概述
https://hbase.apache.org/downloads.html
Apache HBase 是 Hadoop 数据库,一个分布式、可伸缩的大数据存储。
HBase是依赖Hadoop的。为什么HBase能存储海量的数据?因为HBase是在HDFS的基础之上构建的,HDFS是分布式文件系统。
- 是No SQL数据库的一种,不支持Join和事务
- 不支持ACID(Atomicity原子性、Consistency一致性、Isolation隔离性、Durability持久性)
-
为什么要使用HBase?
我们已经学过分布式搜索引擎「Elasticsearch」、分布式文件系统「HDFS」、分布式消息队列「Kafka」、缓存数据库「Redis」等。能够处理数据的中间件(系统),这些中间件基本都会有持久化的功能。
Mysql
MySQL是单机的。MySQL能存储多少数据,取决于那台服务器的硬盘大小。- Elasticsearch
分布式的搜索引擎,主要用于检索。理论上Elasticsearch也是可以存储海量的数据(毕竟分布式),但是如果数据没有经常「检索」的需求,其实不必放到Elasticsearch,数据写入Elasticsearch需要分词,无疑会浪费资源。 - Kafka
主要用来处理消息的(解耦异步削峰)。数据到Kafka,Kafka会将数据持久化到硬盘中,并且Kafka是分布式的(很方便的扩展),理论上Kafka可以存储很大的数据。但是Kafka的数据我们不会「单独」取出来。持久化了的数据,最常见的用法就是重新设置offset,做「回溯」操作。 - Redis
