谷歌起源
大数据起源于-谷歌,于2003年起发布一系列论文:
- 《The Google File System 》
- 《MapReduce: Simplified Data Processing onLarge Clusters》
- 《Bigtable: A Distributed Storage System for Structured Data》
GFS
GFS 是一个大型的分布式文件系统,为 Google 大数据处理系统提供海量存储,并且与 MapReduce 和 BigTable 等技术结合得十分紧密,处于系统的底层。GFS 使用廉价的商用机器构建分布式文件系统,将容错的任务交由文件系统来完成,利用软件的方法解决系统可靠性问题,这样可以使得存储的成本成倍下降。
GFS 的系统架构主要由一个 Master Server(主服务器)和多个 Chunk Server(数据块服务器)组成。
Master Server 主要负责维护系统中的名字空间,访问控制信息,从文件到块的映射及块的当前位置等元数据,并与 Chunk Server 通信。
Chunk Server 负责具体的存储工作。数据以文件的形式存储在 Chunk Server 上。Client 是应用程序访问 GFS 的接口。
GFS 的系统架构设计有两大优势。
- Client 和 Master Server之间只有控制流,没有数据流,因此降低了 Master Server 的负载。
- 由于 Client 与 Chunk Server之间直接传输数据流,并且文件被分成多个 Chunk 进行分布式存储,因此 Client 可以同时并行访问多个 Chunk Server,从而让系统的 I/O 并行度提高。
Chunk Server 在硬盘上存储实际数据。Google 把每个 chunk 数据块的大小设计成 64MB,每个 chunk 被复制成 3 个副本放到不同的 Chunk Server 中,以创建冗余来避免服务器崩溃。如果某个 Chunk Server 发生故障,Master Server 便把数据备份到一个新的地方。
MapReduce
GFS 解决了 Google 海量数据的存储问题,MapReduce则是为了解决如何从这些海量数据中快速计算并获取期望结果的问题。
