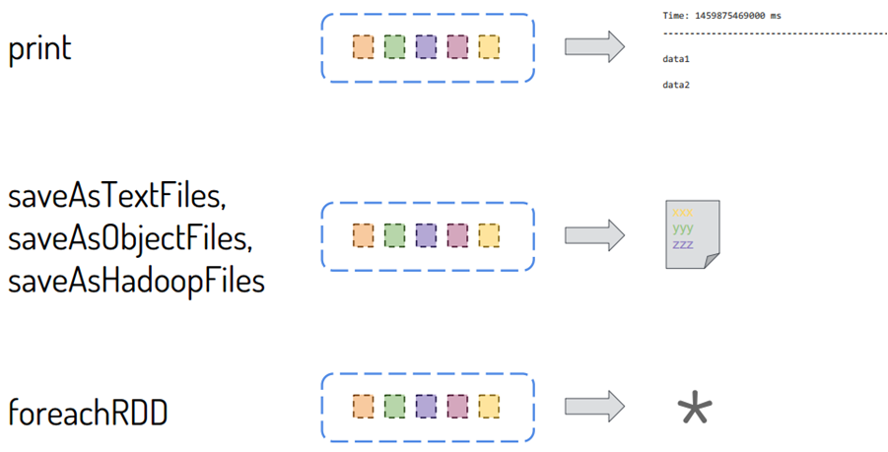 http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#output-operations-on-dstreams
http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#output-operations-on-dstreams
在SparkStreaming企业实际开发中,建议:能对RDD操作的就不要对DStream操作,当调用DStream中某个函数在RDD中也存在,使用针对RDD操作。
流式应用状态
无状态Stateless
- 使用transform和foreacRDD函数
实时增量数据ETL:实时从Kafka Topic中获取数据,经过初步转换操作,存储到ES或HBase表中
有状态State
函数:updateStateByKey、mapWithState(推荐,性能好)
双11大屏幕所有实时统计数字(比如销售额和销售量等),比如销售额、网站PV、UV等
窗口统计
窗口函数【window】声明如下,包含两个参数:
窗口大小(WindowInterval,每次统计数据范围)
- 滑动大小(每隔多久统计一次),都必须时批处理时间间隔BatchInterval整数倍

参考文档:http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#window-operations
Kafka集成
在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下: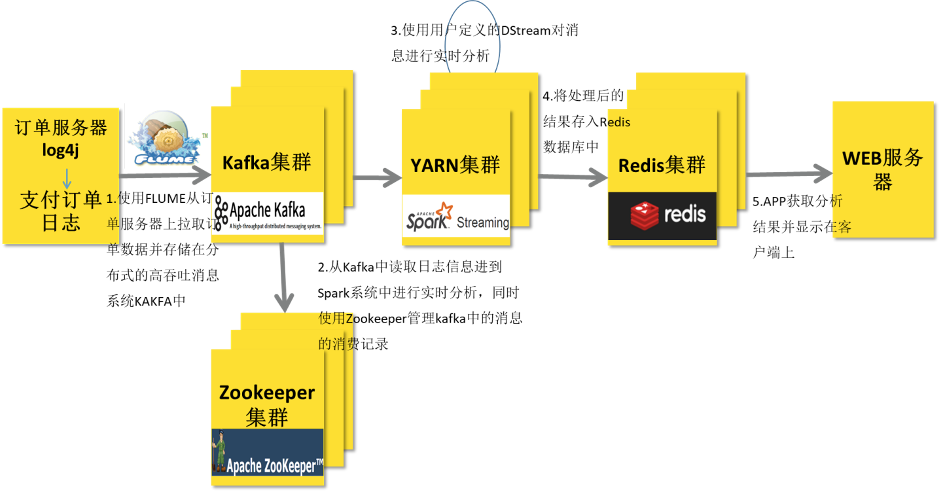
