前世今生
Spark SQL是从shark发展而来。Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。
Spark SQL一直到2.0版本才算是真正稳定,发展经历如下几个阶段:
Spark SQL2.0数据结构演变: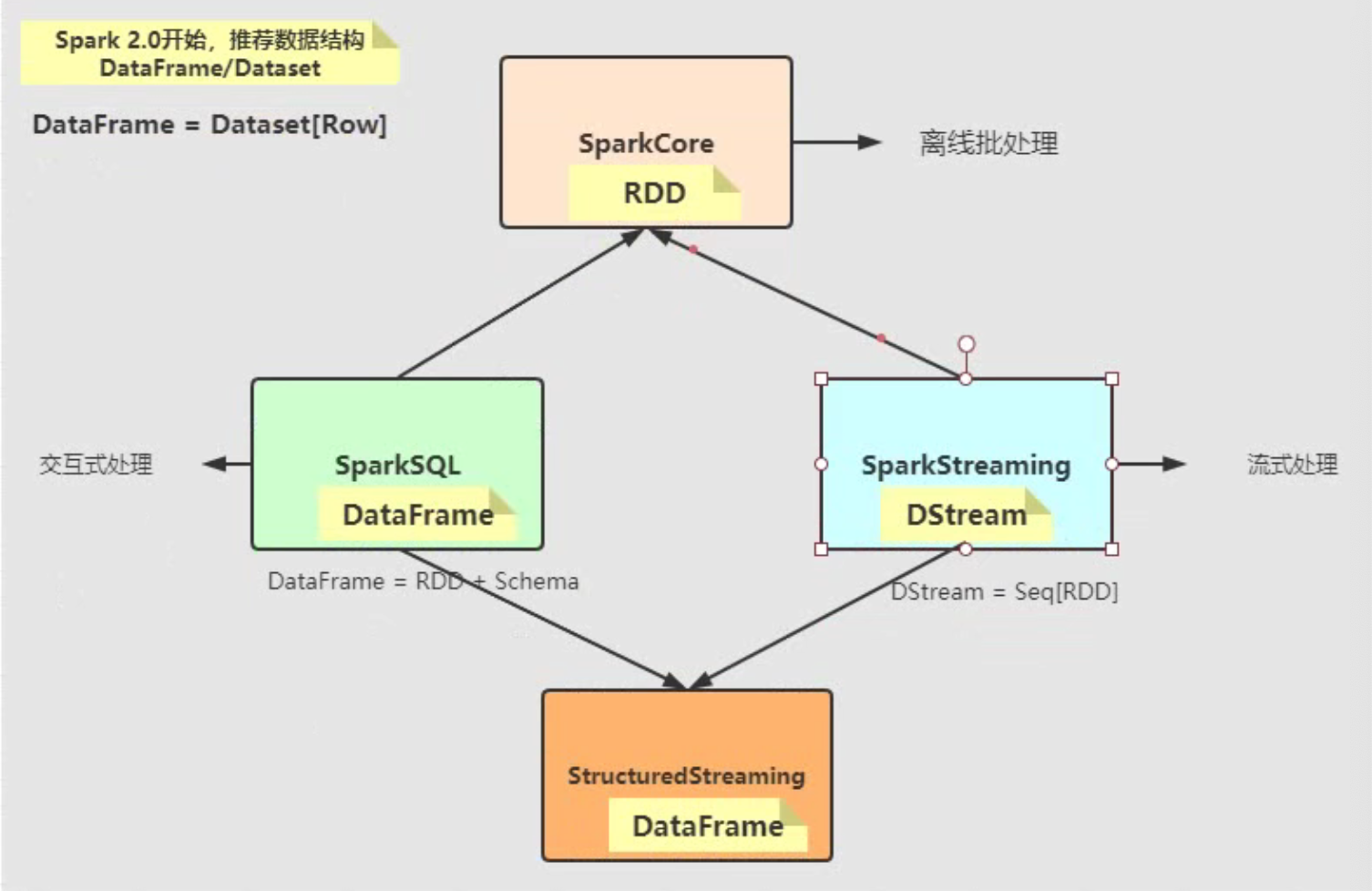
Spark SQL从Hive发展演变而来,功能远大于Hive;Spark SQL提供SQL和DSL两种方式分析数据,并且Hive框架拥有的功能Spark SQL都有。
SparkSession
加载读取外部数据源的数据,并将要处理的数据封装至数据结构(Dataset/DataFrame)。主要分为2种读取方式:
- 静态数据:spark.read
- 流式数据:spark.readStream
```scala
//采用构造者设计模式
val spark: SparkSession = SparkSession
.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[4]").config("spark.sql.shuffle.partitions", "4").getOrCreate()
spark.close()
<a name="hr3p1"></a>
# 数据结构
Dataset = RDD[CaseClass] + Schema<br />DataFrame = Dataset[Row] = RDD[Row] + Schema<br />**Dataset/DataFrame **是基于RDD之上的分布式数据集**。**<br />**解释:**
- ROW:弱类型,相当于元组 <br />row.getAs[type](name)<br />Row(value1,value2,...)