缓存数据库,所有的读写都在内存中,速度快。AOF/RDB存储的数据都会加载到内存中,Redis不适合存大量的数据。 HDFS
可存储海量的数据的,它就是为海量数据而生的。它也有明显的缺点:不支持随机修改,查询效率低,对小文件支持不友好。数据模型
HBase里边也有表、行和列的概念。
一行数据由一个行键(RowKey)和一个或多个相关的列以及它的值所组成。
在HBase里边,先有列族,后有列。如图: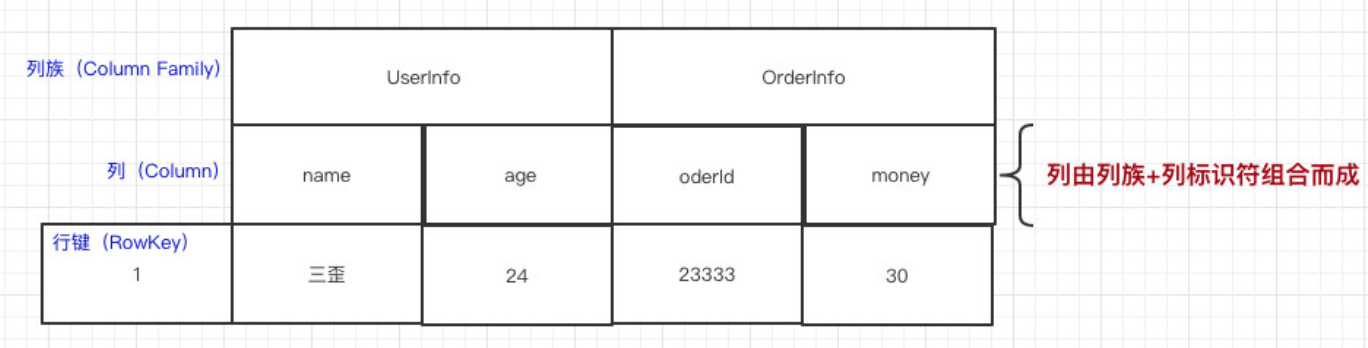
HBase表的每一行中,列的组成都是灵活的,行与行之间的列不需要相同。即一个列族下可以任意添加列,不受任何限制。如图下: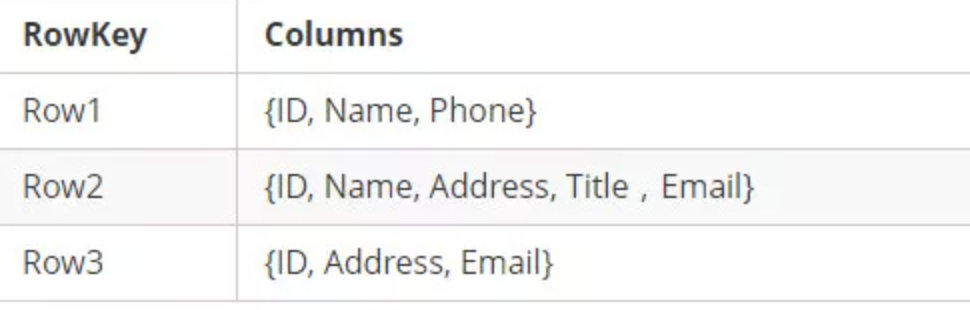
HBase的Key-Value
HBaseKey-Value结构图:

Key由RowKey(行键)+ColumnFamily(列族)+Column Qualifier(列修饰符)+TimeStamp(时间戳—版本)+KeyType(类型)组成,而Value就是实际上的值。HBase架构
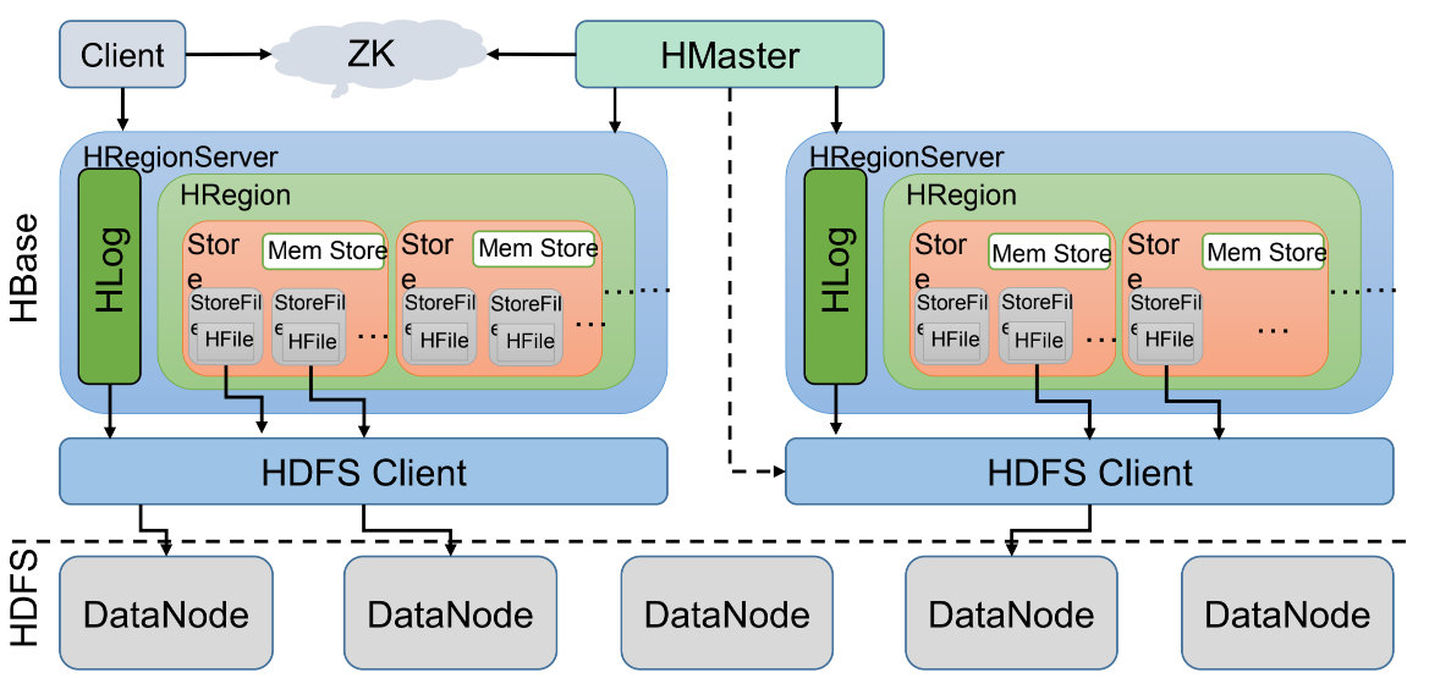
Zookeeper
存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
Client
提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。包括MapReduce、Spark、Flink。
Hmaster
HMaster会处理 HRegion 的分配或转移。
