HDFS
主要是hdfs-site.xml参数调优
- dfs.datanode.handler.count = 10 (默认线程数)
设置原则=集群大小的自然对数 X 20,即20 logN,N为集群大小 - dfs.namenode.edits.dir和dfs.namenode.name.dir尽量分开,达到最大写入延迟
-
YARN
主要是yarn-site.xml参数调优
yarn.nodemanager.resource.memory-mb = 8192MB 节点物理内存
- yarn.scheduler.maximum-allocation-mb = 8192MB 单个任务可申请的最对物理内存
Hadoop宕机
控制Yarn同时运行任务数和每个任务最大内存
写入文件过量造成NameNode宕机。name调高kafka的存储大小,控制kafka到HDFS写入速度,高峰期用kafka进行缓存,高峰期过去数据同步会自动跟上。MapReduce
现在企业几乎不使用MR,推荐Spark和Flink。它主要的瓶颈在于两点:
计算机性能
I/O操作优化
数据倾斜
- map和reduce数配置不合理
- map运行时间太长,导致reduce等待过久
- 小文件过多
- 大量的不可分割超大文件
- spill次数过多
-
解决方案
优化主要从数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜和常用的调优参数来解决。
数据输入
合并小文件,否则导致任务多,初始化多
可采用CombineTextInputFormat来作为输入,解决输入端大量小文件场景
Map阶段
减少spill溢写次数
- 减少merge合并次数
-
Reduce阶段
设置合理的map、reduce个数
- 设置map、reduce共存
- 规避使用reduce
-
IO传输
数据压缩(减少网络I/O的数据库,安装Snappy和lzo压缩编码器)
-
数据倾斜
抽样和范围分区
- 自定义分区
- Combine聚合精简数据
- Map join,尽量避免Reduce join
常用的调优参数
mapred-site.xml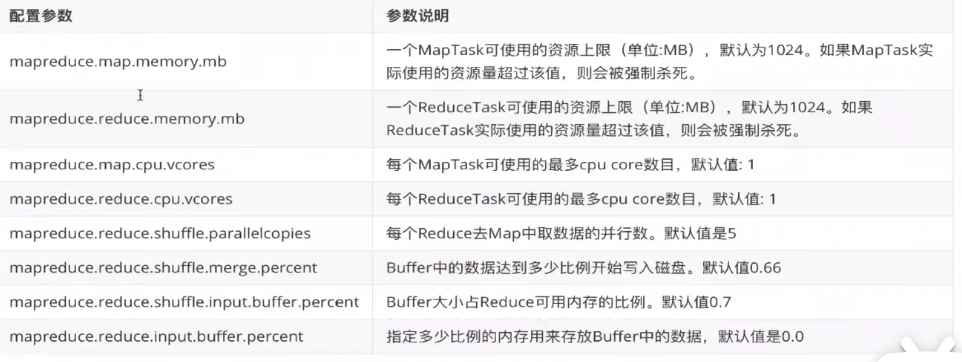

yarn-site.xml

若有收获,就点个赞吧
0 人点赞
