Spark Application
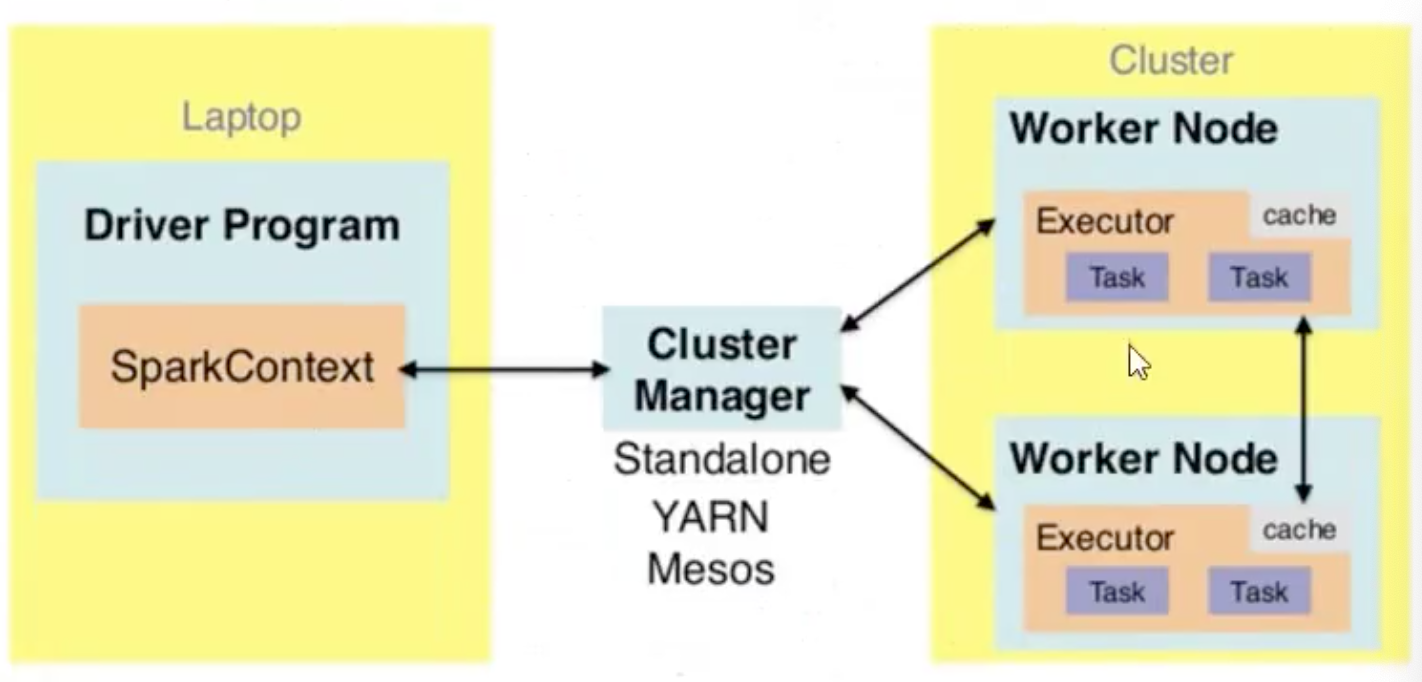
Spark Application在Standalone集群运行时,有2部分组成:
- Driver Program(AppMaster)
- Executors(MapTask和ReduceTask)

应用运行模式
- Standalone
- YARN(推荐)
- Mesos(少用)
应用提交
spark-submit —master options —class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.2.jar 10
options 参数:
- 本地方式:local[2]
- 集群方式:spark://master01:7077,master02:7077
- YARN集群方式:yarn
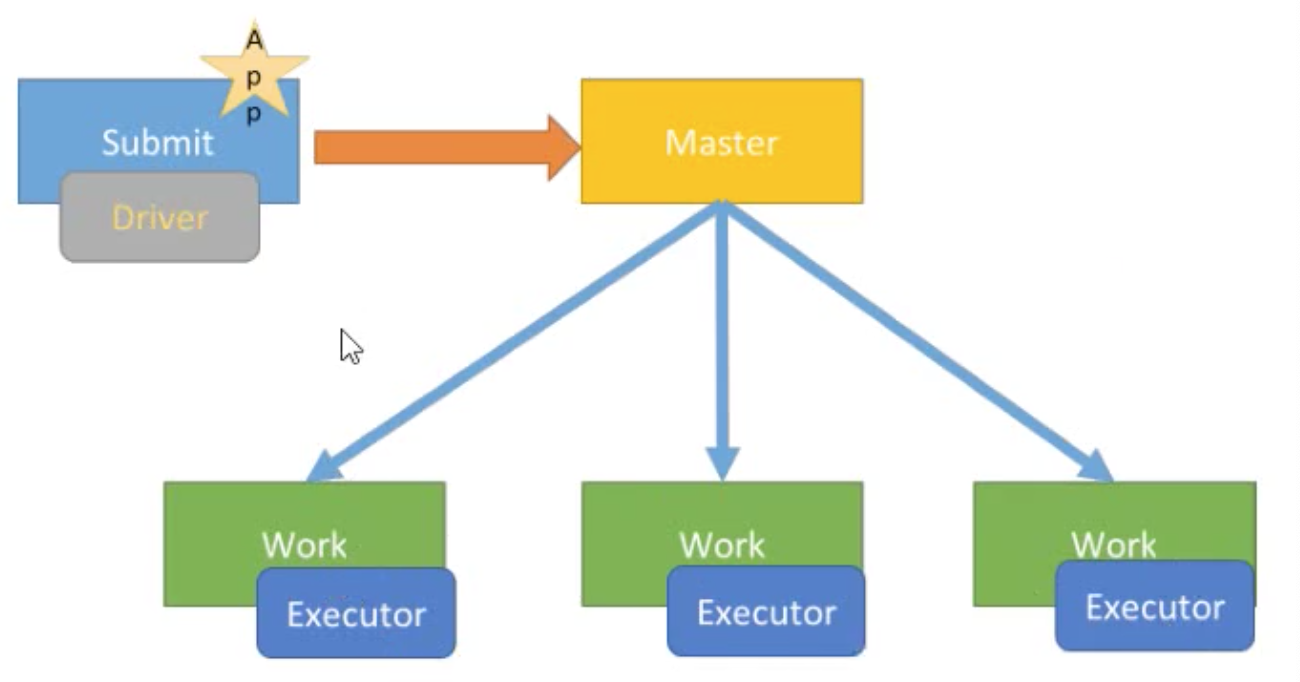
应用部署模式
spark-submit提交应用运行时,指定参数:—deploy-mode,表示Driver Program运行位置client模式(默认)
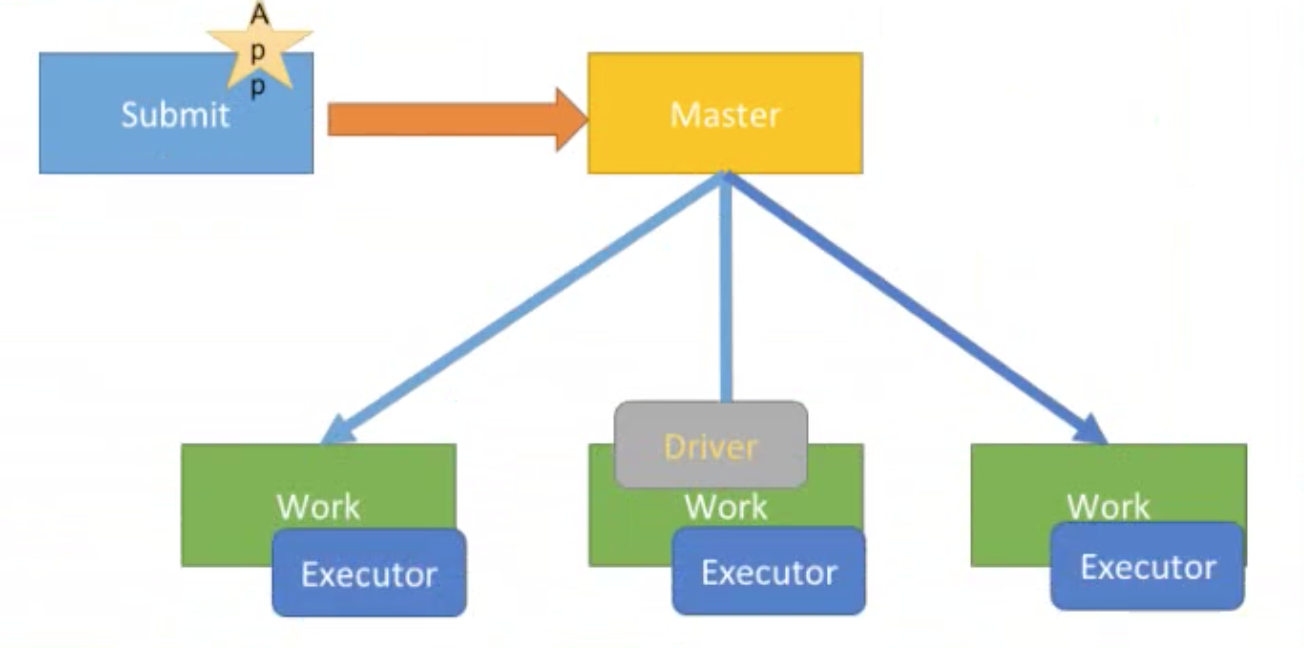
cluster模式(正式环境【推荐】)
Spark on YARN
client模式
Driver与AppMaster各司其职,AppMaster负责资源申请Executors,Driver负责Job调度
cluster模式
