缓存机制和 cache 的意义
Spark中对于一个RDD执行多次算子(函数操作)的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
因此对于这种情况,我们的建议是:对多次使用的RDD进行持久化。
首先要认识到的是, .Spark 本身就是一个基于内存的迭代式计算,所以如果程序从头到尾只有一个 Action 操作且子 RDD 只依赖于一个父RDD 的话,就不需要使用 cache 这个机制, RDD 会在内存中一直从头计算到尾,最后才根据你的 Action 操作返回一个值或者保存到相应的磁盘中.需要 cache 的是当存在多个 Action 操作或者依赖于多个 RDD 的时候, 可以在那之前缓存RDD. 如下:
val rdd = sc.textFile("path/to/file").Map(...).filter(...)val rdd1 = rdd.Map(x => x+1)val rdd2 = rdd.Map(x => x+100)val rdd3 = rdd1.join(rdd2)rdd3.count()
在这里 有2个 RDD 依赖于 rdd, 会形成如下的 DAG 图:
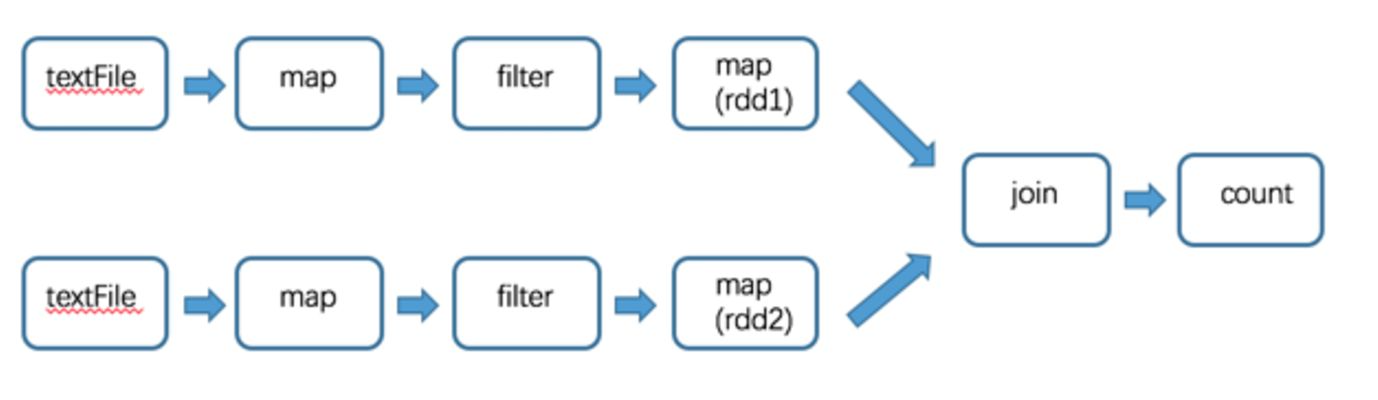
所以可以在 rdd 生成之后使用 cache 函数对 rdd 进行缓存,这次就不用再从头开始计算了.缓存之后过程如下:
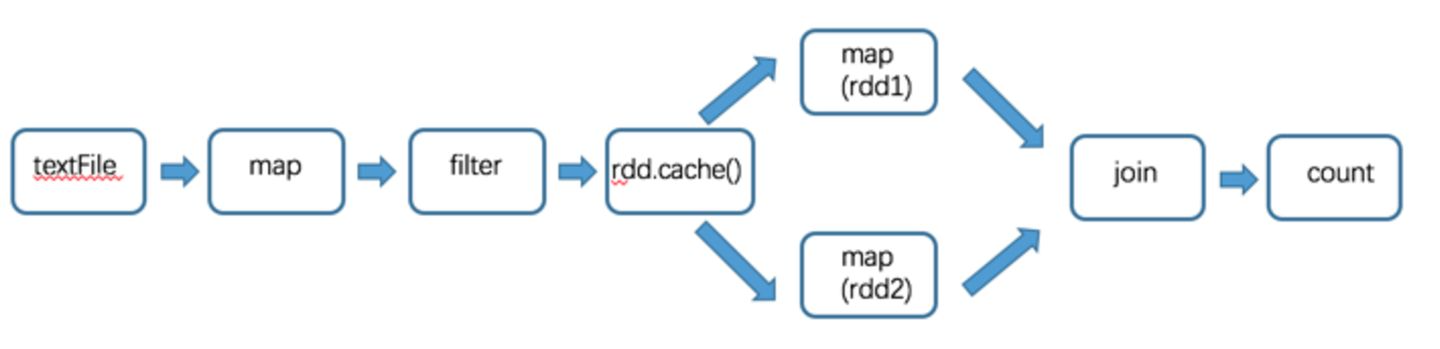
除了 cache 函数外,缓存还可以使用 persist, cache 是使用的默认缓存选项,一般默认为Memoryonly(内存中缓存), persist 则可以在缓存的时候选择任意一种缓存类型.事实上, cache 内部调用的是默认的 persist.