如果HRegion的数据量太大的话,HMaster会对拆分后的Region重新分配RegionServer。(如果发现失效的HRegion,也会将失效的HRegion分配到正常的HRegionServer中)
HMaster会处理元数据的变更和监控RegionServer的状态。HRegionServer
处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
执行流程
client请求到Zookeeper
- Zookeeper返回HRegionServer地址给client
- client得到Zookeeper返回的地址去请求HRegionServer
-
HRegionServer
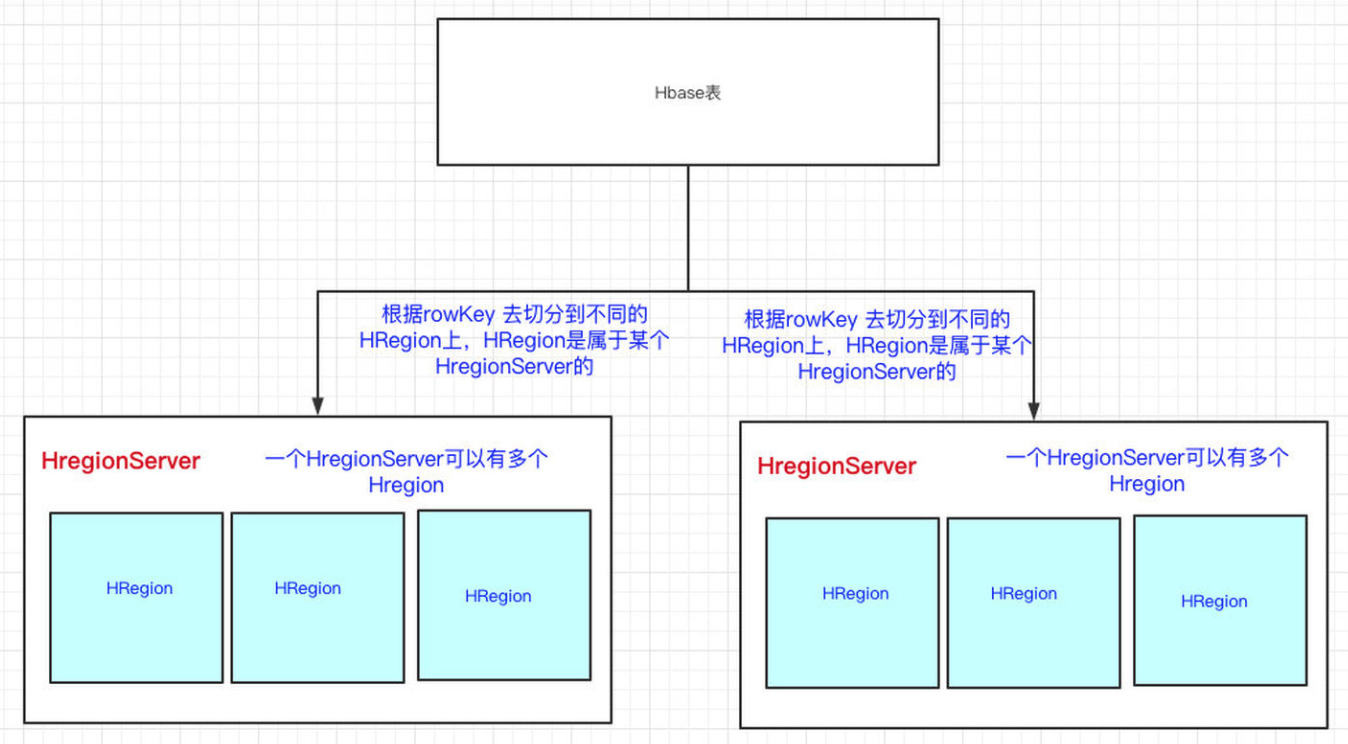
HBase可以存储海量的数据,HBase是分布式的。即:HBase一张表的数据会分到多台机器上的。那HBase是怎么切割一张表的数据的呢?用的就是RowKey来切分,其实就是表的横向切割。
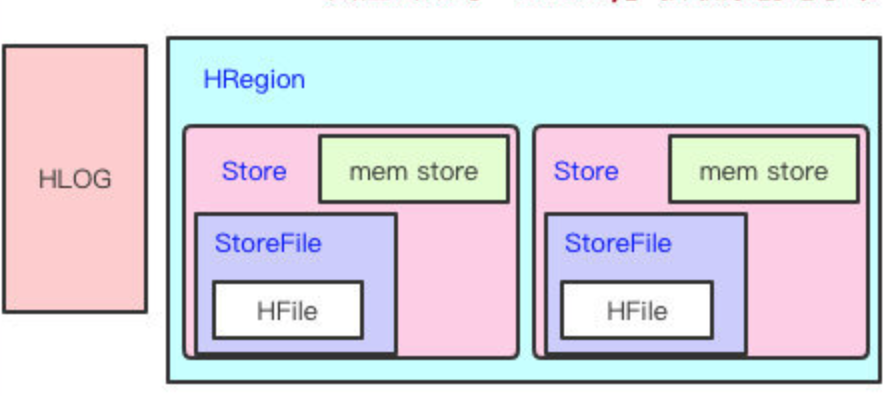
HRegion
Store
一个列族的数据是存储在一起的,所以一个列族的数据是存储在一个Store里边的。即HBase是基于列族存储的(毕竟物理存储,一个列族是存储到同一个Store里的)
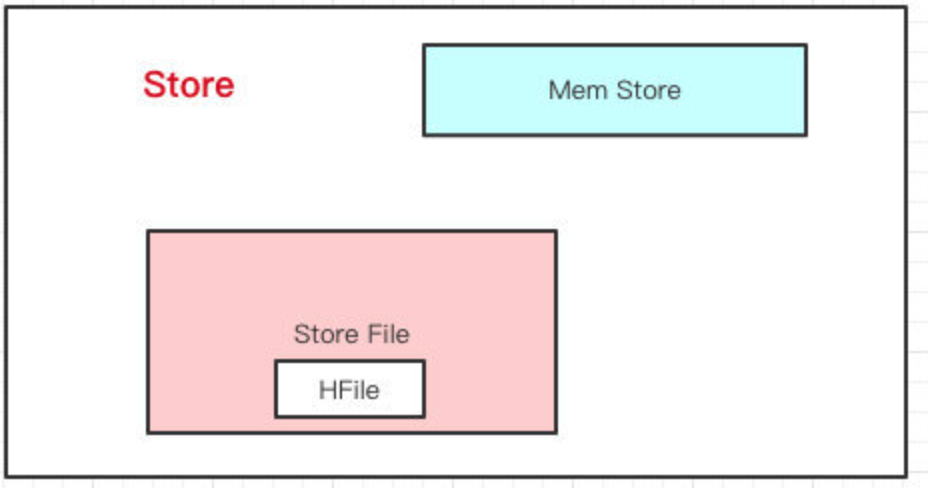
MemStore
HBase在写数据的时候,会先写到MemStore(类似于内存 buffer),当MemStore超过一定阈值,就会将内存中的数据刷写到硬盘上,形成StoreFile。