Driver与AppMaster合为一体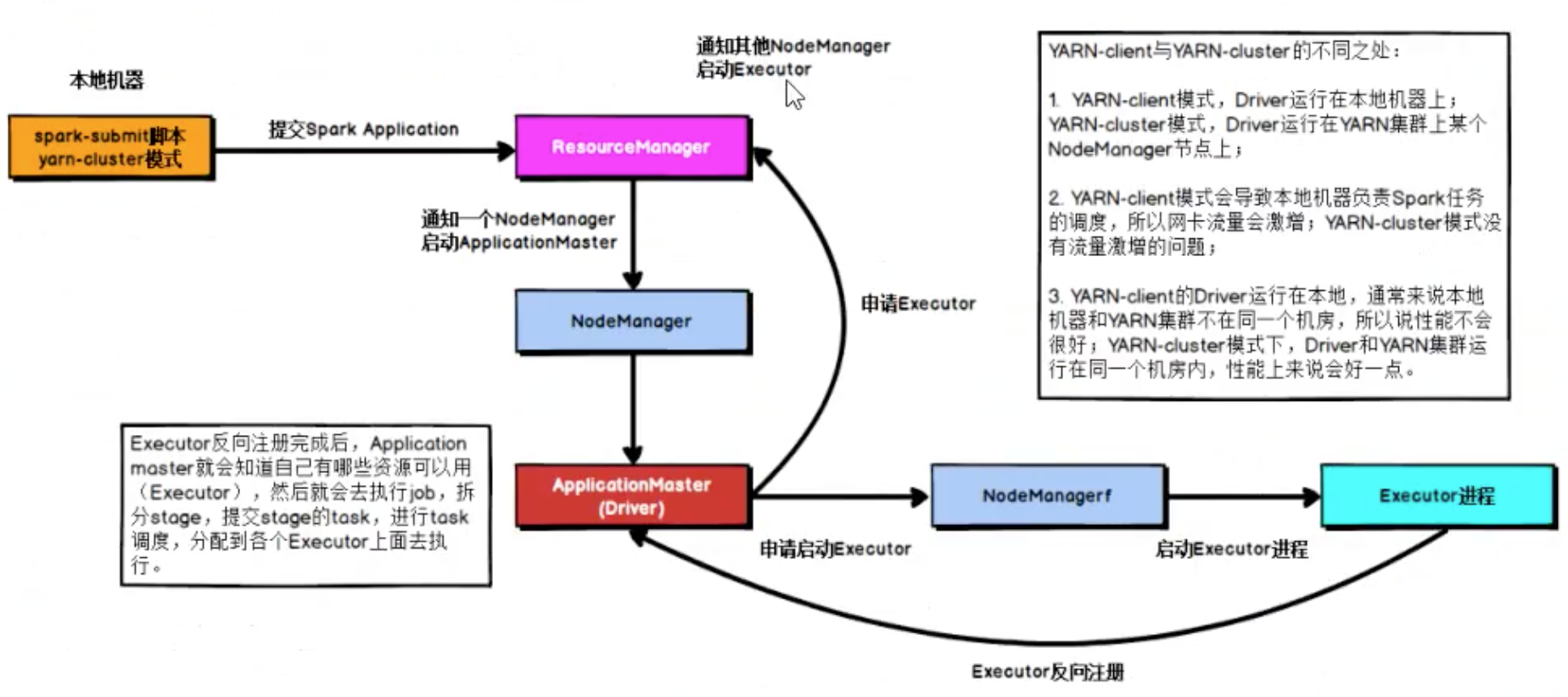
RDD
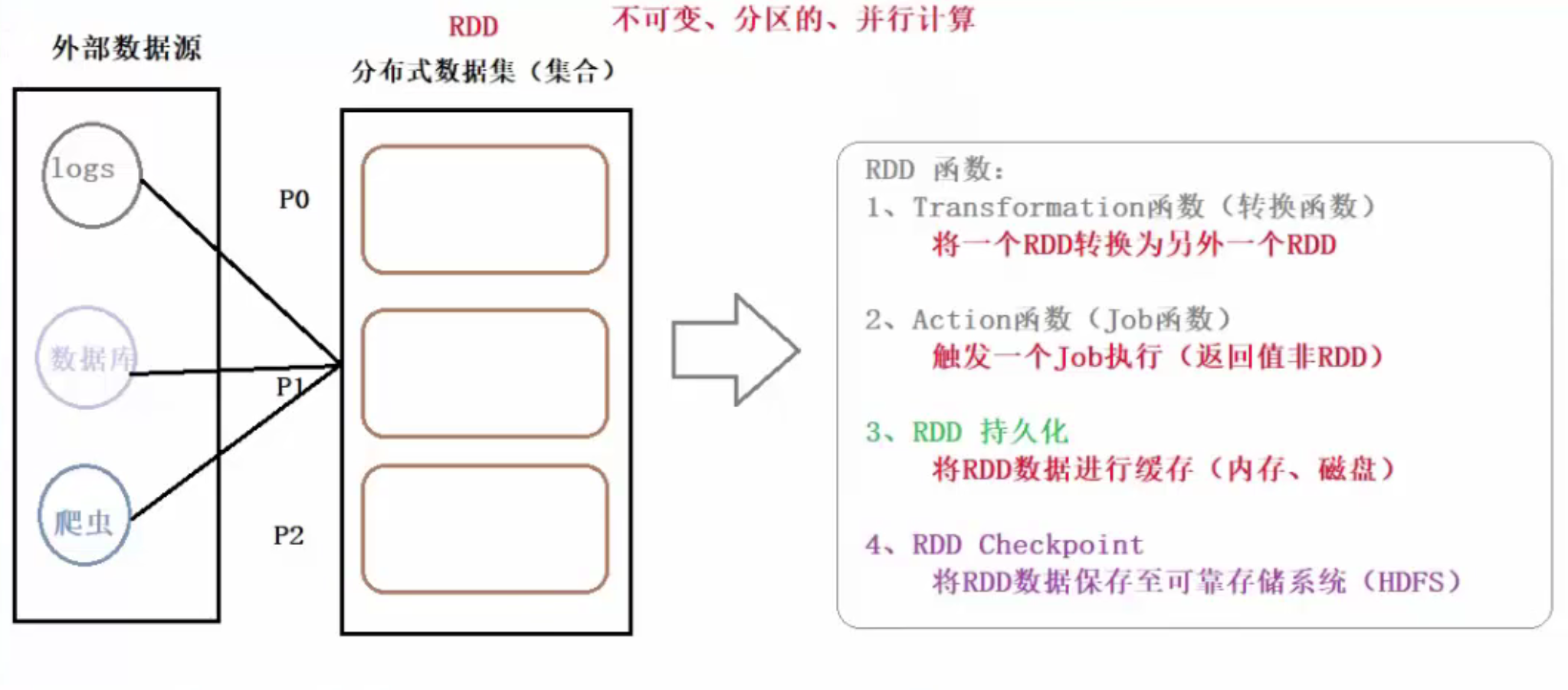
RDD(Resilent Distributed Datasets)俗称弹性分布式数据集,是 Spark 底层的分布式存储的数据结构。可以说是 Spark 的核心, Spark API 的所有操作都是基于 RDD 的。数据不只存储在一台机器上,而是分布在多台机器上,实现数据计算的并行化。弹性表明数据丢失时,可以进行重建。在Spark 1.5版以后,新增了数据结构 Spark-DataFrame,仿造的 R 和 python 的类 SQL 结构-DataFrame,底层为 RDD,能够让数据从业人员更好的操作 RDD。
三个要点:
RDD设计思想
在Spark 的设计思想中,为了减少网络及磁盘 IO 开销,需要设计出一种新的容错方式,于是才诞生了新的数据结构 RDD。RDD 是一种只读的数据块。可以从外部数据转换而来,你可以对RDD 进行函数操作(Operation),包括 Transformation 和 Action。在这里只读表示当你对一个 RDD 进行了操作,那么结果将会是一个新的 RDD,这种情况放在代码里,假设变换前后都是使用同一个变量表示这一 RDD,RDD 里面的数据并不是真实的数据,而是一些元数据信息,记录了该 RDD 是通过哪些 Transformation 得到的,在计算机中使用 