持久化的类型如下:

是否进行序列化和磁盘写入,需要充分考虑所分配到的内存资源和可接受的计算时间长短,序列化会减少内存占用,但是反序列化会延长时间,磁盘写入会延长时间,但是会减少内存占用,也许能提高计算速度.
此外要认识到:cache 的 RDD 会一直占用内存,当后期不需要再依赖于他的反复计算的时候,可以使用 unpersist 释放掉.
shuffle 的优化
进行 shuffle 操作的是是很消耗系统资源的,需要写入到磁盘并通过网络传输,有时还需要对数据进行排序。
常见的 Transformation 操作如:repartition,join,cogroup,以及任何 By 或者 ByKey 的 Transformation 都需要 shuffle 数据,合理的选用操作将降低 shuffle 操作的成本,提高运算速度。具体如下:
- 当进行联合的规约操作时,避免使用 groupByKey。
举个例子,rdd.groupByKey().mapValues( .sum) 与 rdd.reduceByKey( + _) 执行的结果是一样的,但是前者需要把全部的数据通过网络传递一遍,而后者只需要根据每个 key 局部的 partition 累积结果,在 shuffle 的之后把局部的累积值相加后得到结果。 - 当输入和输入的类型不一致时,避免使用 reduceByKey。
举个例子,我们需要实现为每一个key查找所有不相同的 string。一个方法是利用 map 把每个元素的转换成一个 Set,再使用 reduceByKey 将这些 Set 合并起来。 - 生成新列的时候,避免使用单独生成一列再 join 回来的方式,而是直接在数据上生成。
当需要对两个 RDD 使用 join 的时候,如果其中一个数据集特别小,小到能塞到每个 Executor 单独的内存中的时候,可以不使用 join, 使用 broadcast 操作将小 RDD 复制广播到每个 Executor 的内存里 join。
资源参数调优
主要在 spark-submit 提交的时候指定,或者写在配置文件中启动。
可以通过 spark-submit —help 查看。
资源参数的调优,没有一个固定的值,需要根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及Spark web ui中显示的作业gc情况)

总结
对需要重复计算的才使用 cache,同时及时释放掉(unpersist)不再需要使用的 RDD
- 避免使用 shuffle 运算。需要的时候尽量选取较优方案
合理配置 Executor/Task/core 的参数,合理分配持久化/ shuffle的内存占比
driver-memory: 1G
executor-memory: 4~8G(根据实际需求来)
num-executors: 50~100
executor-cores: 2~4
Tasks: 500~1000应用性能优化
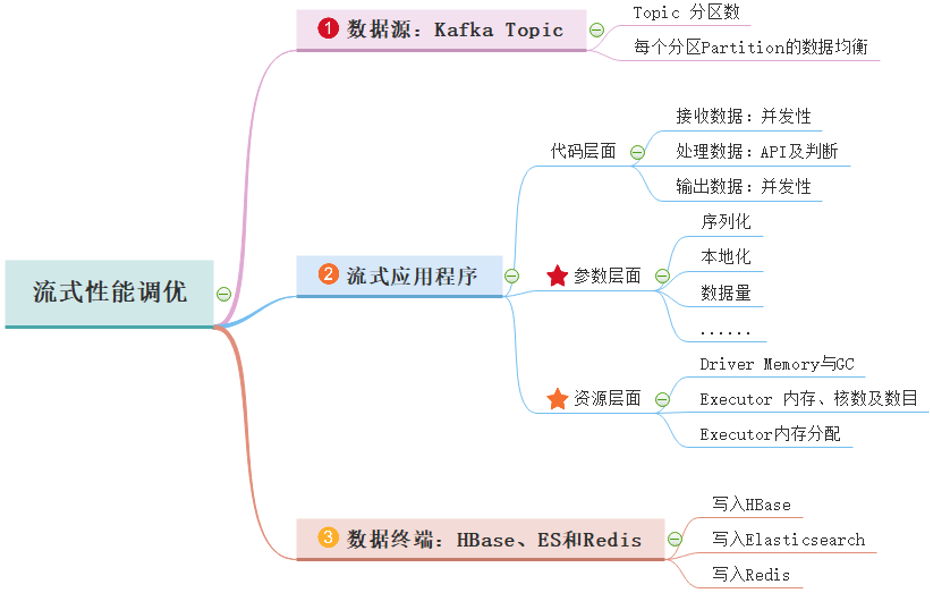
Spark框架中SparkStreaming和StructuredStreaming流式应用程序实际在生产环境运行时,需要调整参数优化性能提升,使其能够实时快速处理数据,从数据源、流式应用程序及数据终端三个方面综合考虑,优化性能,主要思路如下图所示:
数据本地性
Spark作业运行过程中,Driver会对每一个stage的task进行分配。根据Spark的task分配算法,Spark希望task能够运行在它要计算的数据所在的节点(数据本地化思想),这样就可以避免数据的网络传输。
Spark的本地化等级如下所示:
默认为3秒,时间太长,如果设置【spark.locality.wait】为100毫秒,即使用最差的”ANY”策略进行调度, task set的处理也只是花了100毫秒, 因此, 没必要非得为了”NODE_LOCAL”策略的生效而去等待那么长的时间,特别是在流计算这种场景上。反压机制(SparkStreaming)
反压(Back Pressure)机制主要用来解决流处理系统中,处理速度比摄入速度慢的情况。是控制流处理中批次流量过载的有效手段。
在实际流式应用场景中,有些特殊业务场景,如大促、秒杀活动与突发热点事情等业务流量在短时间内剧增,形成巨大的流量毛刺,数据流入的速度远高于数据处理的速度,对流处理系统构成巨大的负载压力,如果不能正确处理,可能导致集群资源耗尽最终集群崩溃,因此有效的反压机制(backpressure)对保障流处理系统的稳定至关重要。
Spark 1.5 引入了反压(Back Pressure)机制,可以根据处理效率动态调整摄入速率。开启反压机制,即设置spark.streaming.backpressure.enabled为true,Spark Streaming会自动根据处理能力来调整输入速率,从而在流量高峰时仍能保证最大的吞吐和性能。反压机制其他参数:spark.streaming.backpressure.initialRate
启用反压机制时每个接收器接收第一批数据的初始最大速率,默认值没有设置,只适用于Receiver Stream,不适用于Direct Stream。- spark.streaming.backpressure.pid.minRate
可以估算的最低费率是多少,默认值为 100,只能设置成非负值。 - spark.streaming.backpressure.rateEstimator
速率估算器类,默认值为 pid ,目前 Spark 只支持这个,可以根据自己的需要实现。 - spark.streaming.backpressure.pid.proportional