- Schema:结构化类型 StructType(封装StructField,包括name、type、nullable、metadata)
<a name="tmSDe"></a>
## DataFrame特点
数据集,来源于Python和Pandas和R语言数据结构dataFrame
- 分布式数据集,并且以列的方式组合,相当于具有schema的RDD
- 相当于关系型数据库中的表,但是底层有优化
- 提供一些抽象操作,如select、filter、aggregation、plot
- 由R语言或Pandas语言处理小数据集经验应用到处理分布式大数据集上
- 在1.3版本之前,叫SchemaRDD
<a name="ibXef"></a>
## RDD转换DataFrame
- 反射类型 RDD[caseClass]
- 自定义Schema RDD[Row]<br />1、RDD中数据类型为Row<br />2、针对Row中数据定义为Schema<br />3、使用SparkSession中方法将定义的Schema应用到RDD[Row]上
<a name="wgyJj"></a>
## toDF指定列名称
RDD或者Seq中类型必须是元组
```scala
val userDF: DataFrame = usersRDD
.map { line =>
val Array(id, age, sex, name, userId) = line.split("\\|")
(id.toInt, age.toInt, sex, name, userId)
}
.toDF("id", "age", "sex", "name", "userId")
Dataset
结合RDD与DataFrame优势的一个新型数据抽象,建立在RDD之上的分布式数据集。三者之间相互转换如下: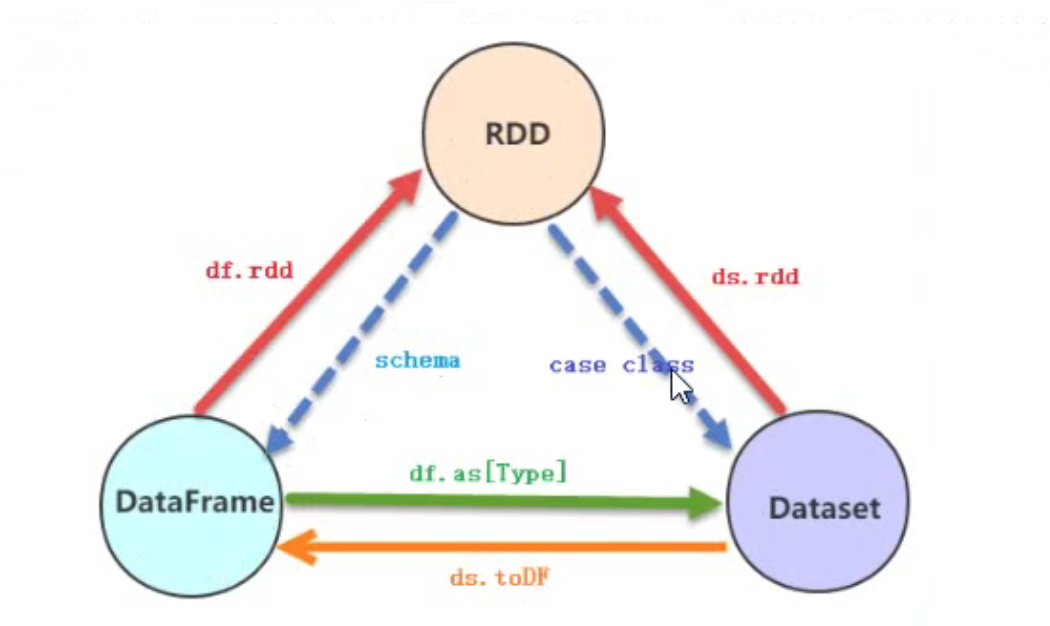
数据分析
- SQL编程,来源于Hive
DSL编程,调用Dataset API,主要包括两大类函数:类似RDD转换函数、类似SQL关键字函数
数据源
外部数据源
从Spark1.4开始提供一套完善外部数据源接口,以便从任意数据源加载Load和保存Save数据
加载读取数据:spark.read.format().option().load()