lineage 来表示这种血缘结构,lineage 形成一个有向无环图 DAG,整个计算过程中,将不需要将中间结果落地到 HDFS 进行容错,加入某个节点出错,则只需要通过 lineage 关系重新计算即可。RDD5个特性
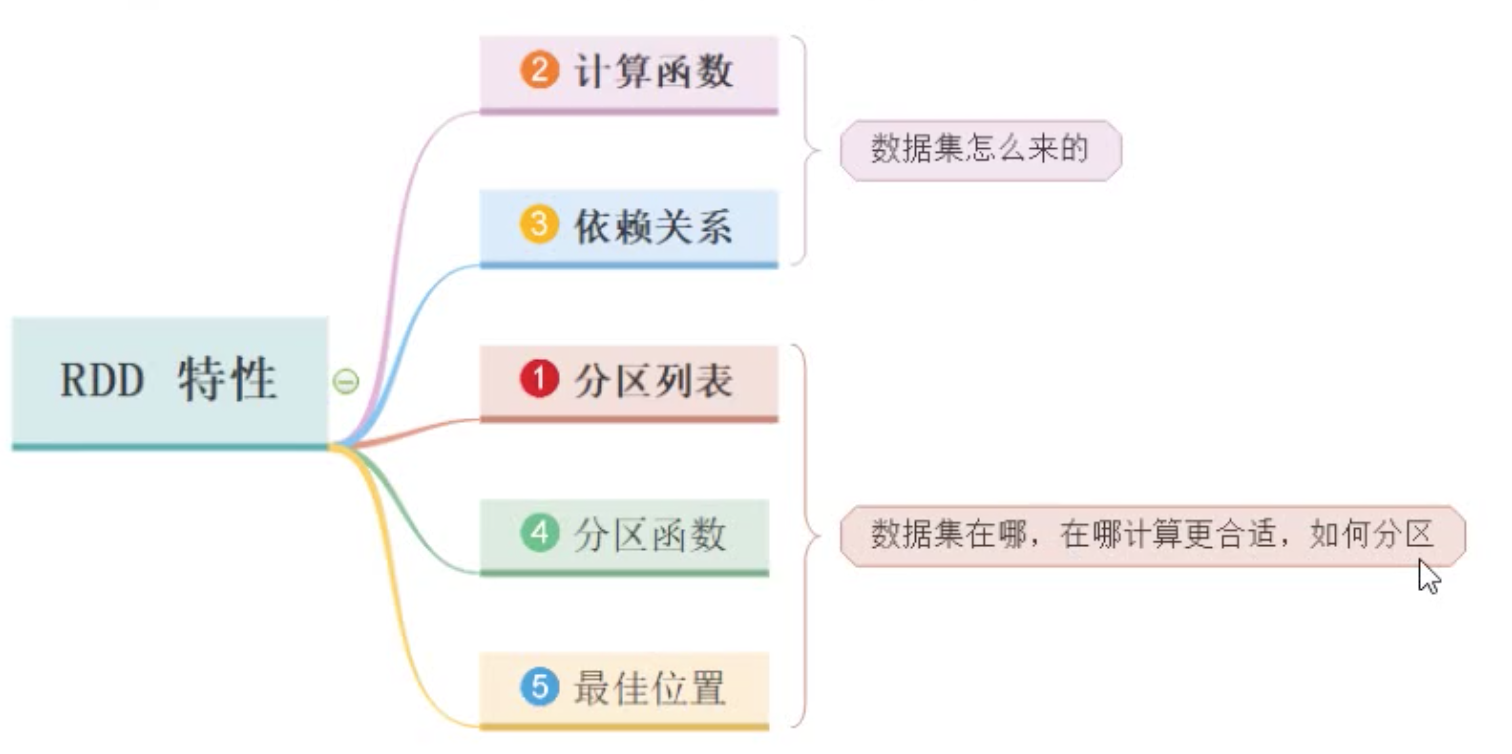
- 它是在集群节点上的不可变的、已分区的集合对象
- 通过并行转换的方式来创建(如 Map、 filter、join 等)
- 失败自动重建
- 可以控制存储级别(内存、磁盘等)来进行重用
- 必须是可序列化的
- 是静态类型的(只读)
RDD创建
- 并行化(Parallelizing)一个已经存在与驱动程序(Driver Program)中的集合,如set、list;
读取外部存储系统上的一个数据集,比如HDFS、Hive、HBase,或者任何提供了Hadoop InputFormat的数据源。也可以从本地读取 txt、csv 等数据集。
RDD函数(operation)
主要分为2种类型 Transformation 和 Action。

Transformation 操作不是马上提交 Spark 集群执行的,Spark 在遇到Transformation操作时只会记录需要这样的操作,并不会去执行,需要等到有Action操作的时候才会真正启动计算过程进行计算。
针对每个 Action,Spark 会生成一个Job,从数据的创建开始,经过 Transformation,结尾是 Action 操作。这些操作对应形成一个有向无环图(DAG),形成 DAG 的先决条件是最后的函数操作是一个Action。常用函数(重点)