MapReduce 是由 Google 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。
MapReduce 实现了 Map 和 Reduce 两个功能。Map 把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集,而 Reduce 是把两个或更多个 Map 通过多个线程、进程或者独立系统进行并行执行处理得到的结果集进行分类和归纳。
用户只需要提供自己的 Map 函数及 Reduce 函数就可以在集群上进行大规模的分布式数据处理。与传统的分布式程序设计相比,MapReduce 封装了并行处理、容错处理、本地化计算、负载均衡等细节,具有简单而强大的接口。正是由于 MapReduce 具有函数式编程语言和矢量编程语言的共性,使得这种编程模式特别适合于非结构化和结构化的海量数据的搜索、挖掘、分析等应用。
Bigtable
BigTable 是 Google 设计的分布式数据存储系统,是用来处理海量数据的一种非关系型数据库。BigTable 是一个稀疏的、分布式的、持久化存储的多维度排序的映射表。
BigTable 的设计目的是能够可靠地处理 PB 级别的数据,并且能够部署到上千台机器上。
BigTable 开发团队确定了 BigTable 设计所需达到的几个基本目标:
- 广泛的适用性
需要满足一系列 Google 产品而并非特定产品的存储要求。 - 很强的可扩展性
根据需要随时可以加入或撤销服务器。 - 高可用性
确保几乎所有的情况下系统都可用。对于客户来说,有时候即使短暂的服务中断也是不能忍受的。 简单性
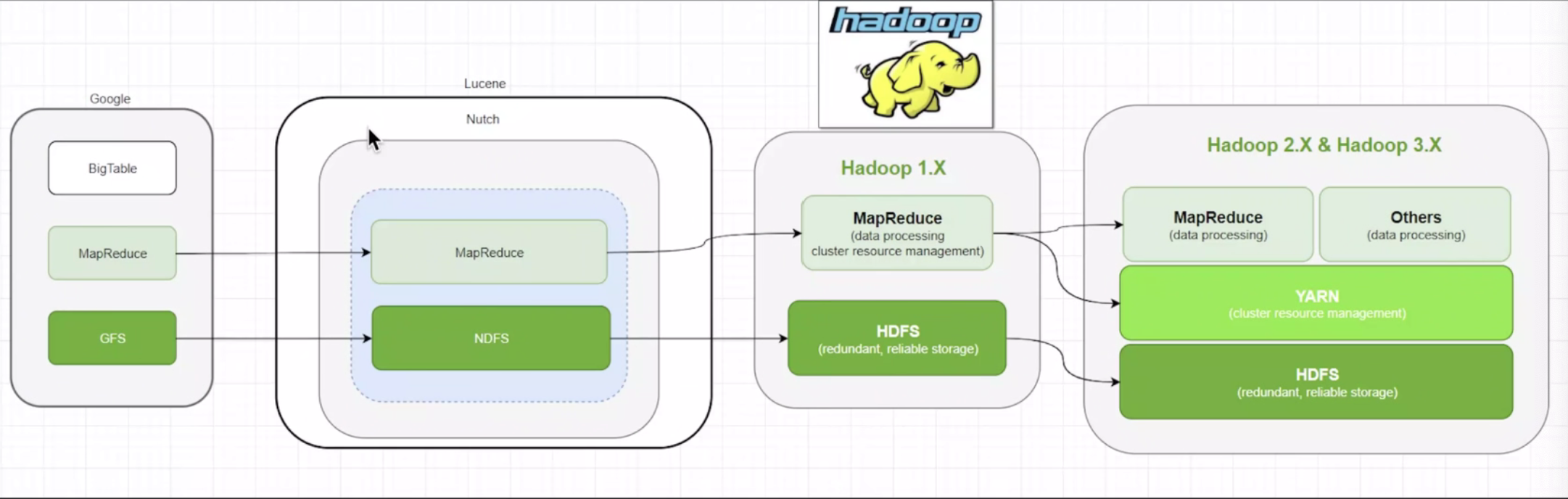
底层系统的简单性既可以减少系统出错的概率,也为上层应用的开发带来了便利。Hadoop版本介绍及选择
2006年3月,Map/reduce和Nutch Distributed File System(NDFS)分别被纳入Hadoop项目中。
- Cloudera公司在2008年开始提供基于Hadoop的软件服务。
- 2016年10月Hadoop-2.6.5
- 2017年12月Hadoop-3.0.0
- 最新稳定版本Hadoop-3.3.1
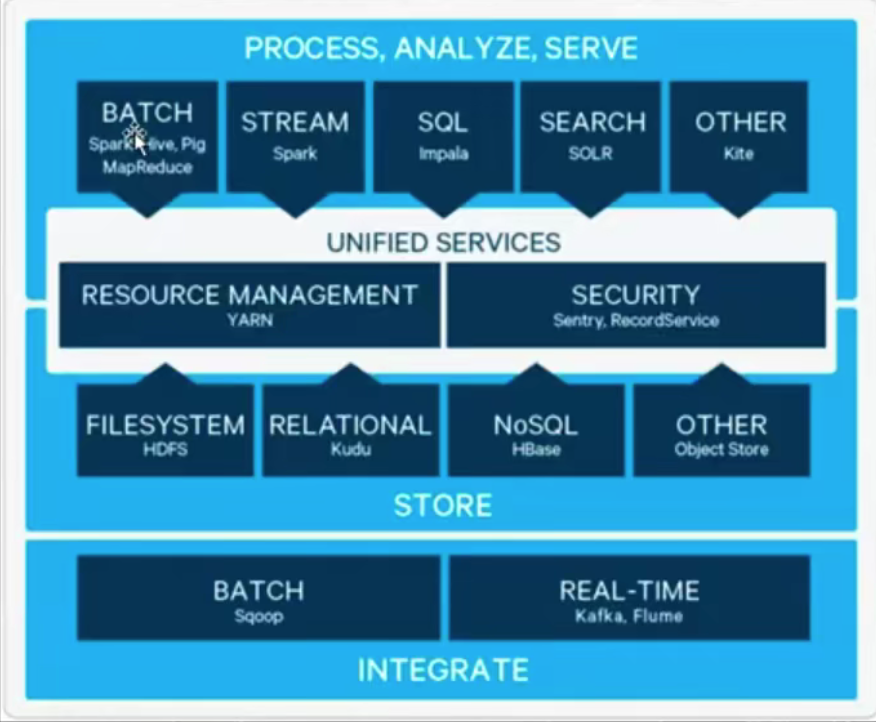
Hadoop组成模块
