概述
官网地址:https://zookeeper.apache.org/
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责 存储和管理数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper特点
- Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
-
Zookeeper数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
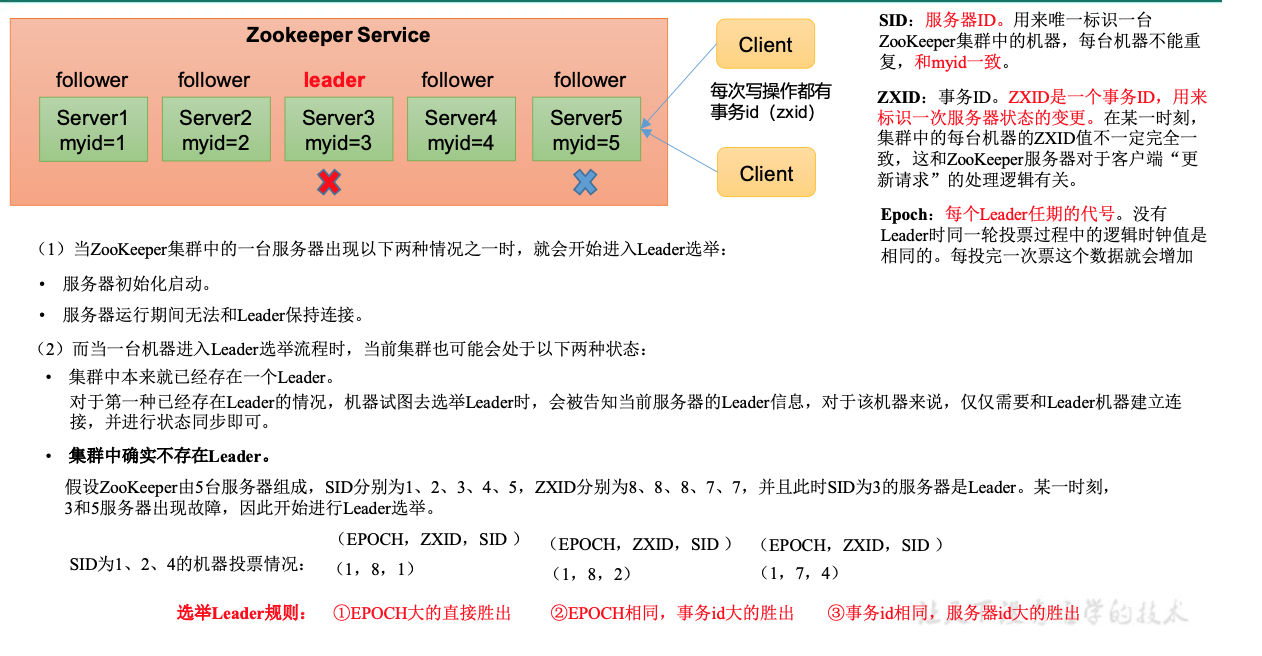
选举机制