分区操作函数(创建对象)
mapPartitions、foreachPartition- 重分区函数(调整分区个数)
repartition(增加分区数量,产生shuffle)、coalesce(减少分区数目) - 聚合函数
Scala聚合函数:reduce【reduce((tmp,item)=>tmp+item)】、fold
RDD聚合函数:reduce/fold(分区内聚合、分区间聚合)、aggregate
PairRDDFunctions聚合函数:groupByKey、reduceByKey/foldByKey、aggregateByKey、combineByKey(最底层聚合函数) - 关联函数
- 缓存函数(持久化函数)
将一个RDD数据进行缓存,可以是内存(Executor内存)、磁盘、系统内存(OFF_HEAP)
释放内存:unpersist
RDD checkpoint
Checkpoint的产生就是为了更加可好的数据持久化,在Checkpoint的时候一般将数据放在HDFS上,这是借助HDFS天生的高容错、高可靠来实现数据最大程度的安全,实现RDD的容错和高可用。
RDD持久化和checkpoint的区别: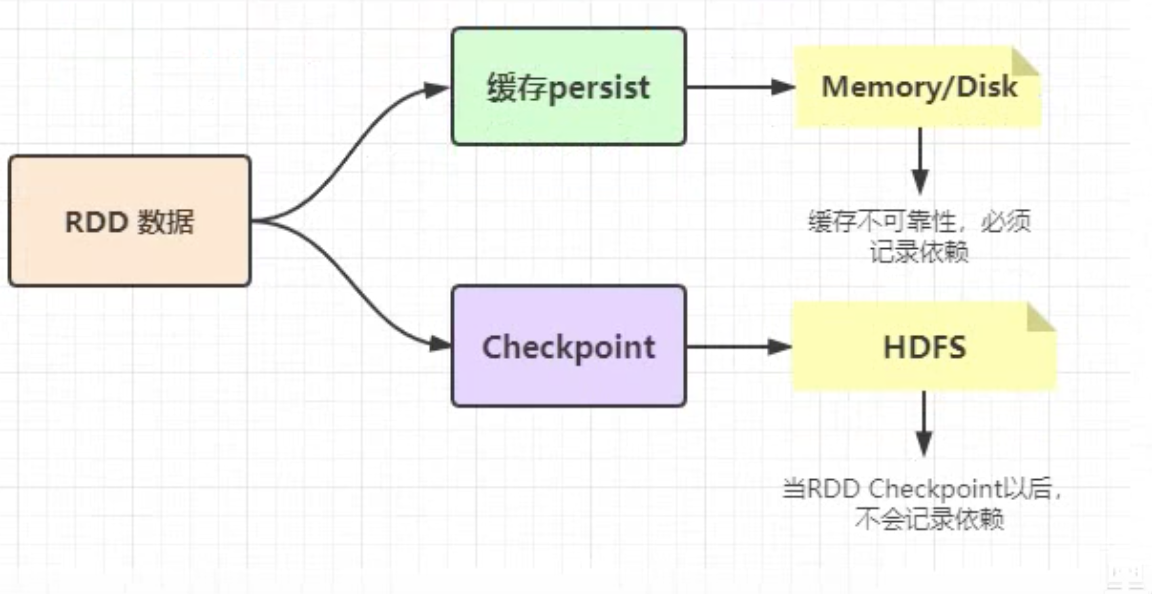
checkpoint是懒加载模式,一般需要借助count函数触发