保存写入数据:dataset/dataframe.write.mode().format().option().load()
内置数据源
文本文件:text、json、csv
- 列式存储:parquet、orc
-
自定义UDF函数
在SQL中使用:spark.udf.register(“函数名称”,(匿名函数)=>{ } )
- 在DSL中使用:val name_udf = udf( ()=>{ } )
Spark on Hive
Spark on Hive与Hive on Spark
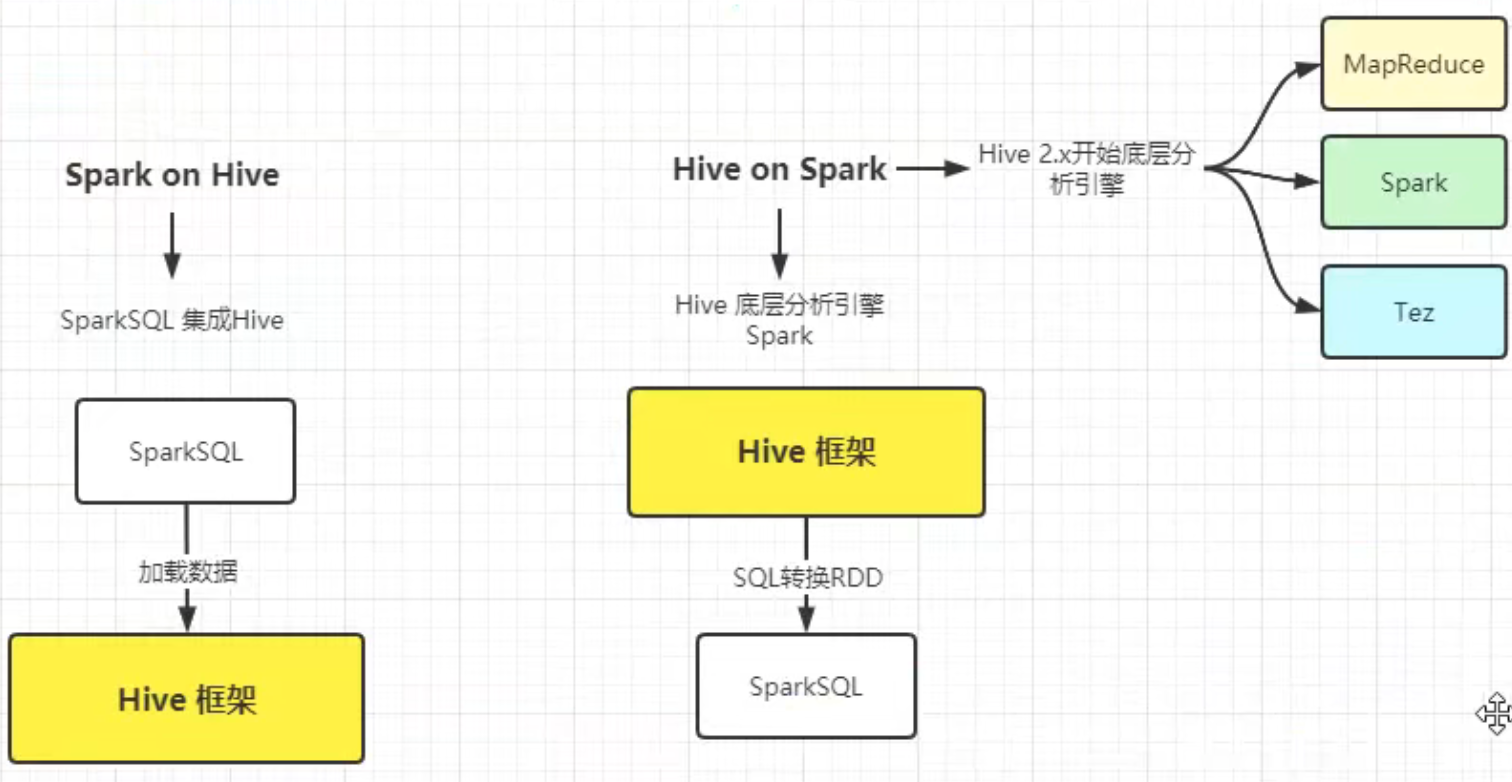
SparkSQL读取Hive MetaStore元数据,只需要Hive MetaStore服务启动。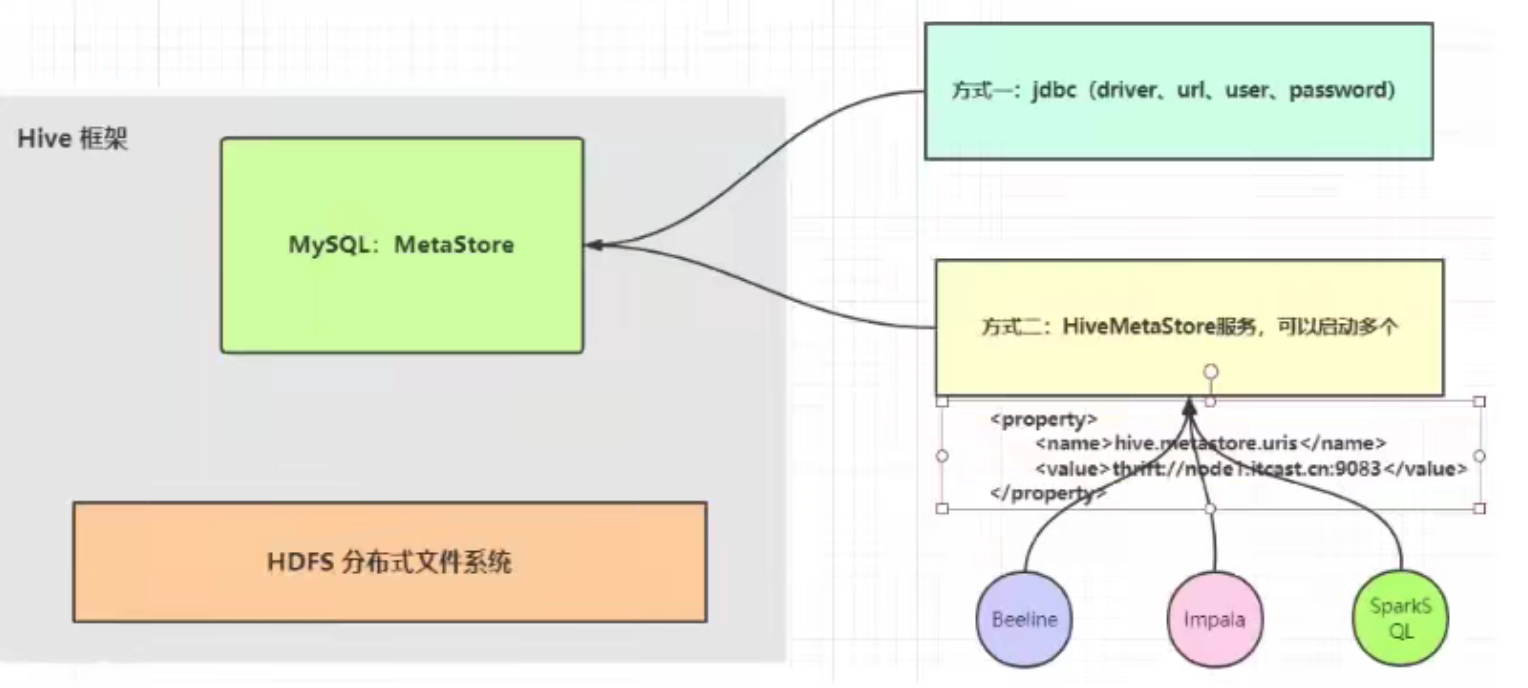
启动hive服务
- hive —service metastore
(必须带上后面参数,否则无法连接Failed to connect to the MetaStore) - nohup hive —service metastore > metastore.log 2>&1 &
spark配置
touch /opt/bigdata/spark/conf/hive-site.xml
vim hive-site.xml ```xml <?xml version=”1.0” encoding=”UTF-8” standalone=”no”?> <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
spark-shell --master local[2]
```scala
import org.apache.spark.sql.hive.HiveContext
val hc = new HiveContext(sc)
hc.sql("show databases").show
hc.sql("use test_hive")
hc.sql("select * from test_hive.employee").show
或者
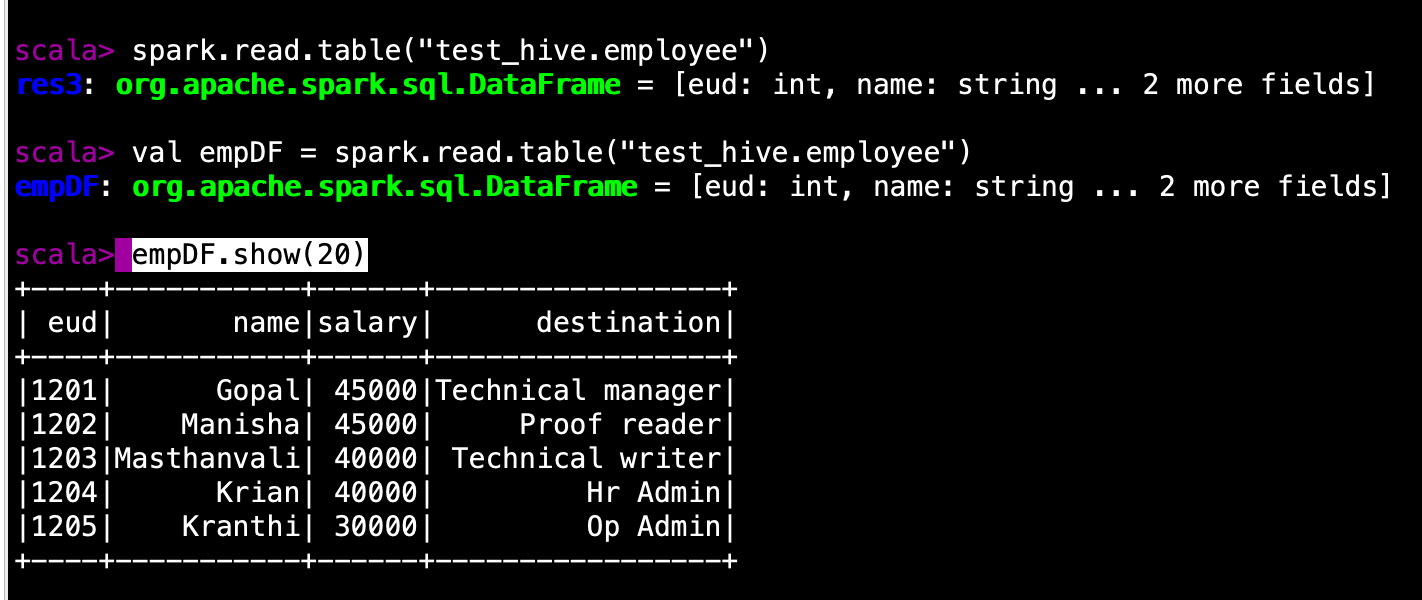
val empDF = spark.read.table("test_hive.employee")
empDF.show(20)
或者