选举Leader规则: 1、EPOCH大的直接胜出 2、EPOCH相同,事务id大的胜出 3、事务id相同,服务器id大的胜出
第一次启动
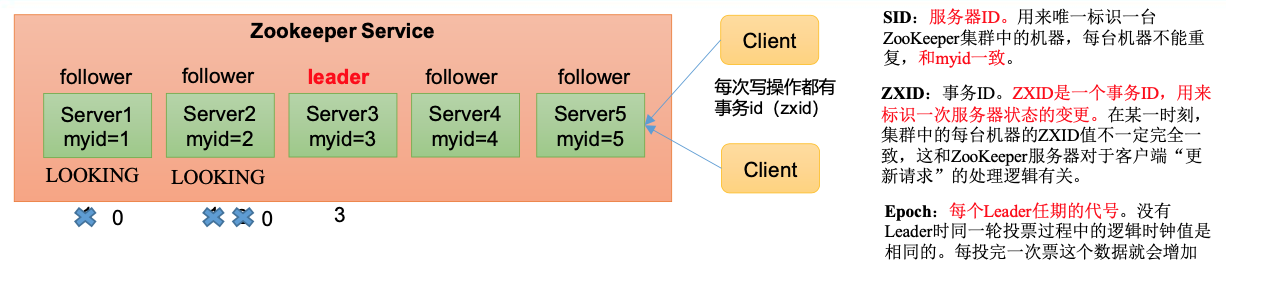
服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持LOOKING
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING
- 服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING
-
非第一次启动
应用场景
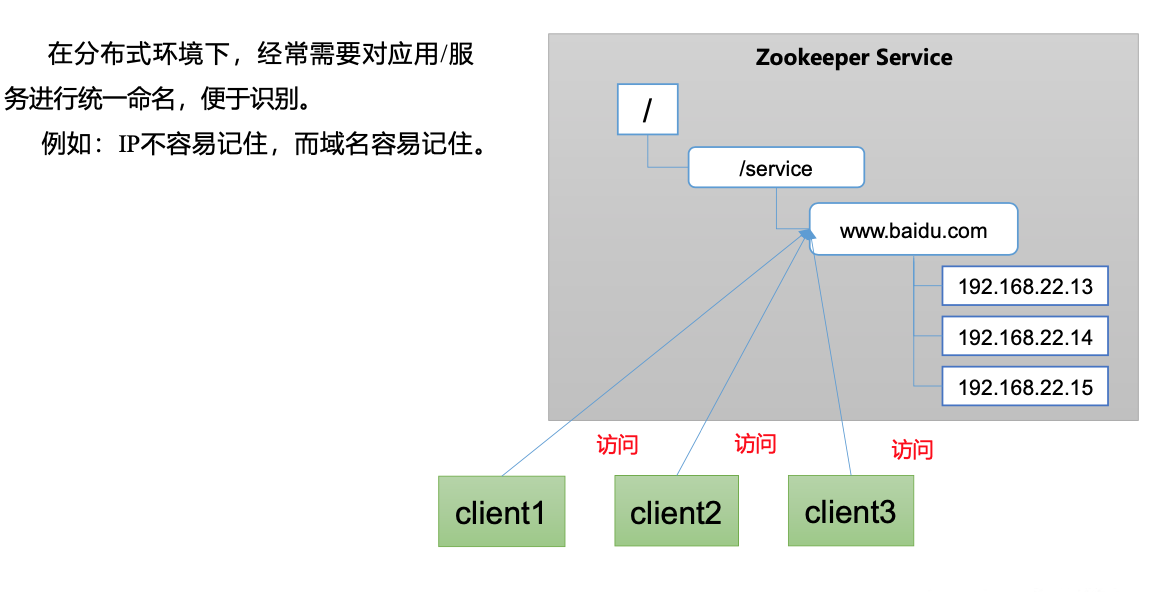
统一命名服务
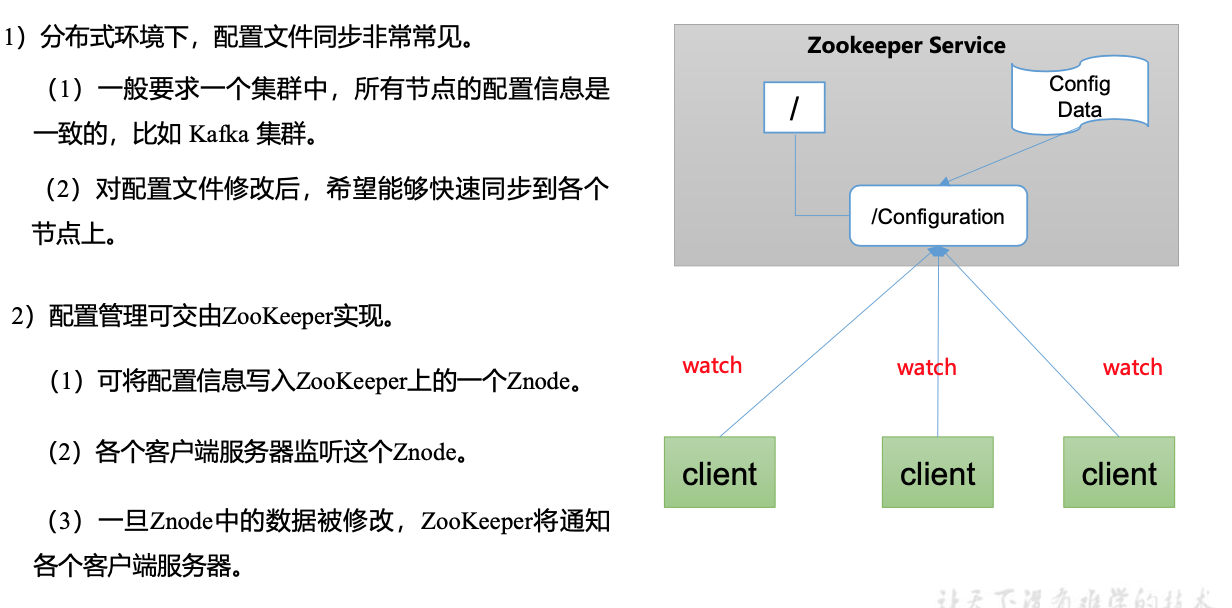