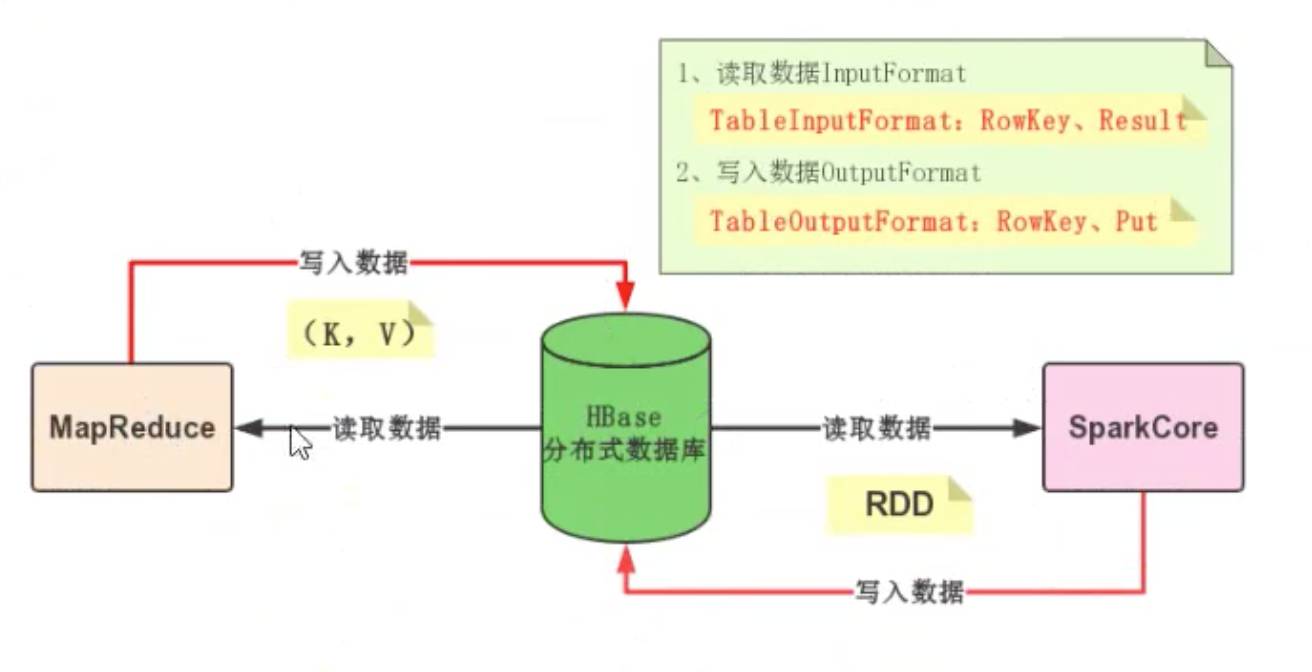
外部数据源
操作方式:
常见的外部数据源扩展:
- HBase数据源
- MySQL数据源
共享变量
广播变量(Broadcast Variables)和累加器(Accumulators)
广播变量Broadcast
类似于MapReduce中的Map DistributedCache,将某个变量数据发送给所有的Executor,变量值不可变
累加器Accumulator
类似于MapReduce中的计数器Counters,即计数功能
Spark内核
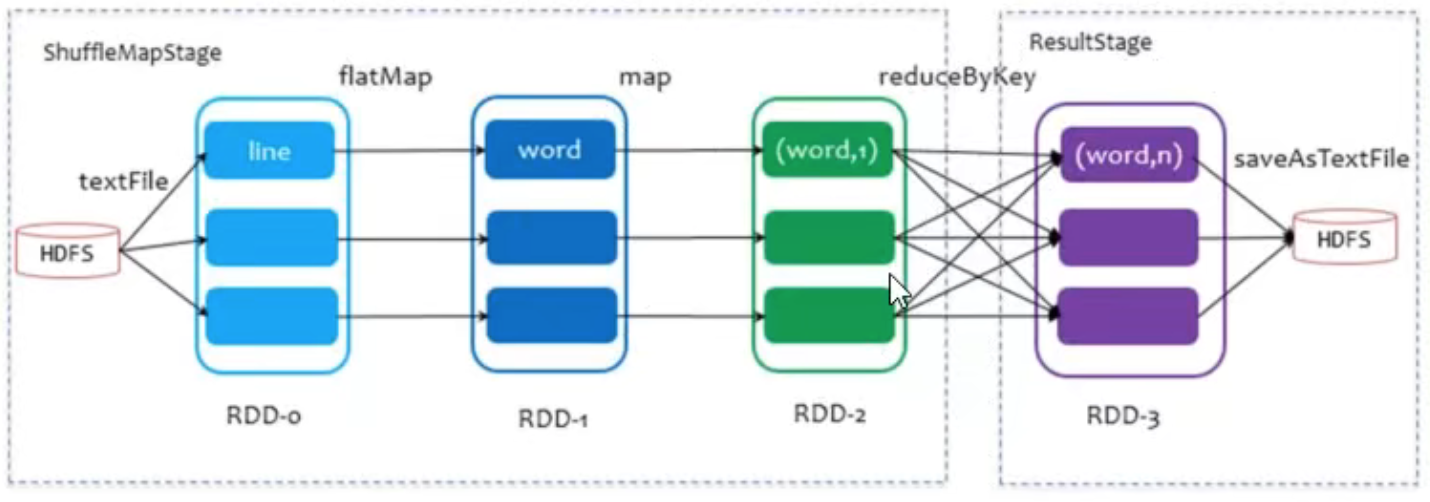
shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤。
RDD依赖
RDD 的 Transformation 函数中,分为:
- 窄依赖(narrow dependency)
窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果。 - 宽依赖(wide dependency)
宽依赖会发生 shuffle 操作。宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片。
Shuffle和Stage流程
看如下示例:
