概述
Apache Spark在2016年的时候启动了Structured Streaming项目,一个基于Spark SQL的全新流计算引擎Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
在这个新的引擎中,也很容易实现之前在Spark Streaming中很难实现的一些功能,比如Event Time的支持,Stream-Stream Join(2.3.0 新增的功能),毫秒级延迟(2.3.0 即将加入的 Continuous Processing)。
Spark Streaming缺点
Spark Streaming会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。
- 使用 Processing Time 而不是 Event Time
Spark Streaming 的数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。 - Complex, low-level api
DStream(Spark Streaming 的数据模型)提供的API类似RDD的API。 - reason about end-to-end application
DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证 批流代码不统一
流式计算一直没有一套标准化、能应对各种场景的模型。Structured Streaming优点
Incremental query model(增量查询模型)
- Support for end-to-end application(支持端到端应用)
-
编程模型
Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的。如下图所示:
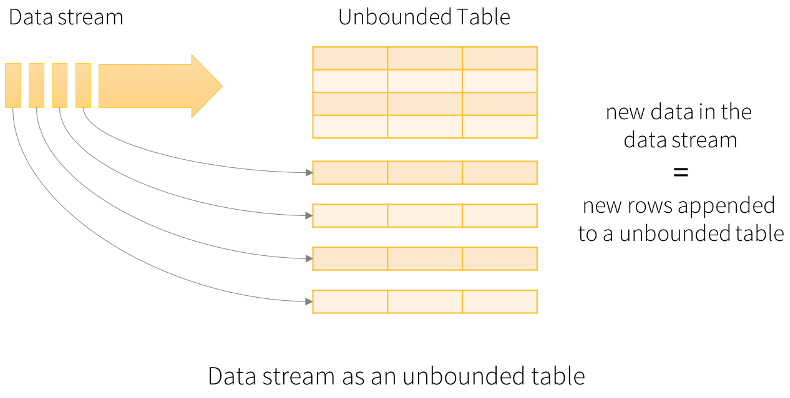
在这个模型中,主要存在下面几个组成部分: Input Table(Unbounded Table),流式数据的抽象表示,没有限制边界的,表的数据源源不断增加;
- Query(查询),对 Input Table 的增量式查询,只要Input Table中有数据,立即执行查询分析操作,然后进行输出(类似SparkStreaming中微批处理);
- Result Table,Query 产生的结果表
- Output,Result Table 的输出,依据设置的输出模式OutputMode输出结果
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项就像是表中的一个新行被附加到无边界的表中,用静态结构化数据的批处理查询方式进行流计算。
架构图
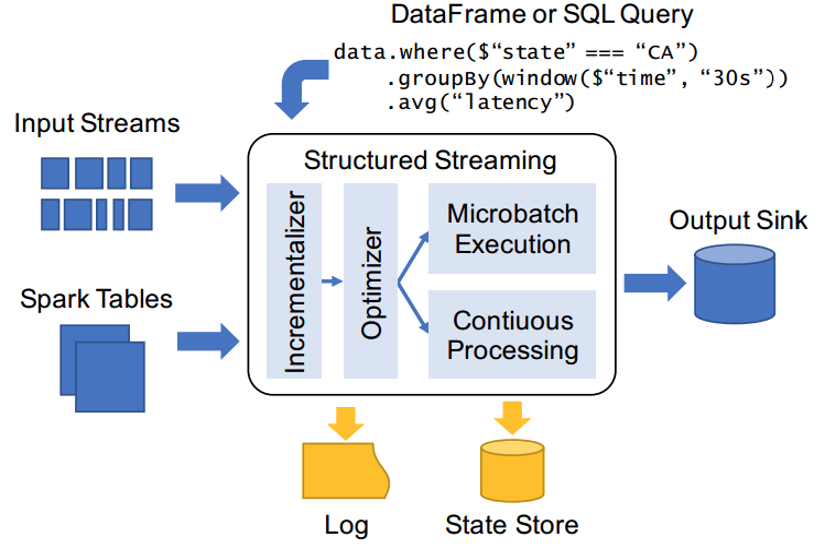
Input Sources 输入源