用于响应错误的权重(最后批次和当前批次之间的更改)默认值为1,只能设置成非负值。 - spark.streaming.backpressure.pid.integral
错误积累的响应权重,具有抑制作用(有效阻尼)。默认值为 0.2 ,只能设置成非负值。 - spark.streaming.backpressure.pid.derived
对错误趋势的响应权重。 这可能会引起 batch size 的波动,可以帮助快速增加/减少容量。默认值为0,只能设置成非负值。
反压机制在SparkStreaming应用程序中使用:
此外反压机制有如下两个注意事项:
- 反压机制真正起作用时需要至少处理一个批:由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制真正起作用前,应至少保证处理一个批。
如何保证反压机制真正起作用前应用不会崩溃:要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。若为Direct Stream,如Kafka Direct Stream,则可以通过spark.streaming.kafka.maxRatePerPartition参数来控制。此参数代表了 每秒每个分区最大摄入的数据条数。假设BatchDuration为5秒,spark.streaming.kafka.maxRatePerPartition为10000条,Kafka topic 分区数为3个,则一个批(Batch)最大读取的数据条数为360条(3510000=150000)。同时,需要注意,该参数也代表了整个应用生命周期中的最大速率,即使是背压调整的最大值也不会超过该参数。
动态资源分配
Spark动态资源调整其实也就是Executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定。
官方文档:http://spark.apache.org/docs/2.4.5/job-scheduling.html
Spark on YARN开启动态资源调整步骤如下:spark.dynamicAllocation.enabled设置为true,启动动态资源功能;
- spark.shuffle.service.enabled设置为true,在每个nodeManager上设置外部shuffle服务
- 重启所有nodeManager
配置yarn-site.xml,内容如下:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
动态资源分配其他相关参数:
- spark.dynamicAllocation.maxExecutors,executor数量的上限,默认是无限制的;
- spark.dynamicAllocation.minExecutors,executor数量的下限,默认是0个;
- spark.dynamicAllocation.initialExecutors,动态分配初始executor个数默认值=spark.dynamicAllocation.minExecutors;
- spark.dynamicAllocation.executorIdleTimeout,当某个executor空闲超过这个设定值,就会被kill,默认60s;
- spark.dynamicAllocation.cachedExecutorIdleTimeout,如果executor内有缓存数据(cache data),并且空闲了N秒,则remove该executor。默认值无限制,也就是如果有缓存数据,则不会remove该executor;
- spark.dynamicAllocation.schedulerBacklogTimeout:任务队列非空,资源不够,申请executor的时间间隔,默认1s;
- spark.dynamicAllocation.sustainedSchedulerBacklogTimeout:同schedulerBacklogTimeout,是申请了新executor之后继续申请的间隔,默认=schedulerBacklogTimeout;
使用动态资源分配机制的应用示例:
# 提交Spark Application,设置启用动态资源管理
$SPARK_HOME/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 5g \
--driver-cores 5 \
--executor-memory 10g \
--executor-cores 5 \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.initialExecutors=5 \
--conf spark.dynamicAllocation.minExecutors=5 \
--conf spark.dynamicAllocation.maxExecutors=15 \
--conf spark.dynamicAllocation.executorIdleTimeout=300s \
--conf spark.dynamicAllocation.schedulerBacklogTimeout=10s \
--class cn.itcast.spark.report.DailyRealTimeOrderReport \
order-apps.jar

若有收获,就点个赞吧
0 人点赞