技术栈
Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -> UI
- 阿里工具Canal:监控MySQL数据库binlog文件,将数据同步发送到Kafka Topic中
https://github.com/alibaba/canal
https://github.com/alibaba/canal/wiki/QuickStart
- Maxwell
实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序
http://maxwells-daemon.io/
https://github.com/zendesk/maxwell
kafka 0.8.2(3.x版本不支持)
https://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html
- 简单消费者API(Consumer Simple Level API) ,Direct 直接拉取数据
高级消费API(Consumer High Level API),Receiver接收器接收数据
kafka 0.10.x
https://spark.apache.org/docs/3.1.2/streaming-kafka-0-10-integration.html
直接到Kafka Topic中依据偏移量范围获取数据,进行处理分析
- 每批次中RDD的分区与Topic分区一对一关系
- 获取Topic中数据的同时,还可以获取偏移量和元数据信息
```xml
org.apache.spark spark-streaming-kafka-0-10_2.12 3.1.2
```
工具类KafkaUtils中createDirectStream函数API使用说明(函数声明):
Kafka偏移量管理
当应用关闭以后,再次启动(Restart)执行,并没有继续从上次消费偏移量读取数据和获取以前状态信息,而是从最新偏移量(Latest Offset)开始的消费,有三种方式:Checkpoint恢复、Kafka自身和手动管理偏移量。
Checkpoint 恢复
当流式应用再次启动时,从Checkpoint 检查点目录恢复,可以读取上次消费偏移量信息和状态相关数据,继续实时处理数据。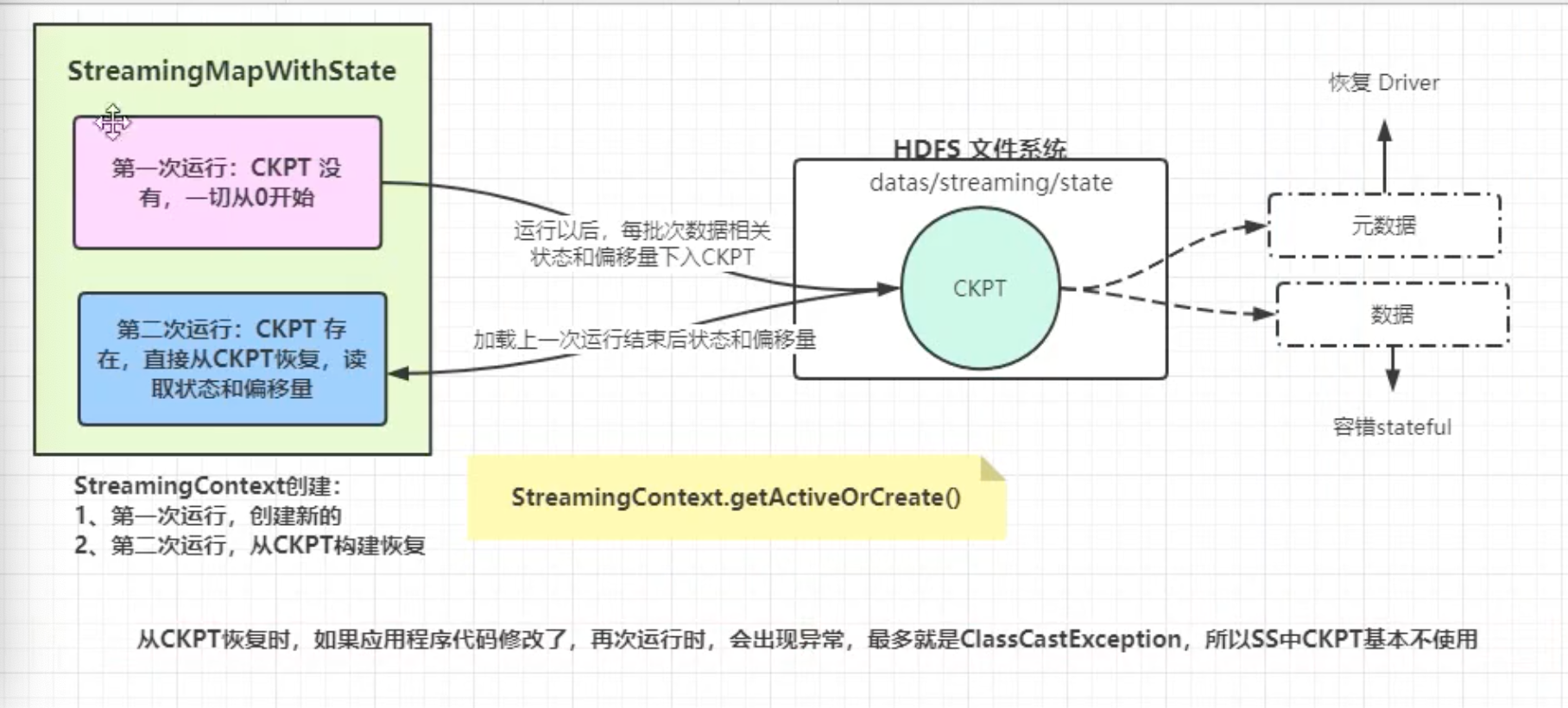
参考文档:http://spark.apache.org/docs/2.4.5/streaming-programming-guide.html#checkpointing
Kafka itself
- Kafka 自身管理消费偏移量
- 当每批次结果RDD输出完成以后,异步手动提交偏移量
手动管理偏移量(推荐)
用户编程管理每批次消费数据的偏移量,当再次启动应用时,读取上次消费偏移量信息,继续实时处理数据。针对偏移量数据:自己管理偏移量,将偏移量存储到MySQL表、Zookeeper、HBase或Redis。
参考文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html#storing-offsets
以下MySQL可以是其他数据: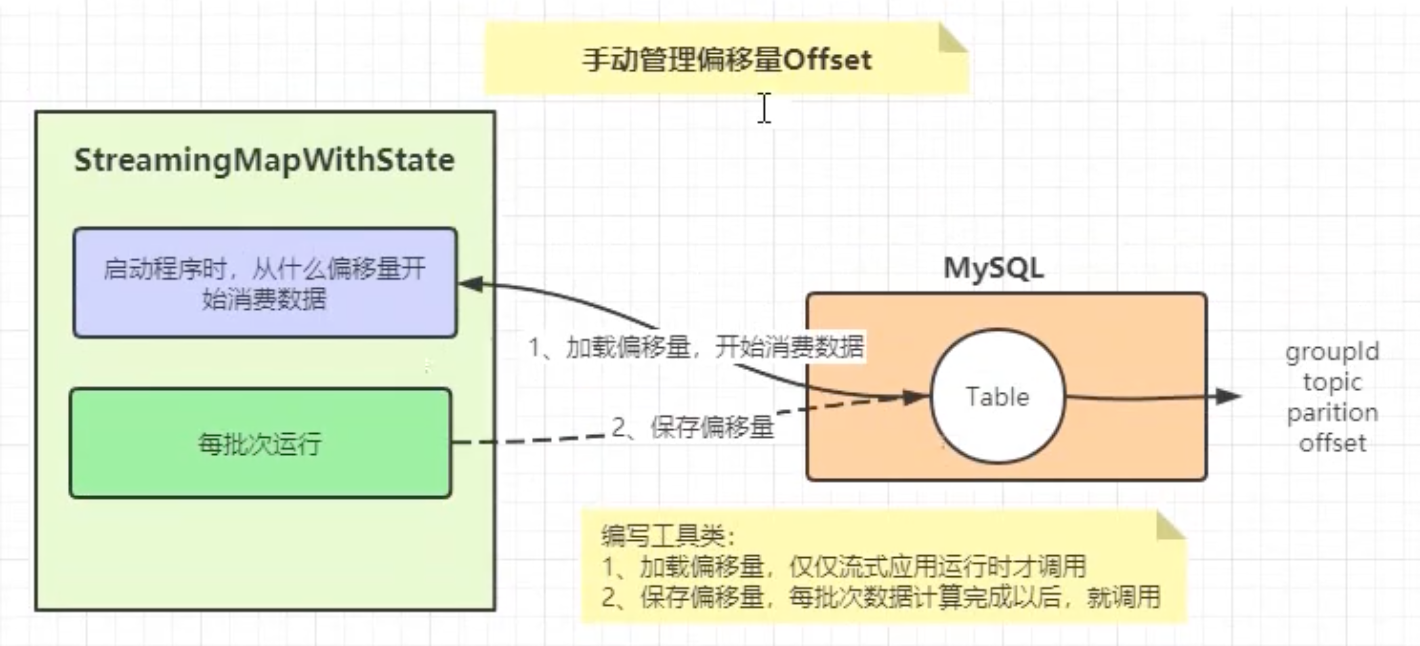
性能优化


若有收获,就点个赞吧
0 人点赞