从Spark 2.0至Spark 2.4版本,目前支持数据源有4种,其中Kafka 数据源使用作为广泛。在Structured Streaming中使用SparkSession#readStream读取流式数据,返回DataStreamReader对象,指定读取数据源相关信息。
将目录中写入的文件作为数据流读取,支持的文件格式为:text、csv、json、orc、parquet。
http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#input-sources
Streaming Queries
在StructuredStreaming中定义好Result DataFrame/Dataset后,调用writeStream()返回DataStreamWriter对象,设置查询Query输出相关属性,启动流式应用运行,相关属性如下: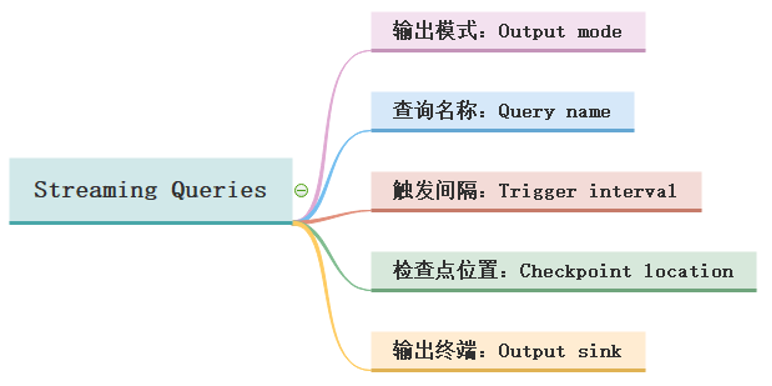
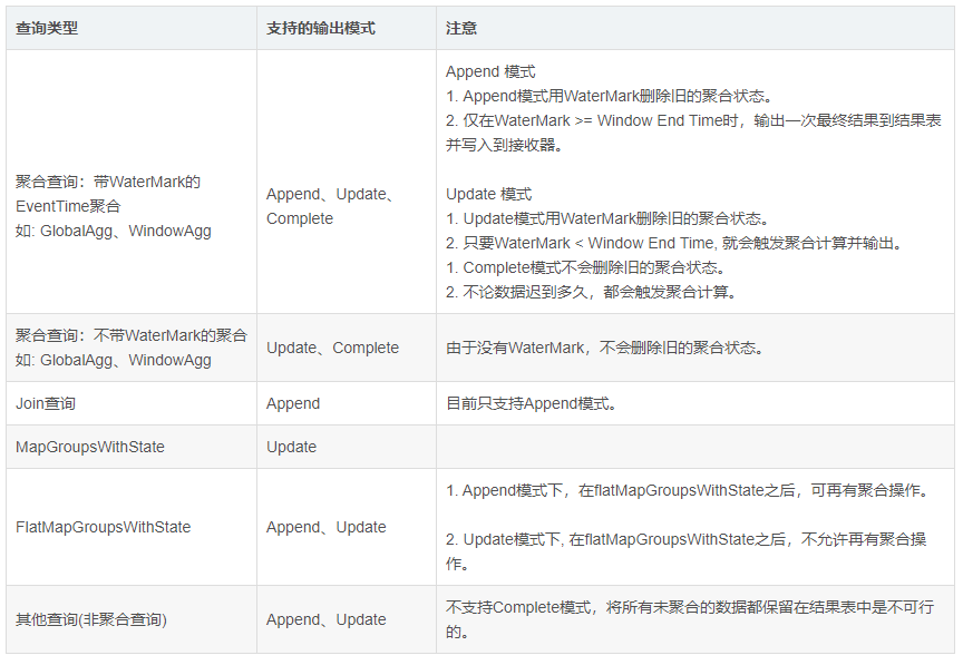
输出模式
- 追加模式(Append mode)
只输出那些将来永远不可能再更新的数据,然后数据从内存移除 。没有聚合的时候,append和update一致;有聚合的时候,一定要有水印,才能使用。 - 完全模式(Complete mode)
每次触发后,整个Result Table将被输出到sink,aggregation queries(聚合查询)支持。全部输出,必须有聚合。 - 更新模式(Update mode)
只输出更新数据(更新和新增)
查询名称
可以给每个查询Query设置名称Name,必须是唯一的,直接调用DataFrameWriter中queryName方法即可,实际生产开发建议设置名称。
触发时间
触发器决定了多久执行一次查询并输出结果,当不设置时,默认只要有新数据,就立即执行查询Query,再进行输出。目前来说,支持三种触发间隔设置: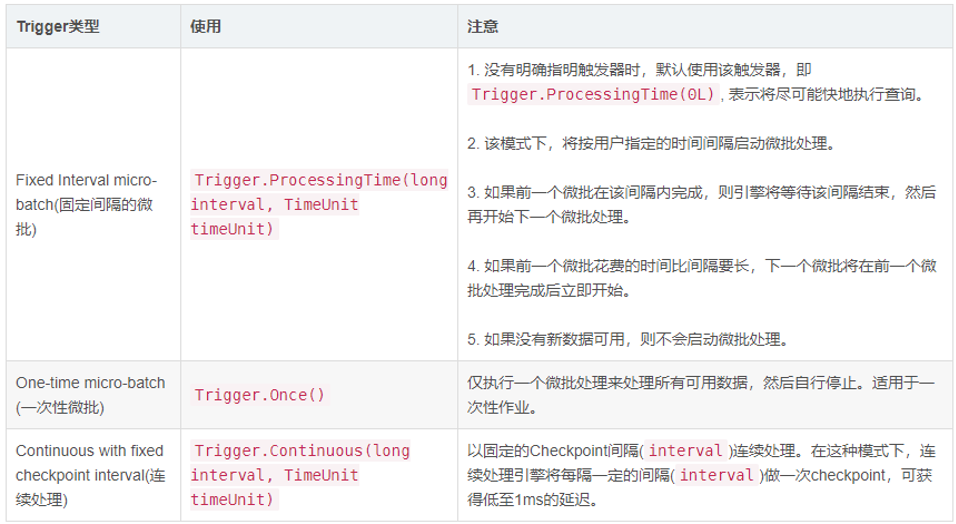
其中Trigger.Processing表示每隔多少时间触发执行一次,此时流式处理依然属于微批处理;从Spark 2.3以后,支持Continue Processing流式处理,设置触发间隔为Trigger.Continuous。
检查点位置
在Structured Streaming中使用Checkpoint 检查点进行故障恢复。如果实时应用发生故障或关机,可以恢复之前的查询的进度和状态,并从停止的地方继续执行,使用Checkpoint和预写日志完成。使用检查点位置配置查询,那么查询将所有进度信息(即每个触发器中处理的偏移范围)和运行聚合(例如词频统计wordcount)保存到检查点位置。此检查点位置必须是HDFS兼容文件系统中的路径,两种方式设置Checkpoint Location位置:
- DataStreamWrite设置
streamDF.writeStream.option(“checkpointLocation”, “xxx”) SparkConf设置