- 统一配置管理
- 统一集群管理
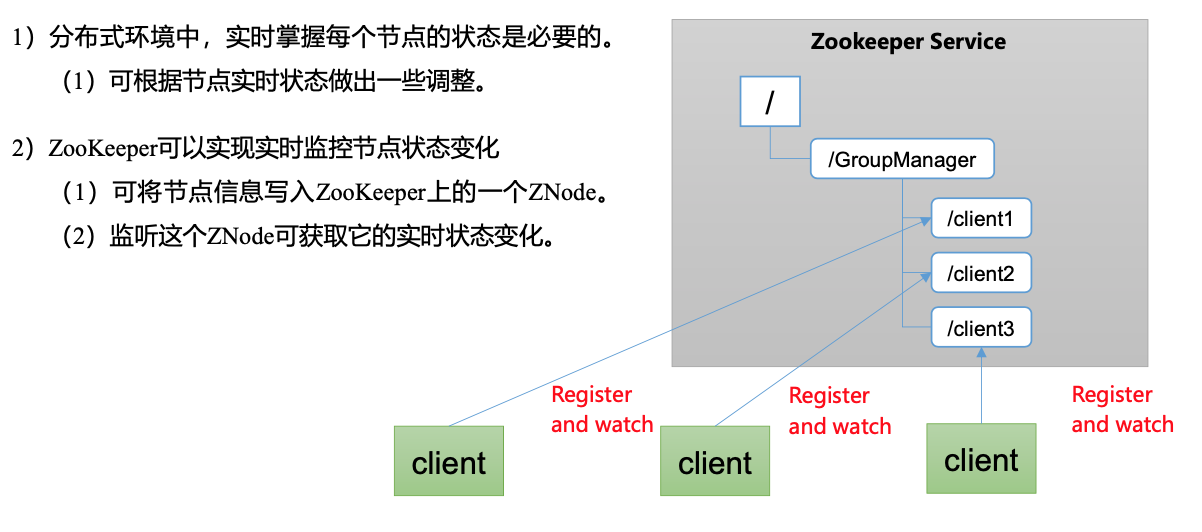
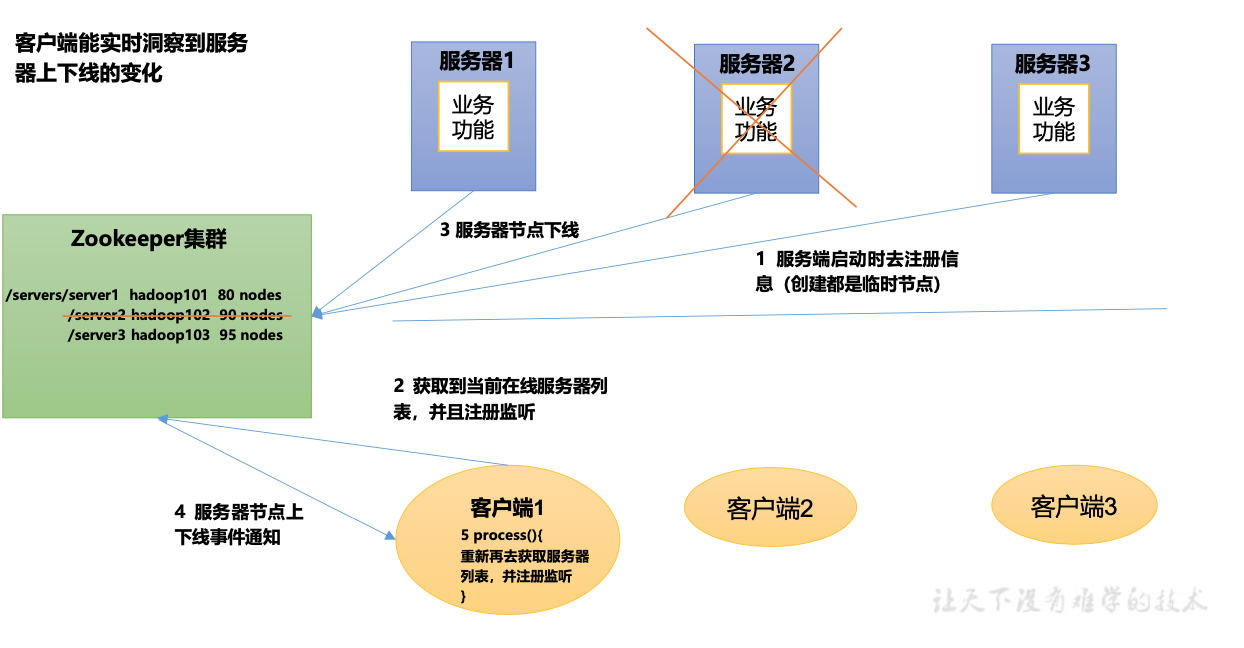
- 服务器节点动态上下线
-
zookeeper算法
拜占庭将军问题
拜占庭将军问题是一个协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将 军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻 行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能 获得胜利。
Paxos算法
Paxos算法解决的问题?