StoreFile
StoreFile底层是以HFile的格式保存,HFile是HBase中KeyValue数据的存储格式。HFile是HBase实际存储的数据格式,而StoreFile只是HBase里的一个名字。
总结
HRegionServer是真正干活的机器(用于与hdfs交互),HBase表用RowKey来横向切分表
- HRegion有多个Store,每个Store就是一个列族的数据(所以HBase是基于列族存储的)
Store里有MenStore和StoreFile(HFile),其实就是先走一层内存,然后再刷磁盘的结构
HLog(WAL)
HLog是顺序写到磁盘的。
写数据的时候是先写到内存的,为了防止机器宕机,内存的数据没刷到磁盘中就挂了。所以在写MemStore的时候还会写一份HLog。HA高可用
基于ZK的临时节点、watch机制来实现的
-
最终总结
HBase是一个NoSQL数据库,一般用它来存储海量的数据(因为它基于HDFS分布式文件系统上构建的)
- HBase的一行记录由一个RowKey和一个或多个的列以及它的值所组成。先有列族后有列,列可以随意添加
- HBase的增删改记录都有「版本」,默认以时间戳的方式实现
- RowKey的设计如果没有特殊的业务性,最好设计为散列的,避免热点数据分布在同一个HRegionServer中
- HBase的读写都经过Zookeeper去拉取meta数据,定位到对应的HRegion,然后找到HRegionServer

若有收获,就点个赞吧
0 人点赞