sparkConf.set(“spark.sql.streaming.checkpointLocation”, “xxx”)输出终端
Structured Streaming 非常显式地提出了输入(Source)、执行(StreamExecution)、输出(Sink)的3个组件,并且在每个组件显式地做到fault-tolerant,由此得到整个streaming程序的 end-to-end exactly-once guarantees。目前Structured Streaming内置FileSink、Console Sink、Foreach Sink(ForeachBatch Sink)、Memory Sink及Kafka Sink,其中测试最为方便的是Console Sink。
文件接收器
将输出存储到目录文件中,支持文件格式:parquet、orc、json、csv等,示例如下:

相关注意事项如下:支持OutputMode为:Append追加模式;
- 必须指定输出目录参数【path】,必选参数,其中格式有parquet、orc、json、csv等等;
- 容灾恢复支持精确一次性语义exactly-once;
-
Memory Sink
输出作为内存表存储在内存中, 支持Append和Complete输出模式。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中,因此,请谨慎使用。
Foreach Sink
Structured Streaming提供接口foreach和foreachBatch,允许用户在流式查询的输出上应用任意操作和编写逻辑,比如输出到MySQL表、Redis数据库等外部存系统。其中foreach允许每行自定义写入逻辑,foreachBatch允许在每个微批量的输出上进行任意操作和自定义逻辑,建议使用foreachBatch操作。
ForeachBatch Sink
方法foreachBatch允许指定在流式查询的每个微批次的输出数据上执行的函数,需要两个参数:微批次的输出数据DataFrame或Dataset、微批次的唯一ID。

使用foreachBatch函数输出时,以下几个注意事项: 重用现有的批处理数据源,可以在每个微批次的输出上使用批处理数据输出Output
- 写入多个位置
- 应用其他DataFrame操作,流式DataFrame中不支持许多DataFrame和Dataset操作,使用foreachBatch可以在每个微批输出上应用其中一些操作,但是,必须自己解释执行该操作的端到端语义。
- 默认情况下,foreachBatch仅提供至少一次写保证。 但是,可以使用提供给该函数的batchId作为重复数据删除输出并获得一次性保证的方法。
-
Structured Streaming核心理念
Structured Streaming的核心设计理念和目标之一:支持一次且仅一次Extracly-Once的语义。
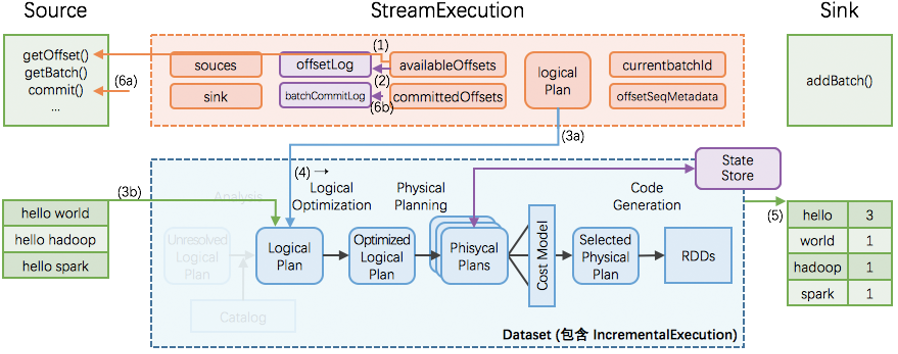