// Map: "cat" -> c, catval rdd1 = rdd.Map(x => (x.charAt(0), x))// groupby same key and countval rdd2 = rdd1.groupBy(x => x._1).Map(x => (x._1, x._2.toList.length))
第一个 Map 操作将 RDD 里的各个元素进行映射,RDD 的各个数据元素之间不存在依赖,可以在集群的各个内存中独立计算,也就是并行化。
第二个 groupby 之后的 Map 操作,为了计算相同 key 下的元素个数,需要把相同 key 的元素聚集到同一个 partition 下,所以造成了数据在内存中的重新分布,即 shuffle 操作。
shuffle 操作是 spark 中最耗时的操作,应尽量避免不必要的 shuffle。
宽依赖主要有两个过程:shuffle write 和 shuffle fetch。
类似 Hadoop 的 Map 和 Reduce 阶段。shuffle write 将 ShuffleMapTask 任务产生的中间结果缓存到内存中, shuffle fetch 获得 ShuffleMapTask 缓存的中间结果进行 ShuffleReduceTask 计算,这个过程容易造成OutOfMemory。
shuffle 过程内存分配使用 ShuffleMemoryManager 类管理,会针对每个 Task 分配内存,Task 任务完成后通过 Executor 释放空间。这里可以把 Task 理解成不同 key 的数据对应一个 Task。 