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。
Paxos算法解决的问题:就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。Paxos算法描述
在一个Paxos系统中,首先将所有节点划分为Proposer(提议者),Acceptor(接受者),和
Learner(学习者)。(注意:每个节点都可以身兼数职)。
一个完整的Paxos算法流程分为三个阶段: Prepare准备阶段
Proposer向多个Acceptor发出Propose请求Promise(承诺)
Acceptor针对收到的Propose请求进行Promise(承诺)- Accept接受阶段
Proposer收到多数Acceptor承诺的Promise后,向Acceptor发出Propose请求
Acceptor针对收到的Propose请求进行Accept处理 Learn学习阶段
Proposer将形成的决议发送给所有LearnersPaxos算法流程

Prepare:Proposer生成全局唯一且递增的Proposal ID,向所有Acceptor发送Propose请求,这里无需携带提案内容,只携 带Proposal ID即可。
- Promise: Acceptor收到Propose请求后,做出“两个承诺,一个应答”。
➢ 不再接受ProposalID小于等于(注意:这里是<=)当前请求的Propose请求。
➢ 不再接受Proposal ID小于(注意:这里是< )当前请求的Accept请求。
➢ 不违背以前做出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的 Value和Proposal ID,没有则返回空值。
- Propose:Proposer收到多数Acceptor的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptor发送 Propose请求
- Accept:Acceptor收到Propose请求后,在不违背自己之前做出的承诺下,接受并持久化当前Proposal ID和提案Value。
Learn:Proposer收到多数Acceptor的Accept后,决议形成,将形成的决议发送给所有Learner。
ZAB协议
什么是ZAB协议?
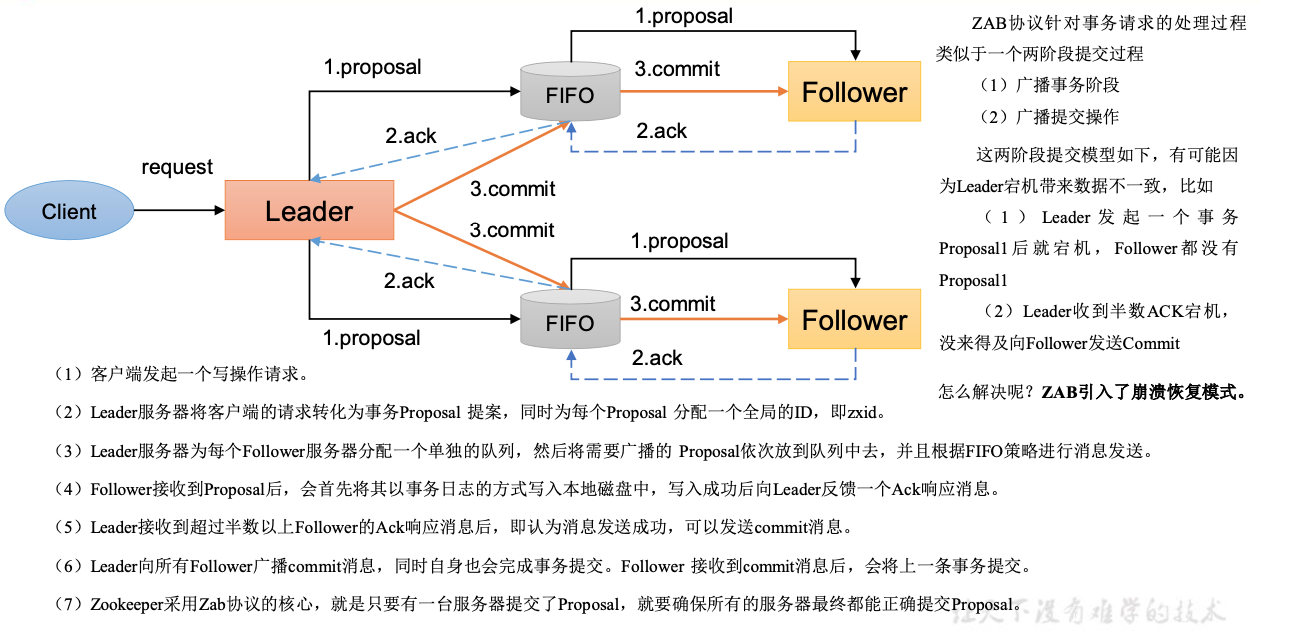
Zab 借鉴了 Paxos 算法,是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。基 于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后 Leader 客户端将数据同步到其他 Follower 节点。