为了实现这个目标,Structured Streaming设计source、sink和execution engine来追踪计算处理的进度,这样就可以在任何一个步骤出现失败时自动重试。 每个Streaming source都被设计成支持offset,进而可以让Spark来追踪读取的位置
- Spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围
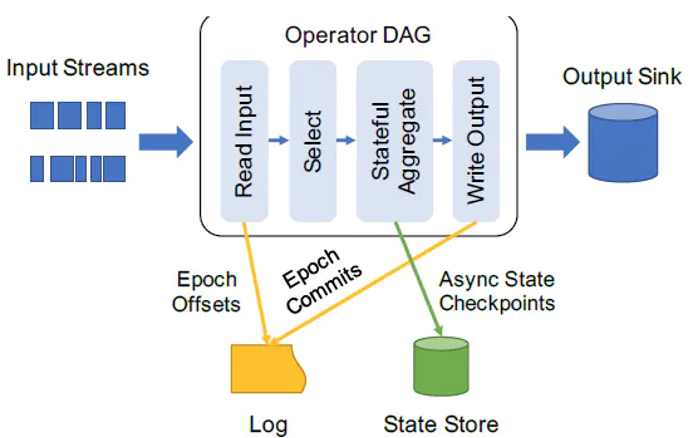
- sink被设计成可以支持在多次计算处理时保持幂等性,即用同样的一批数据,无论多少次去更新sink,都会保持一致和相同的状态。
综合利用基于offset的source,基于checkpoint和wal的execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。
集成Kafka
官方文档:http://spark.apache.org/docs/3.1.2/structured-streaming-kafka-integration.html
流去重
在实时流式应用中,最典型的应用场景:网站UV统计。
在SparkStreaming或Flink框架中要想实现【网站UV统计】需要借助于外部存储系统,比如Redis内存数据库或者HBase列式存储数据库,存储UserId,利用数据库特性去重,最后进行count。
Structured Streaming可以使用deduplication对有无Watermark的流式数据进行去重操作:
- 无 Watermark
对重复记录到达的时间没有限制。查询会保留所有的过去记录作为状态用于去重。 - 有 Watermark
对重复记录到达的时间有限制。查询会根据水印删除旧的状态数据。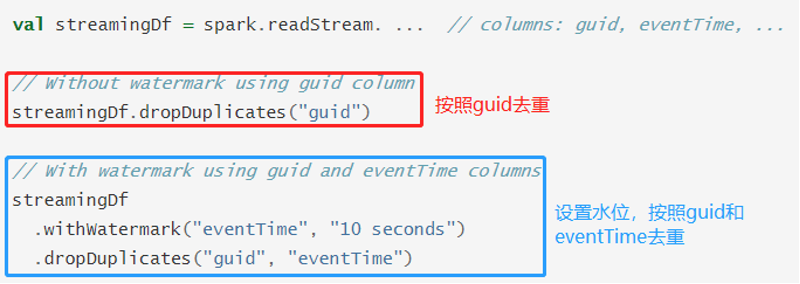
Continuous Processing
连续处理(Continuous Processing)是Spark 2.3中引入的一种新的实验性流执行模式,可实现低的(~1 ms)端到端延迟,并且至少具有一次容错保证。 将其与默认的微批处理(micro-batch processing)引擎相比较,该引擎可以实现一次性保证,但最多可实现~100ms的延迟。
与micro-batch模式缺点和优点都很明显,缺点是不容易做扩展,优点是延迟更低。
使用方式: ```scala val query: StreamingQuery = etlStreamDF.writeStream // 对流式应用输出来说,设置输出模式 .outputMode(OutputMode.Append()) .format(“kafka”) .option(“kafka.bootstrap.servers”, “node1.itcast.cn:9092”) .option(“topic”, “etlTopic”) // 设置检查点目录 .option(“checkpointLocation”, s”datas/structured/etl-100002”) // TODO: 设置持续流处理 Continuous Processing, 指定CKPT时间间隔 /*