早期的内存分配机制使用公平分配,即不同 Task 分配的内存是一样的,但是这样容易造成内存需求过多的 Task 的 OutOfMemory, 从而造成多余的 磁盘 IO 过程,影响整体的效率。(某一个 key 下的数据明显偏多,但因为大家内存都一样,这一个 key 的数据就容易 OutOfMemory)。
1.5版以后Task 共用一个内存池,内存池的大小默认为 JVM 最大运行时内存容量的16%,分配机制如下:假如有 N 个 Task,ShuffleMemoryManager 保证每个 Task 溢出之前至少可以申请到1/2N 内存,且至多申请到1/N,N 为当前活动的 shuffle Task 数,因为N 是一直变化的,所以 manager 会一直追踪 Task 数的变化,重新计算队列中的1/N 和1/2N。但是这样仍然容易造成内存需要多的 Task 任务溢出,所以最近有很多相关的研究是针对 shuffle 过程内存优化的。
如下 DAG 流程图中,分别读取数据,经过处理后 join 2个 RDD 得到结果。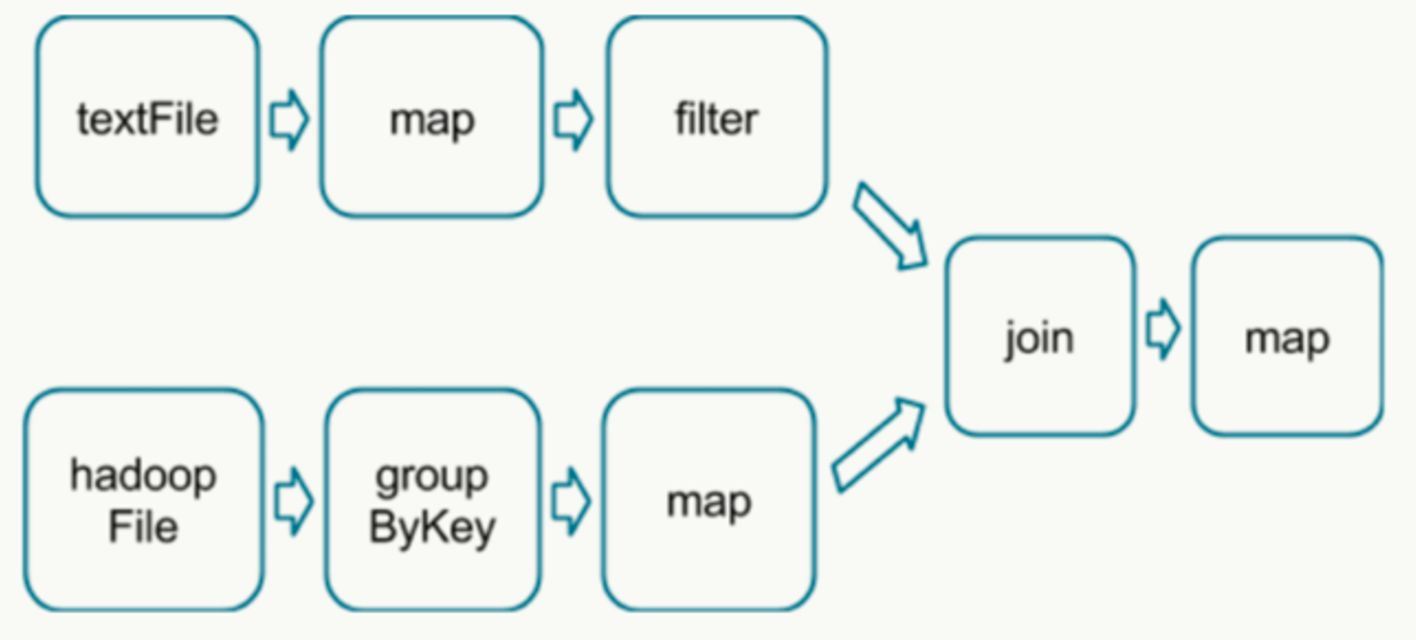
在这个图中,根据是否发生 shuffle 操作能够将其分成如下的 stage 类型: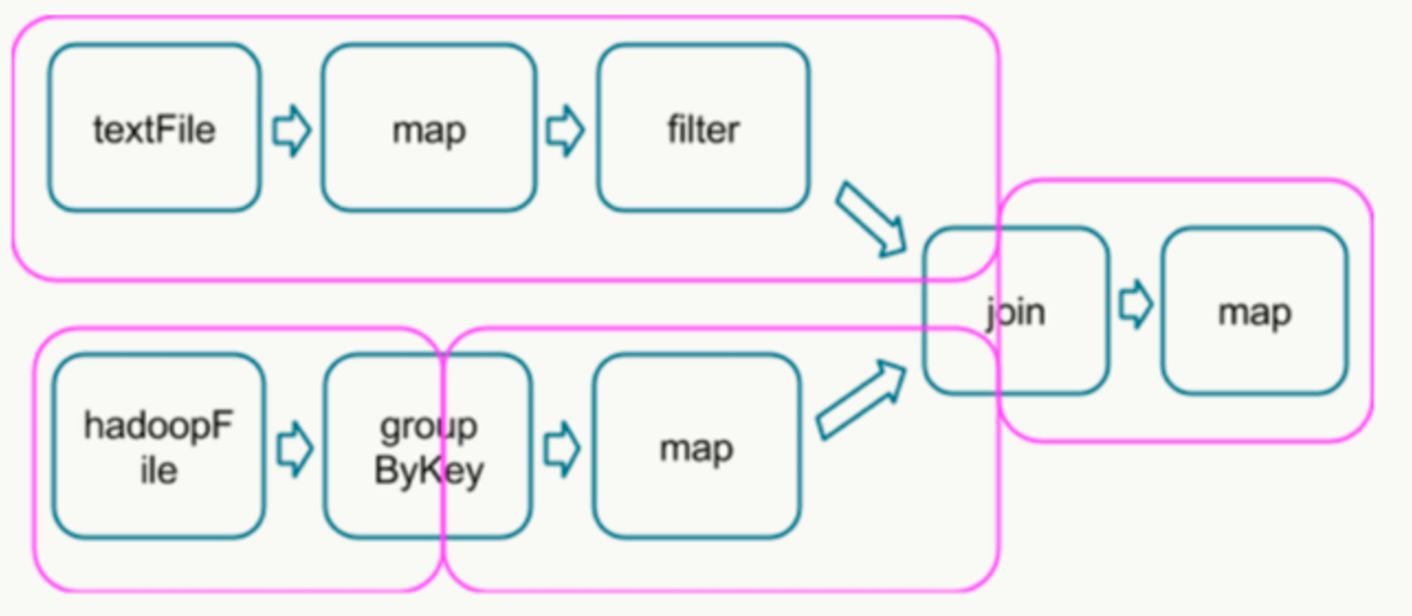
join 需要针对同一个 key 合并,所以需要 shuffle。运行到每个 stage 的边界时,数据在父 stage 中按照 Task 写到磁盘上,而在子 stage 中通过网络按照 Task 去读取数据。
这些操作会导致很重的网络以及磁盘的I/O,所以 stage 的边界是非常占资源的,在编写 Spark 程序的时候需要尽量避免的 。
父 stage 中 partition 个数与子 stage 的 partition 个数可能不同,所以那些产生 stage 边界的 Transformation 常常需要接受一个 numPartition 的参数来觉得子 stage 中的数据将被切分为多少个 partition。
PS:shuffle 操作的时候可以用 combiner 压缩数据,减少 IO 的消耗
Job调度流程
当创建SparkContext对象时,就会创建DAGScheduler和TaskSCheduler对象。
- DAGScheduler
将Job对应的DAG图划分为Stage,划分的依据:RDD之间产生Shuffle(宽依赖) TaskSCheduler
对每个Stage中Task调度执行,运行在Executor中
每个Task以线程Thread方式运行,需要1Core CPU,处理1个分区数据,采用pipeline管道计算模式资源设置
设置Task数量
官方推荐,Task数量设置成Application总CPU Core数量的2-3倍(100个cpu core,设置task数量为200-300)- 设置Application并行度
参数spark.default.parallelism默认是没有设置的,设置值之后在shuffle过程中才起作用

若有收获,就点个赞吧
0 人点赞