spark.sql("select * from test_hive.employee").show(20)
IDEA集成Spark on hive
引入依赖(scala.binary.version = 2.12 和 spark.version =3.1.2)
<!-- spark SQL 集成Hive --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency>引入配置文件(resources)
/opt/bigdata/hadoop/etc/hadoop/core-site.xml
/opt/bigdata/hadoop/etc/hadoop/hdfs-site.xml
/opt/bigdata/spark/conf/hive-site.xml
Scala类编写
object SparkOnHive { def main(args: Array[String]): Unit = { //采用构造者设计模式 val spark: SparkSession = SparkSession .builder() .appName(this.getClass.getSimpleName.stripSuffix("$")) .master("local[4]") //指定hive元数据在hdfs上的位置 .config("spark.sql.warehouse.dir", "hdfs://master01:8020/user/hive/warehouse") // 导入hive集成 .config("hive.metastore.uris", "thrift://master01:9083") .enableHiveSupport() .config("spark.sql.shuffle.partitions", "4") .getOrCreate() // 导入隐式转换 spark.read.table("test_hive.employee") .show(10, truncate = false) spark.sql("select * from test_hive.employee") .show(10, truncate = false) spark.close() } }注意:spark.config(“hive.metastore.uris”,”thrift://master01:9083”).enableHiveSupport()