*/ .trigger(Trigger.Continuous(“1 second”)) // 流式应用,需要启动start .start()the continuous processing engine will records the progress of the query every second持续流处理引擎,将每1秒中记录当前查询Query进度状态
时间时间窗口
在Streaming流式数据处理中,按照时间处理数据,其中时间有三种概念:
- 事件时间EventTime:表示数据本身产生的数据,该字段在数据本身中
- 注入时间IngestionTime:表示数据到达流式系统时间,简而言之就是流式处理系统接收到数据的时间
- 处理时间ProcessingTime:表示数据被流式系统真正开始计算操作的时间
不同流式计算框架支持时间不一样,SparkStreaming框架仅仅支持处理时间,Structured Streaming支持事件时间和处理时间,Flink框架支持三种时间数据操作,实际项目中往往针对【事件时间EventTime】进行数据处理操作,更加合理化。
event-time窗口
基于事件时间窗口聚合操作:基于窗口的聚合(例如每分钟事件数)只是事件时间列上特殊类型的分组和聚合,其中每个时间窗口都是一个组,并且每一行可以属于多个窗口/组。
事件时间EventTime是嵌入到数据本身中的时间,数据实际真实产生的时间。
基于事件时间窗口统计有两个参数索引:分组键(如单词)和窗口(事件时间字段)。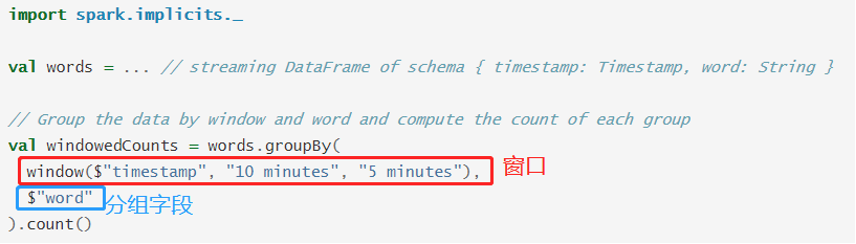
将【(event-time向上取 能整除 滑动步长的时间) - (最大窗口数×滑动步长)】作为”初始窗口“的开始时间,然后按照窗口滑动宽度逐渐向时间轴前方推进,直到某个窗口不再包含该event-time 为止,最终以”初始窗口”与”结束窗口”之间的若干个窗口作为最终生成的 event-time 的时间窗口。

延迟数据处理
Spark 2.1引入的watermarking允许用户指定延迟数据的阈值,也允许引擎清除掉旧的状态。即根据watermark机制来设置和判断消息的有效性,如可以获取消息本身的时间戳,然后根据该时间戳来判断消息的到达是否延迟(乱序)以及延迟的时间是否在容忍的范围内(延迟的数据是否处理)。
通过指定event-time列(上一批次数据中EventTime最大值)和预估事件的延迟时间上限(Threshold)来定义一个查询的水位线watermark。
Watermark = MaxEventTime - Threshod
设置Watermark以后,输出模式OutputMode只能是Append和Update,使用方式: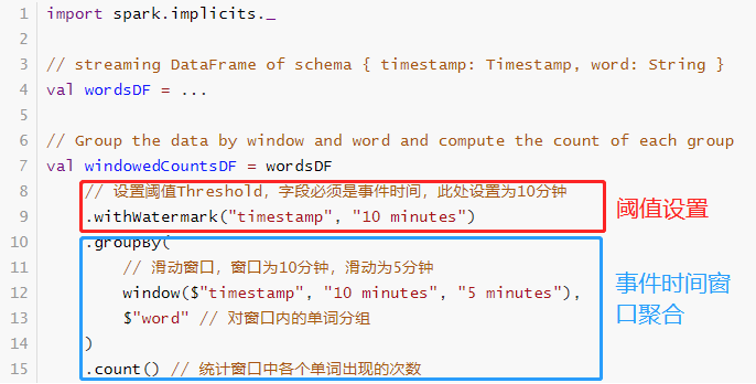

若有收获,就点个赞吧
0 人点赞