即 Zookeeper 只有一个 Leader 可以发起提案。ZAB协议内容
消息广播
崩溃恢复
一旦Leader服务器出现崩溃或者由于网络原因导致Leader服务器失去了与过半 Follower的联系,那么就会进入崩溃恢复模式。
Zab协议崩溃恢复要求满足以下两个要求:确保已经被Leader提交的提案Proposal,必须最终被所有的Follower服务器提交。 (已经产生的提案,Follower必须执行)
- 确保丢弃已经被Leader提出的,但是没有被提交的Proposal。(丢弃胎死腹中的提案)
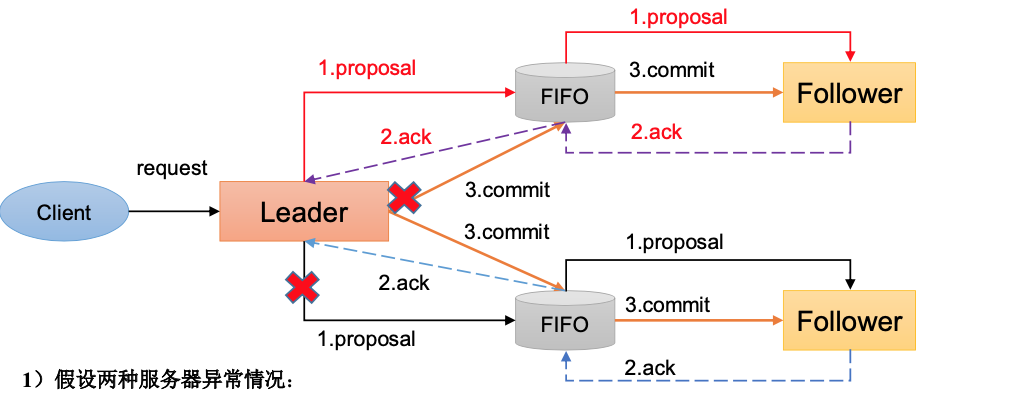
崩溃恢复主要包括两部分:Leader选举和数据恢复。
Zab协议需要保证选举出来的Leader需要满足以下条件:
- 新选举出来的Leader不能包含未提交的Proposal。即新Leader必须都是已经提交了Proposal的Follower服务器节点。
- 新选举的Leader节点中含有最大的zxid。这样做的好处是可以避免Leader服务器检查Proposal的提交和丢弃工作。
Zab如何数据同步:
- 完成Leader选举后,在正式开始工作之前(接收事务请求,然后提出新的Proposal),Leader服务器会首先确认事务日志中的所有的Proposal 是否已经被集群中过半的服务器Commit。
Leader服务器需要确保所有的Follower服务器能够接收到每一条事务的Proposal,并且能将所有已经提交的事务Proposal 应用到内存数据中。等到Follower将所有尚未同步的事务Proposal都从Leader服务器上同步过,并且应用到内存数据中以后, Leader才会把该Follower加入到真正可用的Follower列表中。
CAP
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种:
一致性(C:Consistency)
在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。- 可用性(A:Available)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。 - 分区容错性(P:Partition Tolerance)
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
结论:ZooKeeper不能保证每次服务请求的可用性。(注:在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
进行Leader选举时集群都是不可用。
<br /> <br /> <br /> <br /> <br />

若有收获,就点个赞吧
0 人点赞