分布式SQL引擎
- Spark SQL CLI(不推荐)
- ThriftServer JDBC/ODBC Server(推荐)
Hive远程用户名和密码配置
vim /opt/bigdata/hive/conf/hive-site.xml<!--自定义远程连接用户名和密码--> <property> <name>hive.server2.authentication</name> <value>root</value> </property> <!--设置用户名和密码,如果有多个用户和密码,可以多写几个property--> <property> <name>hive.jdbc_passwd.auth.yonghu</name> <value>123456</value> </property>ThriftServer Server配置
启动metastore服务
- nohup hive —service metastore > metastore.log 2>&1 &
- 启动thriftserver服务:start-thriftserver.sh —master local[2]
- beeline -u jdbc:hive2://master01:10000 -n root -p 123456
-
不启动metastore服务
删除/opt/bigdata/spark/conf/ hive-site.xml,否则无法启动thriftserver
- 启动thriftserver服务(启动一个SparkSubmit进程)
start-thriftserver.sh —hiveconf hive.server2.thrift.port=10000 —hiveconf hive.server2.thrift.bind.host=master01 —master local[2] - beeline
- !connect jdbc:hive2://master01:10000
- 输入用户和密码
- 验证:http://master01:4040/jobs/
注意:如果hive配置mysql元数据库,还需要cp mysql-connector-java-8.0.22.jar /opt/bigdata/spark/jars/

若有收获,就点个赞吧
0 人点赞