官网:https://hadoop.apache.org/#
Modules
可以编写SQL语句来查询HDFS上的结构化数据,SQL会被转化成MapReduce执行
- HBase
HDFS上的数据量非常庞大,但访问和查询速度比较慢,HBase可以提供给用户毫秒级的实时查询服务,是一个基于HDFS的分布式数据库
- Spark
一款大数据计算框架,其初衷是改良Hadoop MapReduce的编程模型和执行速度
- Flink
新一代计算框架,它是一个支持在有界和无界数据流上做有状态计算的大数据引擎。它以事件为单位,并且支持SQL、State、WaterMark等特性。它支持”exactly once”,即事件投递保证只有一次,不多也不少,这样数据的准确性能得到提升。比起Storm,它的吞吐量更高,延迟更低,准确性能得到保障。
- Zookeeper
Extend projects
- 存储:HDFS、Kafka
- 计算:MapReduce、Spark、Flink
- 查询:Nosql解决随机查询(HBase、Cassandra)、Olap解决关联查询(Kylin、Impla)
挖掘:机器学习和深度学习(TensorFlow、caffe、mahout)
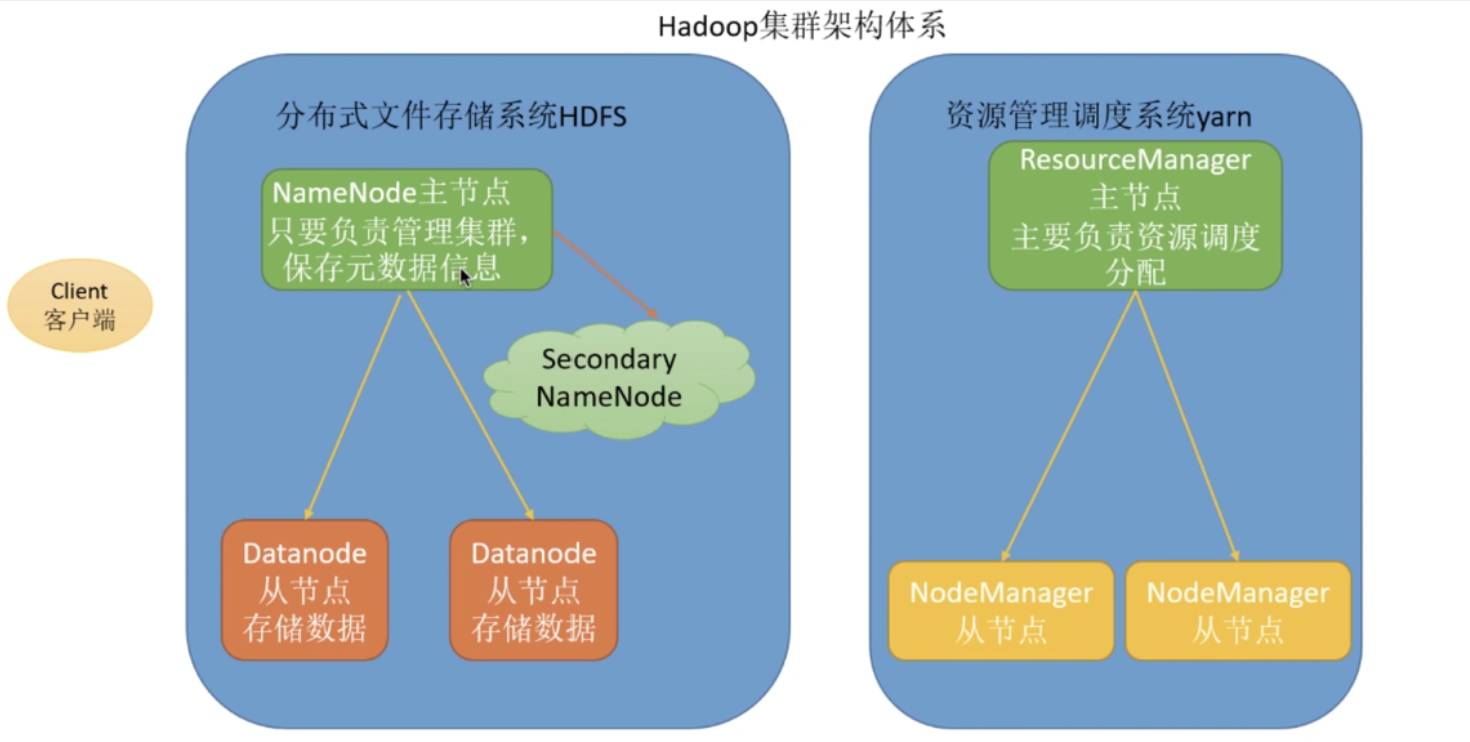
Hadoop架构
基础生态
大数据技术框架
存储引擎
分布式文件系统:HDFS(Block、Replication)
- NoSQL数据库:HBase(Table、Region)
- 分布式消息队列:Kafka(Topic、Partition)
- 分布式搜索引擎:ElasticSearch(Index、Shard)
-
分析引擎
并行计算引擎:MapReduce(分而治之)
- 数据仓库工具:Hive(提供SQL数据分析,转换MR,读取HDFS,运行在YARN上)
- 内存分析引擎:Impala
- 分布式OALP分析框架:Kylin、Druid
- Spark统一分析引擎:批处理,离线分析
-
辅助框架
分布式集群资源管理:YARN(MapReduce、Spark、Flink)
- 数据转换:SQOOP(DataX、Kettle)
- 日志采集:Flum、LogStash、FileBeats
Cloudera公司

若有收获,就点个赞吧
0 人点赞
